壁纸神器
122.67M · 2026-04-06

近两年来,大模型技术完成了从学术突破到工业化落地的快速跃迁,LLM、RAG、Agent、Skill这四个核心概念,已经成为每个技术人绕不开的话题。但我发现,行业内充斥着大量模糊解读、错误认知甚至玄学化的表述:有人把RAG等同于向量数据库,有人把Agent简单理解为LLM+工具调用,有人混淆了Skill与Function Calling的边界,更有很多Java开发者,看着Python生态的碎片化教程,不知道如何在熟悉的Java技术栈中落地这些技术。
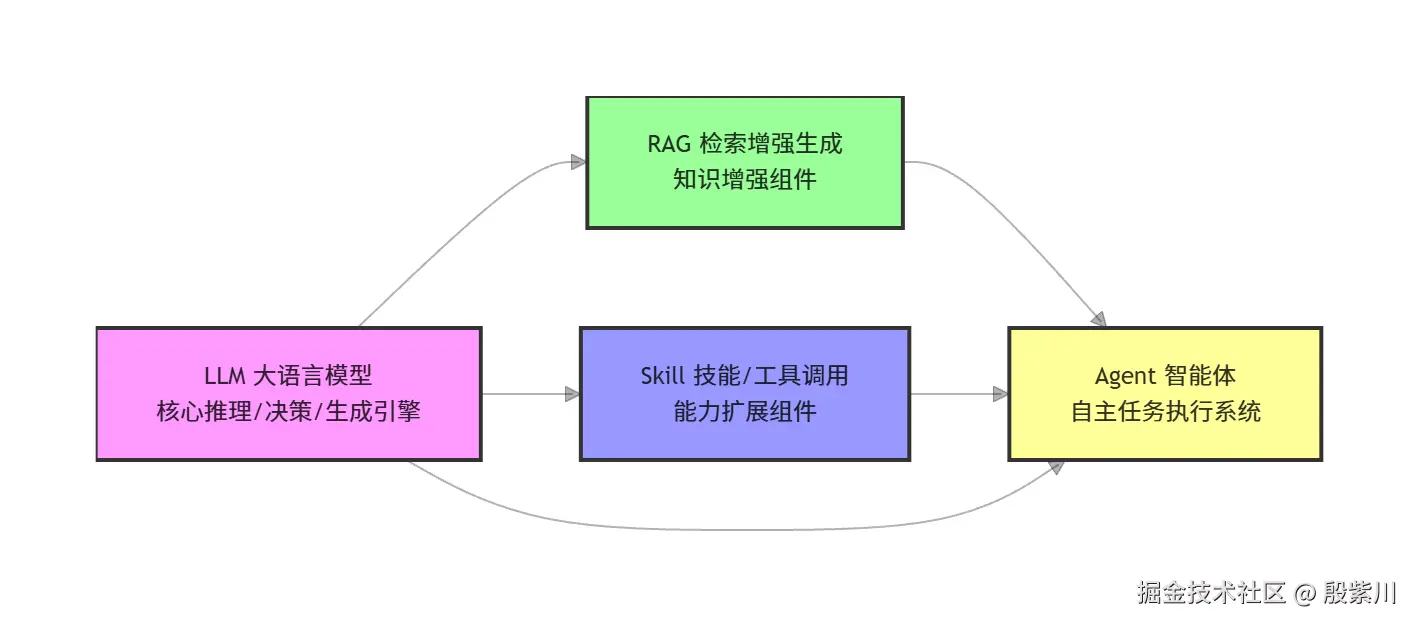
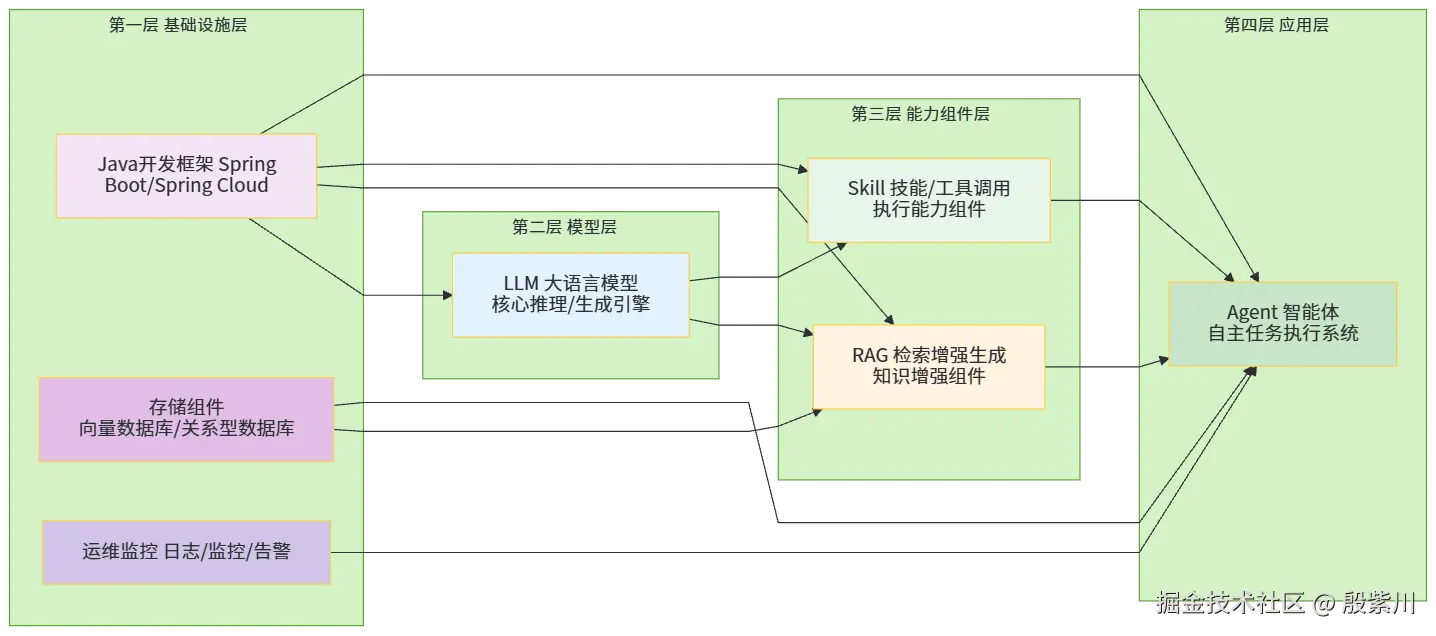
在拆解细节之前,我们先通过全景架构图,明确四个概念的层级关系、依赖关系与协同逻辑,从根源上避免概念混淆。
从架构图可以清晰看到四个概念的核心定位:
这一章我们彻底讲透LLM的底层逻辑,不用晦涩公式,只用Java开发者能懂的类比,让你真正理解LLM的工作原理,而不是只会调用API。
首先纠正行业内最大的误区:LLM并不具备真正的“理解”能力,也没有意识,它的核心本质是基于海量文本训练出来的「token级概率预测模型」。这句话是理解所有LLM行为的基础,有权威学术与官方依据支撑。
什么意思?我们用最通俗的例子说明: 当你给LLM输入“上海的简称是”,LLM要做的不是“理解”这句话的含义,而是基于训练数据中学到的语言规律,计算下一个token出现的概率:
随后它会选择概率最高的“沪”输出,再把“上海的简称是沪”作为新的上文,继续预测下一个token,直到生成结束符或达到上下文长度上限。
再比如你输入“1+1=”,LLM输出“2”,不是因为它会做数学题,而是因为训练数据里“1+1=”后面跟着“2”的概率无限接近100%。
这就是LLM的核心本质:所有输出都是基于上文的token概率预测,一步一步生成的。它的所有“理解能力”“推理能力”“创作能力”,本质上都是这种概率预测能力在模型规模达到临界值后,涌现出来的效果。
所有主流LLM(GPT系列、豆包、通义千问、Llama系列)的底层核心架构都是Transformer,这个来自Google 2017年《Attention Is All You Need》的架构,是整个大模型时代的开山之作,没有Transformer,就没有今天的LLM。
Transformer的核心是自注意力机制,这也是它能处理长文本、理解上下文语义的核心原因。
举个Java开发者最熟悉的例子:
这句话里的“它”,人一眼就能看出指代的是“Java项目的jar包”,但传统模型很难理解这种指代关系。而自注意力机制会给每个词计算和“它”的关联权重:
这样模型在处理“它”时,就会把注意力主要放在“Java项目的jar包”上,正确理解指代对象。用Java代码类比,自注意力机制的核心逻辑如下:
/**
* 自注意力机制的Java类比实现
* @param text 输入文本分词后的列表
* @param targetWord 目标词
* @return 每个词与目标词的关联权重
*/
public Map<String, Double> selfAttention(List<String> text, String targetWord) {
Map<String, Double> weightMap = new HashMap<>();
// 1. 遍历文本,计算每个词与目标词的语义相似度
for (String word : text) {
double similarity = calculateSemanticSimilarity(word, targetWord);
weightMap.put(word, similarity);
}
// 2. 归一化权重,确保所有权重之和为1
weightMap = normalizeWeight(weightMap);
// 3. 返回权重Map,模型根据权重重点关注高相关性内容
return weightMap;
}
真实的自注意力机制通过Q(查询)、K(键)、V(值)三个矩阵实现,核心流程为:
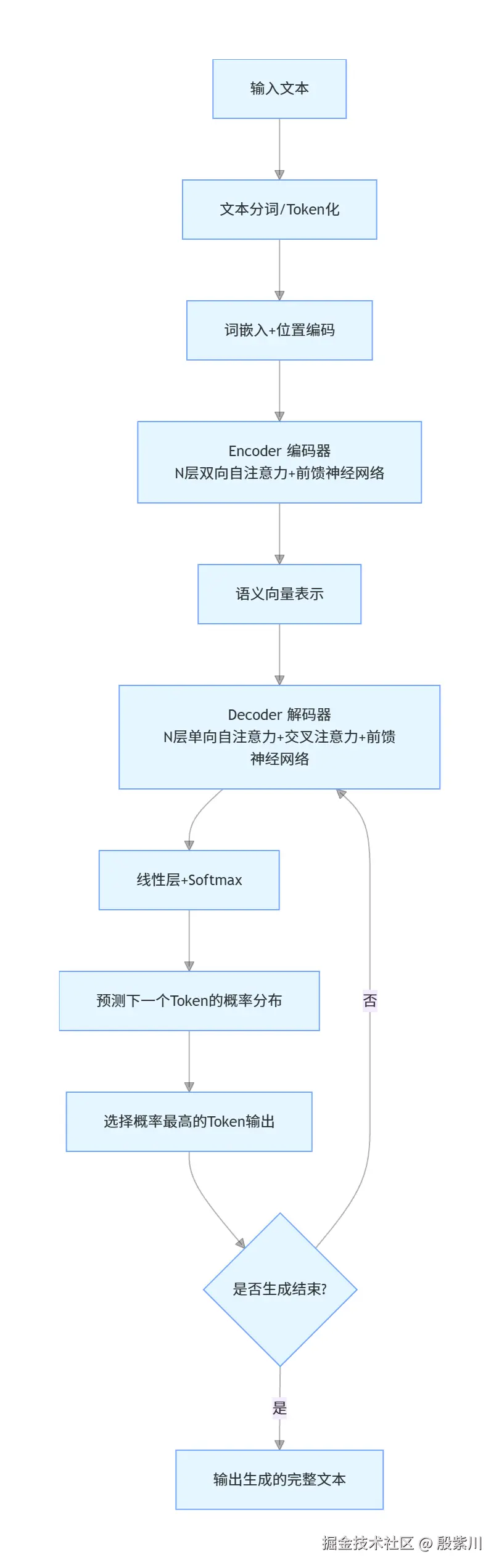
Transformer架构整体分为两个核心部分:Encoder(编码器) 和 Decoder(解码器) 。
我们用流程图展示Transformer的完整工作流程,这是所有LLM文本生成的底层逻辑:
LLM的训练过程就像人的学习过程,分为三个核心阶段,每个阶段都有明确的目标与权威实现方案:
预训练是LLM最核心、最耗时、最耗算力的阶段,目标是让模型学会人类语言的基本规律、语法、语义与常识。
SFT阶段的目标是让预训练模型学会遵循用户指令,按照人类要求输出内容。
这个阶段的目标是让模型的输出符合人类的价值观、偏好与伦理规范,减少幻觉与有害内容。
“涌现能力”是LLM的核心特性,来自Google Brain 2022年《Emergent Abilities of Large Language Models》,权威定义是:在小模型中不存在、但在大模型中突然出现的能力,无法通过外推小模型性能预测。通俗来说,就是模型规模达到临界值后,量变引起质变,突然具备了之前没有的能力。
LLM的核心涌现能力包括:
评估LLM的好坏不能只看参数量,要关注这些核心指标,避免被营销话术误导:
| 指标 | 定义 | 业务意义 |
|---|---|---|
| 参数量 | 模型中可训练参数的数量,单位为B(十亿) | 模型能力的基础,但不是唯一决定因素 |
| 上下文窗口长度 | 模型能处理的最大token数量,包含输入与输出 | 决定模型能处理的文本长度与记忆能力 |
| 困惑度(PPL) | 评估模型语言建模能力的核心指标,值越低越好 | 反映模型预测的准确率,值越低生成的文本越通顺、逻辑越严谨 |
| 推理速度 | 模型每秒能生成的token数量(token/s) | 决定模型的响应速度,是业务落地的关键指标 |
| 基准测试得分 | MMLU、GSM8K、HumanEval等权威测试的准确率 | 客观反映模型在语言理解、数学推理、代码生成等领域的能力 |
Spring AI是Spring官方推出的大模型应用开发框架,与Spring Boot无缝集成,完全符合Java开发者的开发习惯,是Java生态接入LLM的首选方案。
创建Spring Boot 3.2+项目,JDK 17+,引入Maven依赖:
<!-- Spring Boot 父依赖 -->
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.2.5</version>
<relativePath/>
</parent>
<dependencies>
<!-- Spring AI 核心依赖 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter</artifactId>
<version>1.0.0</version>
</dependency>
<!-- Spring AI 字节跳动豆包大模型依赖 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-doubao-spring-boot-starter</artifactId>
<version>1.0.0</version>
</dependency>
<!-- Spring Web 依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- Lombok 依赖 -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
</dependencies>
<!-- Spring AI 官方仓库 -->
<repositories>
<repository>
<id>spring-milestones</id>
<name>Spring Milestones</name>
<url></url>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
</repositories>
在application.yml中配置豆包大模型:
spring:
ai:
doubao:
api-key: 你的豆包API密钥(火山引擎控制台获取)
chat:
options:
model: doubao-pro-32k
temperature: 0.7
max-tokens: 2048
创建Controller实现最简单的LLM对话接口:
package com.ken.llm.demo.controller;
import lombok.RequiredArgsConstructor;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
/**
* LLM基础调用Controller
* 作者:Ken
*/
@RestController
@RequestMapping("/llm")
@RequiredArgsConstructor
public class LlmController {
// Spring AI 自动注入配置好的ChatClient
private final ChatClient chatClient;
/**
* 基础LLM对话接口
* @param prompt 用户输入的提示词
* @return LLM生成的回答
*/
@GetMapping("/chat")
public String chat(@RequestParam String prompt) {
return chatClient.prompt()
.user(prompt)
.call()
.content();
}
}
启动项目后,访问用Java写一个冒泡排序算法,即可直接获取LLM生成的代码。
误区1:LLM有真正的理解能力和意识
误区2:参数量越大,模型能力越强
误区3:LLM能记住所有训练数据
误区4:LLM能完成精确的数学计算和逻辑推理
上一章我们讲了LLM的核心原理,这一章我们讲RAG,它是解决LLM幻觉、知识滞后、专业知识不足的核心方案,也是目前企业级大模型应用落地最成熟的技术。
LLM有四个原生痛点,是自身无法突破的,必须通过RAG解决:
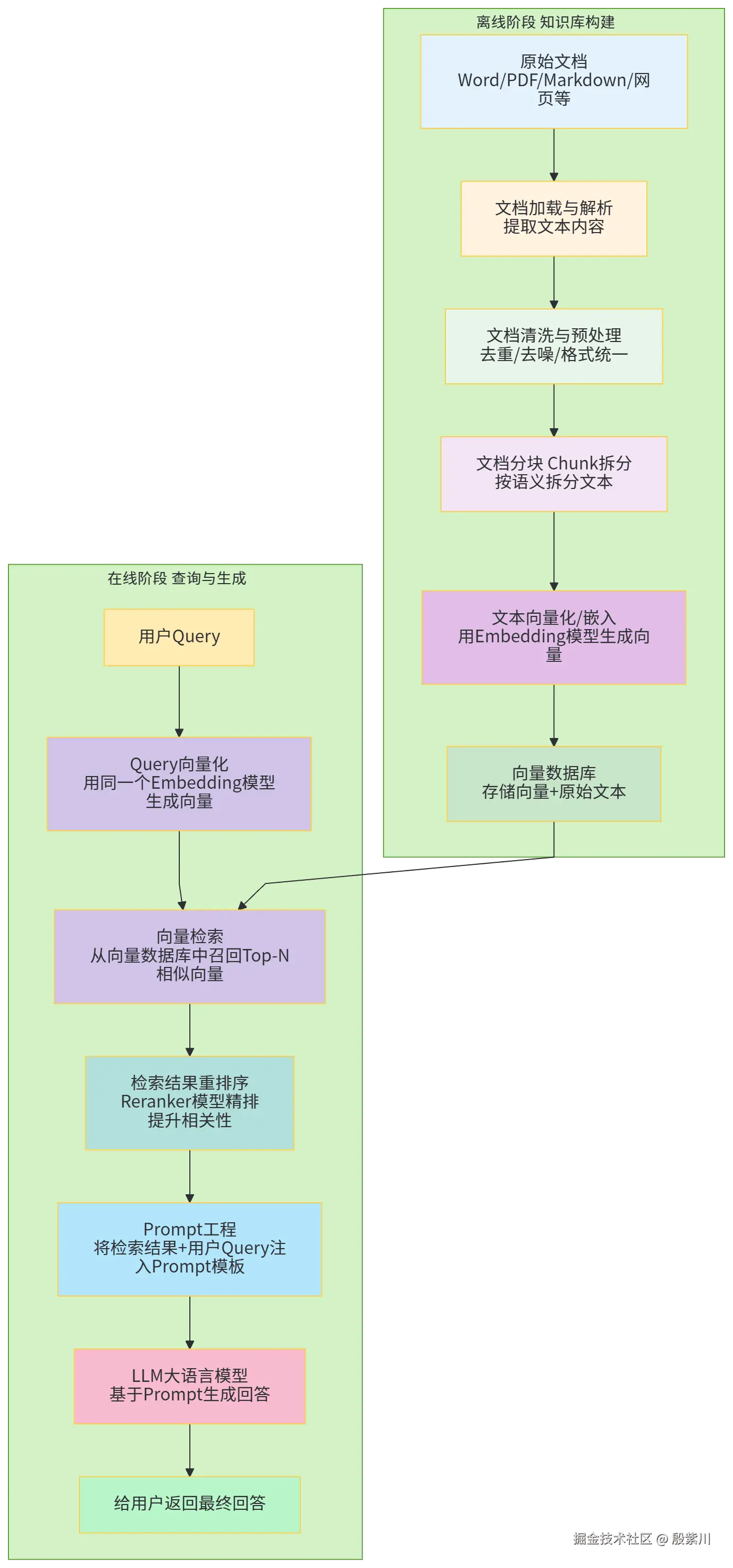
RAG的完整流程分为两大阶段:离线数据预处理阶段(知识库构建)和在线查询生成阶段,70%的RAG效果问题都出在离线阶段。
离线阶段的目标是将原始文档处理成可被高效检索、可被LLM有效利用的格式,直接决定了RAG的最终效果。
步骤1:文档加载与解析 将各种格式的原始文档转换为纯文本内容,Java生态中推荐使用Apache PDFBox处理PDF、Apache POI处理Office文档、Jsoup处理HTML网页,这些都是成熟稳定的工业级工具。解析时需尽量保留文档的标题、段落、表格等结构信息,对后续语义拆分与检索至关重要。
步骤2:文档清洗与预处理 将解析后的文本处理成干净规范的高质量文本,核心操作包括:去重、去噪(去除页眉页脚、页码、乱码)、格式统一、长句拆分,文本质量越高,后续的向量化与检索效果越好。
步骤3:文档分块/Chunk拆分 这是离线阶段最核心的步骤,目标是将长文本拆分成合适大小、语义完整的文本块。
核心原则:语义完整,大小合适。一个Chunk必须是一个完整的语义单元,不能将一个完整的知识点拆分到两个Chunk中,否则会导致检索到的信息不完整,LLM无法准确回答。
最佳实践:
拆分策略:优先使用基于语义的拆分(按段落、标题、章节拆分),其次使用固定大小+重叠拆分,避免语义截断。
步骤4:文本向量化/嵌入(Embedding) 这个步骤是RAG实现语义检索的核心,目标是将文本块转换为固定长度的高维稠密向量。
权威定义:嵌入是将非结构化文本转换为高维稠密向量的技术,语义相似的文本,对应的向量在向量空间中的距离更近。
嵌入模型选择:
核心红线:整个RAG流程必须使用同一个嵌入模型,离线文档向量化和在线Query向量化必须使用同一个模型,否则向量空间不一致,检索结果完全错误。
步骤5:向量数据库存储 将生成的向量与对应的原始文本块存储到向量数据库中,用于后续的快速相似性检索。
向量数据库的核心作用:通过ANN(近似最近邻)算法,实现百万/千万级向量的毫秒级相似性检索,常用算法包括HNSW、IVF_FLAT;
Java生态推荐选型:
在线阶段的目标是接收用户Query,检索相关文档,让LLM基于权威资料生成无幻觉的准确回答。
步骤1:用户Query向量化与改写 用和离线阶段同一个嵌入模型,将用户Query转换为向量。进阶优化可通过Query改写,让LLM将口语化、模糊的Query改写成适合检索的精准语句,大幅提升召回率。
步骤2:向量检索 用Query向量从向量数据库中召回最相似的Top-N个文本块,核心算法为余弦相似度(取值-1到1,值越大语义越相似)。进阶优化可使用混合检索(Hybrid Search),将向量检索(语义检索)与关键词检索(全文检索)结合,同时覆盖语义匹配和关键词匹配,大幅提升召回率。
步骤3:检索结果重排序(Reranker) 这是提升RAG准确率的关键进阶步骤,用专门的重排序模型,对召回的Top-N结果进行二次精排,过滤无关内容,只保留最相关的Top-K个结果给LLM。
步骤4:Prompt工程注入 将检索到的权威文档、用户Query按照固定模板组装成Prompt,引导LLM只基于参考资料回答,从根源上避免幻觉。以下是经过生产验证的RAG专用Prompt模板,可直接使用:
你是一个专业、严谨的智能问答助手,只能基于下面提供的【参考资料】来回答用户的问题,必须严格遵守以下规则:
1. 回答必须完全来自于【参考资料】中的内容,绝对不能编造【参考资料】中没有的信息、数据、结论;
2. 如果【参考资料】中没有和用户问题相关的内容,或者相关内容不足以回答用户的问题,请直接回答:"非常抱歉,参考资料中没有相关内容,无法为您解答这个问题。",绝对不能编造内容;
3. 回答必须准确、严谨、简洁,符合逻辑,不要添加【参考资料】中没有的额外内容;
4. 禁止使用"根据参考资料"、"参考资料中提到"等类似话术,直接输出回答内容即可。
【参考资料】
{reference_content}
【用户问题】
{user_query}
