Tabula相册整理工具2026
27.5MB · 2026-04-07

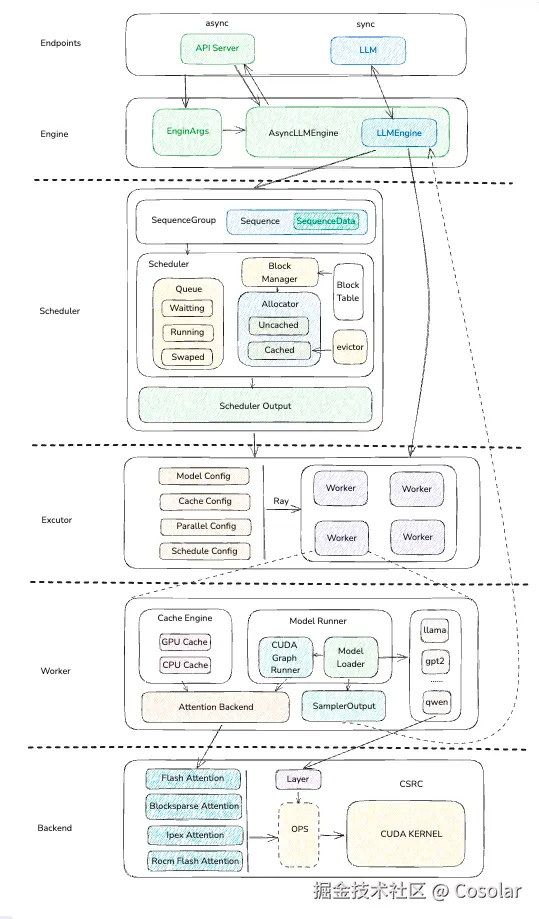
vLLM作为由伯克利大学团队研发的开源推理框架,凭借其革命性的PagedAttention技术,将显存利用率提升至95%以上,同时实现了数倍于传统框架的吞吐量。它不仅解决了大模型推理的显存瓶颈,还提供了简单易用的API接口和完整的生产部署方案,成为了目前最受欢迎的大模型推理引擎之一。
本文将从底层原理出发,深入解析vLLM的推理加速机制,然后通过实战步骤演示如何快速上手vLLM,最后总结生产环境中的常见问题与避坑指南。无论你是刚接触大模型推理的新手,还是正在优化生产部署的资深工程师,都能从本文中获得有价值的信息。
要理解vLLM的加速原理,我们首先需要了解大模型推理的基本过程以及传统方法存在的问题。
大语言模型采用自回归的方式生成文本,即每次根据前面所有的token生成下一个token。在这个过程中,Transformer的注意力机制需要计算每个token与之前所有token的相似度。
如果每次生成新token时都重新计算所有历史token的Key和Value向量,将会产生巨大的计算开销。因此,所有现代推理框架都会使用KV缓存技术:将已经计算过的Key和Value向量保存下来,在后续步骤中直接复用。
然而,传统的KV缓存实现存在一个致命的缺陷:它要求为每个请求分配连续的显存块。这就导致了两个严重的问题:
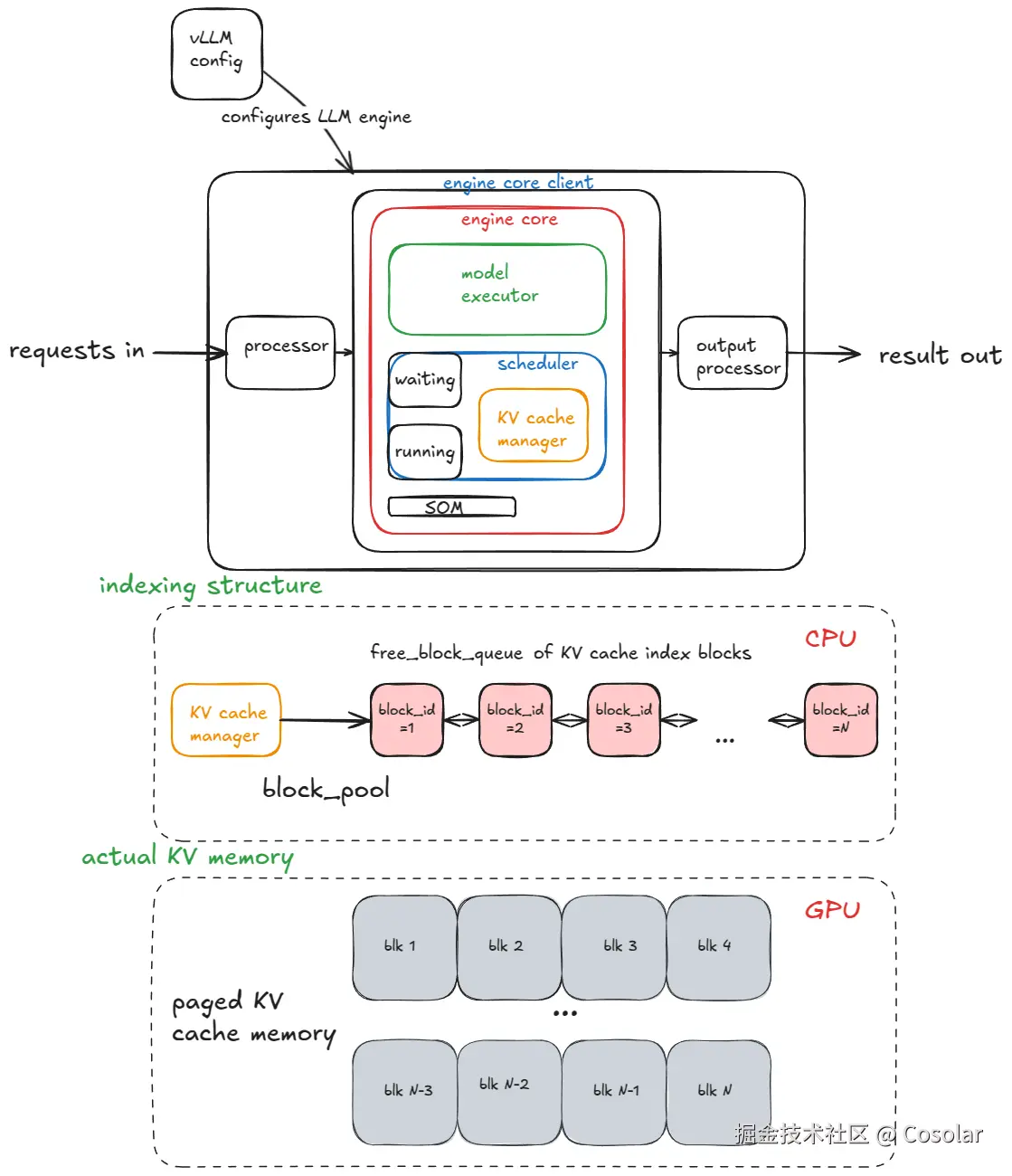
vLLM的核心创新就是PagedAttention(分页注意力),它借鉴了操作系统中虚拟内存管理的分页思想,彻底解决了传统KV缓存的问题。
PagedAttention的核心思想非常简单:不再将KV缓存视为连续的长数组,而是将其划分为固定大小的"页"(blocks)。每个页包含固定数量的token(默认16个)的Key和Value向量。
# 传统KV缓存结构(连续内存)
KV_Cache = [BatchSize][SeqLen][NumHeads][HeadDim]
# PagedAttention KV缓存结构(分页内存)
KV_Pool = [NumPages][BlockSize][NumHeads][HeadDim]
Block_Table[RequestID] = [Page1, Page2, Page3, ...]
每个请求只需要维护一个块表(Block Table),类似于操作系统的页表,记录了该请求的逻辑token块与物理显存页之间的映射关系。
这种设计带来了三个革命性的优势:
除了PagedAttention,vLLM的另一个核心优化是连续批处理(也称为动态批处理)。
传统的静态批处理需要等待一个批次中的所有请求都完成生成后,才能开始处理下一个批次。这导致了严重的GPU资源浪费,因为生成速度快的请求必须等待生成速度慢的请求。
vLLM的连续批处理则完全不同:它在每个token生成步骤后,都会检查是否有新的请求可以加入当前批次,或者是否有已经完成的请求可以从批次中移除。这样,GPU资源始终得到充分利用,不会出现空闲等待的情况。
vLLM还实现了自动前缀缓存技术,进一步提升了显存利用率和推理速度。
在很多应用场景中,不同的请求会共享相同的前缀(例如系统提示词、RAG检索到的上下文等)。传统的推理框架会为每个请求单独计算和存储这些共享前缀的KV缓存,造成了大量的重复计算和内存浪费。
vLLM的自动前缀缓存通过对每个KV块计算哈希值,建立了一个全局的哈希表。当新请求到来时,vLLM会检查其前缀是否已经存在于哈希表中。如果存在,就直接复用已有的KV块,无需重新计算和存储。
除了上述三大核心技术外,vLLM还集成了多种优化技术来进一步提升性能:
了解了vLLM的核心原理后,让我们通过实战步骤来学习如何使用vLLM进行大模型推理和部署。
vLLM支持NVIDIA、AMD、Intel等多种硬件平台,这里我们以最常用的NVIDIA GPU为例进行介绍。
推荐环境配置:
使用uv快速安装(推荐): uv是一个比pip快10-100倍的Python包管理器,强烈推荐使用:
# 创建并激活虚拟环境
uv venv vllm-env --python 3.12
source vllm-env/bin/activate # Linux/macOS
# vllm-envScriptsactivate # Windows
# 安装vLLM(会自动安装匹配的PyTorch版本)
uv pip install vllm==0.18.0
# 验证安装
python -c "import vllm; print(f'vLLM版本: {vllm.__version__}')"
使用conda安装:
# 创建并激活虚拟环境
conda create -n vllm-env python=3.12 -y
conda activate vllm-env
# 安装vLLM
pip install vllm==0.18.0
vLLM提供了非常简单的离线推理接口,与Hugging Face Transformers的接口非常相似,易于上手。
from vllm import LLM, SamplingParams
# 1. 初始化模型
# 这里使用Qwen2-7B-Instruct作为示例,你可以替换为任何支持的模型
llm = LLM(
model="Qwen/Qwen2-7B-Instruct",
tensor_parallel_size=1, # 使用1张GPU
gpu_memory_utilization=0.9, # 使用90%的GPU显存
max_model_len=8192, # 最大上下文长度
enable_prefix_caching=True, # 启用前缀缓存
)
# 2. 设置采样参数
sampling_params = SamplingParams(
temperature=0.7,
top_p=0.9,
max_tokens=512,
repetition_penalty=1.05,
)
# 3. 批量推理
prompts = [
"什么是大语言模型?用简单的语言解释一下。",
"请列出5个提高Python代码性能的技巧。",
"写一首关于春天的七言绝句。",
]
outputs = llm.generate(prompts, sampling_params)
# 4. 输出结果
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"提示词: {prompt}")
print(f"生成结果: {generated_text}n")
vLLM提供了与OpenAI API完全兼容的服务接口,这意味着你可以直接使用OpenAI的SDK或任何支持OpenAI API的工具来调用vLLM服务。
启动API服务:
python -m vllm.entrypoints.openai.api_server
--model Qwen/Qwen2-7B-Instruct
--api-key sk-vllm-demo
--port 8000
--tensor-parallel-size 1
--gpu-memory-utilization 0.9
--max-model-len 8192
--enable-prefix-caching
--max-num-seqs 256
--max-num-batched-tokens 8192
使用OpenAI SDK调用:
from openai import OpenAI
client = OpenAI(
base_url="http://localhost:8000/v1",
api_key="sk-vllm-demo"
)
response = client.chat.completions.create(
model="Qwen/Qwen2-7B-Instruct",
messages=[
{"role": "system", "content": "你是一个有用的助手。"},
