小小部队2无限钻石金币
84.18MB · 2025-11-06

在传统的代码式核对系统中,哪怕只是类似“订单应付金额 = 商品金额 - 优惠金额”这样简单的规则,也要走完一整套流程:需求 → 评审 → 开发/测试 → 发版 → 上线(2–3 天),甚至微调阈值也要发版。对高频变化的业务而言,这样的流程明显低效。
从这个场景可以看到,传统的代码式规则实现方式,存在以下三大痛点:
在复盘这些问题时,我们发现: 核对规则的本质,其实就是“ 数据查询 + 条件判断”。
它并不属于核心业务逻辑,而更像是数据层的一种“验证表达式”。
由此得出关键洞察是 :
于是,我们决定用SQL成为规则。
我们的想法其实很简单:配置一条 SQL ,就是定义一条核对规则。
过去:
现在:
从“写代码发版”到“配置即生效”,规则交付效率提升 95%+ 。
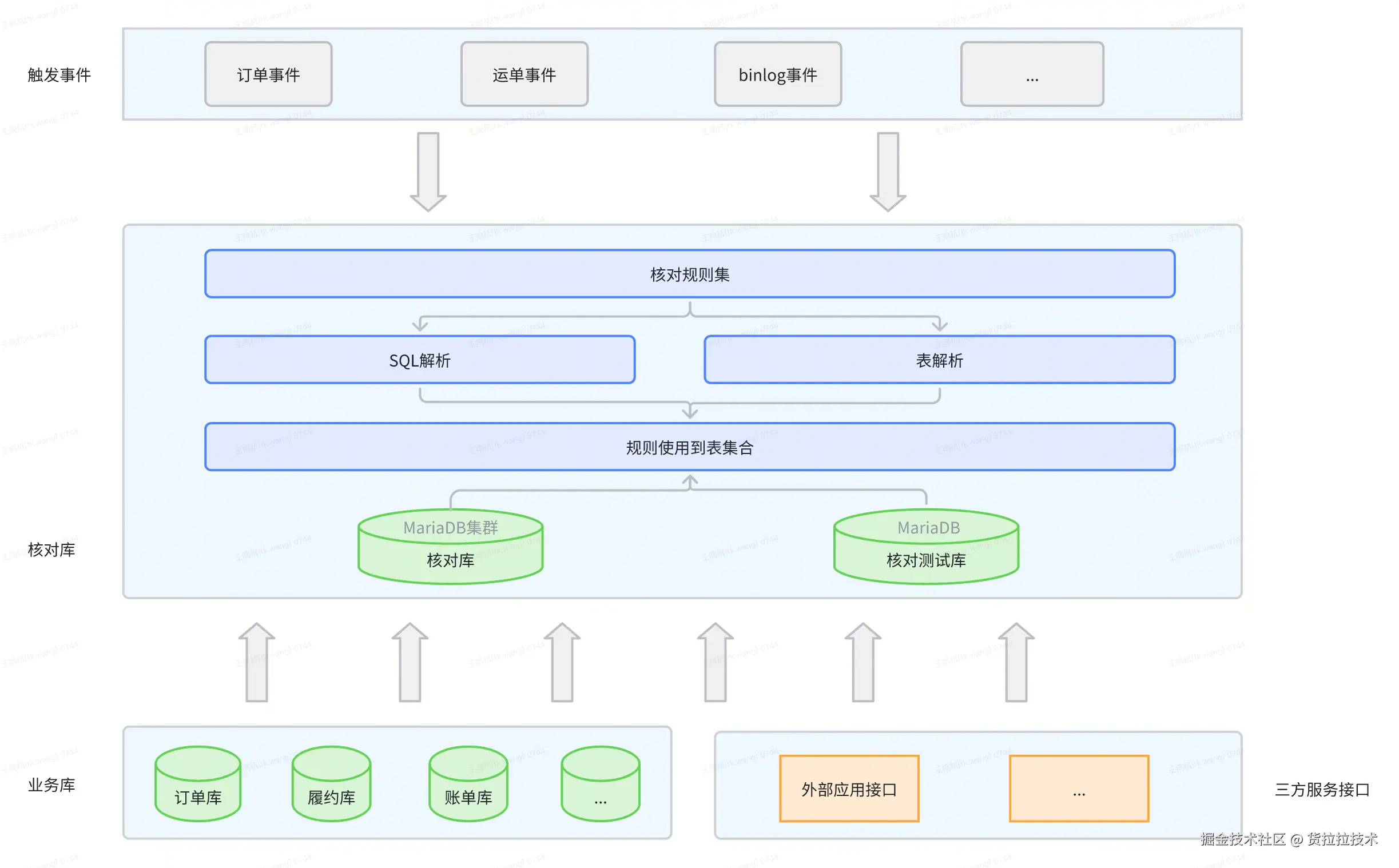
目标:让规则执行更快、更稳、更安全。架构围绕以下关键机制展开:
事件触发(可插拔)
规则 SQL化(可配置)
${field} 参数自动注入;支持在线调试与一键发布,分钟级生效,实现“配置即规则”。线上隔离(可控风险)
数据共享与并行(高吞吐)
当用户在平台上配置一条核对 SQL,比如:
SELECT
o.order_no,
o.order_amount,
p.payment_amount
FROM order o
LEFT JOIN payment p ON o.order_no = p.order_no
WHERE o.order_no = '${order_no}'
AND ABS(o.order_amount - p.payment_amount) > 0.01
系统必须回答两个关键问题:
而答案的来源,就是——SQL 血缘关系分析。
在配置化核对场景中,系统需要对每条规则的 SQL 进行结构化理解,以识别其涉及的表、字段、条件及参数依赖。 为此,我们在 JSqlParser 的基础上进行了定制化扩展,构建了一个轻量级 SQL 元信息解析引擎,用于生成可视化的血缘关系图。
血缘分析流程:
用户配置 SQL
↓
SQL 解析引擎(基于 JSqlParser)
↓
血缘信息提取(表、字段、条件、参数)
↓
生成血缘关系图
最终系统能自动识别出:
【表依赖关系】
order(订单表)
├─ 字段:order_no, order_amount
└─ 查询条件:order_no = '${order_no}'
payment(支付表)
├─ 字段:order_no, payment_amount
└─ 关联条件:order_no = o.order_no