步骤5:LLM生成回答 将组装好的Prompt传给LLM,生成最终回答。RAG场景推荐将temperature设置为0-0.3,低温度能让LLM严格遵循参考资料,进一步减少幻觉。
以下代码基于Spring AI 1.0.0正式版,实现完整的RAG知识库问答功能。
Docker一键部署Milvus向量数据库(官方标准部署方式):
# 下载Milvus docker-compose配置文件
wget -O docker-compose.yml
# 启动Milvus
docker-compose up -d
Milvus启动后,默认服务地址为localhost:19530,可视化管理工具Attu地址为。
在之前的项目中新增Maven依赖:
<!-- Spring AI Milvus 向量存储依赖 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-milvus-store-spring-boot-starter</artifactId>
<version>1.0.0</version>
</dependency>
<!-- PDF文档解析依赖 -->
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>pdfbox</artifactId>
<version>2.0.32</version>
</dependency>
<!-- Office文档解析依赖 -->
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi</artifactId>
<version>5.2.5</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml</artifactId>
<version>5.2.5</version>
</dependency>
在application.yml中新增Milvus与Embedding配置:
spring:
ai:
doubao:
api-key: 你的豆包API密钥
chat:
options:
model: doubao-pro-32k
temperature: 0.3 # RAG场景用低温度,保证严谨性
max-tokens: 2048
# 豆包Embedding模型配置
embedding:
options:
model: doubao-embedding-v1
# Milvus向量数据库配置
vectorstore:
milvus:
client:
host: localhost
port: 19530
database-name: default
collection-name: rag_demo
embedding-dimension: 1024 # 豆包embedding-v1的维度为1024
index-type: HNSW
metric-type: COSINE
package com.ken.llm.demo.service;
import lombok.RequiredArgsConstructor;
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.text.PDFTextStripper;
import org.apache.poi.xwpf.usermodel.XWPFDocument;
import org.springframework.ai.document.Document;
import org.springframework.ai.reader.TextReader;
import org.springframework.ai.transformer.splitter.TokenTextSplitter;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.stereotype.Service;
import org.springframework.web.multipart.MultipartFile;
import java.io.InputStream;
import java.util.List;
/**
* RAG知识库服务
* 作者:Ken
*/
@Service
@RequiredArgsConstructor
public class RagService {
private final VectorStore vectorStore;
// Token文本分块器,基于token拆分,自动处理语义重叠
private final TokenTextSplitter textSplitter = new TokenTextSplitter(
1024, // 每个Chunk的最大token数
200, // 相邻Chunk的重叠token数
true,
true
);
/**
* 上传文档,解析并存储到向量数据库
* @param file 上传的文档,支持pdf、docx、txt、md
* @return 存储结果
*/
public String uploadDocument(MultipartFile file) throws Exception {
String fileName = file.getOriginalFilename();
if (fileName == null) {
return "文件名不能为空";
}
// 1. 解析文档,提取文本内容
String content = "";
if (fileName.endsWith(".pdf")) {
content = extractPdfContent(file.getInputStream());
} else if (fileName.endsWith(".docx")) {
content = extractDocxContent(file.getInputStream());
} else if (fileName.endsWith(".txt") || fileName.endsWith(".md")) {
TextReader textReader = new TextReader(file.getInputStream());
List<Document> documents = textReader.get();
content = documents.get(0).getContent();
} else {
return "不支持的文件格式,仅支持pdf、docx、txt、md";
}
// 2. 文本分块
Document document = new Document(content);
List<Document> chunks = textSplitter.split(List.of(document));
// 3. 向量化并存储到Milvus
vectorStore.add(chunks);
return "文档上传成功,共拆分" + chunks.size() + "个文本块,已存储到向量数据库";
}
/**
* 解析PDF文档提取文本
*/
private String extractPdfContent(InputStream inputStream) throws Exception {
