

桌宠屋免安装中文正式版
965M · 2025-11-09

对于数仓场景和数据湖场景来说,最显著的特点就是数据处理的长流程和高复杂度任务依赖关系,从源数据采集到最终报表数据的生成,中间可能经历上百个任务的处理,这些任务如果是散乱的,无明确的流程组织起来,中间某一个步骤出问题,就很难发现其影响范围,更加难以判定对其他依赖的任务的影响程度。
任务需要被有效地组织并流程化处理。这就需要Workflow 。DolphinScheduler 中 Workflow 通过 DAG(有向无环图)的方式操作。DAG 是由多个顶点(tasks)和其他顶点的之间关系(Relationships)构成,图形化的 Workflow 可以很直观地看到任务之间的关系,任意任务之间不能形成环。使用 Workflow 管理任务可以让数据处理流程更有层次,加上任务血缘展示,可以让整个数据处理流程更可视化和清晰明了。
本文就主要探讨如何在 ApacheDolphinScheduler 上更好地玩转 Workflow, 以帮助大家更好地管理数据处理任务。
根据需求,在 ApacheDolphinScheduler上,可以通过页面拖拽、Python脚本、yaml定义、OpenAPI调用多种方式创建工作流。这一点相对 Apache Airflow 来说,要更容易上手一些,比较适合平台使用者为多个部门的人员,比如分析师、数据科学家等,毕竟所见即所得比起调试 Python 代码要来得更简单直接一些。
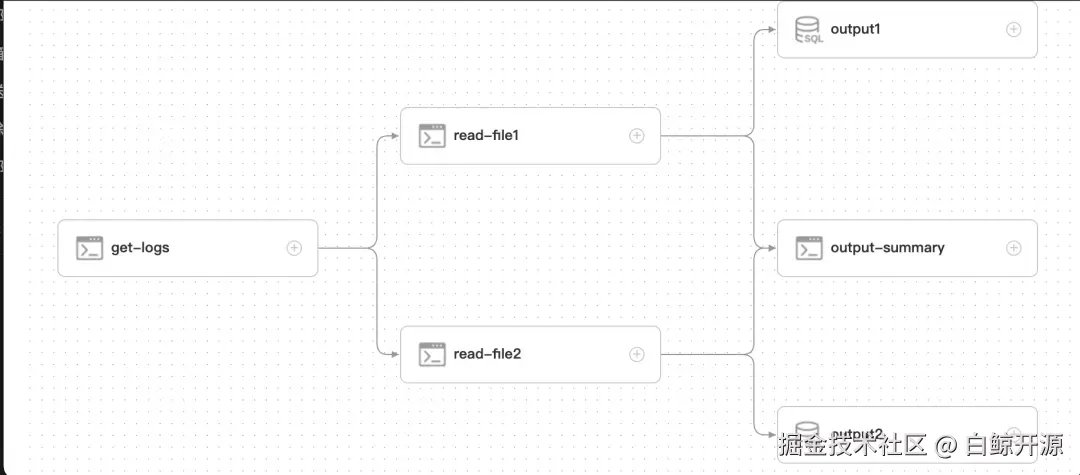
我们以最简单的页面拖拽为例,假如有一个最简单的场景,从一个文件获取日志数据get-logs,然后分别经过处理日志1 read-file1 和日志2 read-file2, 每个文件经过统计,输出到不同的数据表output1, output2,如果两个文件都读取成功,要汇聚总表 output-summary.
