



无限极服务
146.43MB · 2025-10-24

说实话,做内容创作这行,文档处理是个永远绕不开的话题。
前几天赶稿,需要把一堆纸质资料转成电子版。手机拍照吧,光线不好拍出来一片模糊;角度没把握好,文字全是歪的;有时候手指还会不小心入镜。好不容易拍完了,发现屏幕拍摄的PPT上全是摩尔纹(那种密集的波纹),根本没法用。
还有更头疼的:学生时代的笔记本,上面红笔蓝笔标了一堆,现在想要个干净版本做素材,只能一个字一个字重新打?PDF转Markdown,表格识别一塌糊涂,公式全变成了乱码,还不如手动整理。
最近更让人焦虑的是AI安全问题。刷到好几条deepfake诈骗的新闻,有人用AI换脸冒充高管骗了2亿,还有人伪造法律文书诈骗上百万。
直到我参加了PRCV2025(中国模式识别与计算机视觉学术会议)上合合信息承办的"多模态文本智能大模型前沿技术与应用"主题论坛,才发现这些问题都有了系统性的解决方案。
先说结论:这不是简单的OCR升级,而是让AI从"打字员"进化成了"专业助理"。
传统OCR:拍照→识别文字→输出文本(到此为止)
多模态文本智能:拍照→理解内容→分析问题→主动处理→输出结果
差别在哪?三个关键词:
1. 多模态
不只是文字,图像、视频、表格、公式、手写字、印章……包含文本信息的媒介都能处理。
2. 理解
不只是"看见"文字,还能理解版面结构、语义逻辑。比如一份合同,AI能知道哪些是条款、哪些是签名、条款和签名的位置关系是否合规。
3. 决策
这是最关键的。AI不再是被动工具,而是能主动判断"这张图有什么问题""应该怎么处理"。光线不足?自动增强。角度倾斜?自动矫正。有手写标注?智能擦除。
场景1:合同审查
传统方式:提取文字,人工逐条检查
多模态文本智能:不仅提取条款,还能关联签名位置、日期、印章,自动判断合同效力的关键要素是否完整
场景2:财报分析
传统方式:OCR识别表格,经常出错
多模态文本智能:文字陈述与表格数据交叉验证,发现逻辑矛盾会主动标注
场景3:医疗病历
传统方式:分别识别文字和影像
