
alookdlna投屏t
17.07MB · 2026-04-04

在AI Agent(智能体)应用开发热潮中,OpenClaw以其独特的架构设计和庞大的Skill生态迅速脱颖而出。然而,仅仅会使用npx clawhub install是远远不够的。要构建真正健壮、可靠、可用的AI Agent,我们必须深入理解其背后的设计哲学,以及所有Agent系统共同面临的根本性挑战。
本文将结合OpenClaw的技术实现,以及行业内的最佳实践,系统性地拆解这些挑战,并给出相应的工程解决方案。文章将包含架构图、核心代码逻辑示意,并配有解释性图表。
一个常见的误解是将AI Agent视为一个能联网、能调用工具的“增强版ChatGPT”。这严重低估了其复杂性。一个真正的、可长期运行、自主处理复杂任务的Agent,是一个系统工程。它需要管理状态、分配资源、处理失败、并保障安全。OpenClaw和另一个顶尖的工程化Agent系统Claude Code,正是在尝试用不同的架构来回答同一组核心问题。
问题本质:大语言模型(LLM)的上下文窗口是有限的(如128K、200K)。而一个Agent在运行中需要承载的信息可能远超此限:漫长的历史对话、庞大的知识库(memory)、数十上百个工具(Skill)的说明书、当前任务的状态等。无脑地塞入所有信息会迅速耗尽窗口,导致模型遗忘关键指令或输出质量下降。
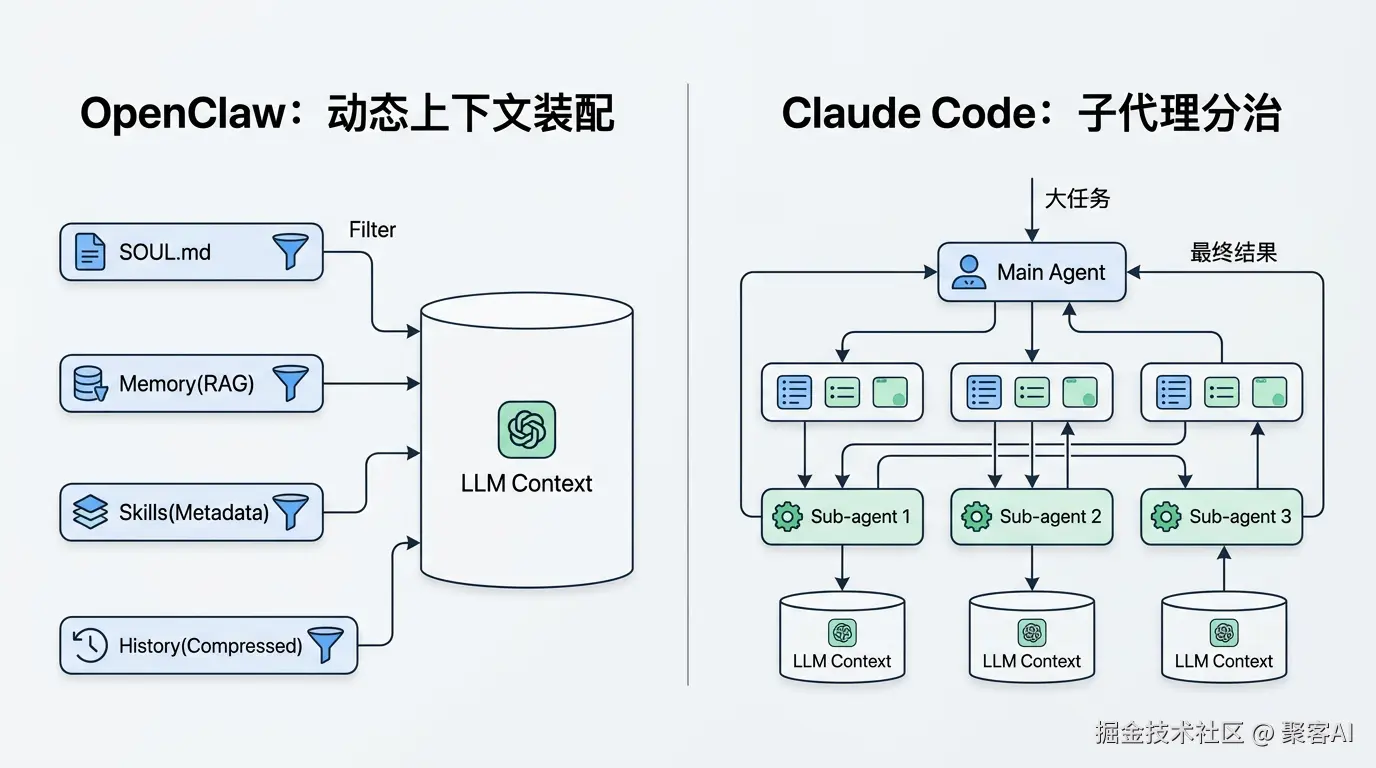
OpenClaw的解法:动态、精准的上下文工程(Context Engineering)
OpenClaw没有采用固定系统提示词,而是动态构建每次请求的提示词。其核心逻辑是一个精密的“装配流水线”:
SOUL.md(Agent的“灵魂”与核心原则)。memory.md(记忆库)进行RAG(检索增强生成) 检索,只选取与当前查询最相关的top-k个记忆片段注入,而非全文载入。这保证了无论记忆库多大,其对上下文的占用是恒定的。# 伪代码示意:OpenClaw动态上下文构建逻辑
def build_system_prompt(user_query, agent_id):
prompt_parts = []
# 1. 核心身份与原则 (不可压缩)
prompt_parts.append(read_file(f"~/.openclaw/agents/{agent_id}/SOUL.md"))
# 2. 相关记忆检索 (RAG, 固定大小)
memory_chunks = retrieve_relevant_memories(user_query, agent_id, top_k=5)
prompt_parts.append(f"Relevant Memories:n{memory_chunks}")
# 3. 工具目录 (仅元信息)
available_skills = list_skills(agent_id)
prompt_parts.append(f"Available Skills (see full doc at path): {available_skills}")
# 4. 压缩后的历史对话摘要
condensed_history = get_condensed_conversation_history(agent_id)