try (PDDocument document = PDDocument.load(inputStream)) {
PDFTextStripper stripper = new PDFTextStripper();
return stripper.getText(document);
}
}
/**
* 解析DOCX文档提取文本
*/
private String extractDocxContent(InputStream inputStream) throws Exception {
try (XWPFDocument document = new XWPFDocument(inputStream)) {
StringBuilder content = new StringBuilder();
document.getParagraphs().forEach(paragraph -> {
content.append(paragraph.getText()).append("n");
});
return content.toString();
}
}
}
package com.ken.llm.demo.service;
import lombok.RequiredArgsConstructor;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.document.Document;
import org.springframework.ai.vectorstore.SearchRequest;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.stereotype.Service;
import java.util.List;
import java.util.stream.Collectors;
/**
* RAG问答服务
* 作者:Ken
*/
@Service
@RequiredArgsConstructor
public class RagChatService {
private final ChatClient chatClient;
private final VectorStore vectorStore;
// 生产级RAG Prompt模板
private static final String RAG_PROMPT_TEMPLATE = """
你是一个专业、严谨的智能问答助手,只能基于下面提供的【参考资料】来回答用户的问题,必须严格遵守以下规则:
1. 回答必须完全来自于【参考资料】中的内容,绝对不能编造【参考资料】中没有的信息、数据、结论;
2. 如果【参考资料】中没有和用户问题相关的内容,或者相关内容不足以回答用户的问题,请直接回答:"非常抱歉,参考资料中没有相关内容,无法为您解答这个问题。",绝对不能编造内容;
3. 回答必须准确、严谨、简洁,符合逻辑,不要添加【参考资料】中没有的额外内容;
4. 禁止使用"根据参考资料"、"参考资料中提到"等类似话术,直接输出回答内容即可。
【参考资料】
{reference}
【用户问题】
{query}
""";
/**
* RAG问答接口
* @param query 用户问题
* @return 基于知识库的回答
*/
public String ragChat(String query) {
// 1. 检索Top5个相关文档,相似度阈值0.7,过滤无关内容
List<Document> relevantDocs = vectorStore.similaritySearch(
SearchRequest.query(query)
.withTopK(5)
.withSimilarityThreshold(0.7)
);
// 2. 拼接参考资料
String reference = relevantDocs.stream()
.map(Document::getContent)
.collect(Collectors.joining("nn"));
// 3. 无相关内容直接返回默认话术
if (reference.isBlank()) {
return "非常抱歉,参考资料中没有相关内容,无法为您解答这个问题。";
}
// 4. 组装最终Prompt
String finalPrompt = RAG_PROMPT_TEMPLATE
.replace("{reference}", reference)
.replace("{query}", query);
// 5. 调用LLM生成回答
return chatClient.prompt()
.user(finalPrompt)
.call()
.content();
}
}
package com.ken.llm.demo.controller;
import com.ken.llm.demo.service.RagChatService;
import com.ken.llm.demo.service.RagService;
import lombok.RequiredArgsConstructor;
import org.springframework.web.bind.annotation.*;
import org.springframework.web.multipart.MultipartFile;
/**
* RAG接口Controller
* 作者:Ken
*/
@RestController
@RequestMapping("/rag")
@RequiredArgsConstructor
public class RagController {
private final RagService ragService;
private final RagChatService ragChatService;
/**
* 上传文档到知识库
*/
@PostMapping("/upload")
public String uploadDocument(@RequestParam("file") MultipartFile file) throws Exception {
return ragService.uploadDocument(file);
}
/**
* RAG问答接口
*/
@GetMapping("/chat")
public String ragChat(@RequestParam String query) {
return ragChatService.ragChat(query);
}
}
启动项目后,先调用/rag/upload接口上传文档,再调用/rag/chat接口,即可基于上传的文档进行问答,完全不会出现幻觉。
误区1:Chunk拆分越小,检索效果越好
误区2:检索结果越多,LLM回答越准确
误区3:嵌入模型维度越高,效果越好
误区4:RAG能完全解决LLM的幻觉问题
上一章我们讲了RAG,解决了LLM的知识问题,这一章我们讲Skill,解决LLM的执行问题,让LLM从“只能说”变成“既能说,又能做”。
LLM有四个原生能力边界,是自身无法突破的,必须通过Skill解决:
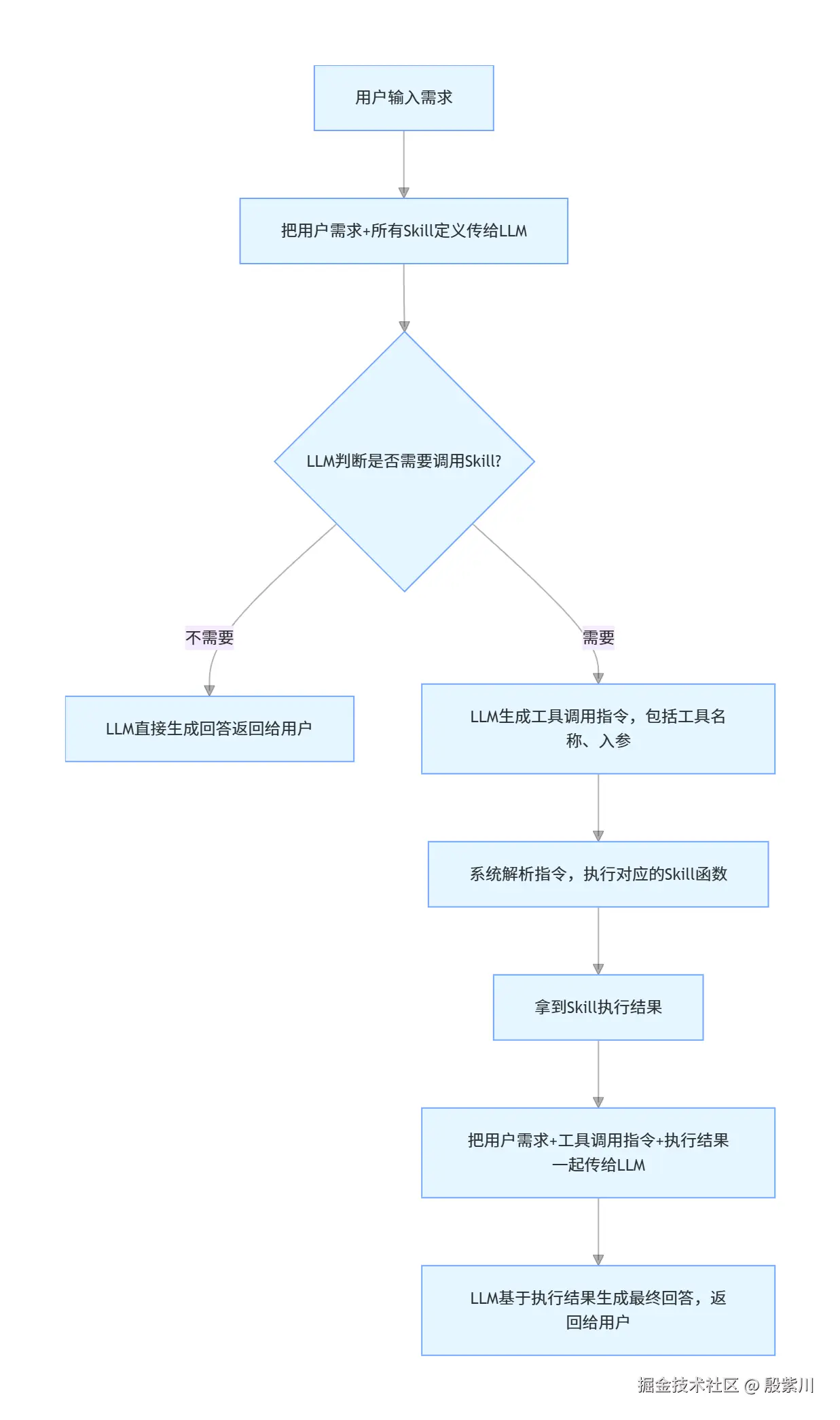
很多人好奇,LLM是怎么知道什么时候要调用工具、怎么生成正确入参的?其实Function Calling的底层原理完全符合LLM的核心本质——token概率预测。
LLM的Function Calling能力,是在SFT(有监督微调)阶段训练出来的。训练时,工程师会给模型喂大量的「用户需求-工具调用-执行结果-最终回答」配对数据,让模型学习:
经过大量训练,模型就掌握了Function Calling能力,能自主判断并正确调用工具。
核心细节:Skill的定义是每次调用LLM时,和用户需求一起传给模型的,不是提前写到模型里的。你可以随时新增、修改、删除Skill,不需要微调模型,只要在调用时把最新的Skill定义传给LLM,它就能理解并使用,这是Skill灵活性的核心原因。
所有主流LLM都支持JSON Schema格式的Skill定义,一个标准的Skill定义包含以下核心部分:
name:Skill的名称,必须清晰直观,让LLM一眼看懂用途;description:函数的详细描述,说明功能、用途、适用场景,是LLM判断是否调用的核心依据;parameters:入参定义,用JSON Schema描述每个参数的名称、类型、描述、是否必填;required:必填参数列表。标准的天气查询Skill定义示例:
{
"type": "function",
"function": {
"name": "getCurrentWeather",
"description": "查询指定城市的实时天气情况,包括天气状况、温度、风力、湿度等信息",
"parameters": {
"type": "object",
"properties": {
"city": {
"type": "string",
"description": "要查询的城市名称,比如:上海、北京、广州,必须是中文的城市名称"
},
"province": {
"type": "string",
"description": "城市所在的省份,可选参数,当城市名称有重名时传入"
}
},
"required": ["city"]
}
}
}
Spring AI 1.0.0对工具调用提供了原生支持,通过@Tool注解即可快速定义Skill,框架会自动处理工具定义、LLM工具调用指令解析、函数执行、结果回传的完整流程,无需手动处理底层细节。
package com.ken.llm.demo.skill;
import dev.langchain4j.agent.tool.Tool;
import org.springframework.stereotype.Component;
import java.util.List;
import java.util.Random;
/**
* Agent可用的工具类
* 作者:Ken
*/
@Component
public class AgentTools {
/**
* 查询指定城市的实时天气
* @param city 要查询的城市名称
* @return 天气信息
*/
@Tool("查询指定城市的实时天气情况,包括天气状况、温度、风力、湿度等信息")
public String getCurrentWeather(String city) {
System.out.println("LLM调用天气查询Skill,查询城市:" + city);
Random random = new Random();
String[] weathers = {"晴", "多云", "阴", "小雨", "中雨", "大雨"};
int minTemp = 10 + random.nextInt(10);
int maxTemp = minTemp + 5 + random.nextInt(10);
return String.format("城市:%s,天气:%s,温度:%d-%d℃,风力:东风%d级,湿度:%d%%",
city, weathers[random.nextInt(weathers.length)], minTemp, maxTemp,
1 + random.nextInt(5), 50 + random.nextInt(30));
}
/**
* 生成Excel文件
* @param fileName Excel文件名称,不需要带后缀
* @param headers Excel表头列表
* @param data Excel数据行列表
* @return 生成结果
*/
@Tool("生成Excel文件,支持自定义表头和数据,返回生成的文件保存路径")
public String generateExcel(String fileName, List<String> headers, List<List<String>> data) {
System.out.println("LLM调用Excel生成Skill,生成文件:" + fileName);
try {
String filePath = "D:/excel/" + fileName + ".xlsx";
// 实际业务中替换为EasyExcel生成逻辑
Thread.sleep(1000);
return "Excel文件生成成功,保存路径:" + filePath;
} catch (Exception e) {
return "Excel文件生成失败:" + e.getMessage();
}
}
}
package com.ken.llm.demo.controller;
import com.ken.llm.demo.skill.AgentTools;
import lombok.RequiredArgsConstructor;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
/**
* Skill工具调用Controller
* 作者:Ken
*/
@RestController
@RequestMapping("/skill")
@RequiredArgsConstructor
public class SkillController {
private final ChatClient chatClient;
private final AgentTools agentTools;
/**
* 支持Skill调用的对话接口
* @param prompt 用户输入的需求
* @return LLM的最终回答
*/
@GetMapping("/chat")
public String skillChat(@RequestParam String prompt) {
return chatClient.prompt()
.user(prompt)
.functions(agentTools) // 注册可用的Skill
.call()
.content();
}
}
启动项目后,访问今天上海的天气怎么样?,即可看到LLM自动调用天气查询Skill,返回准确的天气信息;访问帮我生成一个订单数据报表Excel,表头是订单号、用户名称、订单金额、下单时间,数据是3条测试数据,即可看到LLM自动调用Excel生成Skill,完成文件生成。
Skill的描述必须精准、无歧义
description必须清晰说明功能、适用场景与不适用场景,参数的description必须详细说明含义、格式要求与示例,描述越精准,LLM调用的准确率越高。Skill的职责必须单一,粒度合适
必须做严格的入参校验与异常处理
必须保证Skill的幂等性
必须做严格的安全管控
控制单次调用的Skill数量
误区1:LLM能100%正确调用Skill,不会出错
误区2:Skill的描述越详细越好,参数越多越好
误区3:所有业务逻辑都应该封装成Skill给LLM调用
前面三章我们分别讲了LLM、RAG、Skill三个核心组件,这一章我们讲Agent,它是把三个组件整合起来,实现真正自主智能的终极形态。
我们先举一个例子,就能明白Agent的核心价值: 用户需求:“帮我做一份2026年Q2上海浦东地区Java开发工程师的团队招聘计划,要求包括:1. 初级、中级、高级三个岗位的JD;2. 每个岗位的薪资范围,参考行业平均水平;3. 招聘渠道和预算;4. 完整的面试流程;5. 最终生成可直接使用的Excel招聘计划表。”
完成这个需求,需要做这些事情:
纯LLM、RAG、Skill都无法完成这个需求:纯LLM没有实时数据、无法生成Excel;RAG只能解决知识检索;Skill只能完成单个工具调用,无法自主拆解任务、多轮迭代。而Agent能完美解决这个问题,它的核心价值是:把用户的最终目标,变成可执行的任务计划,自主调用LLM、RAG、Skill,一步步执行、迭代优化,最终完成目标,无需用户逐步骤指令和干预。
简单来说:
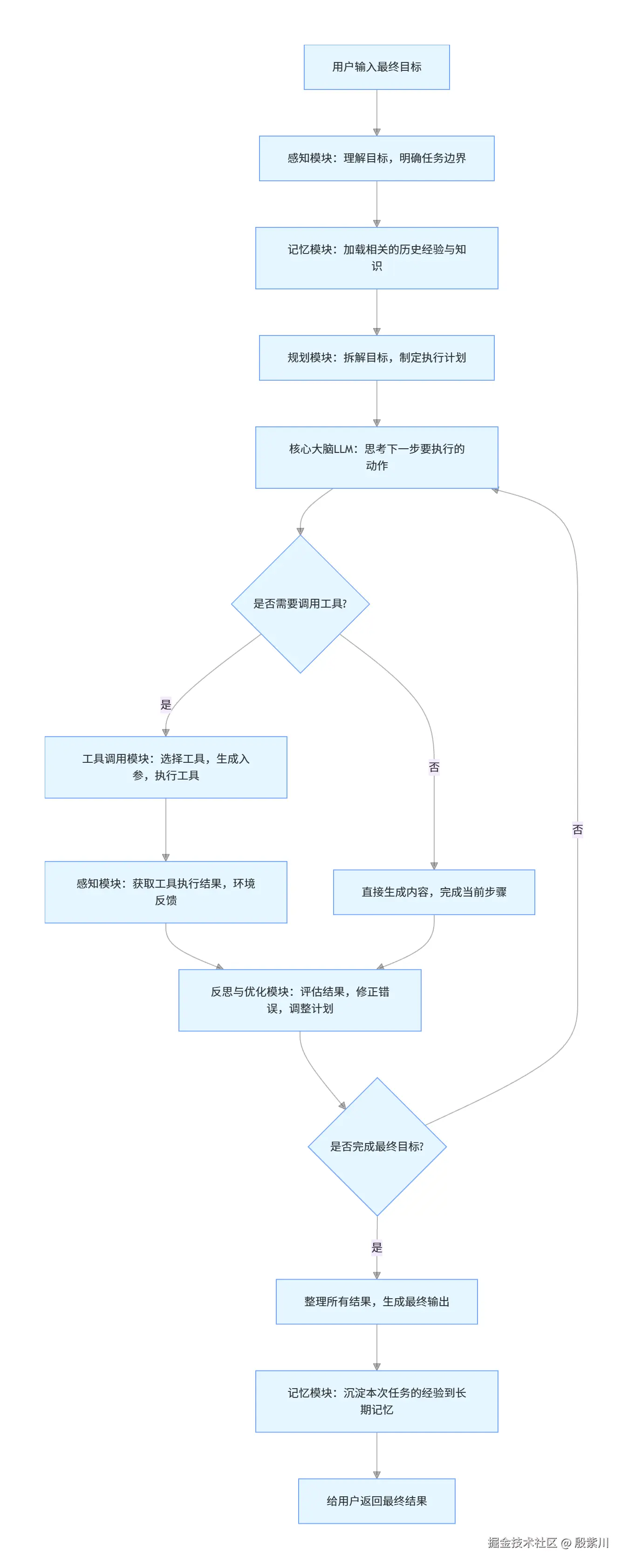
目前行业内最主流、最成熟、落地最广泛的Agent架构,是Google提出的ReAct架构,几乎所有主流Agent框架(LangChain、Spring AI、Semantic Kernel)都是基于这个架构实现的。
ReAct的全称是Reasoning + Acting,核心思想是模拟人类解决问题的方式:先思考(推理),然后行动,然后观察行动结果,再基于结果进一步思考,再行动,直到完成目标。
ReAct架构的核心闭环是四步,循环执行直到完成目标:
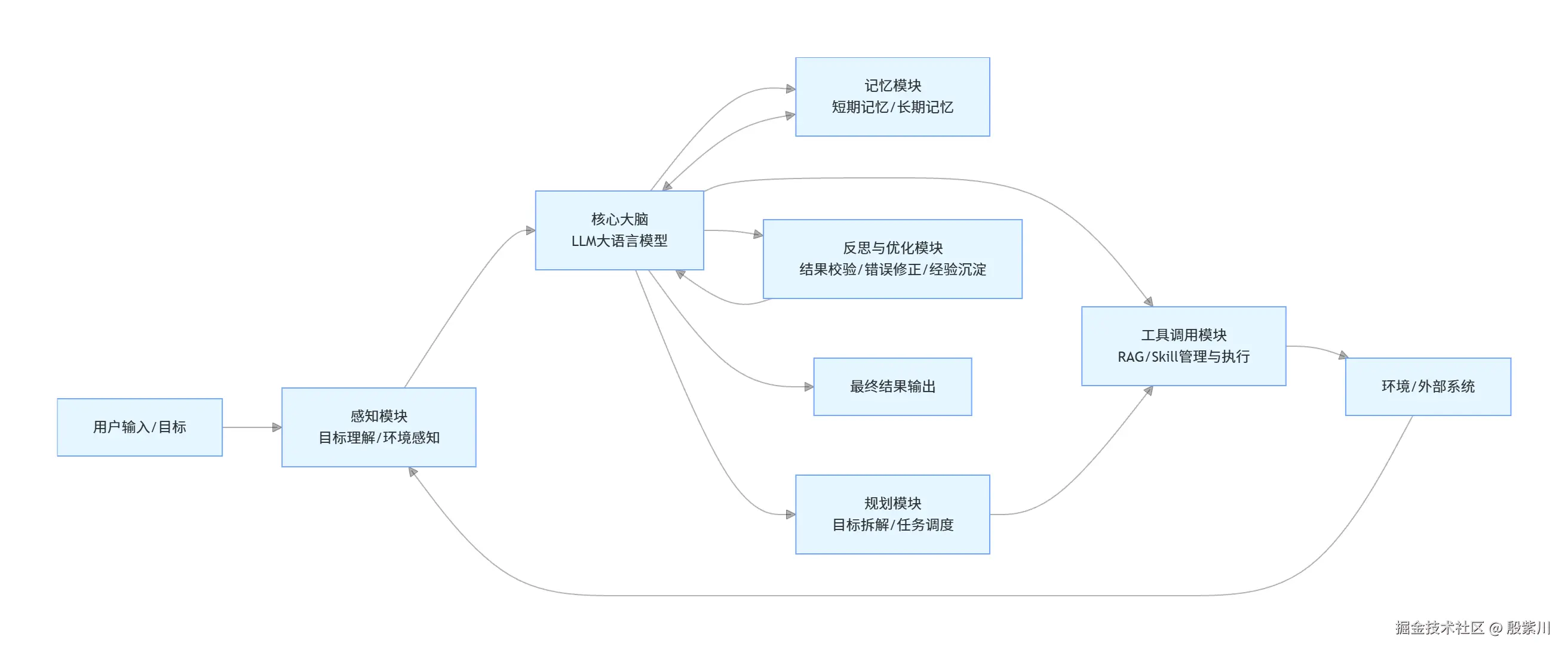
一个完整的Agent包含六大核心模块,缺一不可,架构图如下:
核心大脑:LLM大语言模型
感知模块
记忆模块
规划模块
工具调用模块
反思与优化模块
目前Spring AI的Agent支持还在完善中,而LangChain4j是Java生态最成熟的大模型应用开发框架,对Agent的支持非常完善,以下代码基于LangChain4j 0.32.0。
引入Maven依赖:
<!-- LangChain4j 核心依赖 -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j</artifactId>
<version>0.32.0</version>
</dependency>
<!-- LangChain4j 豆包大模型支持 -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-doubao</artifactId>
<version>0.32.0</version>
</dependency>
<!-- Lombok -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
package com.ken.llm.demo.agent;
import dev.langchain4j.agent.tool.Tool;
import org.springframework.stereotype.Component;
import java.math.BigDecimal;
import java.util.*;
/**
* Agent可用的工具类
* 作者:Ken
*/
@Component
public class AgentTools {
/**
* 查询指定城市、指定岗位的实时行业薪资范围
*/
@Tool("查询指定城市、指定技术岗位的行业平均薪资范围,单位为元/月,返回初级、中级、高级三个级别的薪资区间")
public String getIndustrySalaryRange(String city, String jobPosition) {
System.out.println("Agent调用薪资查询工具,城市:" + city + ",岗位:" + jobPosition);
// 生产环境对接第三方薪资调研平台API/企业内部薪酬数据库
Map<String, Map<String, String>> salaryData = new HashMap<>();
// 上海Java开发岗位薪资数据
Map<String, String> javaSalary = new HashMap<>();
javaSalary.put("初级", "8000-15000元/月");
javaSalary.put("中级", "15000-25000元/月");
javaSalary.put("高级", "25000-40000元/月");
salaryData.put("上海Java开发工程师", javaSalary);
String key = city + jobPosition;
if (salaryData.containsKey(key)) {
return city + jobPosition + "行业薪资范围:" + salaryData.get(key);
}
return "暂无该城市该岗位的薪资数据";
}
/**
* 查询指定岗位的标准JD模板
*/
@Tool("获取指定技术岗位的标准JD模板,包含岗位职责、任职要求的规范框架")
public String getStandardJdTemplate(String jobLevel) {
System.out.println("Agent调用JD模板工具,岗位级别:" + jobLevel);
Map<String, String> templateMap = new HashMap<>();
templateMap.put("初级", """
岗位职责:
1. 参与项目的功能开发与单元测试,保障代码质量
2. 配合资深工程师完成技术方案落地,解决开发过程中的基础问题
3. 编写项目相关的技术文档与注释
任职要求:
1. 本科及以上学历,计算机相关专业
2. 掌握Java基础语法与面向对象编程思想
3. 了解Spring Boot、MyBatis等主流框架
4. 具备良好的代码规范与学习能力
""");
templateMap.put("中级", """
岗位职责:
1. 负责业务模块的设计与开发,独立完成核心功能实现
2. 参与系统架构设计与技术方案评审,提出优化建议
3. 解决项目中的复杂技术问题,保障系统稳定性
4. 指导初级工程师,参与代码评审与技术分享
任职要求:
1. 本科及以上学历,计算机相关专业,3年以上Java开发经验
2. 精通Java核心技术,熟悉JVM原理、多线程编程