多模态文本智能:诊断结论与影像证据综合判断,给出结构化输出
说白了,就是让AI真正"读懂"文档,而不只是"看见"文字。
你有没有遇到过这种情况:拍完照才发现手指挡住了一角,或者角度歪了,或者光线太暗?
合合信息的底层视觉处理技术,能做到的不只是简单的滤镜,而是真正的"图像修复"。
典型场景演示:
场景1:文字图像质量提升
一张手指遮挡、角度倾斜、光线不足的文档照片,经过AI处理后:
场景2:摩尔纹去除
拍摄电脑屏幕或投影时,经常会出现密集的波纹干扰(摩尔纹)。这在以前几乎是无解的,但合合信息可以做到:

场景3:手写擦除
这个功能我个人最喜欢。学生党做题、老师批改作业、工作中文档标注……很多时候我们需要一个"干净版本"。
合合信息能做到:
如果说底层视觉处理解决的是"看清楚"的问题,那文档解析解决的就是"看懂"的问题。
我的痛点:
经常需要把PDF转成Markdown格式,方便后续编辑。但传统工具识别效果惨不忍睹:
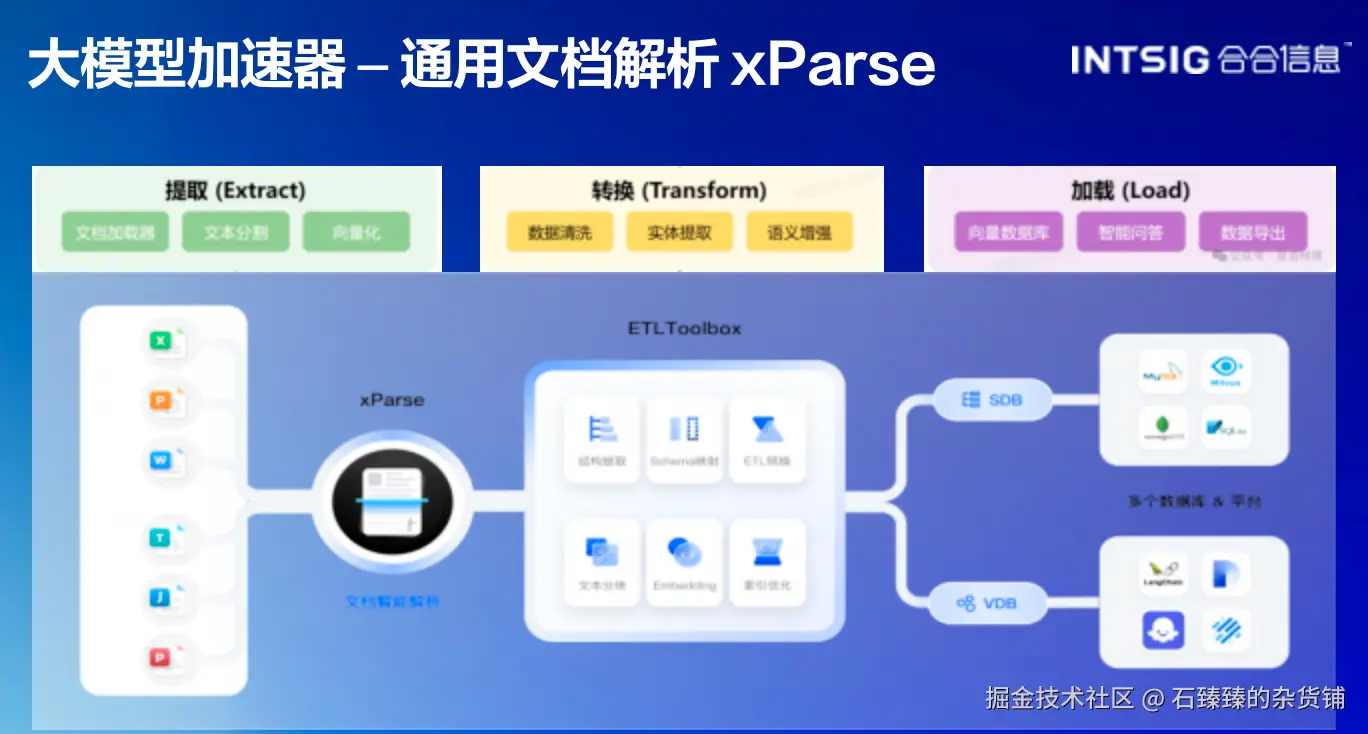
合合信息的大模型加速器-xParse系统,就是专门解决这个问题的。
核心能力:
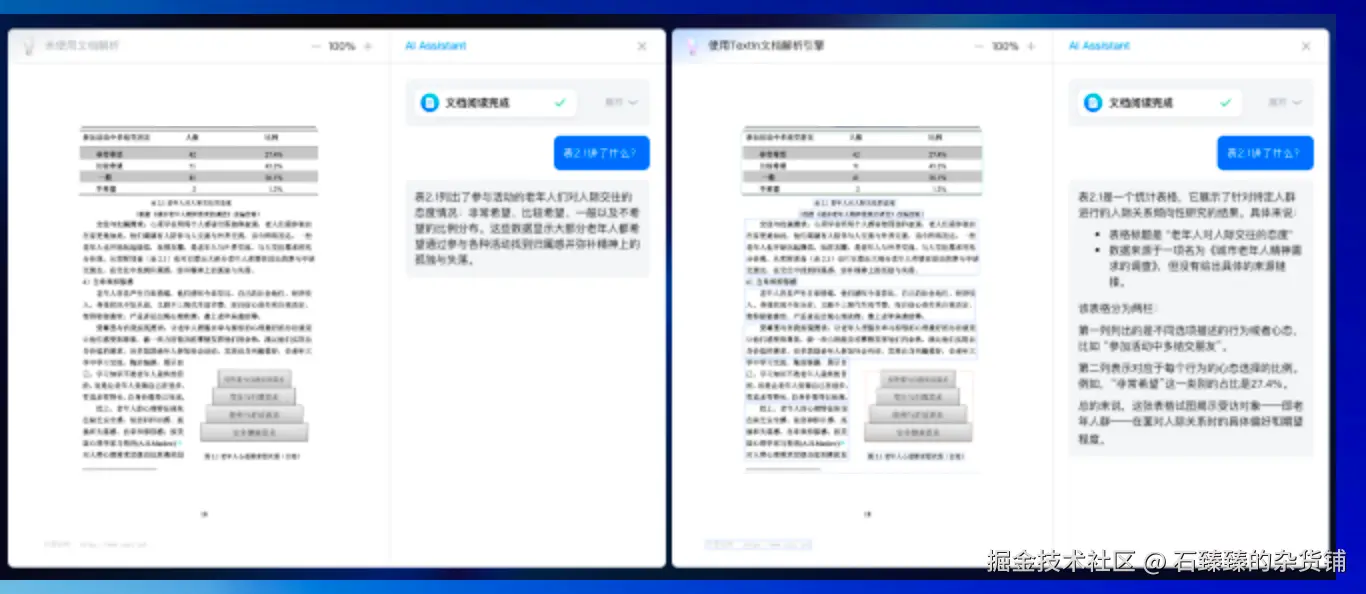
实际应用场景:知识库RAG
论坛上合合信息分享到:搭建企业知识库,用xParse解析文档后,RAG(检索增强生成)系统的准确率提升明显。
他们从三个维度做了评估:
这对于需要搭建企业知识库、做AI Agent的团队来说,是非常实用的工具。
合合信息把这些能力整合到了TextIn平台上,形成了一个完整的生态:
三层架构:
重点是,这些功能都可以线上体验:对于开发者来说,还提供了公有云API、私有化部署、国产化适配等多种方案。
说完文档处理,再来说第二大板块:AI内容安全。
这部分是我之前完全没关注过的领域,但听完论坛分享后,真的觉得太重要了。
案例1:山东淄博法律文书伪造案
2024年,山东淄博警方破获了一起案件:张某伪造公安、检察机关的法律文书,冒充办案人员,以"办理取保候审"为由诈骗。从2024年3月开始,短短几个月,骗取多名受害人100多万元。
