
桌宠屋免安装中文正式版
965M · 2025-11-09

@[toc]
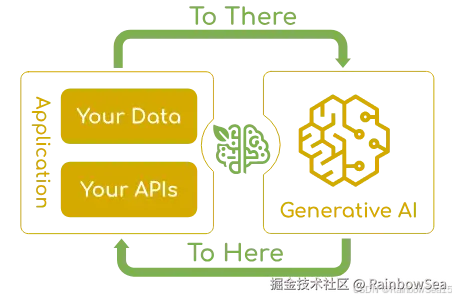
Spring AI 是一个面向人工智能工程的应用框架。解决了 AI 集成的基本挑战:将企业数据和API与AI 模型连接起来。
可以说是大模型应用中最简单也是最核心的一个技术。他是我们更大模型交互的媒介,提示词给的好大模型才能按你想要的方式响应。
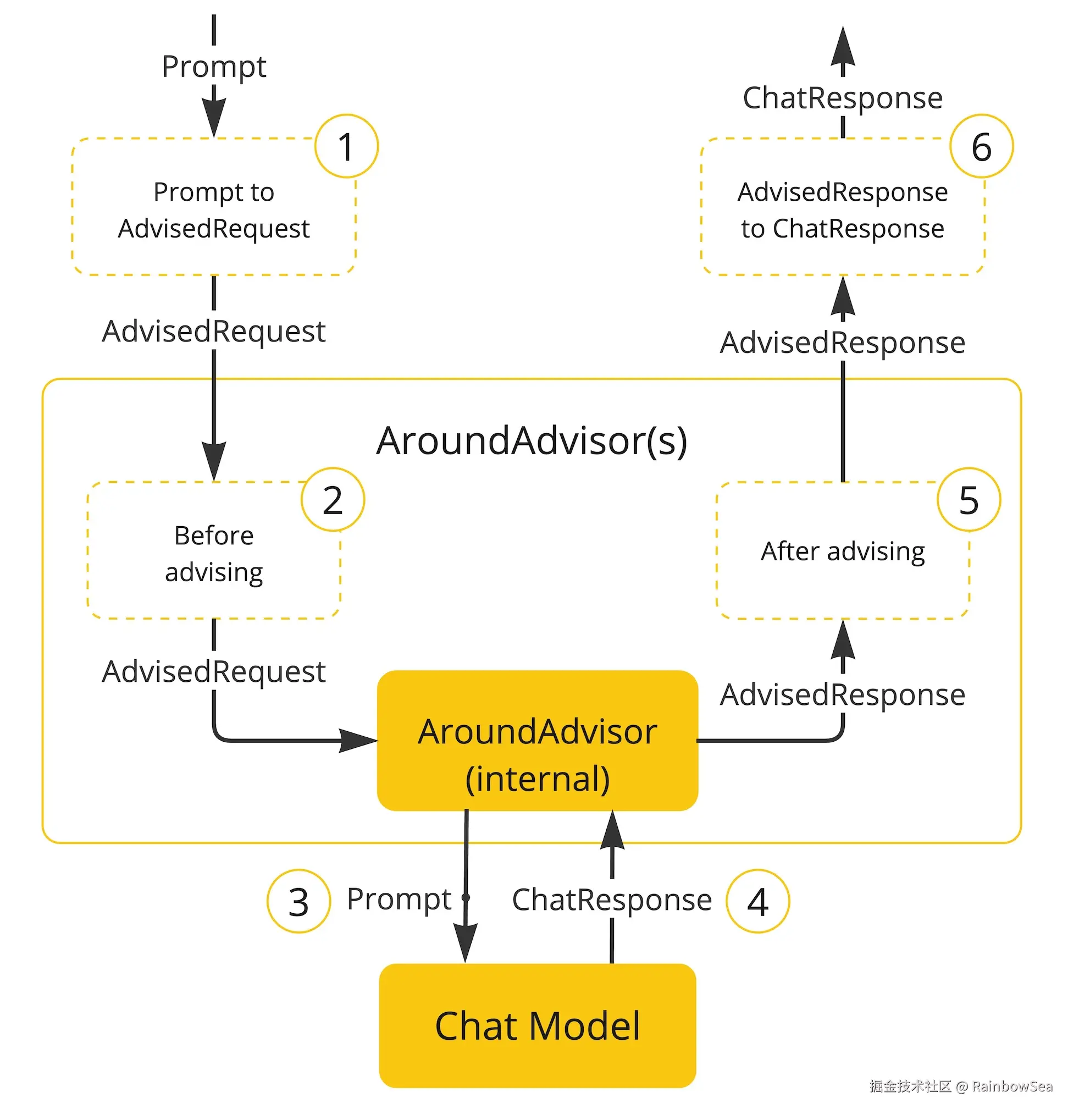
面向切面的思想对对模型对话和响应进行增强。
