
alookdlna投屏t
17.07MB · 2026-04-04

前几天在找数字人方案,需求是把一段产品介绍的录音配上一个"真人讲解"的视频。以前这种活要么找真人拍,要么用那种很假的数字人工具,嘴型对不上看着难受。
然后发现了 InfiniteTalk 这个模型,试了一下,说实话效果比我预期好不少。
你给一张人像照片 + 一段音频,它生成一个这个人在"说话"的视频。唇形跟着音频走,头部和身体也会有自然的微动。最长能做 10 分钟。
不是那种嘴巴一张一合的粗糙效果,是真的能看出在说哪个字的那种同步程度。
装 SDK,拿 Key:
pip install wavespeed
Key 在 wavespeed.ai/settings/api-keys 创建。准备两个文件:一张正面人像照,一段语音。
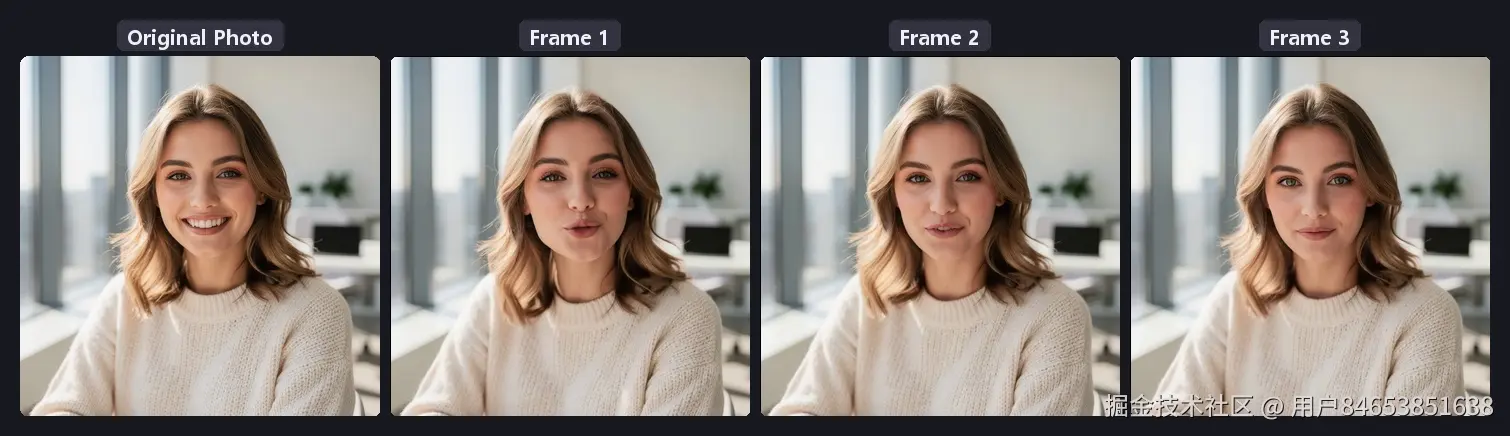
我用的这张照片:
from wavespeed import Client
client = Client(api_key="wsk_xxxxxxxx")
image_url = client.upload("./portrait.jpg")
audio_url = client.upload("./speech.mp3")
output = client.run(
"wavespeed-ai/infinitetalk",
{
"image": image_url,
"audio": audio_url,
"resolution": "720p"
},
timeout=600.0
)
print(output["outputs"][0])
就这么多。端点 wavespeed-ai/infinitetalk,核心参数三个:image、audio、resolution。
先用了一段 30 秒的中文产品介绍,正常语速。唇形同步挺准的,头部会跟着语气有轻微的点头和偏转。生成等了大概 5 分钟,官方说每 1 秒视频需要 10-30 秒生成时间,差不多。
然后换了段英文试试——嗯,效果居然比中文好一点。官方文档也说了 prompt 建议用英文,估计训练数据英文占比更大。
最惊喜的是唱歌。纯粹好奇传了一段哼歌的音频上去,嘴型居然也能跟上。没有说话那么精准,但看着不违和,这个我没想到。
prompt 参数坑了我一次。这个模型有个可选的 prompt,用来控制表情姿态。我一开始写了一大段中文描述,结果生成出来脸上全是噪点。后来看到官方文档写的:
改成简短英文 "natural head movements, subtle expressions" 就好了。或者干脆别写,让模型自己来。
另一个坑是 mask_image。如果照片里有多个人,可以用 mask 指定让谁说话。但我手贱把原图直接当 mask 传了进去——输出全黑。mask 应该只画你要动的那个人脸区域,别把整张图传进去。
还有就是音频质量。背景噪音大的录音,出来的唇形会乱。建议先降噪再传。
生成时间也要注意,30 秒视频等 5 分钟,1 分钟的要等十几分钟。代码里 timeout 记得设大,默认值可能不够。
480p 是 0.06/秒。最低收 5 秒的钱。
算下来 1 分钟 720p 大概 $3.6,约 25 块r民币。比找真人拍便宜太多了。但如果一天要出几十条,成本也不低,可以考虑用 480p 省一半。
我觉得最合适的场景是产品介绍和教学视频——不想露脸或者没时间拍的时候,传张照片配上录音就行。做多语言版本也方便,同一张照片配不同语言的音频就能出不同语言的视频。
但别指望它做大幅度的肢体动作,它主要是头部和面部在动,身体动作很小。侧脸照片效果也不好,正面或者微侧最佳。
模型文档:wavespeed.ai/models/wave…
SDK:github.com/WaveSpeedAI…