prompt_parts.append(f"Conversation Summary:n{condensed_history}")
# 5. 当前查询
prompt_parts.append(f"Current User Request: {user_query}")
return "nn---nn".join(prompt_parts)
对比与延伸:Claude Code的“分而治之”策略 Claude Code采用了更激进的方案:Subagent(子代理)机制。对于超大型任务(如分析一个有50个文件的代码库),主Agent会将任务拆解,派发给多个独立的子Agent并行处理。每个子Agent拥有自己独立的、纯净的上下文。最后,主Agent只汇总子Agent的结论。这彻底避免了单个上下文膨胀的问题,是“分治”思想在Agent架构中的完美体现。
问题本质:LLM本质上是无状态的。一次对话中“记住”的事情,在下次对话或任务中断后就会丢失。依赖模型的短期“记忆”来运行长期任务(如持续数天的项目管理)是极不可靠的。
OpenClaw的解法:显式文件化与“压缩边界”
OpenClaw提出了一个简单而强硬的原则:任何需要被持久化、在后续交互中必须被记住的状态,必须被显式地写入文件(如memory.md)。
关键在于理解其“压缩边界”。在OpenClaw中,SOUL.md和memory.md的内容在上下文压缩过程中是受保护的,不会被摘要替代。而普通的对话历史则会被压缩。这意味着:
memory.md -> 永久记忆,每次对话可用。那个著名的“邮件删除失控”案例正是因此而生:用户的口头约束“删前需确认”只存在于对话历史中,在一次压缩后便被遗忘,Agent便“合法地”忘记了该约束。
# 伪代码示意:记忆的显式写入与RAG检索
import vector_store # 假设使用向量数据库
class AgentMemory:
def __init__(self, memory_file_path):
self.memory_file = memory_file_path
self.vector_index = vector_store.load_index()
def remember(self, fact: str, importance: float):
""" 显式记忆:将事实写入文件并建立向量索引 """
with open(self.memory_file, 'a') as f:
f.write(f"- {fact}n")
# 将事实向量化并存入索引,供后续RAG检索
self.vector_index.add(fact, metadata={"importance": importance})
def recall(self, query: str, top_k: int = 5) -> list:
""" 回忆:根据当前查询检索最相关的记忆片段 """
relevant_chunks = self.vector_index.search(query, k=top_k)
return [chunk.text for chunk in relevant_chunks]
# 在Agent决策循环中
if user_says_contains_important_preference:
agent.memory.remember(user_preference, importance=0.9)
问题本质:工具赋予Agent改变现实世界的能力(执行命令、修改文件、调用API),同时也带来了巨大风险。一个被恶意诱导或出错的Agent可能造成数据丢失、财务损失或安全漏洞。仅靠提示词(如“未经确认不得删除文件”)约束是脆弱的,易受提示词注入攻击。
OpenClaw的解法:程序级的工具调用拦截层
OpenClaw在架构层面设置了一道安全防线:在工具调用真正执行前,运行时会触发一个tool_call事件。开发者可以在此处插入钩子(hook),进行参数验证、权限检查,甚至弹出人工确认。
// 伪代码示意:OpenClaw风格的工具执行拦截
// runtime/core/tool_executor.js
class ToolExecutor {
constructor() {
this.eventEmitter = new EventEmitter();
}
async execute(toolName, parameters) {
// 1. 触发前置拦截事件
const shouldProceed = await this.eventEmitter.emitAsync(
'before_tool_execute',
{ toolName, parameters, user: currentUser }
);
if (shouldProceed === false) {
console.log(`Execution of ${toolName} was blocked by a security hook.`);
return { error: 'Execution blocked by security policy.' };
}
// 2. 实际执行工具
const result = await this.invokeTool(toolName, parameters);
// 3. 触发后置事件(用于日志、审计)
this.eventEmitter.emit('after_tool_execute', { toolName, parameters, result });
return result;
}
}
// 安全插件示例:拦截危险操作
securityPlugin.registerHook('before_tool_execute', async (event) => {
const dangerousPatterns = ['rm -rf', 'format C:', 'DROP DATABASE'];
const paramsString = JSON.stringify(event.parameters).toLowerCase();
for (const pattern of dangerousPatterns) {
if (paramsString.includes(pattern)) {
// 触发人工审核流程,或直接阻止
await requestHumanApproval(event);
return false; // 阻止执行
}
}
return true; // 允许执行
});
设计哲学:安全边界必须建立在程序层,而非模型层。模型的判断可能被欺骗或绕开,但代码中写死的拦截逻辑是确定性的。这与Claude Code禁止子代理无限递归(防止任务无限外包)的设计思路同源。
问题本质:复杂任务链路长、可能失败、需要调整方向。传统的线性对话历史难以支持任务的探索、回溯和分支。
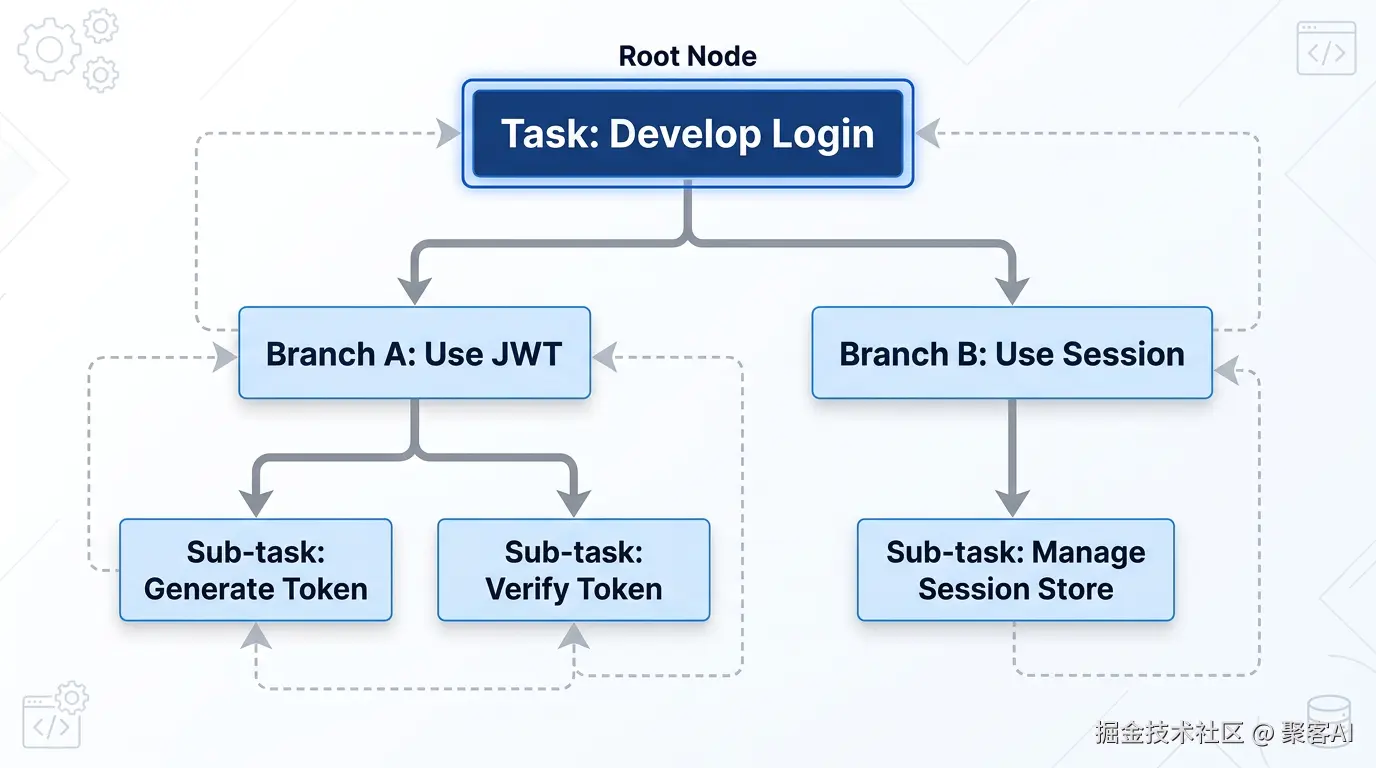
工程实践与借鉴:会话树(Session Tree)与非线性的任务历史
虽然OpenClaw文章未深入此点,但Claude Code的Session Tree设计极具启发性。它将对话历史从一条线变为一棵树。每个步骤都有一个id和parentId,允许Agent从历史中的任意节点分支出新的执行路径。
这解决了复杂任务调试和探索的痛点:
# 伪代码示意:会话树节点结构
class SessionNode:
def __init__(self, node_id: str, parent_id: str, action: str, result: str):
self.id = node_id
self.parent_id = parent_id
self.action = action # 执行的动作
self.result = result # 动作的结果
self.children = [] # 子节点列表
class SessionTree:
def __init__(self):
self.root = SessionNode("root", None, "start", "")
self.nodes = {"root": self.root}
def branch_from(self, parent_id: str, new_action: str):
""" 从指定父节点创建一个新的分支 """
parent = self.nodes[parent_id]
new_node = SessionNode(
node_id=generate_id(),
parent_id=parent_id,
action=new_action,
result=""
)
parent.children.append(new_node)
self.nodes[new_node.id] = new_node
return new_node.id
通过深度剖析OpenClaw及其所代表的先进设计,我们可以提炼出构建现代AI Agent系统的四项核心原则:
OpenClaw通过其动态上下文装配、显式文件记忆、程序级工具拦截,为构建长期运行、高度个性化、人机紧密协作的Agent提供了优秀范式。而Claude Code的极简工具、自我扩展、子代理分治、会话树则更适合复杂、确定性的工程任务。
作为开发者,我们的任务不是二选一,而是深刻理解这些模式背后的通用逻辑,根据自身产品的具体场景、风险偏好和技术栈,设计出最合适的AI Agent架构。未来优秀的Agent系统,必然是能优雅平衡能力、安全与资源的艺术品。