案例2:香港Deepfake视频骗走2亿港元
2024年2月,香港发生了一起震惊世界的AI诈骗案:犯罪嫌疑人利用Deepfake技术,冒充公司高管,在视频会议中骗取企业员工,成功转走近2亿港元。
看到这两个案例,我意识到:AI生成技术的门槛越来越低,伪造的成本几乎为零,但造成的危害却是指数级增长的。
三大伪造风险:
作为内容创作者,我不仅要学会用AI,更要学会防AI。
合合信息的解决方案是FidOK图像智能鉴伪系统。
三大检测能力:
① 文本图像伪造检测
检测身份证、护照、发票、合同、票据、授权书等证件的PS篡改
② 人脸图像/视频伪造检测
识别Deepfake换脸、视频活化,应用于面试、社交、金融远程开户等场景
③ AIGC图像检测
判断图片是真实拍摄还是AI生成(如Midjourney、Stable Diffusion等工具生成的图像)
核心优势:
技术再好,不能落地就是空谈。FidOK已经在多个行业实际应用了。
案例1:某知名银行(文本图像检测)
客户痛点:
业务主要在线上,用户通过APP上传身份证办理业务。但无法有效识别翻拍、复印件、PS篡改等欺诈手段,存在合规风险。
解决方案:
接入FidOK系统,三道防线:
业务成效:
前端实时拦截不合规证件,后端实时检测PS痕迹,伪造样本拦截率超过90%。
案例2:国有四大行之一(人脸伪造检测)
客户痛点:
远程开户、大额转账等场景,面临Deepfake换脸、视频活化等深度伪造风险。
解决方案:
在APP/小程序身份认证环节,接入三道检测:
业务成效:
在用户无感知的情况下,后台实时拦截伪造样本,有效降低欺诈风险。
多模态文本智能技术,本质上是让AI从"被动工具"进化成"主动伙伴"。
它不再只是"你让我做什么,我就做什么",而是能够主动理解问题、分析问题、解决问题。
从文档处理到AI安全,从个人效率工具到企业级风控系统,合合信息搭建的是一个完整的技术生态。
技术的终极意义,不是炫技,而是解决真实问题,创造真实价值。

