鬼畜钢琴
126.99M · 2026-04-16

在 Java 生态中,Spring AI 已经成为开发者拥抱大模型时代的首选利器。很多人用它写出了酷炫的对话机器人、智能客服,甚至成功接入了私有知识库。
然而,“知其然更要知其所以然”。当我们熟练地敲下 ChatClient.builder().build() 时,底层到底发生了什么?
ChatClient 是怎么跨越无状态的 HTTP,记住历史对话的?今天,我们就基于最新的 Spring AI 1.1.4 版本,拨开代码的迷雾,进行一次深度的底层原理解析!
spring-ai-model - 核心抽象接口:ChatModel, EmbeddingModel, VectorStore
spring-ai-client-chat - ChatClient fluent API,Advisor SPI
spring-ai-vector-store - VectorStore 接口,ANTLR4 Filter 表达式解析器
spring-ai-rag - RAG 实现:QueryTransformer, DocumentRetriever, DocumentJoiner
spring-ai-commons - 通用工具类
spring-ai-retry - 重试机制
┌─────────────────────────────────────────────────────────────┐
│ Application │
└─────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────┐
│ spring-ai-client-chat │
│ ChatClient │ Advisor SPI │ MessageChatMemoryAdvisor │
└─────────────────────────────────────────────────────────────┘
│
┌─────────────────┼─────────────────┐
▼ ▼ ▼
┌───────────────────┐ ┌──────────────┐ ┌────────────────────┐
│ spring-ai-rag │ │spring-ai-model│ │spring-ai-vector-store│
│ RetrievalAugment- │ │ ChatModel │ │ VectorStore │
│ ationAdvisor │ │ EmbeddingModel│ │ FilterExpression │
└───────────────────┘ └──────────────┘ └────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────┐
│ models/{provider} (具体实现) │
│ OpenAiChatModel │ OpenAiEmbeddingModel │ ... │
└─────────────────────────────────────────────────────────────┘
ChatModel 是所有对话模型的鼻祖(万物起源)。它的核心职责极其纯粹:接收提示词(Prompt),返回响应(ChatResponse) 。
public interface ChatModel extends Model<Prompt, ChatResponse>, StreamingChatModel {
// 核心同步方法
ChatResponse call(Prompt prompt);
// 便捷方法:字符串直接转 Prompt,这就是适配器模式的体现
default String call(String message) {
return this.call(new Prompt(new UserMessage(message)));
}
}
亮点解析:在类定义中,它巧妙地使用了多继承,同时继承了 Model 泛型接口和 StreamingChatModel 流式接口,在高度抽象的同时保证了能力的完整性。
为了应对大模型打字机效果的流式输出,Spring AI 专门抽离了流式接口:
@FunctionalInterface
public interface StreamingChatModel extends StreamingModel<Prompt, ChatResponse> {
// 便捷方法:自动包装 Prompt,并直接提取流式文本
default Flux<String> stream(String message) {
return stream(new Prompt(new UserMessage(message)))
.map(chatResponse -> chatResponse.getResult().getOutput().getText());
}
// 核心流式方法
Flux<ChatResponse> stream(Prompt prompt);
}
关键特性:
@FunctionalInterface 标记,完美支持 Java Lambda 表达式。Flux<ChatResponse>,全面拥抱响应式流(Reactive Streams)规范。大模型本质上无法直接理解文字,它们只认识“向量”(多维数组)。EmbeddingModel 的职责就是将文本转化为 float[]。在 AbstractEmbeddingModel 基类中,隐藏着一个极其巧妙的细节:
// 缓存维度数,避免每次请求都调用 API 去计算
protected final AtomicInteger embeddingDimensions = new AtomicInteger(-1);
public int dimensions() {
if (this.embeddingDimensions.get() < 0) {
// 如果不知道维度,先拿 "Test" 跑一次 API 探探路,然后缓存起来
this.embeddingDimensions.set(dimensions(this, "Test"));
}
return this.embeddingDimensions.get();
}
通过这种“探路+缓存”机制,框架在处理复杂的向量库操作时,避免了频繁的元数据查询,极大地节约了 Token 和网络请求时间。
看完了接口,我们来看看真正干活的实现类(比如 OpenAI 的客户端)。这里隐藏着重试机制与工具调用的核心奥秘:
Java
public class OpenAiChatModel implements ChatModel {
@Override
public ChatResponse call(Prompt prompt) {
Prompt requestPrompt = buildRequestPrompt(prompt);
return this.internalCall(requestPrompt, null);
}
// 内部递归调用,处理工具执行
private ChatResponse internalCall(Prompt prompt, ChatResponse previousChatResponse) {
// 1. 构建底层 API 请求
ChatCompletionRequest request = createRequest(prompt, false);
// 2. 观察上下文(Micrometer 链路追踪指标)
ChatModelObservationContext observationContext = ChatModelObservationContext.builder()...;
// 3. 执行重试和观察
return ChatModelObservationDocumentation.CHAT_MODEL_OPERATION
.observation(...).observe(() -> {
// 使用 Spring RetryTemplate 包裹网络请求,提升容错率
ResponseEntity<ChatCompletion> completionEntity =
this.retryTemplate.execute(ctx ->
this.openAiApi.chatCompletionEntity(request, headers));
// 4. 转换为 Spring AI 标准的 Generation 格式
List<Generation> generations = choices.stream()
.map(choice -> buildGeneration(choice, metadata, request))
.toList();
// 5. 【核心】处理工具执行 (Function Calling)
if (this.toolExecutionEligibilityPredicate.isToolExecutionRequired(...)) {
// 内部执行本地 Java 方法
ToolExecutionResult toolExecutionResult =
this.toolCallingManager.executeToolCalls(prompt, response);
// ️ 隐式递归调用:将工具执行结果重新塞回 Prompt,再次请求大模型
return this.internalCall(new Prompt(...), response);
}
return response;
});
}
}
底层基建亮点总结:
| 特性 | 底层实现方式 | 业务价值 |
|---|---|---|
| 重试机制 | 使用 RetryTemplate 包装 API 调用 | 极大提升网络抖动和限流时的容错率 |
| 监控打点 | 接入 Micrometer ObservationRegistry | 配合可观测性组件,轻松实现调用链路追踪 |
| 工具调用 | internalCall() 内部隐式递归 | 实现多次 Tool Call 直到任务完成,对业务透明 |
| 流式处理 | Flux.deferContextual() + MessageAggregator | 优雅合并零散的 Chunk 数据 |
日常开发中,我们赋予大模型“记忆”的代码非常简单:
ChatClient.prompt("我刚才问了啥?")
.advisors(new MessageChatMemoryAdvisor(chatMemory))
.call()
.content();
为什么加了一个 Advisor,无状态的 AI 就有了记忆?因为 Spring AI 设计了一套基于 Deque(双端队列)的弹出式拦截器链 (DefaultAroundAdvisorChain) 。
核心设计:基于 Deque 的弹出式链遍历
public ChatClientResponse nextCall(ChatClientRequest chatClientRequest) {
if (this.callAdvisors.isEmpty()) {
throw new IllegalStateException("No CallAdvisors available");
}
// 弹出下一个 advisor 执行
var advisor = this.callAdvisors.pop();
return AdvisorObservationDocumentation.AI_ADVISOR
.observation(this.observationConvention, ...)
