鬼畜钢琴
126.99M · 2026-04-16

PDF 文件因其优秀的兼容性和格式保持能力而被广泛使用,但随着内容的增加,特别是包含大量高清图片时,文件体积往往会变得非常庞大。过大的 PDF 文件不仅占用存储空间,还会导致邮件发送困难、网页加载缓慢以及传输效率低下等问题。
本文将介绍如何使用 Python 和 Spire.PDF 库来压缩 PDF 文件,通过优化文档结构和压缩图像数据,在保持可接受的质量前提下显著减小文件体积。
压缩 PDF 文件大小在实际工作中有着重要的应用价值:
通过 Python 自动化压缩过程,可以批量处理大量 PDF 文件,显著提升工作效率。
首先,需要安装 Spire.PDF for Python 库。可以通过 pip 命令轻松完成安装:
pip install Spire.PDF
安装完成后,即可在 Python 脚本中导入该库并使用其提供的压缩功能。
Spire.PDF 提供了多层次的压缩机制,包括文档级别的压缩设置和页面级别的图像压缩。通过结合使用这些方法,可以实现最佳的压缩效果。
以下代码展示了如何对 PDF 文档进行全方位压缩:
from spire.pdf.common import *
from spire.pdf import *
# 定义输入和输出文件路径
inputFile = "/input/示例文档.pdf"
outputFile = "/output/压缩.pdf"
# 加载 PDF 文档
doc = PdfDocument()
doc.LoadFromFile(inputFile)
# 禁用增量更新,确保压缩生效
doc.FileInfo.IncrementalUpdate = False
# 设置压缩级别为最佳压缩
doc.CompressionLevel = PdfCompressionLevel.Best
# 再次确认禁用增量更新
doc.FileInfo.IncrementalUpdate = False
# 遍历所有页面,压缩其中的图像
imageHelper = PdfImageHelper()
for i in range(doc.Pages.Count):
page = doc.Pages[i]
if page is not None:
# 获取页面中的所有图像信息
imagesInfo = imageHelper.GetImagesInfo(page)
if len(imagesInfo) > 0:
# 尝试压缩每个图像
for j in range(len(imagesInfo)):
imagesInfo[j].TryCompressImage()
# 保存压缩后的文档
doc.SaveToFile(outputFile)
doc.Close()
这段代码展示了 PDF 压缩的三个关键步骤:
文档级压缩设置:
CompressionLevel 设置为 PdfCompressionLevel.Best,启用最高级别的压缩算法IncrementalUpdate(增量更新),确保压缩后的内容完全重写文件而非追加图像压缩处理:
PdfImageHelper 工具类获取每页中的图像信息TryCompressImage() 方法尝试压缩每个图像,该方法会智能判断是否可以安全压缩保存优化结果:
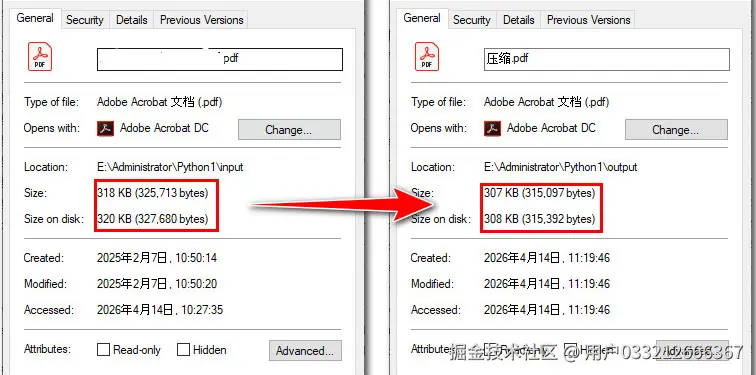
SaveToFile 保存压缩后的文档,由于禁用了增量更新,生成的文件将只包含压缩后的内容这种综合压缩策略可以同时优化文本内容和图像数据,通常能够将文件大小减少 50% 到 80%,具体效果取决于原始文档的内容构成。
理解 PDF 压缩的工作原理有助于更好地应用这些技术:
文档级压缩主要作用于 PDF 的内部结构,包括:
通过设置 CompressionLevel 为 Best,Spire.PDF 会自动应用所有这些优化技术。
图像通常是 PDF 文件中占用空间最大的部分。TryCompressImage() 方法会执行以下操作:
这种方法的优势在于它是智能压缩——只有在可以安全降低质量的情况下才会执行压缩,避免过度处理导致视觉质量明显下降。
PDF 压缩功能在实际工作中有广泛的应用场景:
当需要处理大量 PDF 文件时,可以编写批处理函数来自动化压缩过程。以下是一个实用的批量压缩示例:
from spire.pdf.common import *
from spire.pdf import *
import os
def CompressPdfFolder(input_folder: str, output_folder: str):
"""压缩文件夹中的所有 PDF 文件"""