3. 精通Spring Cloud微服务架构,有分布式系统开发经验
4. 熟悉MySQL数据库优化、Redis缓存中间件使用
5. 具备良好的问题排查能力与技术攻坚能力
""");
templateMap.put("高级", """
岗位职责:
1. 负责系统整体架构设计与技术选型,保障系统高可用、高性能、可扩展
2. 主导核心技术难题攻坚,制定技术规范与开发标准
3. 参与技术团队建设与人才培养,推动技术能力提升
4. 对接业务需求,制定技术落地路线,把控项目技术风险
任职要求:
1. 本科及以上学历,计算机相关专业,5年以上Java开发经验,2年以上架构设计经验
2. 精通Java分布式系统架构设计,有大型微服务项目落地经验
3. 深入理解JVM底层原理、MySQL内核、分布式事务、高可用架构设计
4. 具备丰富的线上问题排查与性能优化经验
5. 具备良好的团队管理能力与技术前瞻性
""");
return templateMap.getOrDefault(jobLevel, "暂无该级别的JD模板");
}
/**
* 查询指定城市的主流招聘渠道与成本数据
*/
@Tool("查询指定城市的主流招聘渠道、收费模式与人均招聘成本数据")
public String getRecruitmentChannelInfo(String city) {
System.out.println("Agent调用招聘渠道查询工具,城市:" + city);
return """
上海地区主流招聘渠道信息:
1. 招聘网站:BOSS直聘、智联招聘、前程无忧,年费3000-10000元/账号,人均招聘成本800-1500元
2. 内推渠道:公司内部员工推荐,人均招聘成本1000-2000元(推荐奖金),候选人匹配度最高
3. 猎头渠道:中高端岗位招聘,收费为候选人年薪的20%-25%,适合高级岗位
4. 校园招聘:高校双选会、校企合作,人均成本500-1000元,适合初级岗位校招
""";
}
/**
* 生成招聘计划Excel文件
*/
@Tool("生成招聘计划Excel文件,传入招聘岗位列表、薪资范围、招聘渠道、预算等信息,返回文件保存路径")
public String generateRecruitmentExcel(
@dev.langchain4j.agent.tool.P("招聘岗位列表,包含岗位名称、级别、招聘人数") List<Map<String, Object>> jobList,
@dev.langchain4j.agent.tool.P("招聘总预算,单位:元") BigDecimal totalBudget,
@dev.langchain4j.agent.tool.P("招聘周期,单位:天") Integer cycleDays
) {
System.out.println("Agent调用Excel生成工具,生成招聘计划文件");
try {
String filePath = "D:/recruitment/2026_Q2_Java团队招聘计划.xlsx";
// 生产环境替换为EasyExcel/POI的真实生成逻辑
Thread.sleep(1000);
return "招聘计划Excel文件生成成功,共包含" + jobList.size() + "个岗位,总预算" + totalBudget + "元,招聘周期" + cycleDays + "天,文件保存路径:" + filePath;
} catch (Exception e) {
return "Excel文件生成失败:" + e.getMessage();
}
}
/**
* 查询实时天气工具(保留基础工具,兼容多场景)
*/
@Tool("查询指定城市的实时天气情况,包括天气状况、温度、风力、湿度等信息")
public String getCurrentWeather(String city) {
System.out.println("Agent调用天气查询工具,查询城市:" + city);
Random random = new Random();
String[] weathers = {"晴", "多云", "阴", "小雨", "中雨", "大雨"};
int minTemp = 10 + random.nextInt(10);
int maxTemp = minTemp + 5 + random.nextInt(10);
return String.format("城市:%s,天气:%s,温度:%d-%d℃,风力:东风%d级,湿度:%d%%",
city, weathers[random.nextInt(weathers.length)], minTemp, maxTemp,
1 + random.nextInt(5), 50 + random.nextInt(30));
}
}
基于LangChain4j官方标准的ReAct Agent实现,完全符合Google ReAct论文的规范,支持自主规划、工具调用、多轮迭代,代码可直接运行。
package com.ken.llm.demo.agent;
import dev.langchain4j.model.chat.ChatLanguageModel;
import dev.langchain4j.model.doubao.DoubaoChatModel;
import dev.langchain4j.agent.tool.ToolSpecification;
import dev.langchain4j.agent.tool.Tools;
import dev.langchain4j.service.AiServices;
import dev.langchain4j.service.SystemMessage;
import dev.langchain4j.service.UserMessage;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.util.List;
/**
* ReAct Agent 核心配置与实现
* 作者:Ken
*/
@Configuration
public class ReActAgentConfig {
// 豆包API密钥,从火山引擎控制台获取
private static final String API_KEY = "你的豆包API密钥";
// 豆包模型名称,推荐使用推理能力强的pro版本
private static final String MODEL_NAME = "doubao-pro-32k";
/**
* 注册LLM模型实例
*/
@Bean
public ChatLanguageModel chatLanguageModel() {
return DoubaoChatModel.builder()
.apiKey(API_KEY)
.modelName(MODEL_NAME)
.temperature(0.3) // Agent场景用低温度,保证规划的稳定性
.maxTokens(4096)
.build();
}
/**
* Agent服务接口,定义Agent的能力
*/
public interface RecruitmentAgent {