@Autowired
ChatMemoryRepository chatMemoryRepository;
通过一个bean组件就可以让大模型拥有对话记忆功能,可谓是做到了开箱即用
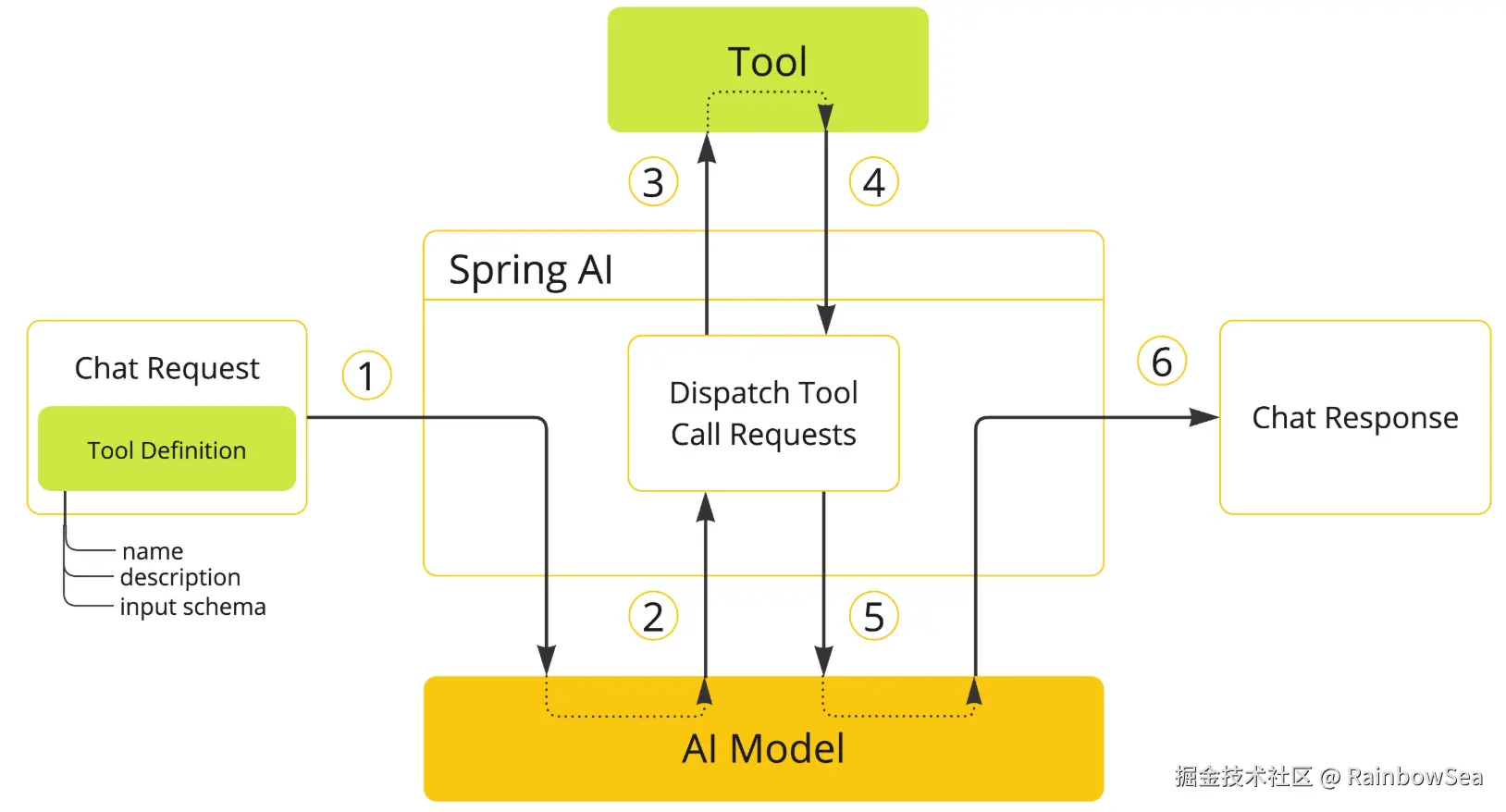
让大模型可以跟企业业务API进行互联 ,这一块实现起来也是非常的优雅
class DateTimeTools {
@Tool(description = "Get the current date and time in the user's timezone")
