人类游乐园
106.63M · 2026-04-16

作者:来自 Elastic David Pilato
刚接触Elasticsearch吗?欢迎参加我们的Elasticsearch入门网络研讨会。你也可以开始免费云试用,或者现在就在你的本地机器上试试Elastic。
在管理Elasticsearch索引时,您可能需要验证一个索引中所有文档是否也存在于另一个索引中,例如在重新索引操作、迁移或数据管道之后。Elasticsearch没有内置“diff”命令,但正确的做法取决于一个关键问题:你的文档ID在两个索引之间是否稳定?
假设你有两个索引,index-a(源)和 index-b(目标),你想找出所有存在于 index-a 但缺失于 index-b 的文档。
一种简单的方法是同时查询两个索引并在内存中比较结果,但这种方法无法扩展。Elasticsearch 旨在处理数百万文档,一次性加载所有数据并不现实。
有两种场景:
接下来我们分别讲解这两种情况。
本文中的所有示例都使用escli,这是一个用 Rust 编写的小型命令行接口(CLI),对 Elasticsearch REST API 进行了封装。它从环境变量中读取你的集群 URL 和凭据,因此你无需在每个命令中重复认证 headers。
为了说明这一点的重要性,下面是一个使用原始 curl 的典型 _search 调用:
curl -X GET \ -H "Authorization: ApiKey $ELASTIC_API_KEY" \ -H "Content-Type: application/json" \ -d '{"query":{"term":{"user.id":"kimchy"}}}' \ "$ELASTICSEARCH_URL/my-index-000001/_search" 使用 escli,相同的请求变为:
./escli search --index my-index-000001 <<< '{"query":{"term":{"user.id":"kimchy"}}}' 凭据存储在.env文件中,escli 会自动加载 —— 无需在每次调用时使用-H "Authorization: ...",也降低了在 shell 历史中泄露敏感信息的风险。请求体通过 stdin(<<<)传入,这使得可以轻松地通过 jq 动态构建并传递多行 JSON。
在进行完整扫描之前,先快速统计每个索引的文档数量。如果数量相同,两个索引很可能已经同步,就不需要再进行扫描。
./escli count --index index-a./escli count --index index-b
_count API 返回:
{ "count": 1000000 } 如果计数不同,则继续进行完整比较。
如果两个索引对同一文档使用相同的 _id,例如因为你使用像 emp_no 这样的业务主键而不是生成的UUID来索引文档,你可以通过一次 _reindex 调用来查找并修复缺失的文档。
当数据具有自然主键时,使用有意义的字段作为 _id(而不是随机 UUID)是一种最佳实践。这意味着:
使用 _reindex 并设置 op_type=create,会尝试将源索引中的每个文档创建到目标索引中。如果目标中已存在相同 _id 的文档,Elasticsearch 会将其报告为 version_conflict 并继续处理,而不会覆盖已有文档。设置 conflicts=proceed 可以让 API 在遇到冲突时继续执行,而不是在第一个冲突时中止。
./escli reindex <<< '{ "source": { "index": "index-a" }, "dest": { "index": "index-b", "op_type": "create" }, "conflicts": "proceed"}' 响应会准确地告诉你发生了什么:
{ "total": 1000000, "created": 49594, "version_conflicts": 950406, "failures": []} 无需扫描,无需客户端比较,无需中间文件。所有操作都在服务端 完成,在一个包含 100 万文档的数据集中大约只需 6 秒。
有时你无法依赖 _id。一个在写入时生成 ID 的数据管道,每次处理同一条记录都会分配不同的 _id。如果 index-a 和 index-b 由这样的两个管道生成,同一个员工记录在一个索引中可能是 _id: "abc123",而在另一个索引中是 _id: "xyz789",即使底层数据完全相同。
在这种情况下,你需要基于内容而不是 ID 来匹配文档。关键是识别一组字段,它们组合在一起构成一个唯一的业务键。
对于员工数据集,一个合理的业务键是(first_name、last_name、birth_date)。如果在 index-b 中不存在具有这三个字段相同组合的文档,则 index-a 中的该文档就被视为 “缺失”。
在源索引上打开一个时间点 (PIT)以获取一致的快照,然后分页 遍历,仅获取业务键字段:
./escli open_point_in_time index-a 5m# → { "id": "46ToAwMDaWR..." } ./escli search <<< '{ "size": 10000, "_source": ["first_name", "last_name", "birth_date"], "pit": { "id": "46ToAwMDaWR...", "keep_alive": "5m" }, "sort": [{ "_shard_doc": "asc" }]}' 排序键 _shard_doc 是全索引分页最有效的排序方式:它使用内部 Lucene 文档顺序,无额外开销。使用 search_after 重复,直到响应中没有命中。完成后务必关闭 PIT:
./escli close_point_in_time <<< '{"id": "46ToAwMDaWR..."}' 对于源文档的每一页,通过 _msearch 检查目标索引。为每页源文档构建一个 _msearch 请求,每个文档一个子查询。每个子查询在三个业务键字段上使用 bool/must 并设置 size: 0;我们只需要知道是否存在匹配,不需要检索文档本身。
./escli msearch << 'EOF'{"index": "index-b"}{"size":0,"query":{"bool":{"must":[{"term":{"first_name.keyword":"Alice1"}},{"term":{"last_name.keyword":"Smith"}},{"term":{"birth_date":"1985-03-12"}}]}}}{"index": "index-b"}{"size":0,"query":{"bool":{"must":[{"term":{"first_name.keyword":"Bob2"}},{"term":{"last_name.keyword":"Jones"}},{"term":{"birth_date":"1990-07-24"}}]}}}EOF 响应包含每个子查询对应的一条记录,顺序与子查询相同:
{ "responses": [ { "hits": { "total": { "value": 1 } } }, { "hits": { "total": { "value": 0 } } } ]} total.value == 0 表示 index-b 中没有文档匹配该业务键;该文档缺失。从源页收集对应的 _id。
如果业务键包含日期字段,你可以将源数据按日期分片,并将每个分片作为独立任务运行。每个分片打开自己的 PIT,并在 birth_date 上使用范围过滤器,运行自己的 msearch 循环,并将结果写入单独文件。父脚本并行启动所有分片,并在所有任务完成后汇总结果。
但根据你的用例,你也可能希望按其他字段分片;例如,如果有 team 字段,可以为每个团队运行一个分片。关键是找到一个字段,使数据可以被分割成合理均匀的块,从而可以并行处理。
[compare] Launching 5 slices in parallel... → Slice 1: 1960-01-01 → 1969-12-31 ✅ — 244408 checked, 12207 missing → Slice 2: 1970-01-01 → 1979-12-31 ✅ — 243624 checked, 12212 missing → Slice 3: 1980-01-01 → 1989-12-31 ✅ — 243551 checked, 11921 missing → Slice 4: 1990-01-01 → 1999-12-31 ✅ — 243895 checked, 11991 missing → Slice 5: 2000-01-01 → 2009-12-31 ✅ — 24522 checked, 1263 missing
为了验证这些方法,演示在 index-a 中生成 1,000,000 条文档,并故意在 index-b 中跳过约 5%(49,594 条缺失文档),然后运行完整的 compare → reindex 循环。
MacBook M3 Pro 上的结果:
Comparison (compare-indices.sh):
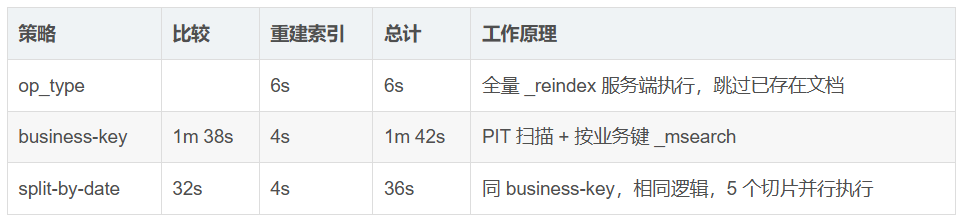
op_type=create 方法最快,因为所有操作都在服务端执行,无需客户端扫描。split-by-date策略通过并行处理将 business-key 耗时从 1m 38s 缩短到 36s:对于两个 1M 文档索引之间的比较,效果不错。
Are _id values stable between both indices?├── Yes → _reindex with op_type=create (6s, server-side)└── No → Do you have a reliable business key? ├── Yes, simple scan is fast enough → business-key (1m 42s) └── Yes, and you need more speed → split-by-date (36s, parallel)
Elasticsearch 不提供原生的索引差异命令,但正确的策略取决于你的数据模型:
完整示例,包括数据集生成、比较脚本和重建索引脚本,可在https://github.com/dadoonet/blog-compare-indices/获取。
原文:https://www.elastic.co/search-labs/blog/elasticsearch-index-comparison
,
