七彩喷射
87.32M · 2026-03-30

大势所趋,前端想继续深钻确实越来越难——这不是在制造焦虑,是我自己在认真想这件事:前端想转 JS 全栈 + AI,到底该怎么走? 以前写过一篇 学习 TailwindCSS 顺便打造个性化在线简历项目——没有 AI 帮我生成文章,自己查资料、折腾项目、踩坑填坑。那篇文章给我留下了土壤,也真的对找工作有所帮助。 现在同样的思路,不一样的是多了 AI 当队友 ^_^
前端或者程序员未来该怎么走?这个系列文章算是我的答案吧!先自己糙,不焦虑,相信自己,前端老油条 + AI = 产品、UI、前后端、测试运维全干。
另外还有个 Learn Claude Code 的项目也不错,准备边学边改着玩~
这个系列学习是开胃菜。吃完后,拿自己的项目开刀,做完整重构——打造全栈 + AI Agent Resume 项目,从头到尾一条龙: AI辅助产品 + UI设计 → NestJS 后端 + 数据库 → 前端 + AI 交互 → 部署上线
先立个 Flag:接下来的文章认真打磨,竭尽所能,打造精品,要是太监了请来评论区骂醒我
当然要是你感兴趣的话,点个赞 + 关注,我们一起干——行动起来,就不会焦虑了不是吗?
| 篇 | 主题 | 状态 |
|---|---|---|
| 第一篇(本篇) | 提示链 · 路由 · 并行化 |
| # | 你会学到 | 对应章节 |
|---|---|---|
| 1 | 复杂任务为什么要拆,怎么拆 | 第一章 |
| 2 | 「提示词 = PRD」——一个我自己推导出来的类比 | 第一章 |
| 3 | Agent 路由和后端路由,哪里一样,哪里不一样 | 第二章 |
| 4 | 规则路由和 LLM 路由,怎么选 | 第二章 |
| 5 | 并行化的本质不是"让所有任务都并行",而是识别依赖关系 | 第三章 |
| 6 | 从 Promise.all 到 Promise.allSettled——AI 调用的失败处理思路 | 第三章 |
刚开始做 AI 应用的时候,我踩过这些坑:
这些问题都有对应的解法,它们有一个统一的名字:Agent 设计模式。
就像软件工程里的设计模式(单例、工厂、观察者……)一样,Agent 设计模式是前人踩坑总结出来的最佳实践。学会它们,你就能系统性地构建高质量的 AI 应用,而不是每次都在瞎摸索。
本篇覆盖最基础也最常用的三个模式:提示链、路由、并行化。 掌握这三个,能解决 80% 的 Agent 开发场景。
说实话,学这本书之前,我对 Agent 的理解停留在"给 AI 一个任务,它自己搞定"这个层面。
打开第一章,第一个概念就是提示链。书里的定义是:
读完第一遍,我的第一反应是:这不就是流水线吗?
工厂流水线、CI/CD 流水线、前端的数据处理管道……本质都是同一件事:每个环节只做一件事,专注且可控。只不过这里的"工位"换成了 LLM 调用。
输入 → [步骤1] → 中间结果1 → [步骤2] → 中间结果2 → [步骤3] → 最终输出
理解了"是什么",我开始想"为什么"。
书里列了一堆单一提示词的问题:指令忽略、上下文偏离、错误传播、幻觉……看完感觉有点抽象,就自己想了个更直接的解释:
LLM 同时处理太多事,就像一个开发同时接了五个需求——每件事都做了,但每件事都没做好。
| 问题 | 说明 |
|---|---|
| 注意力分散 | LLM 同时处理太多事,质量下降 |
| 难以调试 | 出错了不知道哪一步的问题 |
| 无法复用 | 每次都要重写整个 Prompt |
| 超出上下文 | 复杂任务容易超 token 限制 |
这四个问题,其实是同一件事的四个面:任务边界不清晰。提示链做的,就是把边界划清楚。
学到这里,我突然想到一个类比,觉得比书里的解释更好记:
提示词就像 PRD(产品需求文档)。
PRD 写得越清晰,开发偏差越小,返工越少;提示词写得越精准,AI 输出越符合预期,"幻觉"越少。
这个类比是我自己推导出来的——因为我是前端开发,经常遇到 PRD 写得模糊导致开发返工的情况。某一刻读到"提示词要精准"这句话,脑子里直接蹦出来了:这不就是 PRD 吗?
提示链的每一步,本质上都是在给 AI 一份更小、更清晰的"PRD"。
以我自己的 my-resume 项目重构为例,一个完整的 AI 辅助重构规划可以拆成四步:
梳理现状 → 确定架构 → 技术选型 → 里程碑规划
每一步专注一件事,输出结果作为下一步的上下文,最终得到一份完整的重构方案。
import { ChatOpenAI } from "@langchain/openai";
import { PromptTemplate } from "@langchain/core/prompts";
import { StringOutputParser } from "@langchain/core/output_parsers";
import { RunnableSequence } from "@langchain/core/runnables";
const llm = new ChatOpenAI({ modelName: "gpt-4o-mini", temperature: 0.7 });
const parser = new StringOutputParser();
// 带重试机制的单步执行器
async function runStep(
chain: RunnableSequence,
input: Record<string, string>,
stepName: string,
maxRetries = 3
): Promise<string> {
for (let attempt = 1; attempt <= maxRetries; attempt++) {
try {
const result = await chain.invoke(input);
if (result && result.length > 20) return result;
} catch (e) {
console.error(`[${stepName}] 第${attempt}次失败:`, e);
}
}
throw new Error(`[${stepName}] 重试${maxRetries}次后仍失败`);
}
书里提到了错误处理的重要性,但没有给出具体的分层结构。我结合自己写Nestjs后端服务的经验,把它补充完整了:
Level 1:原地重试(Retry) ← 大多数临时错误在这里解决
↓ 失败 N 次
Level 2:修正上一步输出后重试 ← 上下文质量问题
↓ 仍失败
Level 3:降级处理(Fallback) ← 返回兜底结果
↓ 仍失败
Level 4:人工介入 ← 高风险场景的最后防线
这个分层思路,和写后端服务的容错逻辑是一样的——先自救,再降级,最后才是报警。书里的思路给了方向,工程经验补上了细节。
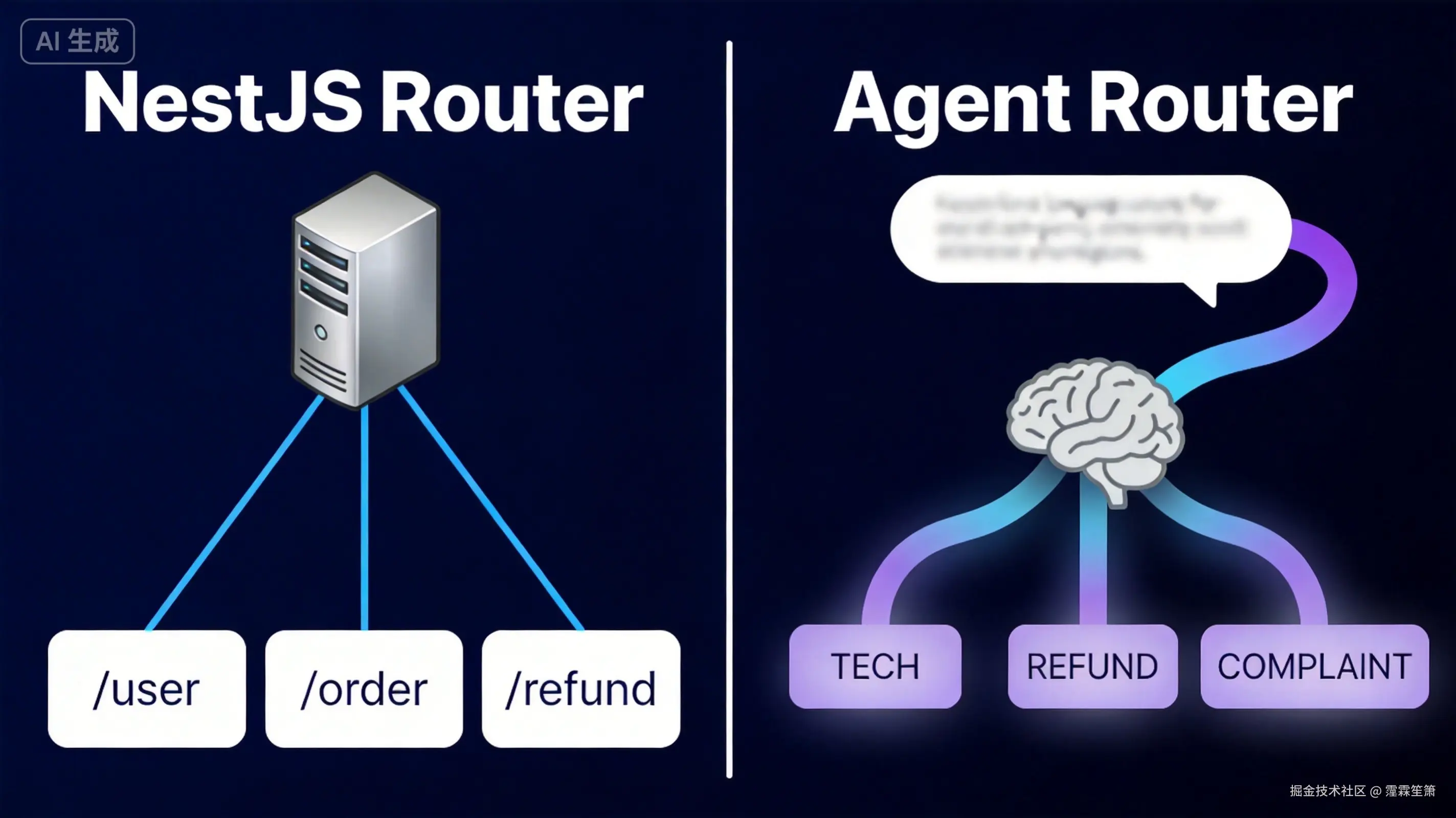
读到路由这章,第一反应非常直接:这不就是后端路由吗?