String getCurrentDateTime() {
return LocalDateTime.now().atZone(LocaleContextHolder.getTimeZone().toZoneId()).toString();
}
}
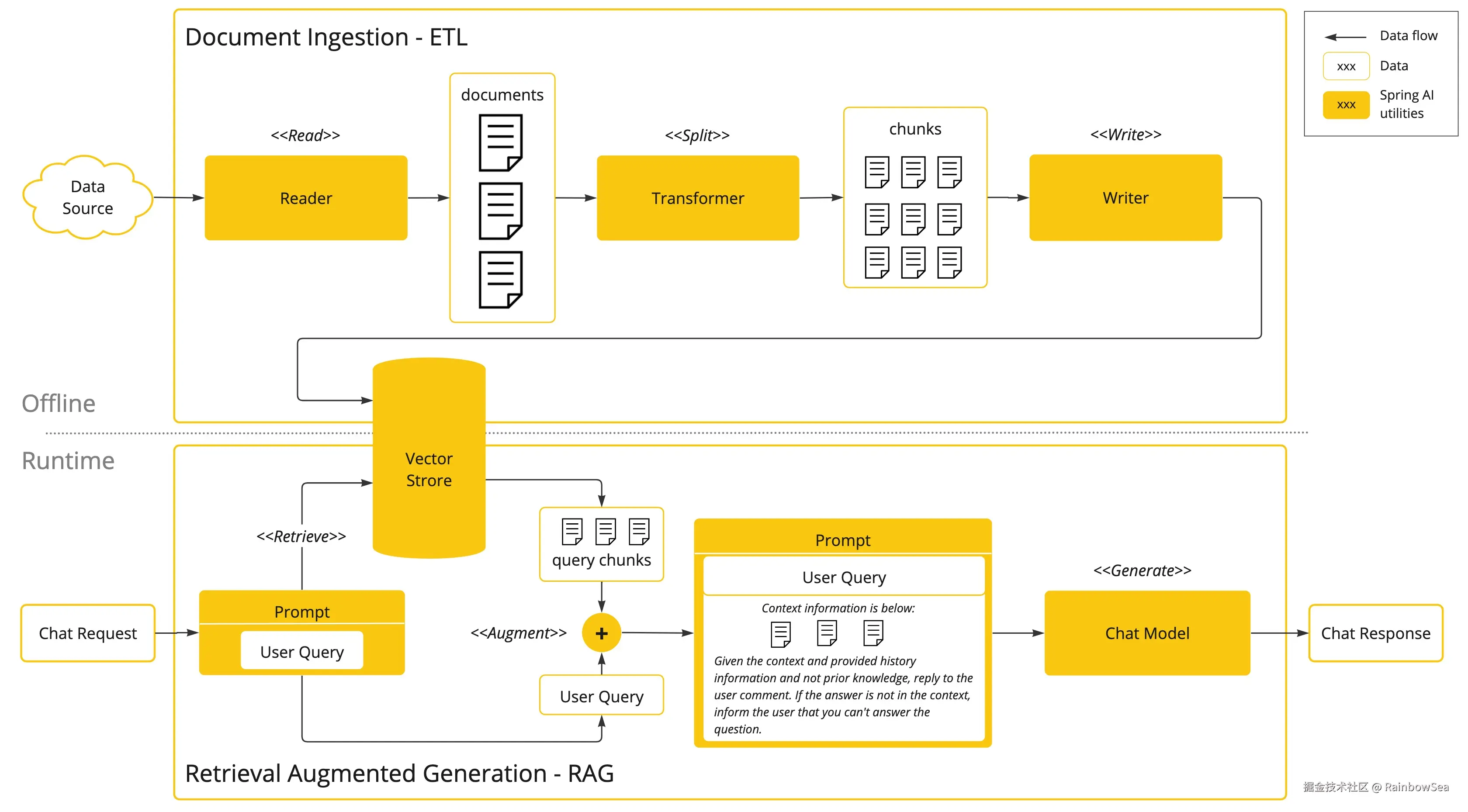
让大模型可以跟企业业务数据进行互联(包括读取文件、分隔文件、向量化) 向量数据库支持 目前支持20+种向量数据库的集成 这块我到时候也会详细去讲
让tools外部化,形成公共工具让外部开箱即用。 原来MCP协议的JAVA SDK就是spring ai团队提供的 提供了MCP 客户端、服务端、以及MCP认证授权方案 ,还有目前正在孵化的Spring MCP Agent 开源项目:
可以测试大模型的幻觉反应(在系列课详细讲解)
它把AI运行时的大量关键指标暴露出来, 可以提供Spring Boot actuctor进行观测
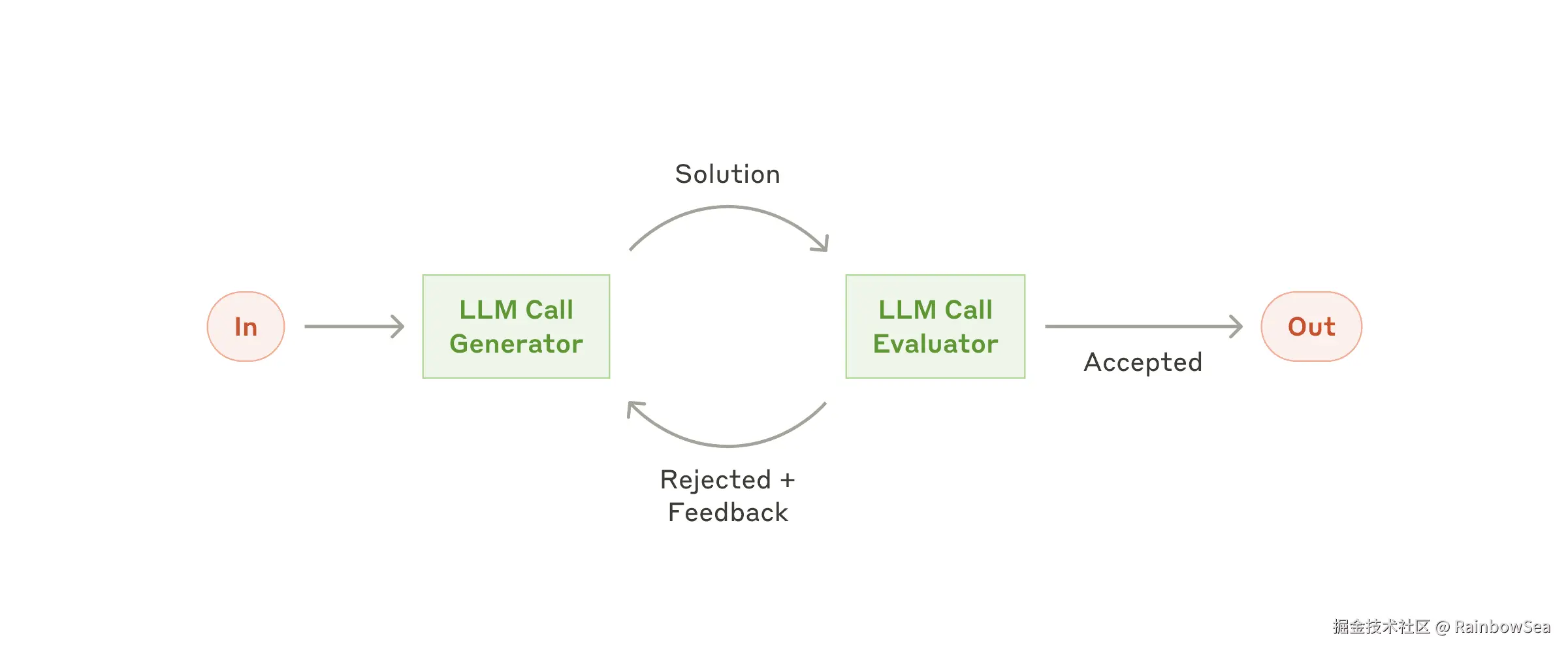
springai 提供了5种agent模式的示例
学完这5种你会对对模型下的agent应用有一个完整认识
