
GDM
36.48M · 2026-03-29

上一篇我们搞定了开发环境、对很多概念都已经有了一个基础的了解。
但你可能已经发现了一个问题:AI 只能看到你在输入框里告诉他的信息,该怎么让它自己去检索项目代码?怎么让它按固定格式交付修 Bug 的证据?怎么给它接上它可以调用的工具呢?这些就是这一篇想要解决的问题。
本篇包含 3 个任务:
目标:把一个 MCP 工具接进来,先简单感受一下mcp。
如果你对 MCP(Model Context Protocol)还不熟悉,可以把它理解成一个 "标准的工具插槽"。以前你得往提示词里写很多上下文;现在只要用统一的协议把外部工具接进来,你的客户端(CLI、IDE、Agent )就能用同一套约定去发现工具、调用能力。
这一部分我推荐大家选只读的工具。比如:
这两个工具都比较老牌并且用的比较多,大家可以根据自己的情况选择。
我目前最喜欢的使用方法就是用antigravity(我开的ultra)右边是agent窗口,然后开一个终端在下面,然后也分享一个小技巧,如果想一个项目开多个窗口的话可以存一个工作区,这样就可以左右开弓了。
mcp底层原理都一样:读mcp配置后,帮你在后台起一个进程,本质就是执行 command + args。
下面直接给出上面提到的两个工具的mcpserver配置:
这步其实可以直接告诉你使用的coding agent我要配置什么mcp就可以了,然后有的mcp需要你自己去到对应的网站上注册然后拿一个key,拿到之后再给你的coding agent来配置就可以了
Filesystem(只读文件系统):
{
"mcpServers": {
"filesystem": {
"command": "npx",
"args": ["-y", "@modelcontextprotocol/server-filesystem", "/ABSOLUTE/PATH/TO/YOUR/PROJECT"]
}
}
}
注意把路径换成你项目的绝对路径。这个工具只给 AI 读取指定目录的能力,不会写文件。
context7(文档检索):
{
"mcpServers": {
"context7": {
"command": "npx",
"args": ["-y", "@upstash/context7-mcp@latest"]
}
}
}
context7 可以帮 AI 直接查阅各种开源库的最新文档,不用你手动复制粘贴。
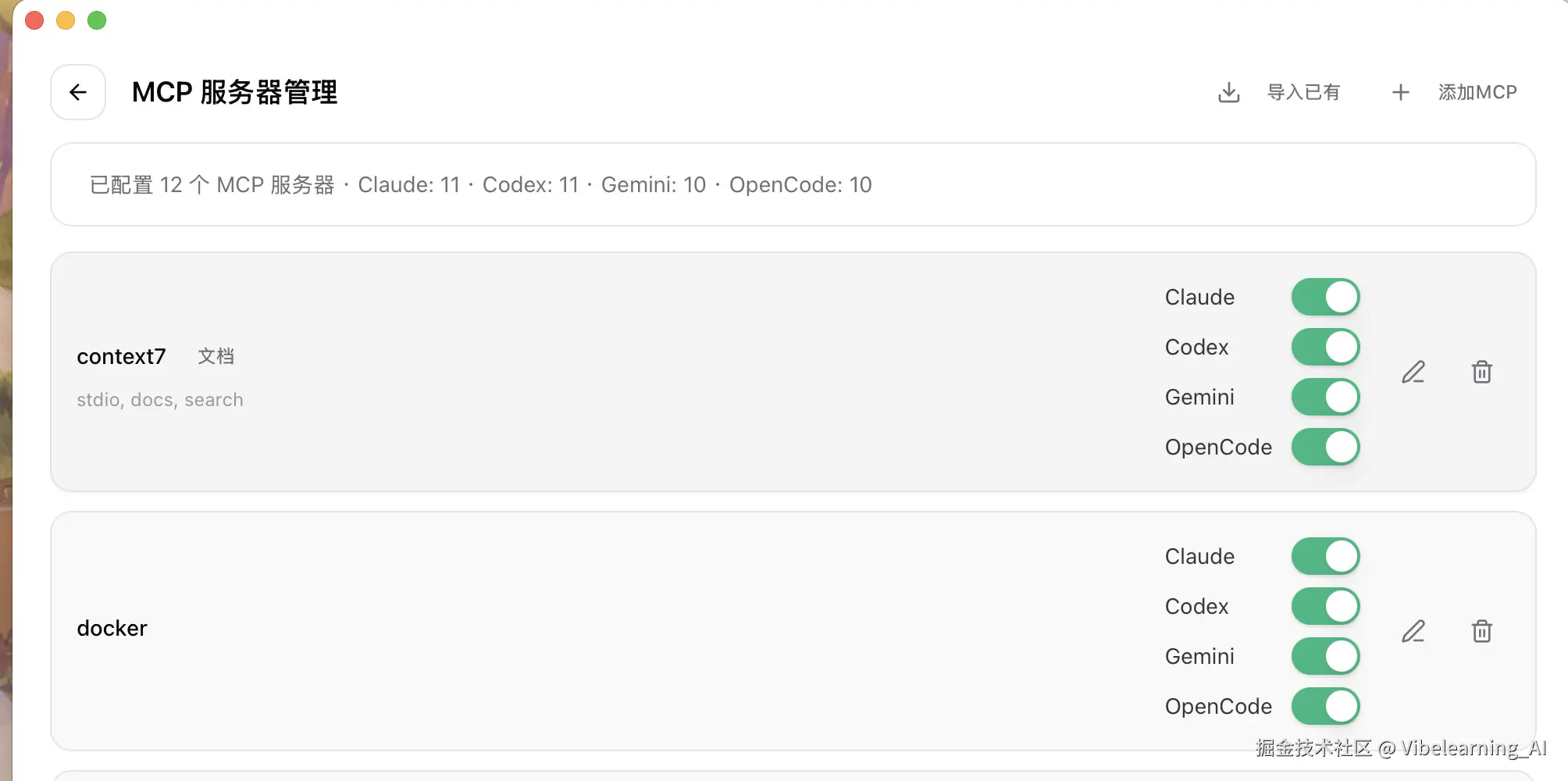
验证标准: 可以直接让你的coding agent检查mcp启用状态,或者用命令来看,mcp list或者/mcp之类的指令,可以根据你自己用的coding agent的文档来查一下怎么看mcp的启动状态,ccswitch也是一个不错的mcp管理工具。
延伸阅读:
如果你对 MCP 的概念还比较模糊,建议先看一遍官方介绍,搞清楚 Tools、Resources、Prompts 这三者的区别,然后跟着 Server Quickstart 走一遍,感受一下客户端和工具之间怎么配合的。