.observe(() -> {
// 当前 advisor 调用链(链包含剩余的 advisors)
var response = advisor.adviseCall(chatClientRequest, this);
return response;
});
}
当请求发出时,犹如过五关斩六将:
before() 阶段:MessageChatMemoryAdvisor 发挥作用。它会根据 ConversationId 从 ChatMemory(支持 InMemory 或者 Jdbc 落库,比如 PostgreSQL、MySQL)里捞出之前的几十条对话,悄悄塞进本次的 Prompt 前面。ChatModelCallAdvisor 触发真实的大模型 API 请求。after() 阶段:拿到回复后,拦截器栈回溯,MessageChatMemoryAdvisor 再次拦截,把 AI 的最新回答存入数据库,完成闭环。执行顺序:
[Request Path - before() methods]
1. toolCallAdvisor.before() --> 初始化工具调用循环
2. ragAdvisor.before() --> 检索文档,增强查询
3. memoryAdvisor.before() --> 添加对话历史
[Terminal - 实际 AI 调用]
4. ChatModelCallAdvisor.adviseCall() --> 调用 chatModel.call()
[Response Path - after() methods]
5. memoryAdvisor.after() --> 存储助手回复到记忆
6. ragAdvisor.after() --> 添加文档到响应元数据
7. toolCallAdvisor.after() --> 检测并执行工具调用,循环直到完成
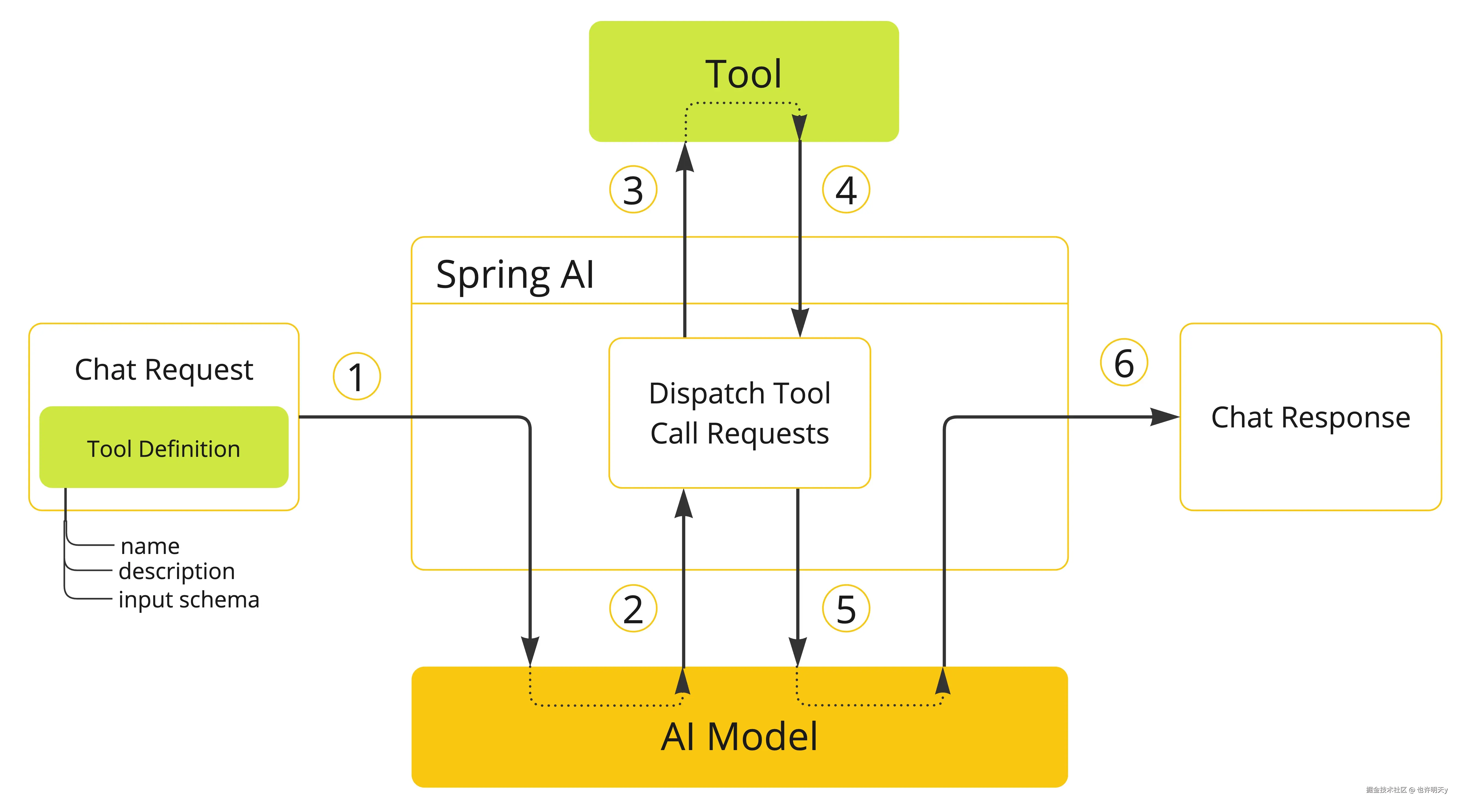
ToolCallAdvisor 实现了一个极其精妙的递归执行循环。
非流式执行流程:
public ChatClientResponse adviseCall(ChatClientRequest request, CallAdvisorChain chain) {
// 1. 禁用模型内部的工具执行,由 Advisor 处理
var optionsCopy = (ToolCallingChatOptions) request.prompt().getOptions().copy();
optionsCopy.setInternalToolExecutionEnabled(false);
boolean isToolCall;
do {
// 2. 调用链中的下一个 advisor(最终到达 ChatModel)
ChatClientResponse response = chain.nextCall(processedRequest);
// 3. 检查响应中是否包含工具调用
isToolCall = response.chatResponse().hasToolCalls();
if (isToolCall) {
// 4. 执行工具调用
ToolExecutionResult toolResult = this.toolCallingManager
.executeToolCalls(processedRequest.prompt(), response.chatResponse());
if (toolResult.returnDirect()) {
break; // 直接返回工具结果,跳过 LLM
}
// 5. 获取下一轮指令,继续循环
instructions = doGetNextInstructionsForToolCall(...);
}
} while (isToolCall);
return doFinalizeLoop(response, chain);
}
假设你注册了一个 @Bean 或者 java.util.function.Function 作为工具:
ToolCallAdvisor 拦截请求,修改配置,告诉底层的 OpenAiChatModel:“遇到工具调用别自己瞎处理,抛出来给我”。{"name": "getWeather", "args": {"city": "北京"}}。ToolCallAdvisor 捕获到这个特殊的响应(response.chatResponse().hasToolCalls() == true),启动一个 do-while 循环。ToolCallingManager 找到你写的 getWeather 方法,通过反射传入“北京”,拿到结果“晴天,25度”。ToolResponseMessage,再次向 OpenAI 发起请求。isToolCall == false),结果返回给用户。对于流式(Stream)响应,情况更复杂,因为工具调用的 JSON 是一段段返回的。Spring AI 在底层的 OpenAiStreamFunctionCallingHelper 中实现了极其复杂的 merge(合并)逻辑,把散落的 chunks 拼成完整的工具调用参数。
public final class ToolContext {
public static final String TOOL_CALL_HISTORY = "TOOL_CALL_HISTORY";
private final Map<String, Object> context;
// 工具可访问的内容
public Map<String, Object> getContext() { return this.context; }
// 获取工具执行前的对话历史
public List<Message> getToolCallHistory() { ... }
}
上下文构建:
private static ToolContext buildToolContext(Prompt prompt, AssistantMessage assistantMessage) {
Map<String, Object> toolContextMap = new HashMap<>();
// 用户提供的上下文
if (prompt.getOptions() instanceof ToolCallingChatOptions options
&& !CollectionUtils.isEmpty(options.getToolContext())) {
toolContextMap.putAll(options.getToolContext());
}
// 添加对话历史
toolContextMap.put(ToolContext.TOOL_CALL_HISTORY,
buildConversationHistoryBeforeToolExecution(prompt, assistantMessage));
return new ToolContext(Collections.unmodifiableMap(toolContextMap));
}
大模型在调用本地工具(比如查订单)时,往往不能只传一个“订单号”,工具方法可能还需要知道“当前登录的用户是谁?”、“用户的鉴权 Token 是什么?”。这就需要一套机制来跨越层层拦截器,把业务上下文透传给底层工具。
ToolContext 类Map<String, Object> context:这是一个极其灵活的 Map 容器,相当于档案袋的内胆。你可以往里面塞任何业务所需的对象(比如 HTTP Request、User Session 等),工具在执行时可以直接取用。TOOL_CALL_HISTORY 常量:这是框架预留的一个专属 VIP 席位。它专门用来存放工具执行前的完整对话历史。这样一来,工具在处理逻辑时,不仅知道当前的参数,还能“回头看”用户之前到底聊了什么。我们在检索文档时,不仅要看向量相似度,还要做属性过滤,比如:只搜索“状态为活跃”且“年份大于 2020”的文档。 Spring AI 提供了类似 MyBatis-Plus 的 DSL 语法:
var b = new FilterExpressionBuilder();
var exp = b.and(b.eq("country", "UK"), b.gte("year", 2020));
内置了一个 ANTLR4 语法分析器!你可以直接传字符串:"country == 'UK' && year >= 2020"。 底层通过 FilterExpressionTextParser 解析生成一棵抽象语法树(AST)。然后,框架使用不同的 Converter,把这棵树翻译成各种向量数据库认识的方言(比如转换成 Pinecone 专属的 JSON 结构,或者通过 SpEL 进行内存过滤)。
用户输入: "country == 'UK' && year >= 2020"
│
▼
FilterExpressionTextParser.parse(text)