SQL 中的占位符会被系统自动识别并替换。例如:
WHERE order_no = '${order_no}'
系统解析出占位符:
${order_no}
再从 Kafka 消息中提取对应字段:
{
"order_no": "20250101001"
}
替换后生成最终可执行 SQL:
WHERE order_no = '20250101001'
整个过程无需人工干预,完全自动完成参数解析与注入。
通过定制化 SQL 血缘解析,系统可以自动理解用户配置的 SQL,并生成完整的数据准备与执行逻辑。
对比传统 方式 :
| 传统方式 | SQL配置化 |
|---|---|
| 开发人员手动编写代码,明确数据来源、查询逻辑和比对规则 | 用户只需写 SQL,系统自动识别表、字段、条件和占位符,生成可执行查询 |
| 规则上线依赖开发、测试与发版流程 | 配置即生效,无需额外开发操作 |
| 调整规则需要重复修改代码 | 修改 SQL 即可,自动完成数据准备和逻辑执行 |
配置 SQL 规则时,用户最担心的是:
SQL 写得对不对?
能否查到数据?
查询结果是否符合预期?
上线后会不会出问题?
如果没有调试能力,用户只能“盲配置”,上线后才发现问题,需要来回修改,效率低,风险也大。
我们提供了一个在线 SQL 调试器,让用户在配置规则时就能验证 SQL 的正确性、性能和结果。
SQL 调试流程:
用户在配置页面编写 SQL
↓
输入测试参数(如 order_no)
↓
点击“调试”按钮
↓
系统自动执行:
├─ SQL 安全校验(防止 DROP/DELETE/UPDATE 等危险操作)
├─ 权限校验(检查用户是否有表权限)
├─ SQL 解析(提取表依赖)
├─ 数据查询(从业务库获取真实数据)
├─ 数据加载(写入测试数据库)
└─ SQL 执行(返回查询结果)
↓
用户查看调试结果(查询结果、表使用情况、执行耗时)
SQL 安全校验(防破坏)
权限控制(防越权)
性能兜底(防慢查)
支持两种调试模式:
| 模式 | 描述 | 适用场景 |
|---|---|---|
| 自动查询模式(推荐) | 系统自动从业务库获取数据,只需输入参数 | 大多数场景 |
| 手动编辑输入模式 | 用户可手动输入表数据(JSON) | 边界测试或无真实数据场景 |
对用户:
对系统:
一个订单创建事件可能触发多条核对规则:
如果每个规则独立查询,会产生重复查询 IO:
规则 1 → 查询 order (order_no='1001') → 100ms
规则 2 → 查询 order (order_no='1001') → 100ms ← 重复查询!
