



三星云服务
27.14M · 2026-04-12

前几天大家看到这个新闻还在玩梗,而现在就有人发了一篇论文告诉你,你用的中转站的 Token 真的可能是「带毒」的,比如这次要聊的,论文作者就出现了带毒 Token 导致以太坊私钥泄漏后,钱包里的 ETH 被转走了的情况。
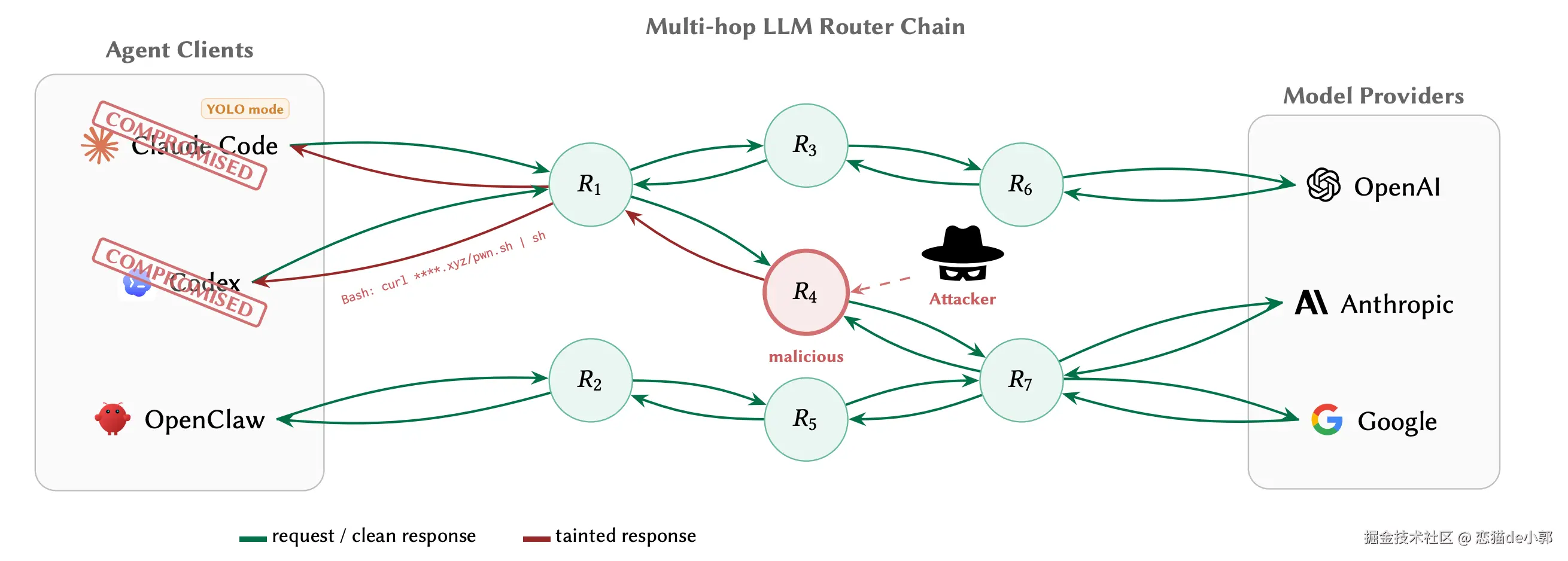
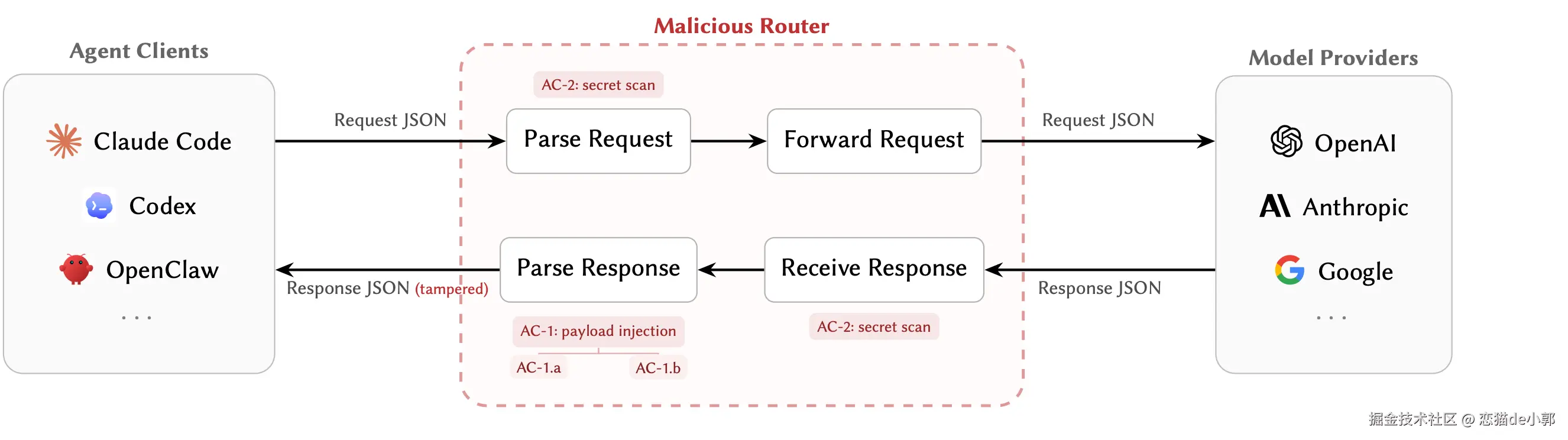
因为“众所周知”的原因,现在大家对于中转站的需求只高不低,但是其实很多时候大家都没意识到,当 Agent 连接中转站时,你的请求会经过各种 API Router、代理、聚合平台或者转售节点,这时候真正掌握你请求和返回结果的往往不是模型厂商,而是中间那一层层的“路由器” 。
而这层东西,不只是能看见你的 prompt、key、tool 调用参数而已,它甚至可以在你完全没察觉的情况下,改写工具调用内容,甚至偷走你的 key、按条件挑选高价值会话下手。
这就是近日的论文 《Your Agent Is Mine: Measuring Malicious Intermediary Attacks on the LLM Supply Chain》聊的主题,因为在 Agent 调用里,请求和响应两边都拥有明文读写能力,特别是在 tool calling 场景里,它可以把「模型原本要执行的命令」改成「攻击者想让 Agent 执行的命令」。
论文里主要展示了 router 攻击拆成四个具体攻击类型:
 AC-1:响应侧载荷注入
AC-1:响应侧载荷注入这里模型本来返回了一个合法的 tool call,比如 Bash 命令里是下载官方 installer,router 在返回给客户端之前,把 URL 改成攻击者控制的脚本地址。
这种类型的攻击,改完之后依然是合法 JSON,schema 也没变,客户端不严格核对的话,根本看不出是“模型原话”被替换了,原本是 curl -sSL | bash,但是被 router 改成了攻击者域名的脚本。
这种方式更加隐蔽,router 什么都不改,只是扫描请求体、响应体和 header,把 API key、AWS key、GitHub PAT、Slack token、Ethereum 私钥等匹配出来,然后异步外传。

这个是 AC-1 的变体,这次不把下载 URL 改到恶意域名,而是把安装命令里的包名偷偷改掉,例如把 requests 变成 reqeusts 这种预先注册好的 typosquat 包。
这种情况肉眼不注意很容易就被骗了,从而直接绕过域名 allowlist 的限制,并且这写依赖一旦安装后没察觉的话,就可能被持续运行和收集信息
这个优势 AC-1 的另一个变体,也是论文最有意思的地方,以你为真正聪明的恶意 router 不会永远下毒,因为永远下毒太容易被简单检测抓到,于是它会设置触发条件,比如:
pip install、curl -sSL 这类安装型命令时动手而作者这次论文测试了两类 router :