用户输入 → 判断意图 → 分发到对应的处理链。和 NestJS 里 @Get('/user') @Post('/order') 的逻辑一模一样嘛。
但我多想了一秒,感觉哪里不太对。
HTTP 路由的判断依据是 URL 路径,是你自己定义的规则,边界清晰、精确。但 Agent 路由的判断依据是用户说的话——你永远不知道用户会怎么表达同一件事。
"我要退款"、"我想申请退款"、"这个东西我不想要了能退吗"、"退款流程是什么"——这四句话意图相同,但表达完全不同。规则路由根本兜不住。
这就是两者本质的区别:
| 维度 | NestJS 路由 | Agent 路由 |
|---|---|---|
| 判断依据 | URL 路径(规则固定) | 输入语义(动态理解) |
| 边界 | 清晰、精确 | 模糊、需置信度判断 |
想清楚这一点,书里后面讲的"规则路由 vs LLM 路由"就很好理解了。
书里给了四种路由实现方式(基于LLM、基于嵌入、基于规则、基于ML模型),实际开发中用得最多的是前两种,用一句话概括它们的区别:
规则路由:你告诉它边界在哪里。LLM 路由:它自己理解边界在哪里。
适合意图明确、流程固定的场景,比如退款、账号注销。
优点:快速、可控、零幻觉 缺点:无法处理模糊边界
适合意图模糊、内容开放的场景,比如技术咨询、品牌对话。
优点:理解语义、处理模糊 缺点:有延迟、有成本
| 场景特征 | 推荐方式 |
|---|---|
| 意图明确 + 流程固定 | 规则路由 |
| 意图明确 + 内容开放 | 规则路由定向 + LLM 生成 |
| 意图模糊 + 内容开放 | LLM 路由 + LLM 生成 |
| 高风险操作 | 规则路由 + 二次确认 |
// LLM 路由判断器
// 注意:temperature=0,确保分类结果稳定,不能让它"发挥创意"
const classifyChain = RunnableSequence.from([
PromptTemplate.fromTemplate(`
将用户输入分类为:TECH / REFUND / COMPLAINT / OTHER
只输出标签,不解释。
用户输入:{input}
`),
new ChatOpenAI({ temperature: 0 }),
new StringOutputParser(),
]);
async function smartRouter(userInput: string): Promise<string> {
// 规则路由优先:确定性流程,零延迟,零幻觉
if (userInput.includes("退款")) {
return refundChain.invoke({ input: userInput });
}
// LLM 路由:语义理解,处理模糊意图
const intent = await classifyChain.invoke({ input: userInput });
switch (intent.trim()) {