规则 3 → 查询 order (status='PAID') → 100ms
总耗时:300ms,且有 1 次重复查询
我们通过 SQL 血缘分析,提取每个规则的"数据指纹"(表 + WHERE 条件),将"数据指纹相同"的规则分为一组:
步骤 1:提取数据指纹
规则 1:订单金额核对
数据指纹:order WHERE order_no='1001'
规则 2:优惠金额核对
数据指纹:order WHERE order_no='1001' ← 与规则 1 相同
规则 3:状态核对
数据指纹:order WHERE status='PAID' ← 条件不同
步骤 2:数据指纹分组(按数据指纹)
分组 1:规则 1 + 规则 2
数据指纹:order WHERE order_no='1001'
共享策略:只查询一次,两个规则复用同一份数据快照
分组 2:规则 3
数据指纹:order WHERE status='PAID'
独立查询:指纹不同,需单独查询
步骤 3:执行流程(数据共享 + 组内并行)

核心价值:
从技术选型角度看,核对计算的场景与传统业务库存在明显差异。如果直接使用 MySQL,我们需要额外维护一套核对专用库,并同步所有业务表结构。这会带来几个问题:
基于这些限制,我们将执行引擎选型方向转向 MariaDB 内存数据库。 它兼容 MySQL 生态,却以内存为计算核心,支持快速加载、计算与释放数据,非常契合“短生命周期、高性能计算”的特征。
我们采用 MariaDB 内存数据库 + 池化管理 实现隔离计算,执行流程如下:
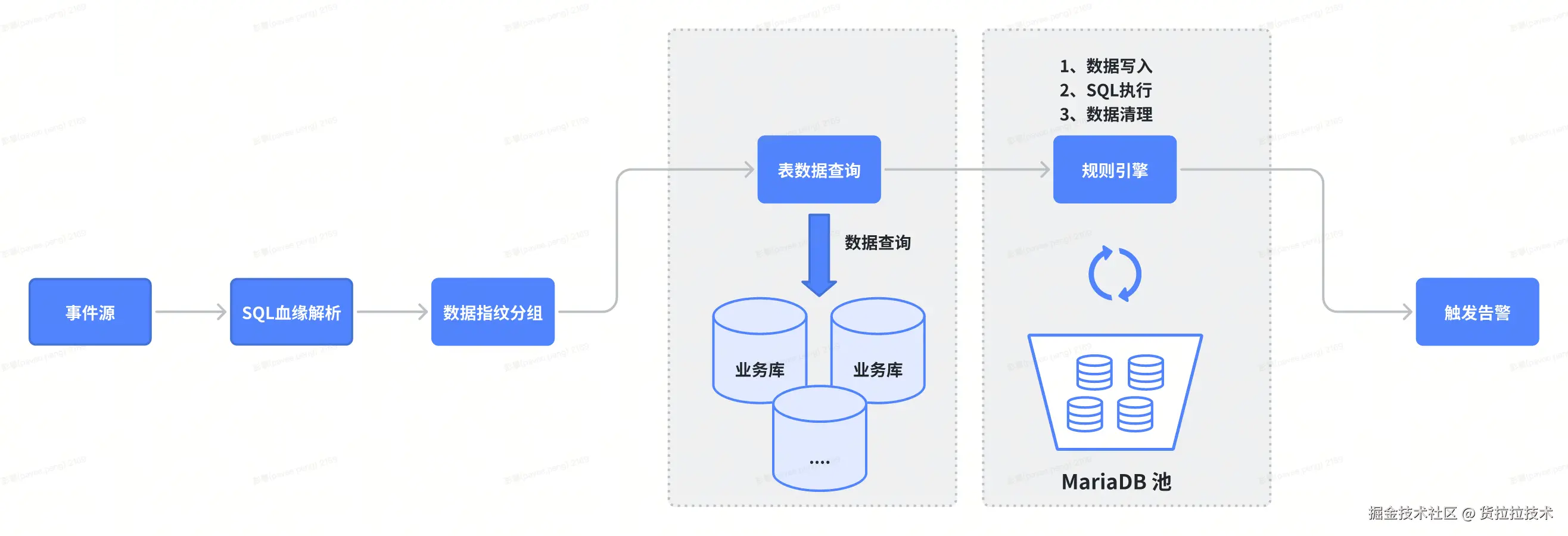
步骤 1:事件触发 → 匹配规则 → 解析 SQL 血缘图
↓
步骤 2:根据数据指纹分组,从多个业务库(MySQL/接口/...)拉取数据
→ 从池中租借一个空闲的 MariaDB 实例(独占)
→ 将拉取的跨库数据统一写入该 MariaDB 实例(实现数据汇聚)
↓
步骤 3:在该实例内执行规则 SQL(支持跨表 JOIN/聚合)
↓
步骤 4:获取执行结果 → 清理实例内数据 → 归还实例到池中(供下次复用)
↓
步骤 5:触发告警
核心优势:
技术层面:
业务层面:

