火柴人武林大会
156.74M · 2026-02-04

java 中 CompactStrings 选项的影响JDK 版本 | String 中的 value 字段的类型 | 代码 | 图 |
|---|---|---|---|
JDK 8 | char[] | value 字段 |  |
JDK 9 及之后 | byte[] | value 字段 | 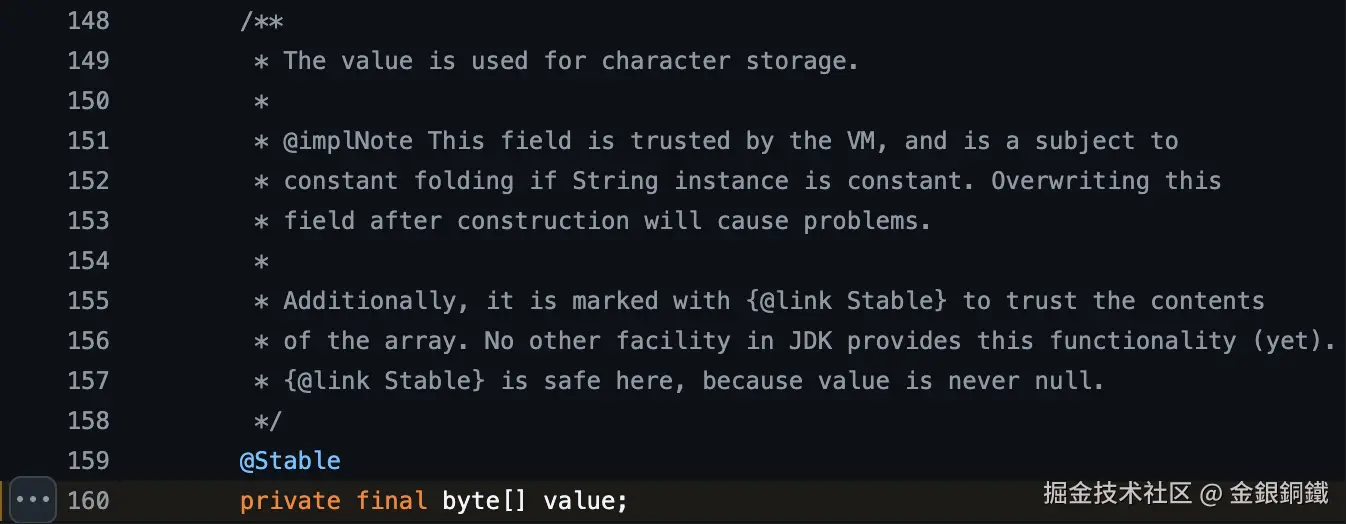 |
在 JDK 8 及之前,java 中的 String 使用 char[] 来保存 String 的各个 char。以 JDK 8 为例,在 String.java 中可以看到,String 中的 value 字段的类型是 char[]。
ASCII 和 Latin-1
ASCII 字符在 Unicode 字符中的编号范围是从 到 ,
Latin-1 字符(如上图所示,它包含了所有 ASCII 字符)的编号范围是从 到 。所以每个 Latin-1 字符都可以用 8 bit 来表示。
如果代码中只处理 Latin-1 字符,char[] 这样的存储方式会造成空间浪费。 例如在 "Hi" 这个 String 里,只有 'H', 'i' 2 个 char,在 char[] 类型的 value 字段中,需要用 bit(java 中的一个 char 大小为 16 bit)来存储它们。假如我们改用 byte[] 来保存 'H', 'i',那么只需要用 bit(java 中的一个 byte 大小为 8 bit)。
从 JDK 9 开始,String 内部改用 byte[] 来保存 char。对 Latin-1 范围的 char 而言,char 的高 8 bit 都是 0,所以可以只用一个 byte 来保存这个 char 的低 8 bit 而不会造成信息的损失。
以 'A' 这个 char 为例,它会占据 16 个 bit ⬇️
15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0 (Bit Index)
+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | (Bit Content)
+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+
'A' = 65 (Decimal)
如果我们忽略掉高 8 bit,那就可以这样保存 'A' ⬇️
7 6 5 4 3 2 1 0 (Bit Index)
+---+---+---+---+---+---+---+---+
| 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | (Bit Content)
+---+---+---+---+---+---+---+---+
'A' = 65 (Decimal)
请注意:虽然 String 中的 value 字段的类型发生了变化,但是从概念上讲,我们还是可以认为一个 String 实例是由若干个 char 组成的。至少有两个理由 ⬇️
String 类中的 charAt(int) 方法依然存在String 类中的 length() 方法的返回值仍旧和对应的 char 的数量相同所以本文还是会采用 “String 中的 char” 这类的说法。
对完全由 Latin-1 构成的 String 而言 ⬇️
CompactStrings 选项 | 中 value 字段的 length 与 的关系 | 解释 |
|---|---|---|
| 开启(⬅️ 这是默认的行为) | CompactStrings 选项开启时,每个 char 用 1 个 byte 来存储 (请注意,这里的大前提是: 中的每个 char 都来自 Latin-1) | |
| 关闭 | CompactStrings 选项关闭时,每个 char 用 2 个 byte 来存储 |
本文会用一些代码来验证 CompactStrings 选项的影响。
从 JDK 9 开始,String 类改为使用 byte[] 来存储 char。
CompactStrings 选项(⬅️ 这是默认行为)
String 完全由 Latin-1 的 char 组成,每个 char 占据 byte[] 中的 1 个元素,例如
'A' 会用 1 个 byte 来表示String 包含非 Latin-1 的 char 时,每个 char 占据 byte[] 中的 2 个元素,例如
'人' 会用 2 个 byte 来表示'A' 会用 2 个 byte 来表示-XX:-CompactStrings 来关闭 CompactStrings,则每个 char 占据byte[] 中的 2 个元素请将以下代码保存为 CompactStringTest.java ⬇️
import java.lang.reflect.Field;
public class CompactStringTest {
public static void main(String[] args) throws Exception {
Field valueField = String.class.getDeclaredField("value");
valueField.setAccessible(true);
Field coderField = String.class.getDeclaredField("coder");
coderField.setAccessible(true);
String decorator = "=".repeat(5);
for (String str : new String[]{"Hi", "人", "uD83CuDF34"}) {
System.out.printf("%s Details for [%s] %s%n", decorator, str, decorator);
byte[] value = (byte[]) valueField.get(str);
System.out.println("Each element of value:");
for (byte b : value) {
System.out.printf("0x%02X%n", b);
}
System.out.println();
byte coder = (byte) coderField.get(str);
System.out.println("Coder:");
System.out.println(coder);
System.out.println();
}
}
}
这段代码里会处理以下 3 个 String ⬇️
String 的内容 | 这个 String 由哪些 char 组成? | char 的数量 | 是否完全由 Latin-1 组成? |
|---|---|---|---|
"Hi" | 'H', 'i' | 2 | |
"人" | '人' | 1 | |
"uD83CuDF34" | 'uD83C', 'uDF34' | 2 |
以下命令可以编译 CompactStringTest.java ⬇️
javac CompactStringTest.java
我们可以用两种不同的方式来运行其中的 main(...) 方法。具体的命令如下 ⬇️
# 下面这一行是第一种方式
java --add-opens=java.base/java.lang=ALL-UNNAMED CompactStringTest
# 下面这一行是第二种方式
java --add-opens=java.base/java.lang=ALL-UNNAMED -XX:-CompactStrings CompactStringTest
在我的电脑上,运行结果如下 ⬇️ (在您的电脑上,byte[] 中的值的顺序可能会不同)
===== Details for [Hi] =====
Each element of value:
0x48
0x69
Coder:
0
===== Details for [人] =====
Each element of value:
0xBA
0x4E
Coder:
1
===== Details for [] =====
Each element of value:
0x3C
0xD8
0x34
0xDF
Coder:
1
===== Details for [Hi] =====
Each element of value:
0x48
0x00
0x69
0x00
Coder:
1
===== Details for [人] =====
Each element of value:
0xBA
0x4E
Coder:
1
===== Details for [] =====
Each element of value:
0x3C
0xD8
0x34
0xDF
Coder:
1
| 标题 | coder 的值 | byte[] 中每个元素的值 | 图示 | 补充说明 |
|---|---|---|---|---|
| 第一种方式 | 0 (和 Latin-1 对应) | 0x48, 0x69 | 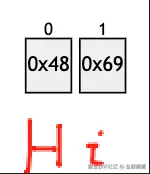 | H 和 0x48 对应, i 和 0x69 对应 |
| 第二种方式 | 1 (和 UTF-16 对应) | 0x48, 0x00, 0x69, 0x00 | 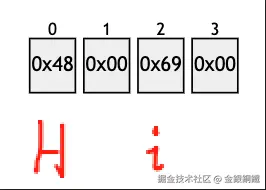 | H 和 0x48 对应, i 和 0x69 对应 |
"人" 的结果对比两种方式的输出一样,所以写到下表的同一行里了 ⬇️
| 标题 | coder 的值 | byte[] 中每个元素的值 | 图示 | 补充说明 |
|---|---|---|---|---|
| 第一种方式/第二种方式 | 1 (和 UTF-16 对应) | 0xBA, 0x4E | 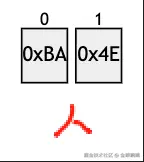 | 人 和 0x4EBA 对应,在我的电脑上,value 字段中字节的顺序是先 0xBA,后 0x4E |
"uD83CuDF34" 的结果对比两种方式的输出一样,所以写到下表的同一行里了 ⬇️
| 标题 | coder 的值 | byte[] 中每个元素的值 | 图示 | 补充说明 |
|---|---|---|---|---|
| 第一种方式/第二种方式 | 1 (和 UTF-16 对应) | 0x3C, 0xD8, 0x34, 0xDF | 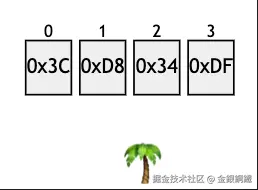 | 在 CompactStringTest.java 中是用 uD83C, uDF34 这两个 char 来表示的。 |
关于 这个 code point,我多解释一下。在 CompactStringTest.java 中, 是用以下 2 个 char 表示的 ⬇️
uD83CuDF34char | 对应的 byte 的值 | 在我的电脑上,value 中存储的 byte 的顺序 |
|---|---|---|
uD83C | 0xD8 和 0x3C | 先存 0x3C,后存 0xD8 |
uDF34 | 0xDF 和 0x34 | 先存 0x34,后存 0xDF |