 |  | |
|---|---|---|
| 生态 | 不依赖Spring,需要单独集成Spring | Spring官方,和Spring无缝集成 |
| 诞生 | 更早,中国团队,受 LangChain 启发 | 稍晚,但是明显后来居上 |
| jdk | v0.35.0 前的版本支持jdk8 ,后支持jdk17 | 全版本jdk17 |
| 功能 | 没有mcp server, 官方建议使用quarkus-mcp-server | 早期落后langchain4j, 现在功能全面,并且生态活跃,开源贡献者众多 |
| 易用性 | 尚可,中文文档 | 易用,api优雅 |
| 最终 | 公司不用 Spring AI 就选择它 | 无脑选! |
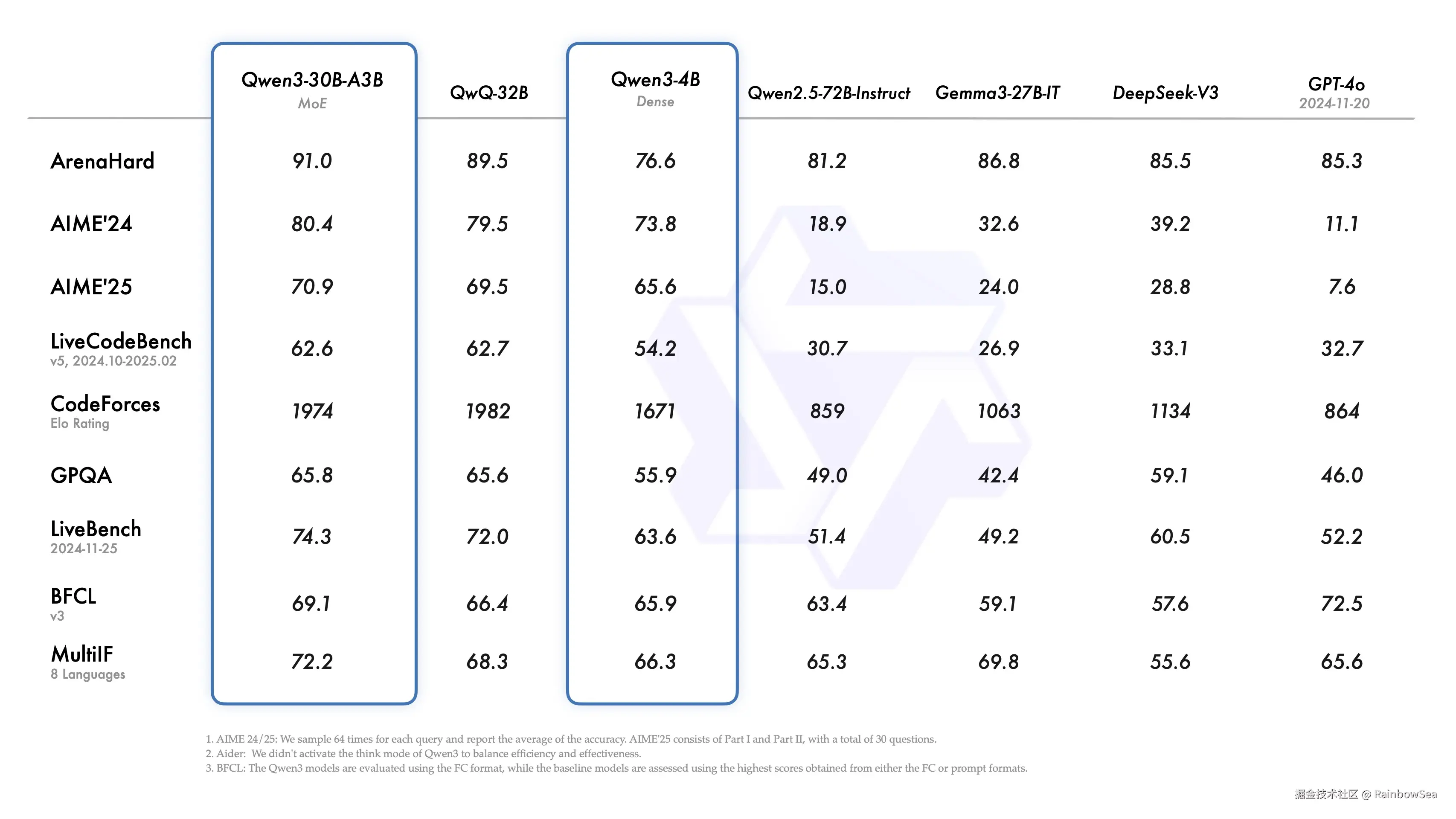
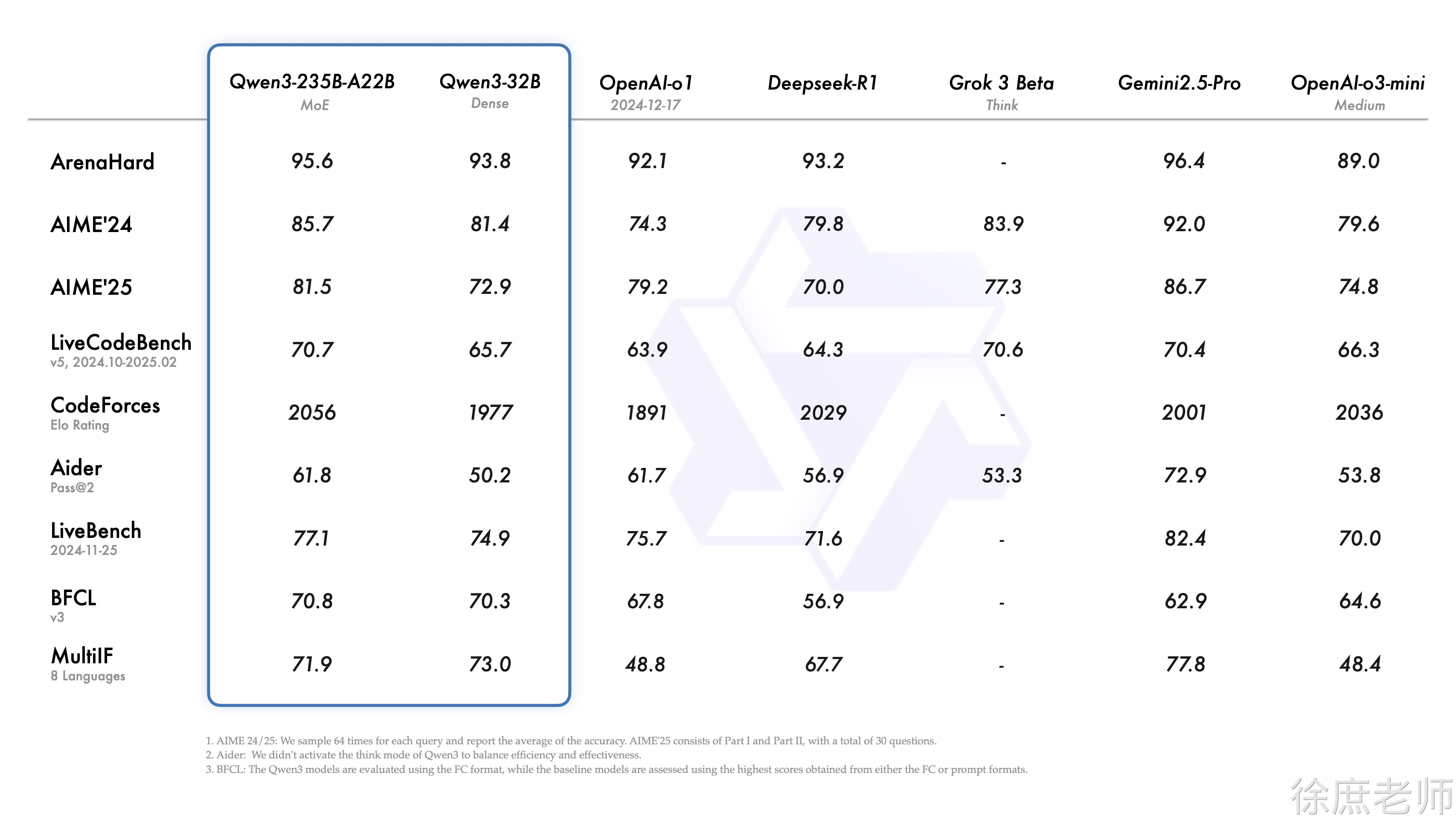
从证明的比较我们可以看出,目前大模型的基本上可以说是有一定的定型了,基本上都是通过提高硬件设置参数,算力,提高大模型的性能。而想要通过算法设计的方式,提高大模型有点困难了。
大模型的选择,需要根据自身的业务以及财力进行综合的选择。
1. 