@SystemMessage("""
你是一名专业的企业招聘专家,也是一个具备自主规划、工具调用、迭代优化能力的智能Agent。
你的核心任务是根据用户的招聘需求,完成完整的招聘计划制定,必须严格遵守以下规则:
1. 先理解用户的最终招聘目标,拆解成可执行的子任务,制定清晰的执行计划;
2. 所有薪资数据、招聘渠道信息、JD模板,必须通过调用对应的工具获取,绝对不能编造;
3. 每完成一个子任务,要检查结果是否符合要求,再进行下一个步骤;
4. 所有工具调用必须严格按照参数要求传入正确的参数,禁止传入非法值;
5. 最终必须生成完整的招聘计划,包含JD、薪资范围、招聘渠道、预算、面试流程、Excel文件生成;
6. 执行过程中要清晰说明每一步的执行情况,最终结果要专业、完整、可直接落地使用。
""")
String executeRecruitmentPlan(@UserMessage String userDemand);
}
/**
* 注册Agent实例,绑定LLM模型与工具
*/
@Bean
public RecruitmentAgent recruitmentAgent(ChatLanguageModel chatLanguageModel, AgentTools agentTools) {
// 扫描工具类中的@Tool注解,生成工具规范
List<ToolSpecification> toolSpecifications = Tools.toolSpecificationsFrom(agentTools);
// 构建Agent实例
return AiServices.builder(RecruitmentAgent.class)
.chatLanguageModel(chatLanguageModel)
.tools(toolSpecifications, agentTools)
.build();
}
}
package com.ken.llm.demo.controller;
import com.ken.llm.demo.agent.ReActAgentConfig;
import lombok.RequiredArgsConstructor;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
/**
* Agent 对外接口Controller
* 作者:Ken
*/
@RestController
@RequestMapping("/agent")
@RequiredArgsConstructor
public class AgentController {
private final ReActAgentConfig.RecruitmentAgent recruitmentAgent;
/**
* 执行招聘计划Agent任务
* @param demand 用户的招聘需求
* @return Agent的最终执行结果
*/
@GetMapping("/recruitment/plan")
public String executeRecruitmentPlan(@RequestParam String demand) {
return recruitmentAgent.executeRecruitmentPlan(demand);
}
}
启动项目后,访问接口: 帮我做一份2026年Q2上海浦东地区Java开发工程师的团队招聘计划,需要招初级2人、中级3人、高级1人,招聘周期60天
Agent会自动完成以下操作:
整个过程无需人工干预,Agent自主完成所有步骤,完美实现复杂任务的全自动执行。
基于大量生产级Agent项目落地经验,总结出Java开发者必须遵守的8条核心规范,直接决定Agent的稳定性与落地效果:
优先选择成熟的规划策略,拒绝过度设计
严格管控Agent的工具边界,拒绝万能Agent
完善的记忆管理,避免上下文溢出与信息丢失
强制的结果校验与错误重试机制
严格的安全管控,杜绝业务风险
完善的可观测性,快速定位问题
明确的任务边界,给Agent设置“刹车机制”
优先使用Java生态成熟框架,避免重复造轮子
误区1:Agent越复杂、能力越多,效果越好
误区2:Agent能完全替代人工,实现全自动化
误区3:所有场景都应该用Agent,不用Agent就是落后
误区4:Agent的效果只取决于LLM的能力
前面我们分别拆解了LLM、RAG、Skill、Agent的核心原理与实战,这一章我们讲清楚四个技术的协同关系,以及不同业务场景下的选型策略,让Java开发者面对业务需求时,能快速做出正确的技术选型,避免过度设计与选型错误。
四个技术不是孤立的,而是从下到上的层级依赖关系,形成完整的企业级大模型应用技术栈,我们用架构图清晰展示:
核心协同逻辑:
我们整理了Java开发者最常遇到的8类业务场景,给出明确的技术选型方案,避免踩坑:
| 业务场景 | 核心需求 | 推荐技术选型 | 不推荐选型 |
|---|---|---|---|
| 企业内部知识库问答 | 基于内部文档、产品手册、规章制度,实现精准问答,无幻觉 | LLM + RAG | 纯LLM、Agent(过度设计) |
| 智能客服 | 基于产品知识库,回答用户问题,解决售后咨询 | LLM + RAG + 简单Skill(订单查询工具) | 全功能Agent(复杂度高,稳定性不足) |
| 代码生成/优化 | Java代码生成、代码评审、Bug修复、注释生成 | 纯LLM + 代码优化Skill | RAG(无特殊知识库需求无需使用)、Agent |
| 数据查询与报表生成 | 自然语言转SQL,查询业务数据库,生成数据报表 | LLM + Skill(SQL生成/查询/Excel生成) | 纯LLM(无法查询数据库)、复杂Agent |
| 内容创作 | 文案、文档、报告、公众号文章创作 | 纯LLM + RAG(行业知识增强) | Skill、Agent(无执行需求无需使用) |
| 自动化运维 | 自然语言指令执行服务器监控、日志查询、服务重启等运维操作 | LLM + Skill(运维工具) + 严格的安全管控 | 无人工审核的全自动Agent(风险极高) |
| 复杂业务流程自动化 | 完整的招聘计划、项目管理、合同审核、财务报销等多步骤业务流程 | Agent + RAG + Skill | 纯LLM、零散工具调用(无法完成多轮任务) |
| 个人助手 | 日程管理、待办提醒、信息查询、内容整理 | Agent + 基础Skill + 轻量RAG | 复杂架构(个人场景无需过度设计) |
基于我多年Java开发与大模型应用落地的经验,总结出10条Java开发者必须遵守的黄金法则,避开90%的落地坑,让你的项目从demo快速走向生产级落地:
各位Java开发者朋友们,大模型技术的发展,不是对Java后端开发者的替代,而是给我们打开了全新的增量市场,让我们能用熟悉的技术栈,开发出更智能、更有价值的企业级应用。
LLM、RAG、Skill、Agent这四个核心技术,本质上都是我们解决业务问题的工具。想要真正用好这些工具,核心不是堆砌概念、盲目追新,而是彻底搞懂它们的底层逻辑、能力边界、适用场景,结合Java生态的成熟框架,落地到真实的业务中,创造真正的业务价值。