这部分我们的目标是从零写一个最小可用的 MCP server(哪怕它只能返回一句话),然后把它注册到你的开发环境里。
这一步的意义不在于写出一个 Hello World 工具,而是自己动手实践搭了一个可复制的模板。以后想让 AI 检索公司的 Jira、内部日志或者发版系统,该怎么起步、怎么验证、怎么排错心里就有数了。
这部分演示一条按官方思路、跨平台兼容且确保能跑通的轻量路径。
官方建议 Python 3.10 以上,搭配最新的 MCP SDK。客户端拉起你的 Server 时,需要找到你配好的那个 Python 解释器。
为什么?因为 MCP 用 STDIO 模式通信时,stdout 是专门给协议消息走的通道。你往里面混了别的东西(比如一句 print("hello")),客户端收到的 JSON 就乱了,可能会导致直接断连。
用代码来说就是这样:
错误写法(会导致连接断开):
print("Server 启动中...") # 这行会写到 stdout,把协议搞坏
正确写法(日志走 stderr,不影响协议):
import sys
print("Server 启动中...", file=sys.stderr) # 日志走 stderr,协议不受影响
Node.js 也一样:用 console.error(...) 代替 console.log(...)。
简单记住一条规则就行:
stdout → 只给 MCP 协议用,你的代码里不要往这里写任何东西stderr → 你的调试日志全走这边所以碰到连接断开就可以排查一下是不是写错了
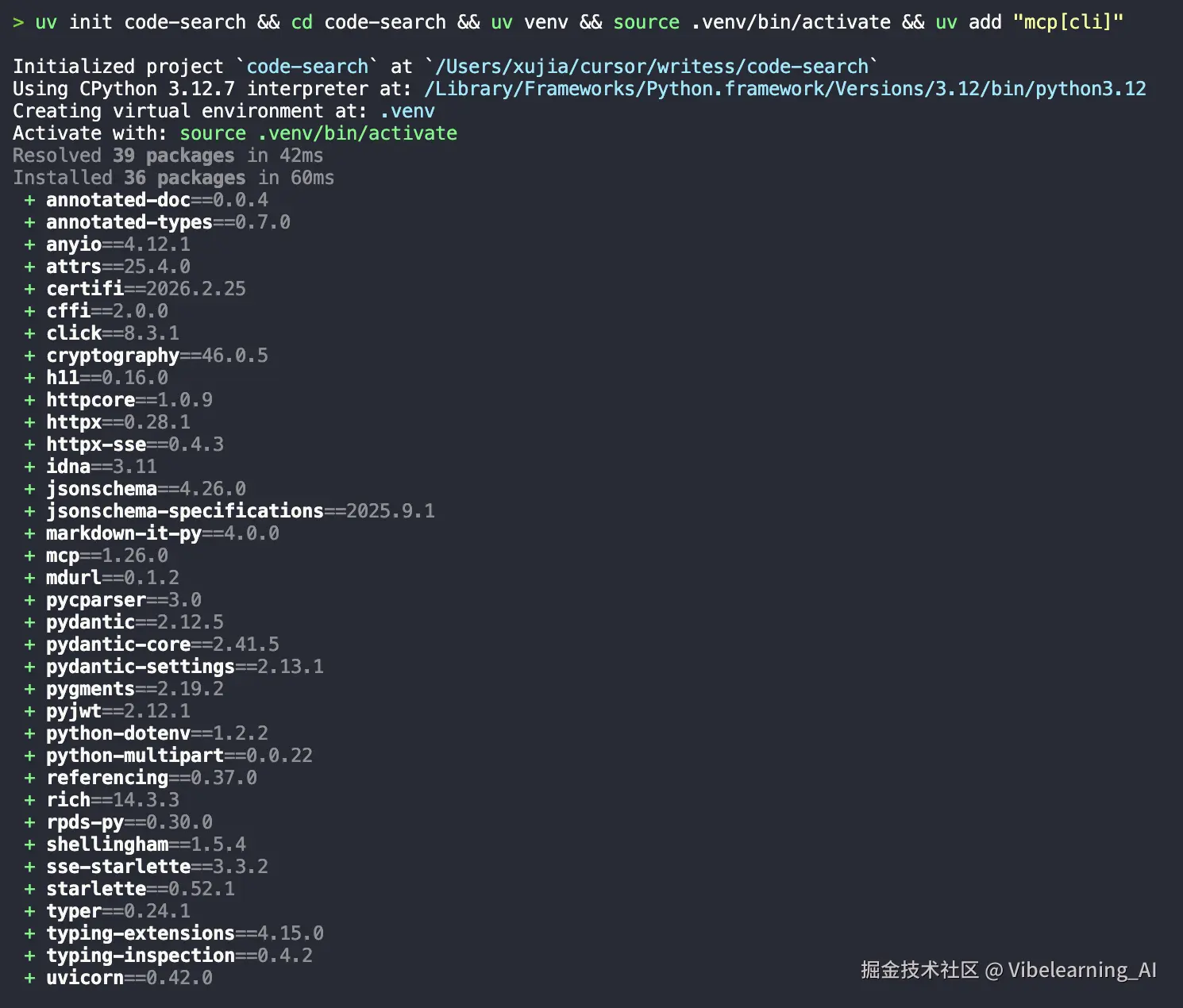
找一个你放 Demo 的文件夹:
uv init code-search
cd code-search
uv venv
激活虚拟环境(挑你用的终端):
# macOS/Linux
source .venv/bin/activate
# Windows PowerShell
.venvScriptsActivate.ps1
# Windows cmd
.venvScriptsactivate.bat
装上 SDK 依赖:
uv add "mcp[cli]"
创建脚本文件:
# macOS/Linux/WSL
touch code_search_server.py
# Windows PowerShell
ni code_search_server.py
# 你也可以用 Python 方式创建
python -c "open('code_search_server.py','w').close()"
验证:
uv --version 能正常返回。python -V 是你预期的版本。python -c "import mcp" 不报错。与其写一个只会返回 Hello 的玩具,不如直接上手写一个好用的纯读取检索工具:用 rg 做文本搜索,或者用 ast-grep 做语法树级别的代码检索。
前置准备:
rg (ripgrep)ast-grep把下面这段代码存到 code_search_server.py 里:
import os
import shutil
import subprocess
import sys
from pathlib import Path
from typing import Any, Optional
from mcp.server.fastmcp import FastMCP
mcp = FastMCP("code-search")
# 确保 Homebrew / Linuxbrew 等常见路径在 PATH 里
# (uv run 的子进程可能丢失这些路径,导致 rg 找不到)
_EXTRA_PATHS = ["/opt/homebrew/bin", "/usr/local/bin", "/home/linuxbrew/.linuxbrew/bin"]
_ENV = os.environ.copy()
_ENV["PATH"] = os.pathsep.join(_EXTRA_PATHS + [_ENV.get("PATH", "")])
def _find_bin(name: str) -> str:
"""查找可执行文件的绝对路径,找不到就原样返回让后面报 FileNotFoundError。"""
return shutil.which(name, path=_ENV["PATH"]) or name
def _run(cmd: list[str], cwd: str, timeout_s: int = 30) -> tuple[int, str, str]:
"""安全地执行子进程,带超时保护。"""
p = subprocess.run(
cmd,
capture_output=True,
text=True,
timeout=timeout_s,
shell=False,
cwd=cwd,
env=_ENV,
stdin=subprocess.DEVNULL, # 防止子进程继承 MCP 的 stdin 管道
)
return p.returncode, p.stdout, p.stderr
@mcp.tool()
def rg_search(target_dir: str, query: str, globs: Optional[list[str]] = None, max_lines: int = 200) -> dict[str, Any]:
"""用 ripgrep 搜索文本,返回结构化结果。"""
if not target_dir.strip():
return {"ok": False, "error": "target_dir required"}
if not Path(target_dir).is_dir():
return {"ok": False, "error": "target_dir not a directory"}
if not query.strip():
return {"ok": False, "error": "empty query"}