case "TECH": return techChain.invoke({ input: userInput });
case "COMPLAINT": return complaintChain.invoke({ input: userInput });
default: return fallbackChain.invoke({ input: userInput });
}
}
书里的定义很直接:识别工作流中不依赖其他部分输出的环节,将它们并行执行。
串行(慢):A → B → C → D 耗时:T(A)+T(B)+T(C)+T(D)
并行(快):A ─┐
B ─┼──→ 汇总 → D 耗时:max(T(A),T(B),T(C)) + T(D)
C ─┘
用函数式编程来理解,就是先 fan-out(扇出)再 fan-in(汇聚):
// 提示链 = pipe(串行)
pipe(stepA, stepB, stepC)(input)
// 并行化 = 先 fan-out 再 fan-in
pipe(
fanOut(taskA, taskB, taskC), // 同时执行,各自独立
merge, // 汇聚结果
stepD // 依赖汇聚结果的后续步骤
)(input)
典型场景:简历多维度评估(同时分析技术栈、项目经验、表达能力)
用户简历
↓
┌─────────────────────────────┐
│ ① 提取技术栈 │ ← 并行执行
│ ② 评估项目经验 │ ← 并行执行
│ ③ 分析表达能力 │ ← 并行执行
└─────────────────────────────┘
↓ 汇总
综合评估报告
单个模型有自己的"思维定势",多个模型投票相当于让多个专家各自给意见,再综合判断——比只听一个人靠谱得多。
典型场景:长文档摘要、大规模数据分析。熟悉 Hadoop 或函数式编程的同学,这个模式一眼就懂。
Promise.all 到 Promise.allSettled 的思维转变这里有个细节是我自己推导出来的,书里没有直接讲。
一开始我的直觉是用 Promise.all——等所有并行任务完成再汇总。但写着写着意识到一个问题:AI 调用天然不稳定,某一个维度分析偶尔超时或报错是正常的。Promise.all 的行为是一个失败就全军覆没——一个维度挂了,整份报告作废。
这明显不对。一个维度分析失败,不代表整份报告没价值。
于是想到了 Promise.allSettled——等所有任务都结束(不管成功还是失败),对失败的单独降级处理,其余照常返回。
| Promise API | 行为 | 适用场景 |
|---|---|---|
Promise.all | 一个失败全部终止 | 所有结果都必须有 |
Promise.allSettled | 等全部结束,记录每个状态 | Agent 并行化推荐 |
Promise.race | 取最快完成的 | 多备用源取最快响应 |
Promise.any | 取最快成功的 | 多备用源容忍失败 |
import { RunnableParallel } from "@langchain/core/runnables";
// RunnableParallel:LangChain 原生并行执行,底层等价于 Promise.allSettled
const parallelAnalysis = RunnableParallel.from({
techStack: techStackChain,
experience: experienceChain,
expression: expressionChain,
});
async function evaluateResume(resume: string) {
// 三链并行执行
const results = await parallelAnalysis.invoke({ resume });
// 汇总生成综合报告
return summaryChain.invoke(results);
}
书里有一句话说得很准:核心思想是识别工作流中不依赖其他部分输出的环节。
所以并行化的本质不是"让所有任务都并行",而是识别依赖关系:
动手之前,先画一张任务依赖图——哪些任务之间有箭头,哪些没有,一目了然。
学完这三章,你手里已经有了三把利器:
| 模式 | 解决什么问题 | 核心结构 |
|---|---|---|
| 提示链 | 复杂任务怎么拆解? | A → B → C(线性) |
| 路由 | 不同输入怎么分发? | 输入 → 判断 → 分叉 |
| 并行化 | 无依赖任务怎么提速? | 扇出 → 并行 → 汇聚 |
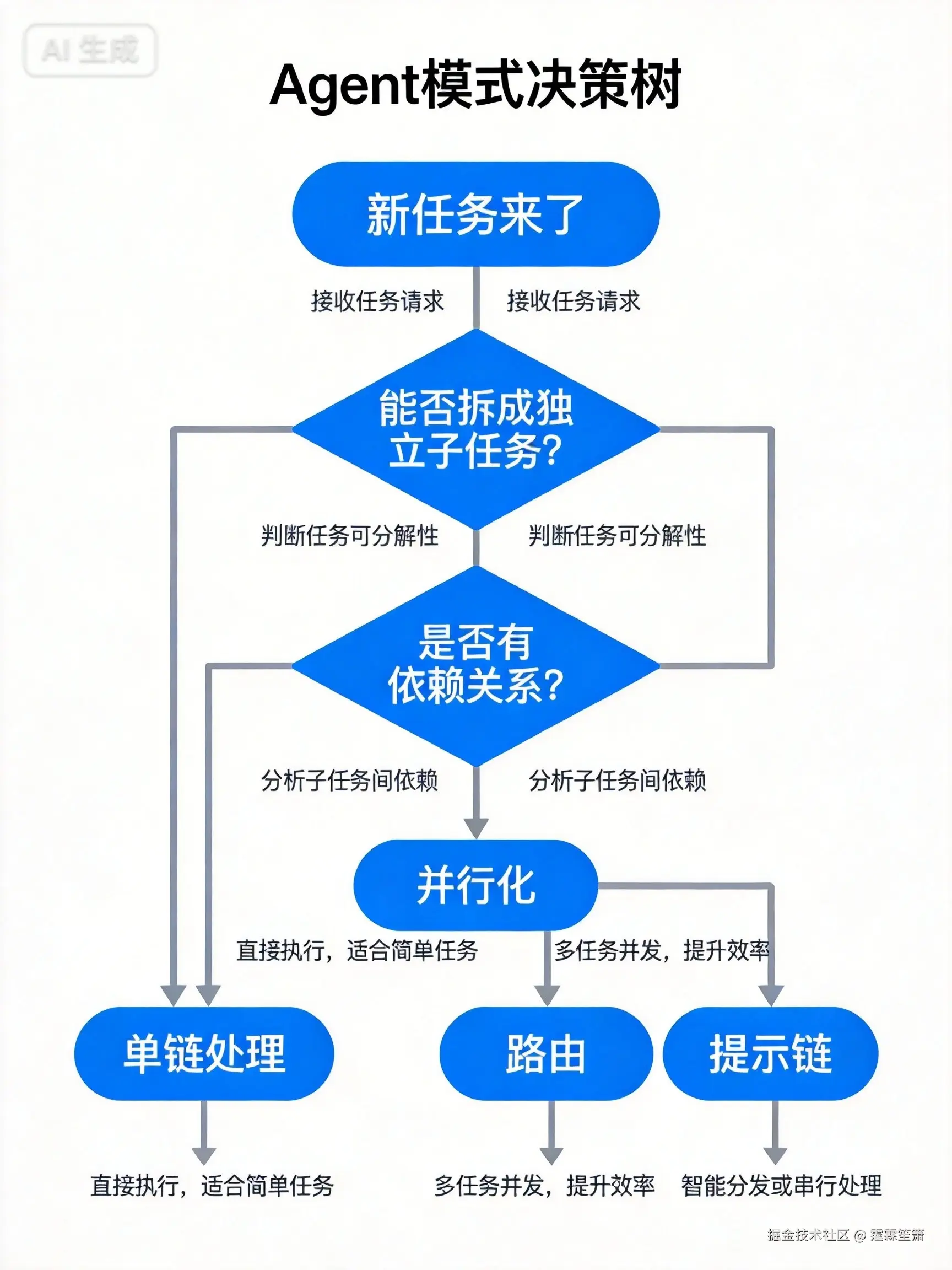
三者组合的决策流程:
新任务来了
↓
能拆成独立子任务吗?
├─ 能 → 子任务间有依赖吗?
│ ├─ 有依赖 → 提示链(串行)
│ └─ 无依赖 → 并行化
└─ 不能(单一任务)
↓
输入类型固定吗?
├─ 是 → 路由(分发到专属链)
└─ 否 → 单链处理
我正在用 NestJS + Drizzle ORM + SQLite 重构 my-resume 项目,三个模式都有直接对应:
| 项目场景 | 对应模式 | 说明 |
|---|---|---|
| 重构规划(梳理→架构→选型→里程碑) | 提示链 | 四步顺序执行,前步输出是后步输入 |
| 用户意图识别(简历生成/面试辅导/职位分析) | 路由 | 根据用户需求分发到不同功能链 |
| 多维度简历评估(技术栈/项目经验/表达能力) | 并行化 | 无依赖维度同时分析,汇总生成报告 |
边学边做,是我觉得最快的方式。理论看懂了,不等于会用——只有落到真实项目里,才知道哪里还没想清楚。
这三个模式是 Agent 开发的地基,掌握它们之后:
说到底,这三个模式解决的都是同一个问题:如何让 AI 在复杂场景下,稳定地做对事情。
这件事和写软件没什么本质区别——拆任务、管流程、做容错,工程师早就在做了。只不过现在执行者从代码变成了模型。