├── ANTLR4 Lexer/Parser
└── FilterExpressionVisitor.visit()
│
▼
Filter.Expression AST
│
┌───────┴───────┐
▼ ▼
SimpleVectorStore Provider Converter
直接评估 (Pinecone/SpEL/...)
│ │
▼ ▼
Boolean 结果 提供商原生查询
前面我们在拦截器中看到了 MessageChatMemoryAdvisor,那这些历史对话具体是存在哪里、又是如何管理的呢?这就不得不提 Spring AI 中极其优雅的记忆抽象设计。
在架构上,Spring AI 采用了经典的门面接口与底层仓储分离的设计:
门面接口:ChatMemory 这是面向业务开发者的顶层接口,相当于大模型的“海马体”(短期记忆区)。它只关心最核心的四个动作:增加、批量增加、查询、清空。
public interface ChatMemory {
String DEFAULT_CONVERSATION_ID = "default";
void add(String conversationId, Message message);
void add(String conversationId, List<Message> messages);
List<Message> get(String conversationId);
void clear(String conversationId);
}
底层实现:ChatMemoryRepository 光有接口不行,记忆最终得落地。ChatMemoryRepository 负责实际的存储逻辑。框架内置了基于内存的 InMemoryChatMemory,同时也支持通过扩展接入 Redis、PostgreSQL 等持久化数据库,确保服务重启后 AI 不会“失忆”。
public interface ChatMemoryRepository {
List<String> findConversationIds();
List<Message> findByConversationId(String conversationId);
void saveAll(String conversationId, List<Message> messages);
void deleteByConversationId(String conversationId);
}
痛点:大模型的上下文窗口(Token)是极其宝贵且有上限的。如果不加节制地把几百轮历史对话全塞进 Prompt 里,不仅每次调用的 API 费用会原地起飞,还极易触发“Token 爆栈”(Context Window Exceeded)错误。
为此,Spring AI 提供了 MessageWindowChatMemory(滑动窗口记忆)来精准控场。它的底层驱逐算法(Eviction Algorithm)遵循着极其严密的逻辑:
SystemMessage 永远不会被丢弃。如果动态添加了新的 SystemMessage,框架会自动覆盖旧的,确保 AI 始终明确“自己是谁”。DEFAULT_MAX_MESSAGES)。当对话超出这个限制时,框架会无情地从最旧的消息开始执行 remove 剔除操作。我们来看一眼这段冷酷但高效的剔除算法源码:
// 计算需要剔除多少条旧消息
int messagesToRemove = processedMessages.size() - this.maxMessages;
int removed = 0;
for (Message message : processedMessages) {
// 核心逻辑:如果是 SystemMessage,或者剔除名额已经用完,则保留该消息
if (message instanceof SystemMessage || removed >= messagesToRemove) {
trimmedMessages.add(message);
} else {
// 否则,无情剔除最旧的常规对话
removed++;
}
}
public ChatClientRequest before(ChatClientRequest request, AdvisorChain chain) {
// Step 0: 从用户消息和历史创建 Query
Query originalQuery = Query.builder()