# 如果输出文件夹不存在则创建
if not os.path.exists(output_folder):
os.makedirs(output_folder)
# 统计信息
total_original = 0
total_compressed = 0
# 遍历输入文件夹中的所有文件
for filename in os.listdir(input_folder):
if filename.endswith(".pdf"):
# 构建完整的文件路径
input_path = os.path.join(input_folder, filename)
output_filename = filename
output_path = os.path.join(output_folder, output_filename)
# 获取原始文件大小
original_size = os.path.getsize(input_path)
total_original += original_size
# 执行压缩
doc = PdfDocument()
doc.LoadFromFile(input_path)
doc.FileInfo.IncrementalUpdate = False
doc.CompressionLevel = PdfCompressionLevel.Best
# 压缩图像
imageHelper = PdfImageHelper()
for i in range(doc.Pages.Count):
page = doc.Pages[i]
if page is not None:
imagesInfo = imageHelper.GetImagesInfo(page)
if len(imagesInfo) > 0:
for j in range(len(imagesInfo)):
imagesInfo[j].TryCompressImage()
doc.SaveToFile(output_path)
doc.Close()
# 获取压缩后文件大小
compressed_size = os.path.getsize(output_path)
total_compressed += compressed_size
# 计算压缩率
ratio = (1 - compressed_size / original_size) * 100
print(f"已压缩: {filename}")
print(f" 原始大小: {original_size / 1024:.2f} KB")
print(f" 压缩后: {compressed_size / 1024:.2f} KB")
print(f" 压缩率: {ratio:.1f}%n")
# 输出总体统计
overall_ratio = (1 - total_compressed / total_original) * 100
print("=" * 50)
print(f"总计:")
print(f" 原始总大小: {total_original / 1024 / 1024:.2f} MB")
print(f" 压缩后总大小: {total_compressed / 1024 / 1024:.2f} MB")
print(f" 整体压缩率: {overall_ratio:.1f}%")
# 使用示例
input_folder = "./PDF文档"
output_folder = "./压缩后PDF"
CompressPdfFolder(input_folder, output_folder)
这个函数不仅实现了批量压缩,还提供了详细的压缩统计信息,包括每个文件的压缩率和整体压缩效果,便于评估压缩策略的有效性。
在发送包含 PDF 附件的邮件前,自动压缩文件以确保不超过邮件服务商的大小限制(通常为 25MB)。
网站管理员可以定期压缩网站上托管的 PDF 文档,加快用户下载速度并减少带宽消耗。
企业可以将历史文档库进行压缩处理,在不影响查阅的前提下大幅减少存储成本。
在进行 PDF 压缩时,以下技巧可以帮助获得更好的结果:
通过本文的介绍,我们学习了使用 Python 和 Spire.PDF 库压缩 PDF 文件的方法:
CompressionLevel 设置文档级压缩级别IncrementalUpdate 确保压缩完全生效PdfImageHelper 和 TryCompressImage() 压缩页面中的图像这些技术为解决 PDF 文件过大问题提供了有效的方案。掌握这些技能后,您将能够高效地优化 PDF 文件大小,提升文档传输和存储的效率,同时保持良好的视觉质量。