{"role": "user", "content": "什么是vLLM?它有什么优势?"}
],
temperature=0.7,
max_tokens=512
)
print(response.choices[0].message.content)
正确调整vLLM的参数对于获得最佳性能至关重要。以下是几个最关键的参数及其调优建议:
| 参数 | 说明 | 调优建议 |
|---|---|---|
gpu_memory_utilization | GPU显存利用率 | 通常设置为0.8-0.9,不要设置为1.0,需要为CUDA内核和其他操作预留显存 |
max_model_len | 最大上下文长度 | 根据你的应用场景设置,不要设置得过大,否则会预留过多的KV缓存空间 |
max_num_seqs | 同时处理的最大请求数 | 根据GPU显存大小调整,A10(24GB)可设为256,A100(80GB)可设为1024 |
max_num_batched_tokens | 单个批次的最大token数 | 这是防止OOM的最重要参数,建议设置为max_model_len的一半 |
enable_prefix_caching | 启用前缀缓存 | 在多轮对话或RAG场景中强烈建议启用 |
quantization | 量化方式 | 显存不足时使用,支持"awq"、"gptq"、"squeezellm"等 |
当模型太大无法放入单个GPU时,可以使用张量并行将模型拆分到多个GPU上运行。
# 使用4张GPU运行Qwen2-72B-Instruct
python -m vllm.entrypoints.openai.api_server
--model Qwen/Qwen2-72B-Instruct-AWQ
--api-key sk-vllm-demo
--port 8000
--tensor-parallel-size 4
--gpu-memory-utilization 0.9
--max-model-len 32768
--enable-prefix-caching
--quantization awq
--max-num-seqs 128
--max-num-batched-tokens 16384
注意:
examples/offline_inference/save_sharded_state.py将模型转换为分片检查点,加快加载速度在实际使用vLLM的过程中,你可能会遇到各种问题。以下是我总结的最常见问题及其解决方案。
OOM是使用vLLM时最常见的问题,通常由以下原因引起:
问题1:模型加载时OOM
gpu_memory_utilization参数问题2:运行时突发OOM
max_num_batched_tokens参数(最重要)max_num_seqs参数max_model_len问题3:max-model-len设置过大导致OOM
误区1:max_num_seqs越大越好
误区2:gpu_memory_utilization设置为1.0
误区3:所有场景都启用前缀缓存
问题1:PyTorch版本不兼容
问题2:CUDA版本不兼容
pip install vllm==0.18.0 --extra-index-url
问题3:某些模型不支持
vLLM通过引入PagedAttention技术,彻底改变了大模型推理的显存管理方式,实现了接近最优的显存利用率和极高的推理吞吐量。它不仅解决了传统推理框架的核心痛点,还提供了简单易用的接口和完整的生产部署方案,成为了大模型应用开发的首选推理引擎。
优势:
局限性:
目前主流的大模型推理框架还有SGLang和TensorRT-LLM,它们各有侧重:
vLLM正在快速发展中,未来可能会在以下几个方面取得突破:
总的来说,vLLM已经成为了大模型推理领域的事实标准之一。掌握vLLM的原理和使用方法,对于每一位AI大模型应用开发工程师来说都是必不可少的技能。
如果你在使用vLLM的过程中有任何问题或经验分享,欢迎在评论区留言讨论。关注我,获取更多大模型技术干货!