.text(request.prompt().getUserMessage().getText())
.history(request.prompt().getInstructions())
.context(context)
.build();
// Step 1: 通过 QueryTransformer 链变换查询
Query transformedQuery = originalQuery;
for (var queryTransformer : this.queryTransformers) {
transformedQuery = queryTransformer.apply(transformedQuery);
}
// Step 2: 可选的查询扩展
List<Query> expandedQueries = this.queryExpander != null
? this.queryExpander.expand(transformedQuery)
: List.of(transformedQuery);
// Step 3: 并行检索文档
Map<Query, List<List<Document>>> documentsForQuery = expandedQueries.stream()
.map(query -> CompletableFuture.supplyAsync(() -> getDocumentsForQuery(query)))
.toList().stream().map(CompletableFuture::join)
.collect(Collectors.toMap(Map.Entry::getKey, entry -> List.of(entry.getValue())));
// Step 4: 连接多个查询的文档
List<Document> documents = this.documentJoiner.join(documentsForQuery);
// Step 5: 后处理文档
for (var documentPostProcessor : this.documentPostProcessors) {
documents = documentPostProcessor.process(originalQuery, documents);
}
// Step 6: 用文档上下文增强查询
Query augmentedQuery = this.queryAugmenter.augment(originalQuery, documents);
// Step 7: 更新请求
return request.mutate()
.prompt(request.prompt().augmentUserMessage(augmentedQuery.text()))
.context(context).build();
}
很多文章把 RAG 讲得很玄乎,实际上在 RetrievalAugmentationAdvisor 这个拦截器的源码中,把 RAG 清晰地定义为了 7 个 Pipeline(流水线)步骤:
Step 0 - 初始化 Query:把你输入的问题(文本)和前面的聊天历史封装成一个 Query 对象。
Step 1 - Transformer (查询变换) :用户的原始问题往往指代不明(比如“那它有什么缺点?”)。RewriteQueryTransformer 会利用大模型,结合上下文,把问题重写为适合去向量库搜索的独立句子(如“Spring AI 的缺点是什么?”)。
Step 2 - Expander (查询扩展) :[可选] 把一个复杂问题拆分成多个子问题,提高检索命中率。
Step 3 - Retriever (并发检索) :拿着变换后的查询,通过 VectorStoreDocumentRetriever 去向量数据库发起相似度搜索。如果前面裂变了多个问题,这里会使用 CompletableFuture 进行异步并发检索。
Step 4 - Joiner (文档聚合) :把搜回来的所有片段(Documents)扔进 DocumentJoiner,默认通过 ID 去重,并按照相似度得分(Score)倒序排列。
Step 5 & 6 - Augmenter (提示词增强) :这是最关键的一步。把刚才高分命中、排好序的文档内容,塞进一个系统预设的 Prompt 模板中:
Context information is below.
---------------------
{此处填入检索到的文档片段}
---------------------
Given the context information and no prior knowledge, answer the query: {用户的原始问题}
Step 7 - 执行:带着被厚厚参考资料包裹的终极 Prompt,正式向大模型发起调用。
至此,大模型就能看着你私有库里的资料,一本正经地回答问题了!
RAG 完整流程图
用户消息
│
▼
[QueryTransformer 链]
│
▼
[QueryExpander] (可选)
│
▼
[DocumentRetriever] --> VectorStoreDocumentRetriever --> VectorStore.similaritySearch()
│
▼
[DocumentJoiner] --> 去重 + 按分数排序
│
▼
[DocumentPostProcessor] (可选)
│
▼
[QueryAugmenter] --> 用文档上下文增强用户提示
│
▼
LLM (携带增强提示的调用)
spring-ai-model) :抹平了 OpenAI、Ollama、千问等各种模型提供商的接口差异。Advisor SPI) :把记忆(Memory)、外挂工具(Tools)、检索增强(RAG)全部做成了非侵入式的切面,像搭积木一样随插随拔。spring-ai-rag) :将看似黑盒的 RAG 拆解为 Transformer、Retriever、Augmenter 等标准组件,支持极细粒度的自定义。源码地址:github.com/spring-proj…
| 组件 | 文件路径 |
|---|---|
| ChatModel | spring-ai-model/src/main/java/org/springframework/ai/chat/model/ChatModel.java |
| StreamingChatModel | spring-ai-model/src/main/java/org/springframework/ai/chat/model/StreamingChatModel.java |
| EmbeddingModel | spring-ai-model/src/main/java/org/springframework/ai/embedding/EmbeddingModel.java |
| OpenAiChatModel | models/spring-ai-openai/src/main/java/org/springframework/ai/openai/OpenAiChatModel.java |
| ChatClient | spring-ai-client-chat/src/main/java/org/springframework/ai/chat/client/ChatClient.java |
| DefaultChatClient | spring-ai-client-chat/src/main/java/org/springframework/ai/chat/client/DefaultChatClient.java |
| Advisor | spring-ai-client-chat/src/main/java/org/springframework/ai/chat/client/advisor/api/Advisor.java |
| DefaultAroundAdvisorChain | spring-ai-client-chat/src/main/java/org/springframework/ai/chat/client/advisor/DefaultAroundAdvisorChain.java |
| ToolCallAdvisor | spring-ai-client-chat/src/main/java/org/springframework/ai/chat/client/advisor/ToolCallAdvisor.java |
| ToolCallback | spring-ai-model/src/main/java/org/springframework/ai/tool/ToolCallback.java |
| VectorStore | spring-ai-vector-store/src/main/java/org/springframework/ai/vectorstore/VectorStore.java |
| SearchRequest | spring-ai-vector-store/src/main/java/org/springframework/ai/vectorstore/SearchRequest.java |
| FilterExpressionBuilder | spring-ai-vector-store/src/main/java/org/springframework/ai/vectorstore/filter/FilterExpressionBuilder.java |
| Filters.g4 | spring-ai-vector-store/src/main/antlr4/org/springframework/ai/vectorstore/filter/antlr4/Filters.g4 |
| ChatMemory | spring-ai-model/src/main/java/org/springframework/ai/chat/memory/ChatMemory.java |
| MessageWindowChatMemory | spring-ai-model/src/main/java/org/springframework/ai/chat/memory/MessageWindowChatMemory.java |
| RetrievalAugmentationAdvisor | spring-ai-rag/src/main/java/org/springframework/ai/rag/advisor/RetrievalAugmentationAdvisor.java |
| VectorStoreDocumentRetriever | spring-ai-rag/src/main/java/org/springframework/ai/rag/retrieval/search/VectorStoreDocumentRetriever.java |
| ContextualQueryAugmenter | spring-ai-rag/src/main/java/org/springframework/ai/rag/generation/augmentation/ContextualQueryAugmenter.java |