一般来说一个工作流不要超过30个任务,如果超过30个,建议将同类的任务使用子工作流汇总,比如get-logs这个流程可能需要有多个步骤(校验、清洗、分拆等),可以替换成子工作流来处理“准备日志文件”这个步骤,这样整个流程就会比较清晰。
当然实际的业务场景中,任务数量会更多,关系也会更复杂。例如:
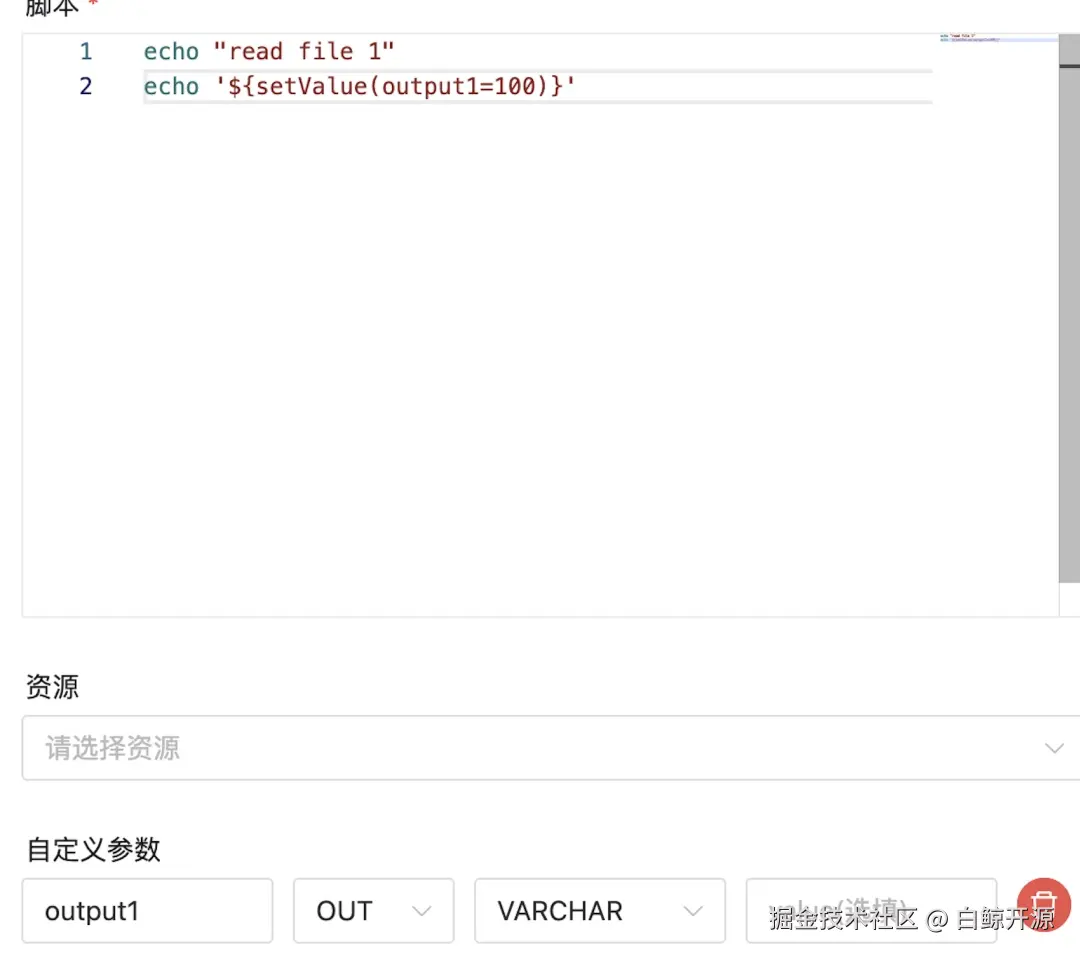
read-file1:
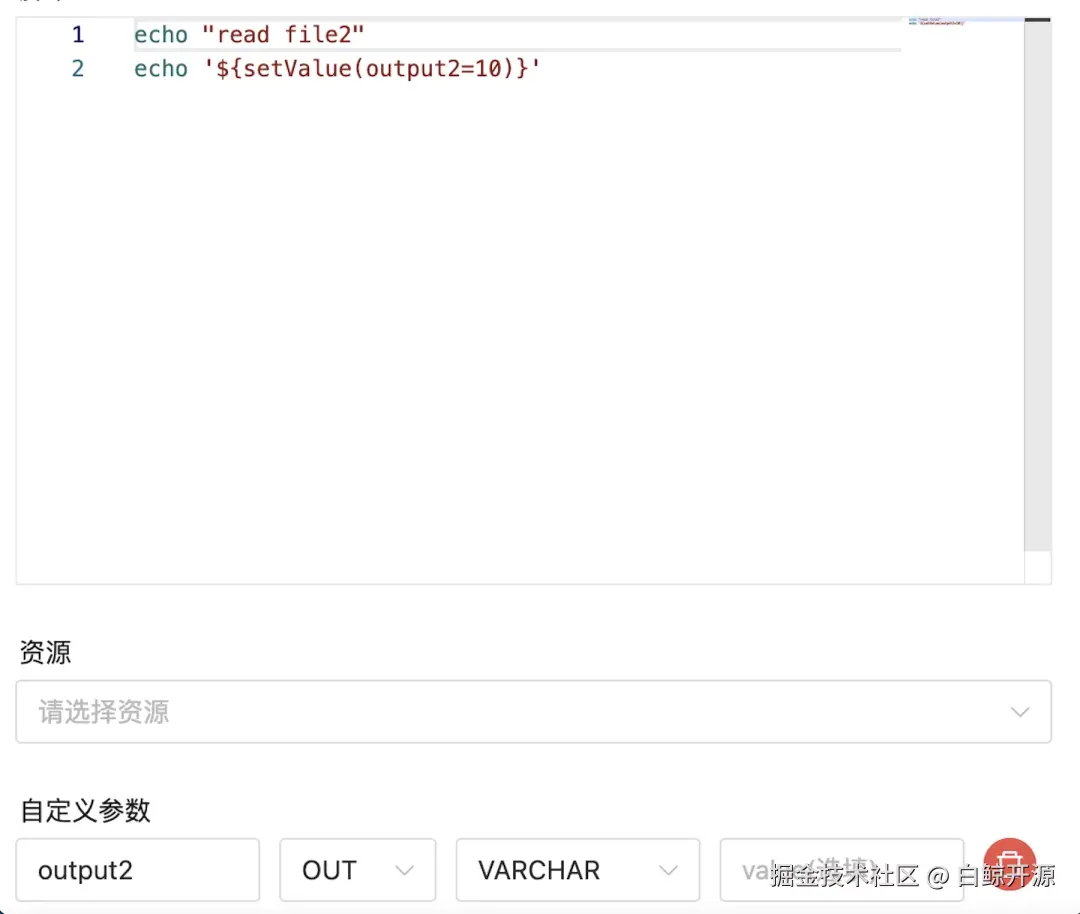
read-file2:
output-summary:
在DolphinScheduler的设计中,每次运行工作流,都会生成一条当前工作流的实例,并且这个实例和工作流定义是分离的,也就是说如果实例运行失败,我们针对实例的修改,不会影响到工作流定义的内容。不过在产品设计上,提供了修改实例可以同步到工作流定义的功能,让用户更加方便地修改工作流。
系统支持多种运行模式:
补数运行,就是在运行的时候,设置补数模式,处于补数模式时,用户在任务里使用的时间,会变成补数的时间。补数有两种选择:
运行完工作流以后,我们可以通过实例的DAG页面查看当前实例内任务的运行状况。并且通过右键某个任务实例,在页面上直接查看任务的运行日志,而不用去登录到服务器,或者其他系统中查找任务日志了。
如果工作流执行失败,我们可以对实例内失败的任务进行修改,然后再恢复运行,即可达到工作流断点执行的目的。
工作流实例也支持多种操作:暂停、停止、恢复执行、重跑、查看甘特图等。
以上是DolphinScheduler的工作流的一些用法,当然还有更多工作流使用的细节,限于篇幅,我们下次再详细讨论。但是通过以上的内容,我们可以知道使用DolphinScheduler的工作流:

