汤锅
38.89M · 2026-04-02

【在线原创技术解析】随着大语言模型的全面爆发,我们每天都在与各种AI助手打交道,“Token”这个单词也被频频提及。前不久,全国科学技术名词审定委员会等权威机构在规范人工智能术语时,为它赋予了一个正式且中文名字:“词元”。

那么,这个“词元”到底是个什么东西?为什么在评估AI模型能力、计算API接口费用,甚至讨论AI记忆力时,都离不开它?今天,我们就来扒一扒“词元”在AI世界里究竟扮演着怎样的角色。
1 什么是词元?
要理解词元,我们首先要切换一下视角。人类阅读文章时,看到的是一个个字词;但计算机底层只认识0和1,它根本看不懂人类的文字。为了让AI能够阅读、理解并生成人类语言,科学家们必须把人类语言“切碎”,转换成机器能懂的数学符号。

“词元”,就是大语言模型处理文本的基本单位。你可以把它想象成搭建乐高城堡的基本积木块。一段完整的话输入给AI时,AI并不会把它当成一个整体,而是会先使用分词器将其切分成一个个的“词元”。
不同语言之间,词元的定义也不完全相同:
在英语中,一个词元可能是一个完整的单词,也可能是一个单词的一部分。例如“hamburger”汉堡包可能会被AI切分为“ham”和“burger”两个词元。甚至,一个单纯的逗号或句号也是一个单独的词元。
由于中文的复杂性,早期的AI模型可能把一个汉字当作一个词元。但随着国内大模型技术的进步,现在的模型已经能把常见的双字词组或多字成语打包压缩成一个词元,这大大提高了AI处理中文的效率。
2 词元到底有啥用?
了解了词元的概念,我们再来看看它在AI的实际运行中到底发挥着哪些不可替代的作用。简单来说,词元的作用可以概括为以下三个方面:
首先,AI模型本质上是一堆庞大复杂的数学公式,它把句子切碎,并给每一个切出来的词元分配一个唯一的数字ID,模型通过海量计算,推测出数字后面最可能跟着的“数字ID”是多少,最后再把这些预测出的数字翻译回人类的文字输出给你。

我们在使用AI时经常会听到一个词:上下文窗口。我们常说某个AI模型支持“128K”或“100万”上下文,这里的“K”和“万”,指的其实就是词元的数量。128K意味着这个模型一次性最多能记住并处理大约12.8万个词元的信息量,如果你的输入加上AI的回答超过了这个词元限制,AI就会忘记你最开始喂给它的资料。因此,词元直接决定了你能让AI一次性分析多长的财报,或者帮你写多长的代码。
如果你是AI开发者或者重度用户,一定会对“按Token计费”有所改变。在AI商业化的世界里,词元就是流通的货币。因为AI每阅读或生成一个词元,都需要消耗实打实的GPU算力和电力。
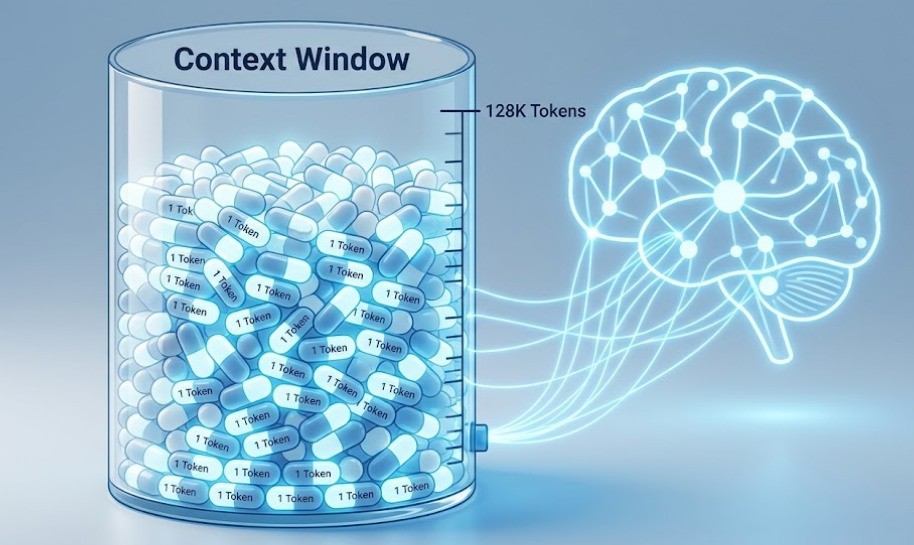
因此,各大AI厂商提供的API接口,无一例外都是按照处理的词元数量来收费的。输入了多少词元,模型又生成了多少词元,后台算得清清楚楚,这是AI行业最基础的商业模式。
3 理解词元,理解AI
“Token”有了新名字“词元”,这不仅是国内在AI术语规范化上迈出的一步,也标志着AI技术正越来越深入地融入我们的日常大众生活。各位以后在使用AI时,也就知道TA不是像我们人类一样阅读,而是有着自己的一套阅读方式。

