
荣耀文档
80.56M · 2026-04-14

在此背景下,由香港大学数据科学实验室(HKUDS)开源的 Nanobot 框架应运而生。它以“少即是多”为核心理念,仅用约 4,000 行核心代码便实现了一套完整、可生产级别的 AI Agent 系统。本文将从技术架构、核心模块、部署实战、应用场景及生态定位等维度,对 Nanobot 进行深度剖析,为开发者提供一份系统性的技术参考。
Nanobot 的诞生并非为了替代重量级企业级框架,而是为了解决 “个人 AI 助手落地最后一公里” 的工程难题。其设计哲学可归纳为三点:
在 AI 基础设施日益完善的当下,Nanobot 选择了一条“向下兼容、向上轻量”的技术路线,精准切中了个人开发者与轻量级自动化场景的需求空白。
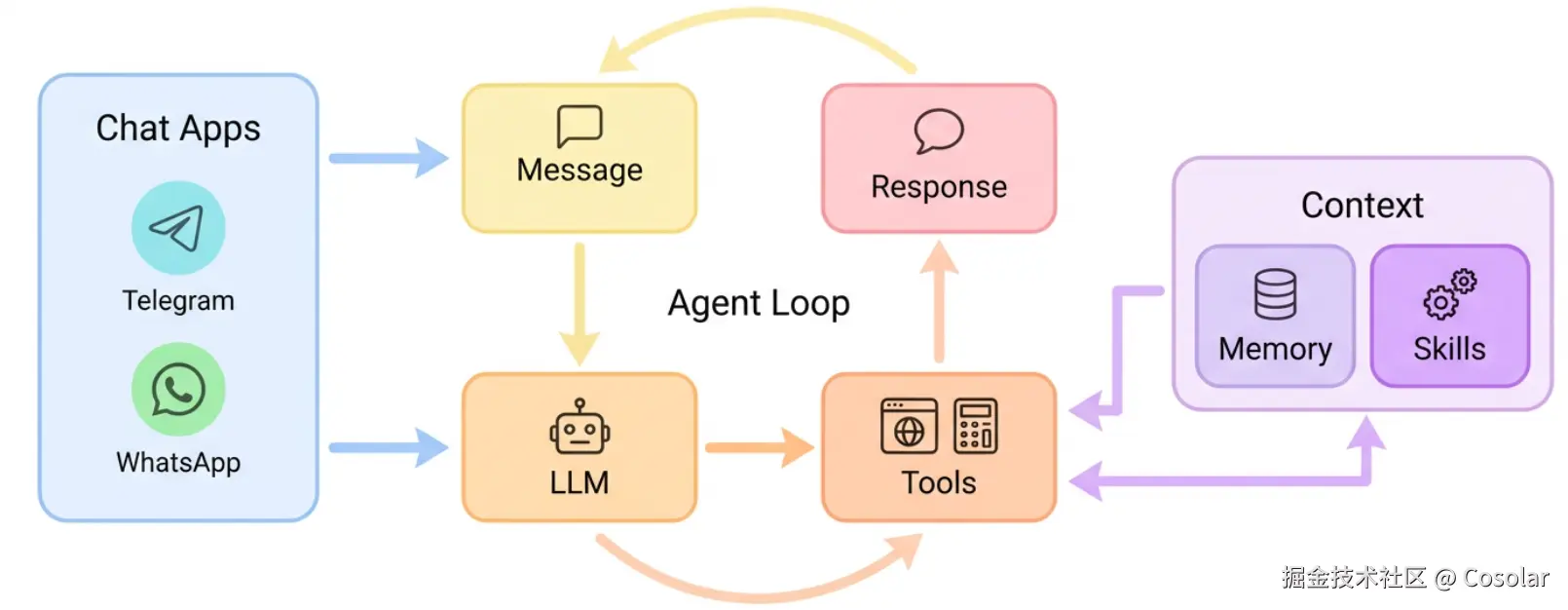
Nanobot 的架构设计遵循经典的 Agent Loop(智能体循环) 范式,但在模块划分与数据流管理上做了大量工程化优化。整体架构可划分为四大核心子系统:Agent Loop 驱动引擎、ContextBuilder 上下文构建器、Memory System 记忆系统、Skills System 技能系统。
Agent Loop 是 Nanobot 的“心脏”,负责协调用户输入、大模型推理、工具执行与结果反馈的完整生命周期。其工作流程如下:
用户消息 → 消息路由(Router) → 上下文组装(ContextBuilder)
→ LLM 推理(Provider 抽象层) → 工具解析与执行(Tool Executor)
→ 结果注入循环 → 最终回复生成 → 落盘记忆 → 返回用户
与传统框架不同,Nanobot 的 Loop 采用 同步阻塞与异步回调混合 的设计。对于耗时较长的工具(如 Shell 命令执行、网页爬虫),框架会将其放入后台线程或异步任务队列,避免阻塞主消息流。同时,Loop 内置了 重试机制与超时熔断,当 LLM 返回格式非法或工具执行失败时,会自动触发修复提示或降级策略,显著提升了系统的鲁棒性。
上下文管理是 Agent 系统的核心难点。Nanobot 通过 ContextBuilder 模块实现了高度可配置的上下文注入策略:
ContextBuilder 会根据用户意图动态检索相关长期记忆条目与匹配的技能文档,按优先级插入上下文。这种“按需加载”策略大幅提升了上下文利用率。Nanobot 的记忆系统采用 三层架构,兼顾实时性与持久化能力:
Nanobot 最具创新性的设计之一是其 基于 Markdown 的 Skills 系统。开发者无需编写复杂代码,只需创建 .md 文件即可为 Agent 扩展新能力:
# 技能名称:代码审计助手
## 触发条件
当用户请求包含"review code", "检查漏洞", "安全扫描"时激活。
## 可用工具
- `run_shell`: 执行静态分析脚本
- `read_file`: 读取目标源码
## 执行规范
1. 优先读取文件内容
2. 调用 `run_shell` 执行审计命令
3. 输出结构化报告(漏洞类型、行号、修复建议)
框架在启动时会扫描 skills/ 目录,解析 Markdown 结构并注册到技能路由表中。当用户输入匹配触发条件时,Agent 会自动加载对应规范,指导 LLM 按步骤调用工具。这种声明式设计极大降低了能力扩展门槛,同时保证了 LLM 行为的可控性。
Nanobot 仅依赖 Python 标准库与少数核心第三方包(如 requests, pydantic, openai 兼容客户端)。冷启动内存占用通常低于 150MB,CPU 占用率极平稳。即使在配置较低的云服务器(如 1C2G)或本地树莓派上,也能流畅运行 24/7 的个人助手服务。
框架采用 Provider 抽象层 与 Platform Adapter 模式,实现模型与平台的解耦:
model 字段与 API Base URL 即可无缝切换。Nanobot 预置 8+ 核心工具,覆盖日常自动化高频场景:
filesystem:安全目录下的文件读写、目录遍历shell:受限命令执行(支持白名单与超时限制)web_search:聚合搜索引擎接口(支持 Bing、DuckDuckGo、Serper)scheduler:Cron 定时任务管理messaging:跨平台消息推送与转发code_executor:安全沙箱内的 Python/JS 代码运行工具调用遵循标准的 Function Calling 协议,LLM 输出 JSON 后由框架解析、校验、执行,并将结果结构化返回给模型进行下一步推理。
# 克隆源码
git clone
cd nanobot
# 使用 editable 模式安装,便于后续开发调试
pip install -e .
# 一键初始化配置与目录结构
nanobot onboard
执行 onboard 后,框架会在 ~/.nanobot/ 下生成标准目录:config.json(主配置)、memory/(记忆存储)、skills/(技能库)、logs/(运行日志)。
config.json 是系统的控制中枢,典型配置如下:
{
"providers": {
"openrouter": {
"apiKey": "sk-or-v1-xxxxxxxxxxxx",
"baseUrl": "https://openrouter.ai/api/v1"
},
"qwen": {
"apiKey": "sk-xxxxxxxxxxxx",
"baseUrl": "https://dashscope.aliyuncs.com/compatible-mode/v1"
}
},
"agents": {
"defaults": {
"model": "anthropic/claude-sonnet-4",
"temperature": 0.3,
"maxTokens": 4096,
"toolCallingStrategy": "function_calling"
}
},
"memory": {
"storageType": "json",
"vectorDbPath": "./memory/vectors",
"retentionDays": 30,
"dailyJournalHour": 23
},
"platforms": {
"telegram": {
"botToken": "123456:ABC-DEF1234ghIkl-zyx57W2v1u123ew11",
"allowedUserIds": [123456789]
}
}
}
关键配置说明:
providers:多模型凭证管理,支持多 Key 负载均衡与 fallback。toolCallingStrategy:可选 function_calling(推荐)或 react_prompt(兼容不支持 Function Calling 的模型)。memory.retentionDays:自动清理过期记忆,控制存储体积。platforms.telegram.allowedUserIds:安全白名单,防止未授权调用。启动服务只需执行 nanobot agent 或 nanobot serve --platform telegram。日志默认输出至终端与文件,支持 DEBUG 级别追踪完整推理链路。
结合 shell、filesystem 与 web_search 工具,Nanobot 可充当本地开发环境的“结对编程伙伴”。开发者通过聊天界面提交需求(如“重构 auth 模块的 JWT 校验逻辑”),Agent 会自动读取相关代码、执行静态检查、生成补丁文件,并提示人工 Review。配合 Git Hook 与 CI/CD 脚本,可实现轻量级自动化工作流。
通过长期记忆与 dailyJournalHour 定时任务,Nanobot 可在每晚自动汇总当日技术笔记、会议要点、待办进度,生成结构化 Markdown 报告。结合向量检索,用户可随时提问“上周关于 Kubernetes 网络策略的讨论结论是什么?”,系统精准召回相关记忆段落,实现真正的“第二大脑”。
利用多平台适配器,企业可将 Nanobot 部署为统一消息中枢。用户从 T@elegrimm、飞书或网页端发送请求,Agent 根据意图分类调用内部 API(查询订单、重置密码、生成报表),并将结果原路返回。通过 Skills 系统定义标准回复模板与权限边界,可在保障数据安全的前提下实现 7×24 小时自动化响应。
| 维度 | Nanobot | LangChain / LlamaIndex | AutoGen |
|---|---|---|---|
| 代码规模 | ~4,000 行 | 数万行 | 数万行 |
| 学习曲线 | 低(1-2 天上手) | 中高(需掌握组件链) | 高(多智能体编排) |
| 上下文管理 | 动态组装+自动摘要 | 手动构建或基础封装 | 依赖外部组件 |
| 适用场景 | 个人助手、轻量自动化、研究实验 | 企业级 RAG、复杂 Pipeline | 多智能体协作仿真 |
| 扩展方式 | Markdown Skills + 工具注册 | 代码级自定义 Chain/Agent | 自定义 Agent 类与消息协议 |
Nanobot 并非追求“大而全”,而是聚焦“小而精”。它在 可维护性、部署成本、透明度 上具有显著优势,非常适合个人开发者、独立研究者、小型团队用于快速验证 Agent 想法或构建专属数字助理。若需构建复杂的多智能体博弈系统或企业级数据流水线,仍建议结合更重量级的框架使用。
Nanobot 以极简架构重构了个人 AI 助手的开发范式。它证明了:一个优秀的 Agent 框架不需要庞大的依赖树与复杂的抽象层,清晰的模块边界、高效的上下文管理、声明式的扩展机制,同样能支撑起生产级的自动化任务。其开源代码不仅是工具,更是学习 LLM Agent 底层原理的绝佳教材。
当前局限:复杂工作流编排能力相对薄弱;插件生态仍在成长期;对超长上下文模型的优化尚有提升空间。
未来演进方向:社区已规划多模态输入支持(图像/语音)、强化学习驱动的工具选择优化、WebUI 可视化配置面板、以及标准化 Skill 插件市场。随着 LLM 推理成本持续下降与端侧算力提升,Nanobot 有望成为边缘 AI 与个人数字助理领域的基础设施。
如果你正在寻找一个透明、轻量、易定制的 AI Agent 起点,Nanobot 绝对值得纳入技术选型清单。从一行配置到一个懂你的数字助手,技术民主化的脚步,正通过这些开源项目加速到来。

