倩女幽魂口袋互通版
1.87 GB · 2025-11-16

alixixi 11 月 16 日消息,科技媒体 golem 昨日(11 月 15 日)发布博文,报道称谷歌通过其 AI Studio 平台,正测试一款尚未命名的 AI 模型,在破译难以辨认的历史手稿方面已接近人类专家的水平。
alixixi援引博文介绍,历史学家 Mark Humphries 使用一套专门开发的基准数据集,系统性地测试了该模型的性能。结果表明,在处理五份高难度历史手稿时,该模型的整体字符错误率约为 1.7%,其中大部分错误涉及标点符号和大小写,而非单词本身。
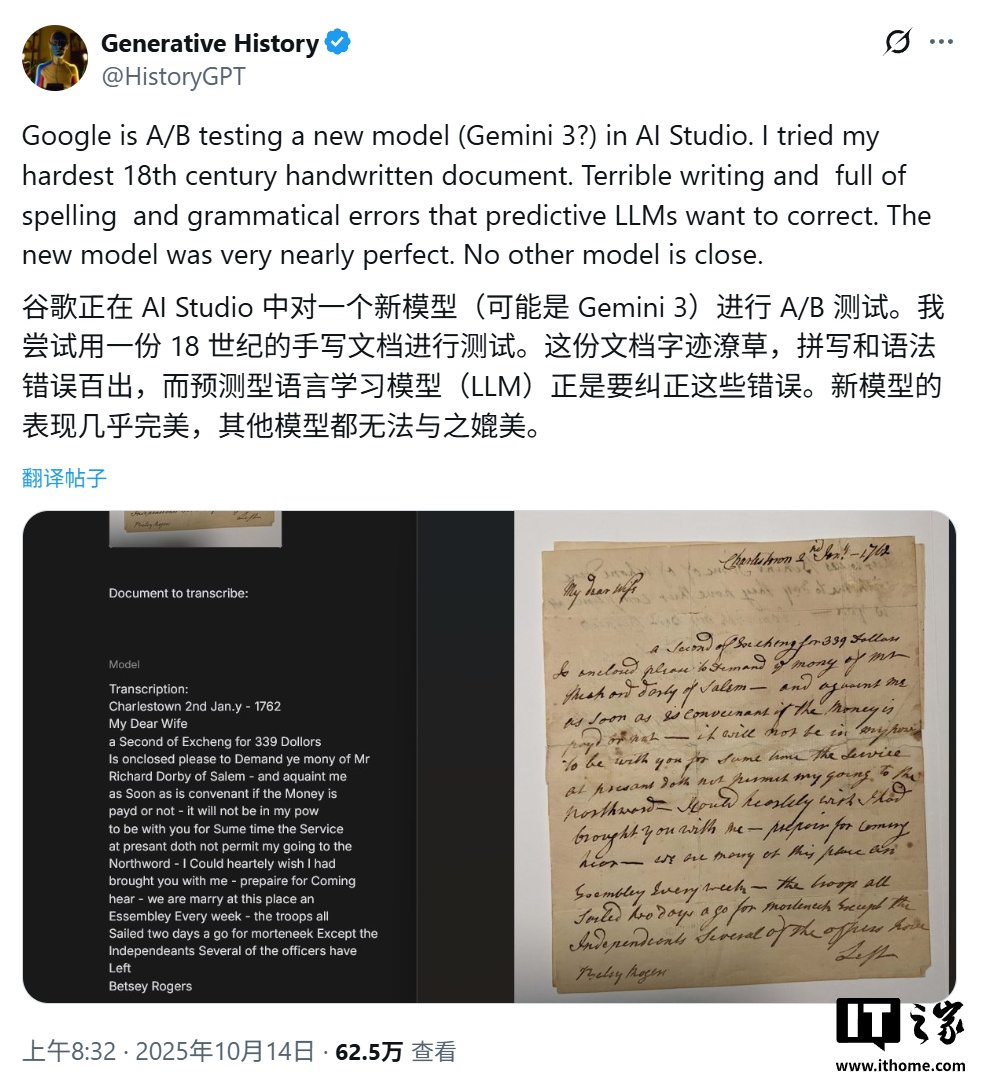
Humphries 的评估进一步指出,如果排除模糊的标点符号和大小写错误,该 AI 模型的字符错误率将骤降至约 0.56%,相当于每转写 200 个字符才出现一个错误。
这一惊人的准确度,让其性能足以与从事历史文献转写的专业人类工作者相提并论。此次测试的文档涵盖了 18 至 19 世纪的多种手写风格,其中不乏字迹潦草、拼写错误和语法不一致的复杂样本,进一步凸显了该模型的强大能力。
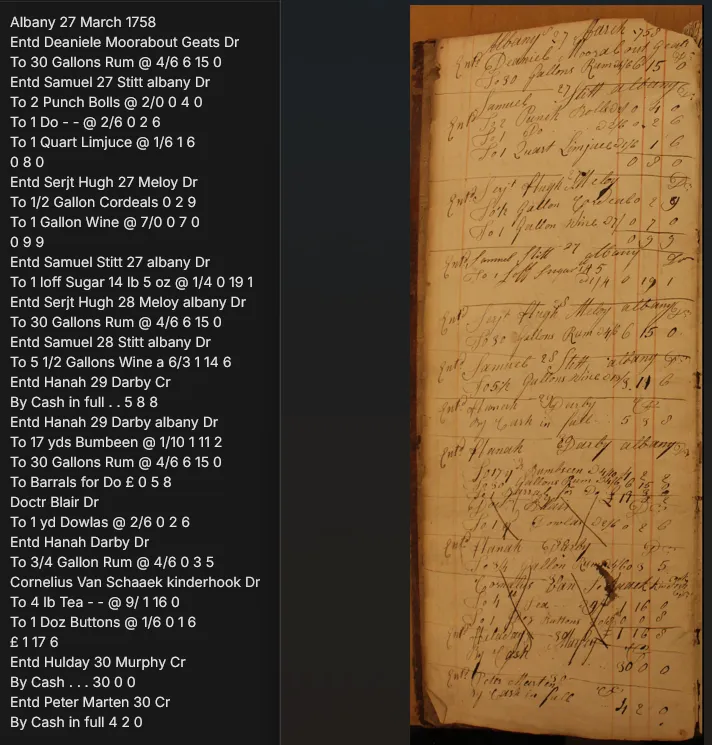
该模型最令人意外的表现,是其超越了简单的文字转写,展现出复杂的推理能力。在处理一份 18 世纪商人的日记时,原文中有一条关于购买糖的记录,仅标记了数字“145”,并未注明计量单位。
谷歌的 AI 模型并未直接转写为“145”,而是输出了“14 磅 5 盎司”。研究人员发现,AI 是通过反向计算账本中记录的总价,并结合当时英国的货币(磅、先令、便士)与重量单位关系,才成功推断出这一结果。

尽管初步结果令人振奋,但 Humphries 也强调了当前评估的局限性。由于该模型通过 A/B 测试形式零星出现,系统性地进行大规模测试存在困难,目前仅评估了基准数据集中约 10% 的样本。