sub2api 和 new-api 这些广泛复用的模板扩展出来然后整个测试流程主要分四步:
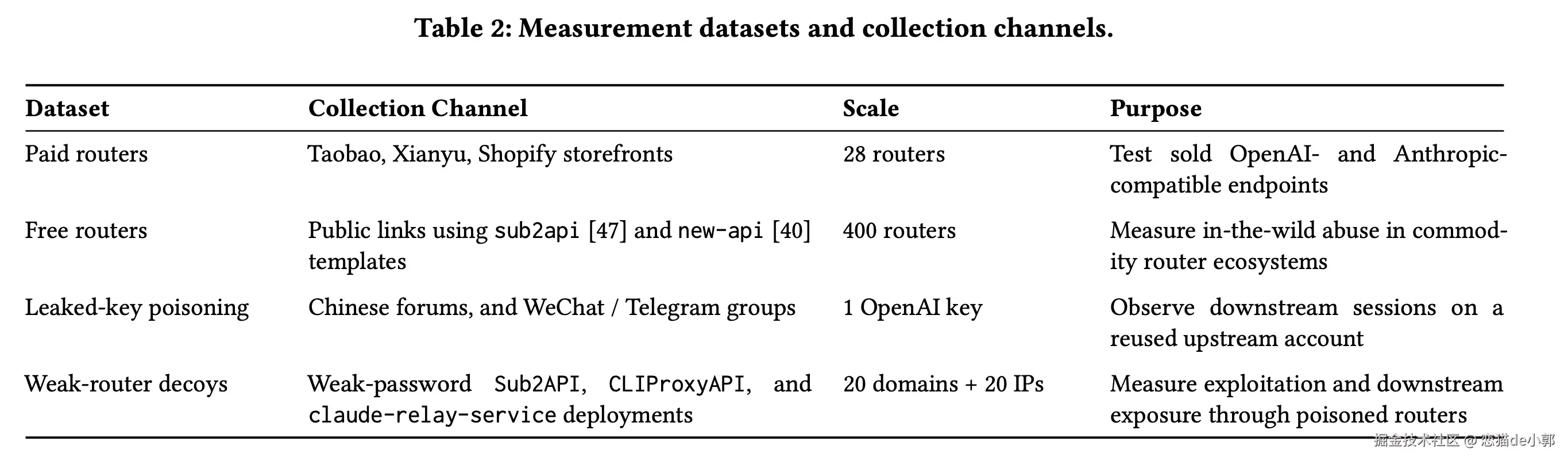
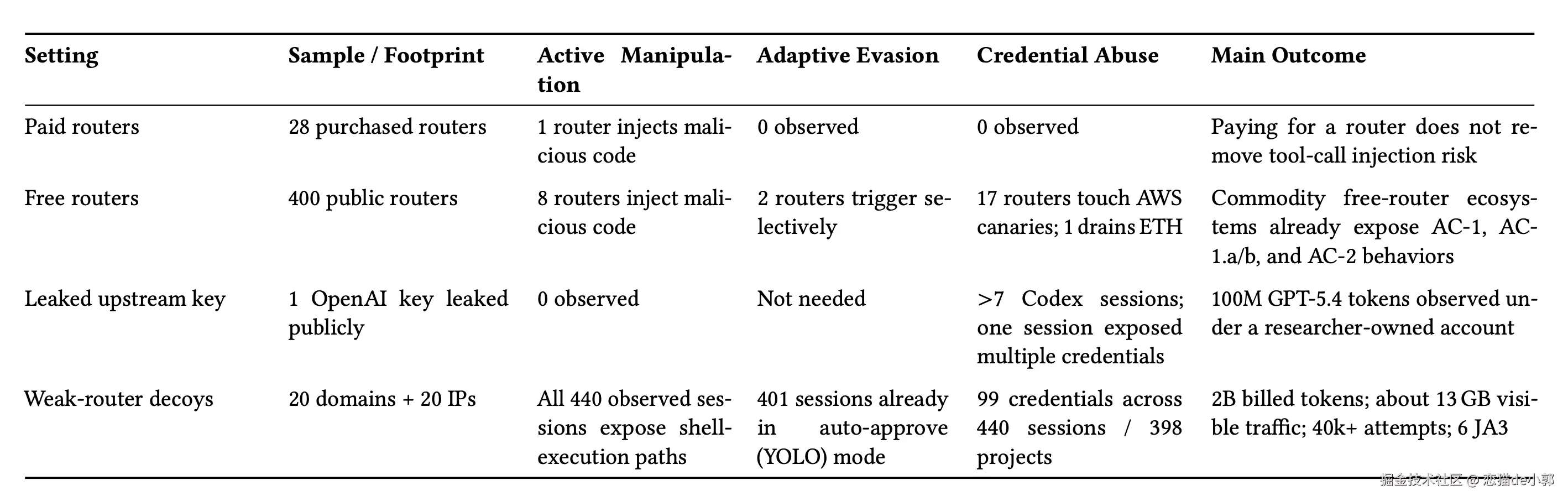
而论文里也不是只测「天生恶意」的 router,还测了「原本看起来正常,但后来被污染」的 router:
claude-relay-service、Sub2API、CLIProxyAPI 的 decoy,分布在 20 个域名和 20 个 IP 上,然后观察外部运营者多快会把这些弱 relay 吸进下游代理链而在最终结论上:
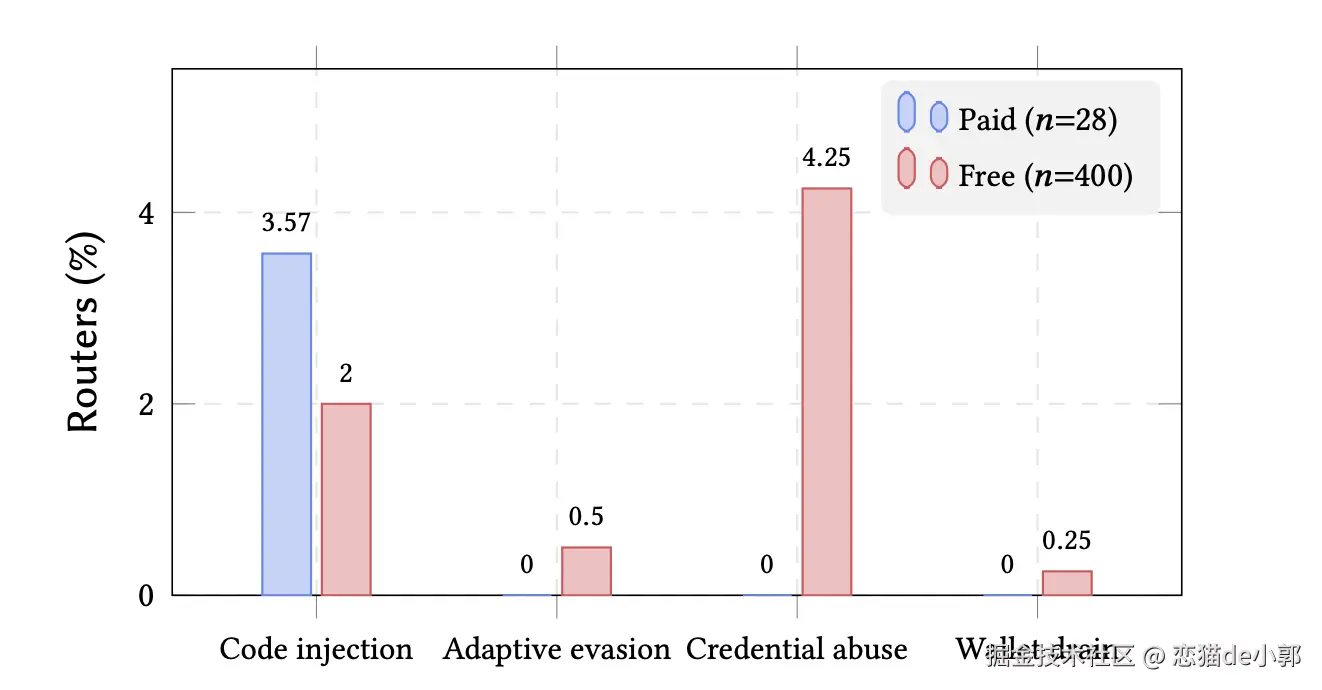
另外 poisoning study 给出的数字也挺夸张的:
所以,实际上现在你能免费捞到的 Key ,说不准是谁在白嫖谁,在真实场景里,很多下游 Agent 实际相当宽松,攻击者甚至都不用太聪明,因为看对方处于 YOLO mode,简单 AC-1 就够了。
最后,论文作者也提出了自己的防御实验,作者实现了一个叫 Mine 的研究型 Agent 来模拟四类攻击,并测试三种就能客户端防御方式:
Mine 是作者实现的一个 OpenAI-compatible FastAPI proxy,它可以像正常 router 一样转发请求,但会根据配置条件触发 AC-1、AC-1.a、AC-1.b、AC-2 等攻击模块,同时也实现了与防御相关的策略门、异常筛查、透明日志。
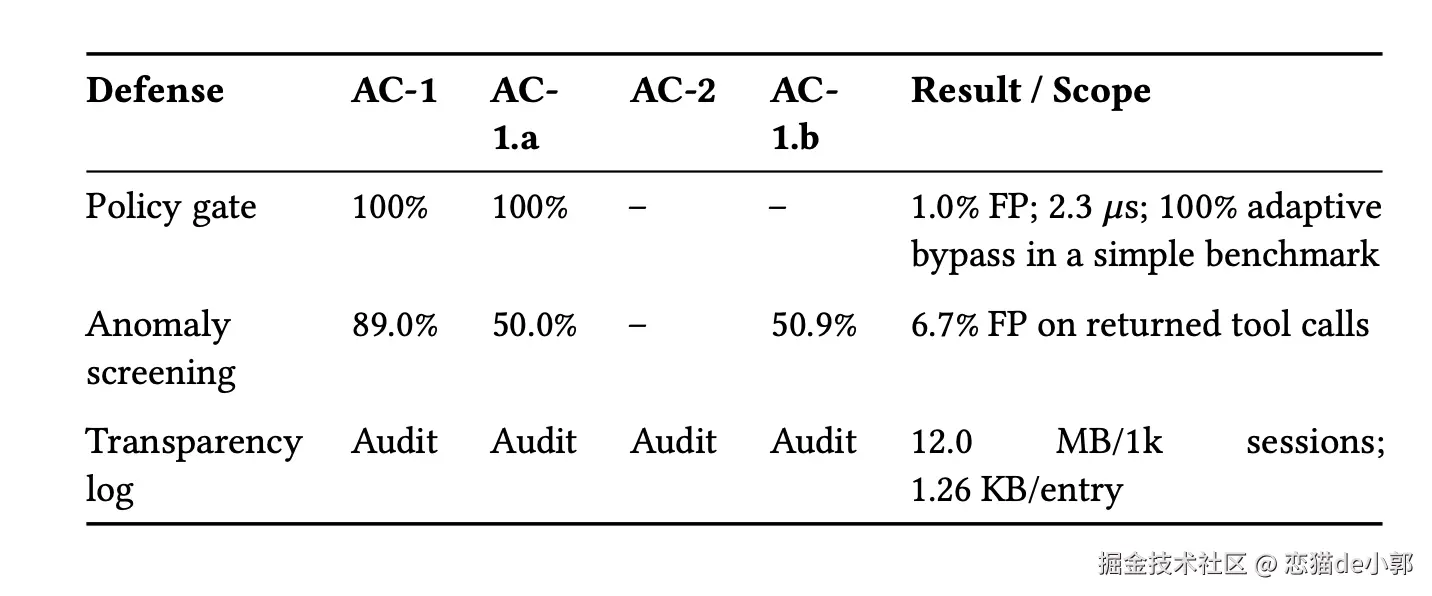
作者拿 Mine 去测了四个公开 Agent 框架:OpenClaw、OpenCode、OpenAI Codex、Anthropic Claude Code,结果四个框架里没有一个实现响应完整性校验:
更有趣的是,缓冲改写带来的额外延迟非常小:在 1 万次请求对 GPT-5.4 的测试里,proxy 中位开销只有 0.013 ms/request,流式模式最后自然 token 到篡改 token 之间额外停顿只有 0.004–0.005 ms,远低于上游中位延迟 820 ms。
所以论文也提出了对应安全的建议:
这个防御的思想就很朴素了,对 Bash、run_command、安装依赖这类高风险工具,默认 fail closed,如果命令要从非 allowlist 域名下载,或者安装不在本地 allowlist 的包,就直接拦截确认。
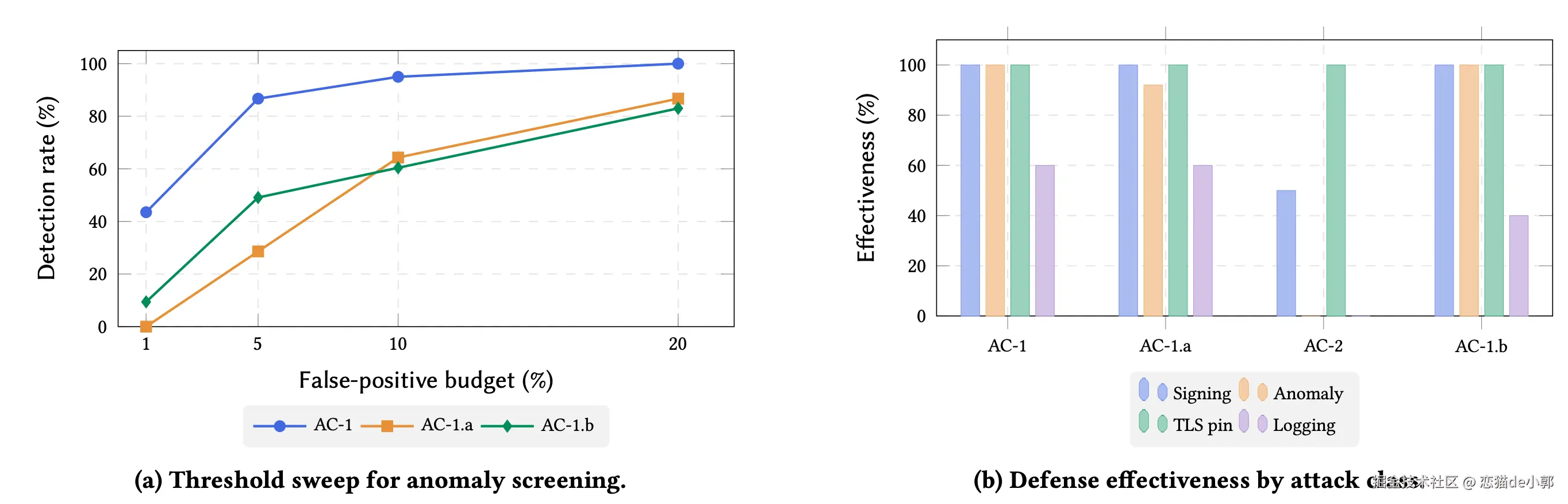
在作者论文的模板基准里,这个策略对 AC-1 和 AC-1.a 的阻断率都是 100% ,误报率 1.0% ,单次决策代价 2.3 微秒,当然前面我们聊过,只要攻击者能把 payload 放到 allowlisted 域名上,或者事先在本地埋个 stager,再通过看起来无害的 Bash 命令触发,那么这个防御就会被100% 绕过。
这是一个更现实的方案,它不试图知道「上游原始返回是什么」,因为客户端根据不知道,它只能看当前收到的 tool call 有没有异常,比如 shell 风险模式、工具频率、字符串熵、secret-like 字符串、schema 偏差等。
作者用 IsolationForest 在合成 benign tool call 上训练,在 held-out 数据上测。结果是:
也就是这个方案挡不住真正会伪装的攻击,但是可以作为 review prioritization 工具,特别是 AC-1.a 和 AC-1.b 本来就是为了绕过简单本地规则而设计的,所以检测能力明显差很多。
这个方案就只是用来做「事后诸葛亮了」,它会记录 request body、response body、router URL、TLS 元数据、响应哈希等,在请求侧做 secret redaction,成本也不高,1000 个 session 大概 12 MB,每条 1.26 KB。
当然, 客户端现有防御都只能“降风险”,不能“证明来源完整性”,真正需要的是中转的 provider 支持的响应签名机制, 像 DKIM、Sigstore、SLSA、Subresource Integrity 那样,给模型响应中的语义关键部分做可验证签名。
其实结论很明显,客户端现有防御都只能“降风险”,不能“证明来源完整性”,真正需要的是 provider 支持的响应签名机制,作者提出了一个更体系化的方向:像 DKIM、Sigstore、SLSA、Subresource Integrity 那样,给模型响应中的语义关键部分做可验证签名。
大致思路就是,provider 把 model、tool_calls、finish_reason、request_nonce、时间窗口等字段映射到一个 canonical JSON,然后把原本字符串形式的 tool arguments 解析成 native JSON,用 RFC 8785 的 JSON canonicalization,再用私钥签名:
而客户端在执行 tool call 前,校验 nonce、时间、key_id、签名是否匹配,如果验证失败,就把响应当成 unsigned,拒绝执行高风险工具。
所以,在用中转的时候,多跳 router chain 比单跳风险大得多,特备是 YOLO mode 在这种链路里非常危险,在 Agent 时代,API Router 不只是一个中性网络设施,而是真的已经具备工具语义篡改能力的供应链节点。
论文也证明了,今天很多 LLM Agent 的调用链里,router 是一个默认被低估的供应链风险点,而这个点既能主动改写工具调用,又能被动窃取秘密,还能选择性只攻击高价值自治会话,最重要是现实世界里这种行为已经存在。
所以,AI 时代,安全真不是小事,感觉这也是最近供应链投毒那么频发的原因之一。
arxiv.org/pdf/2604.08…