github.com/jeinlee1991…
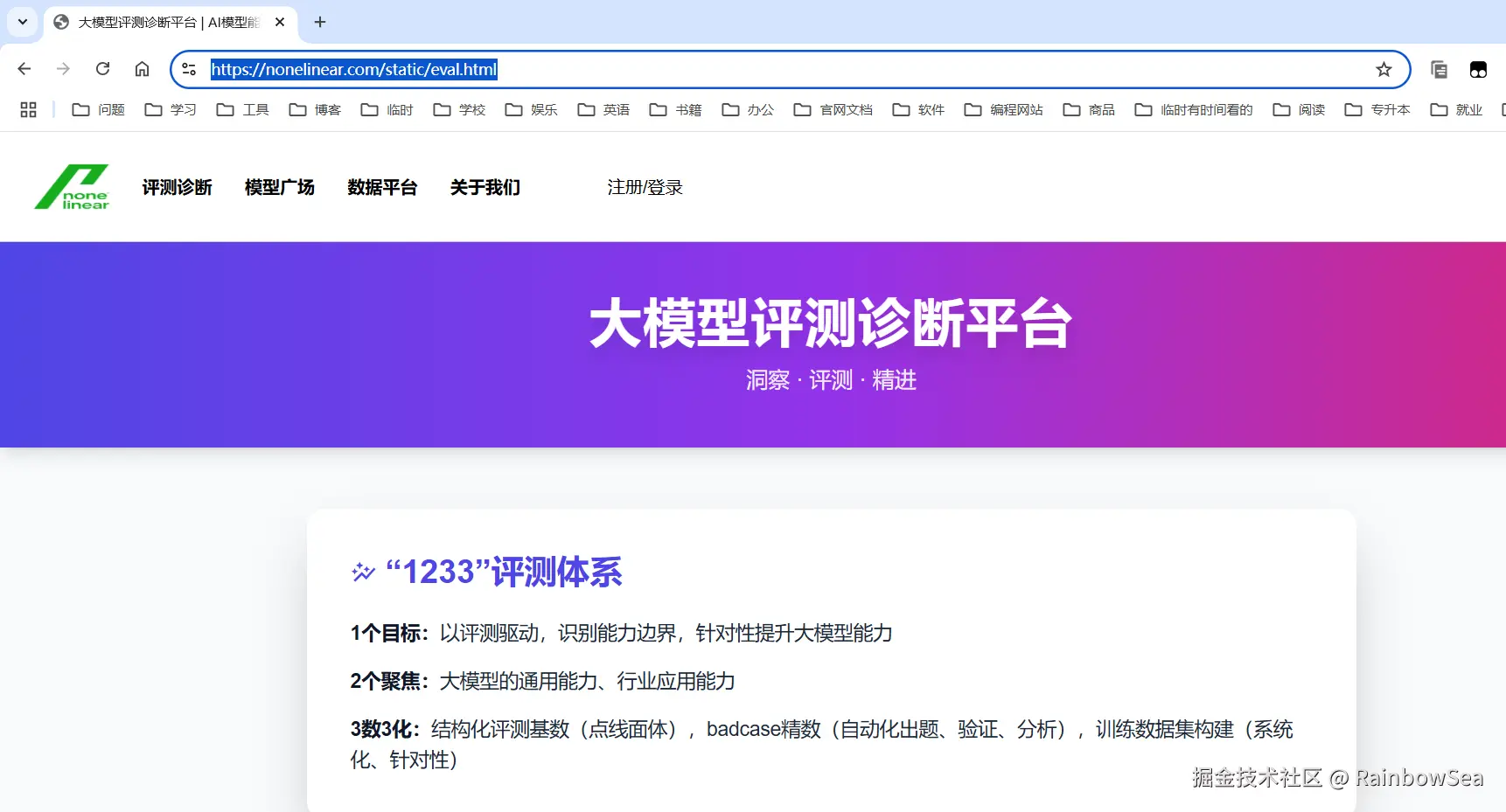
大模型的诊断平台:nonelinear.com/static/eval…,可以通过它,帮助我们进行以一个初步大模型的选择。

