弗兰的悲惨之旅
99.73M · 2026-04-04

字符串处理在日常开发中非常常见,尤其是在日志分析、接口数据处理、文本清洗等场景中。这一篇把最常用的几个点串起来,了解实际应用中高效的字符串处理。
切片的语法是 [start:end:step],end 是开区间,取不到。
text = "Python大法好"
# 切片口诀:[开始:结束:步长]
print(text[0:6]) # Python
print(text[::-1])
# 好法大nohtyP(反转字符串)
print(text[-2:])
# 法好(最后两个字符)
2. ### 字符串拼接
words = ["我", "爱", "Python"]
# 每次`+`都创建新对象
result = ""
for w in words:
result += w # 内存爆炸!
# 推荐使用 `join`
result = "".join(words)
# 我爱Python
3. ### 常用方法
sentence = " data science, machine learning, AI "
# 去掉首尾空格
print(sentence.strip())
# 按逗号切分
parts = sentence.strip().split(", ")
print(parts)
# ['data science', 'machine learning', 'AI']
# 用 / 重新拼接
print("/".join(parts))
# data science/machine learning/AI
# 替换
print(sentence.replace("AI", "Deep Learning"))
相比 % 或 format,f-string 更直观,也更易读。
name = "Alice"
score = 98.5
# 使用 `%` 写法
print("Name: %s, Score: %.1f" % (name, score))
# f-string 写法
print(f"Name: {name}, Score: {score:.1f}")
# 还可以直接放表达式
print(f"及格线:{score:.0f}分,{'通过' if score >= 60 else '不及格'}")
常见用法是构造日志或接口返回:
user_id = 1001
status = "success"
log = f"[INFO] user={user_id}, status={status}"
print(log)
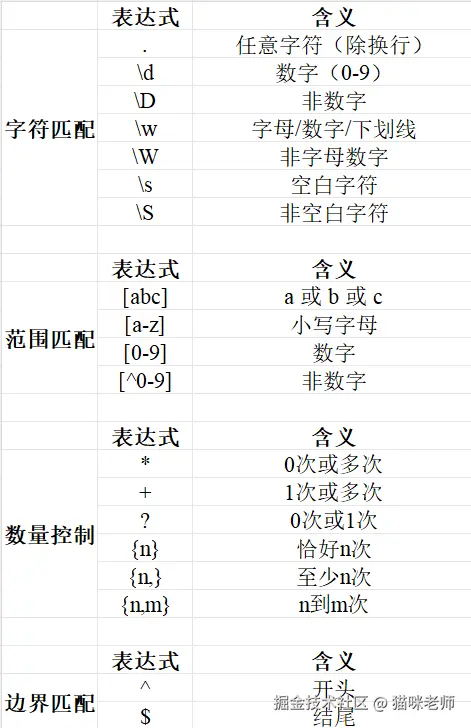
当字符串结构不固定时,简单的 split 就不够用了,这时可以用 re,也就是正则表达式。
正则表达式使用规则:
示例:
import re
text = "用户手机号:138-1234-5678,备用:021-87654321"
# findall:找出所有匹配项
phones = re.findall(r'd{3}[-d]+', text)
print(phones) # ['138-1234-5678', '021-87654321']
# sub:替换(脱敏处理)
clean = re.sub(r'd{3}-d{4}-d{4}', '***-****-****', text)
print(clean) # 用户手机号:***-****-****,备用:021-87654321
| 场景 | 用什么 |
|---|---|
| 按分隔符切分/拼接 | split / join |
| 字符串格式化输出 | f-string |
| 模式匹配/数据清洗 | re.findall / re.sub |

