本文入选 CVPR 2026
CVPR(IEEE/CVF Conference on Computer Vision and Pattern Recognition)IEEE国际计算机视觉与模式识别会议,主要内容是计算机视觉与模式识别技术。
论文主页:arxiv.org/abs/2603.08…
一、为什么固定 CFG scale 不够好?
标准 CFG: ϵ^ω(xt,t,y)=ϵ^∅(xt,t)+ω(ϵ^c(xt,t,y)−ϵ^∅(xt,t)). 常见做法使用固定 ω,但它默认“条件/无条件差异在所有时间步同等重要”。我们的理论与实证显示:这种差异在扩散时间上是动态变化的,因此固定 ω 难以同时兼顾早期结构形成与后期精确对齐。
二、核心理论(VP-SDE 重点):score discrepancy 的严格上界(论文 Theorem 1)
VP-SDE 前向扩散: dxt=−21β(t)xtdt+β(t)dwt.
Theorem 1(VP-SDE Score MSE Bound)
假设样本空间有界且闭。令 p(x,t) 与 p~(x,t) 为由初始分布 p(x0) 与 p~(x0) 诱导的时刻 t 的密度(论文中取 p~(x,t)=p(x,t∣y))。则 score 差异满足一致上界: ∣∇logp(x,t)−∇logp~(x,t)∣≤σ2(t)α(t)C,∀x∈supp, t≥0, 其中 C 为常数, α(t)=exp(−21∫0tβsds),σ(t)=α(t)∫0tα2(s)βsds.
重参数化 t′=21∫0tβsds 后(论文式(9)): ∣∇logp(x,t)−∇logp(x,t∣y)∣≤1−e−2te−tC, 当 t 较大时呈现 O(e−t) 的指数衰减趋势。
结论: 在前向扩散中,条件/无条件分布会逐步“趋同”,其 score 差异上界随时间衰减;对应到反向采样,越接近数据(t→0)越需要更强、更精细的条件引导。
三、方法:C²FG(指数控制的 time-dependent CFG)
我们将固定 ω 替换为时间控制函数: ω(t)=ω0exp(λ(1−tmaxt)). 并在采样时使用:
ϵ^cω(xt)=ϵ^∅(xt)+ω(t)[ϵ^c(xt)−ϵ^∅(xt)].
为什么这种形式好用?
- 与理论与观测一致: 差异呈指数趋势,调度函数自然对齐;
- 连续可导更稳定: 比分段/线性更平滑;
- 只需两个超参: ω0(最大强度)与 λ(衰减速率);
- training-free、plug-and-play: 无需额外训练或外部分类器。
四、实验结果展示
Figure 1:理论预测的“时间趋势”在真实模型中成立
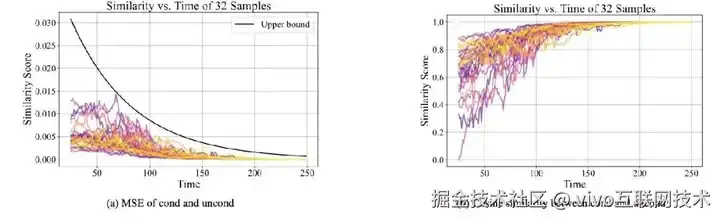
- (a) 条件与无条件 score 的 MSE 随时间变化,并被一个随 t→+∞ 逼近 0 的函数上界约束;
- (b) 余弦相似度在反向采样过程中下降,说明二者在幅值与方向上都逐渐分离。
Figure 2:CFG vs.C²FG 的采样流程比较

- CFG:ω 为常数;
- C2FG:ω(t) 为随时间变化的衰减控制函数。
Figure 3:C²FG的直观示意(并解释 interval guidance 可视为特例/可融合)

论文指出:区间 guidance 的“只在有效区间用引导”可以在我们的框架下得到解释;同时C²FG+ interval可以进一步减少不必要的模型评估开销(把引导放在更“有效”的阶段)。
Figure 4:2D Toy Example(更少 outliers,更贴近目标条件分布)
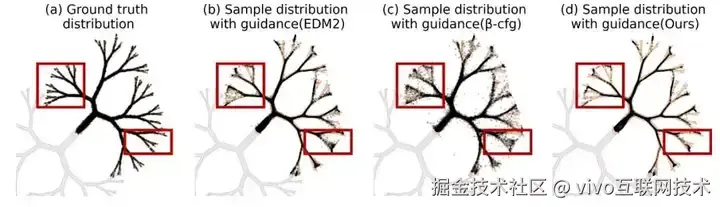
- (b) EDM2(ω=1)出现 outliers;
- (c) β-CFG(α=β=2, ω=1)outliers 更多;
- (d) C2FG(ω0=1, λ=0.6)outliers 更少,匹配目标更好。
Figure 5:ImageNet 质化对比(纹理更清晰、畸变更少)

红框示例显示C²FG 能有效缓解失真与纹理模糊;在不同采样器与步数下都能保持一致改进。
ImageNet Class-Conditional(多架构、多分辨率、多采样器综合评估)
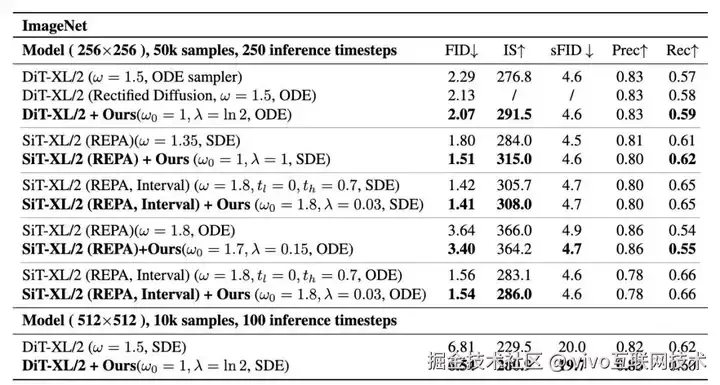
DiT-XL/2 (256×256, ODE)
- baseline:FID 2.29,IS 276.8
- C²FG(ω0=1, λ=ln2):FID 2.07,IS 291.5
SiT-XL/2 (REPA, 256×256, SDE)(强基线也能继续提升)
- baseline:FID 1.80,IS 284.0
- C²FG(ω0=1, λ=1):FID 1.51,IS 315.0
SiT-XL/2 (REPA, 256×256, SDE)(强基线也能继续提升)
- interval baseline:FID 1.42,IS 305.7
- interval +C²FG:FID 1.41,IS 308.0
DiT-XL/2 (512×512, SDE, 100 steps)
- baseline:FID 6.81,IS 229.5
- C²FG:FID 6.54,IS 280.9
引用:
C²FG:Control Classifier-Free Guidance via Score Discrepancy Analysis, CVPR 2026.