# 注意:--glob 必须放在 "--" 之前,"--" 之后的参数会被当作搜索词和路径
cmd = [_find_bin("rg"), "--line-number", "--no-heading", "--color", "never"]
for g in (globs or []):
cmd += ["--glob", g]
cmd += ["--", query, "."]
try:
code, out, err = _run(cmd, cwd=target_dir)
except FileNotFoundError:
return {"ok": False, "error": "rg not installed"}
except subprocess.TimeoutExpired:
return {"ok": False, "error": "rg timeout"}
# rg 退出码:0=有匹配, 1=无匹配, 2=出错
if code == 2:
print(err.strip(), file=sys.stderr)
return {"ok": False, "error": "rg error", "details": err.strip()}
lines = [ln for ln in out.splitlines() if ln.strip()]
if len(lines) > max_lines:
lines = lines[:max_lines] + ["... truncated ..."]
return {"ok": True, "matches": lines, "rc": code}
@mcp.tool()
def ast_search(target_dir: str, pattern: str, lang: str, globs: Optional[list[str]] = None, max_lines: int = 200) -> dict[str, Any]:
"""AST 级别的代码搜索,需要本地安装 ast-grep。"""
if not target_dir.strip():
return {"ok": False, "error": "target_dir required"}
if not Path(target_dir).is_dir():
return {"ok": False, "error": "target_dir not a directory"}
if not pattern.strip() or not lang.strip():
return {"ok": False, "error": "pattern/lang required"}
if not lang.isalnum():
return {"ok": False, "error": "invalid lang"}
cmd = [_find_bin("ast-grep"), "run", "--pattern", pattern, "--lang", lang]
for g in (globs or []):
cmd += ["--globs", g]
cmd += ["."]
try:
code, out, err = _run(cmd, cwd=target_dir)
except FileNotFoundError:
return {"ok": False, "error": "ast-grep not installed"}
except subprocess.TimeoutExpired:
return {"ok": False, "error": "ast-grep timeout"}
if code != 0:
print(err.strip(), file=sys.stderr)
return {"ok": False, "error": "ast-grep error", "details": err.strip()}
lines = [ln for ln in out.splitlines() if ln.strip()]
if len(lines) > max_lines:
lines = lines[:max_lines] + ["... truncated ..."]
return {"ok": True, "matches": lines}
if __name__ == "__main__":
mcp.run(transport="stdio")
划重点:
stderr,不污染 stdout。FileNotFoundError,如果系统没装 rg 或 ast-grep,会返错误而不是崩溃。uv run code_search_server.py
跑起来之后终端会挂住而没有任何输出,这说明它正在等客户端发指令过来,而不是寄了。
Server 跑通之后,可以告诉你的 coding agent:"我本地有一个 MCP server,你去给我连接上。"
第一步:找到你工具的 MCP 配置文件
不同工具的配置文件位置不一样,这里我举一下反重力和codex的例子,如果是直接配置到cc/codex这种,就直接在配置文件里面改,codex在toml,cc在json,也可以直接在ccswitch里面管理或者改配置:
| 工具 | 配置文件位置 |
|---|---|
| Antigravity | ~/.gemini/antigravity/mcp_config.json |
| Codex | ~/.codex/config.toml |
第二步:把配置写进去
打开对应的配置文件,把下面的配置加进去(注意把路径换成你自己的):
Antigravity / Cursor / Claude Desktop(JSON 格式):
{
"mcpServers": {
"code-search": {
"command": "uv",
"args": [
"--directory",
"/你的绝对路径/code-search",
"run",
"code_search_server.py"
]
}
}
}
Codex(TOML 格式,加到 ~/.codex/config.toml 末尾):
[mcp_servers.code-search]
type = "stdio"
command = "uv"
args = ["--directory", "/你的绝对路径/code-search", "run", "code_search_server.py"]
第三步:重启你的 coding agent,验证连接
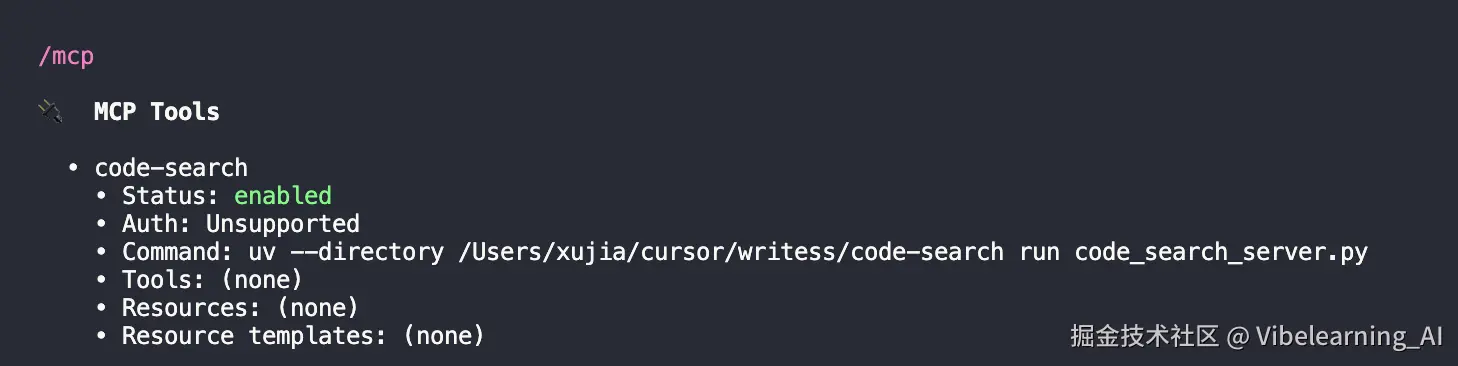
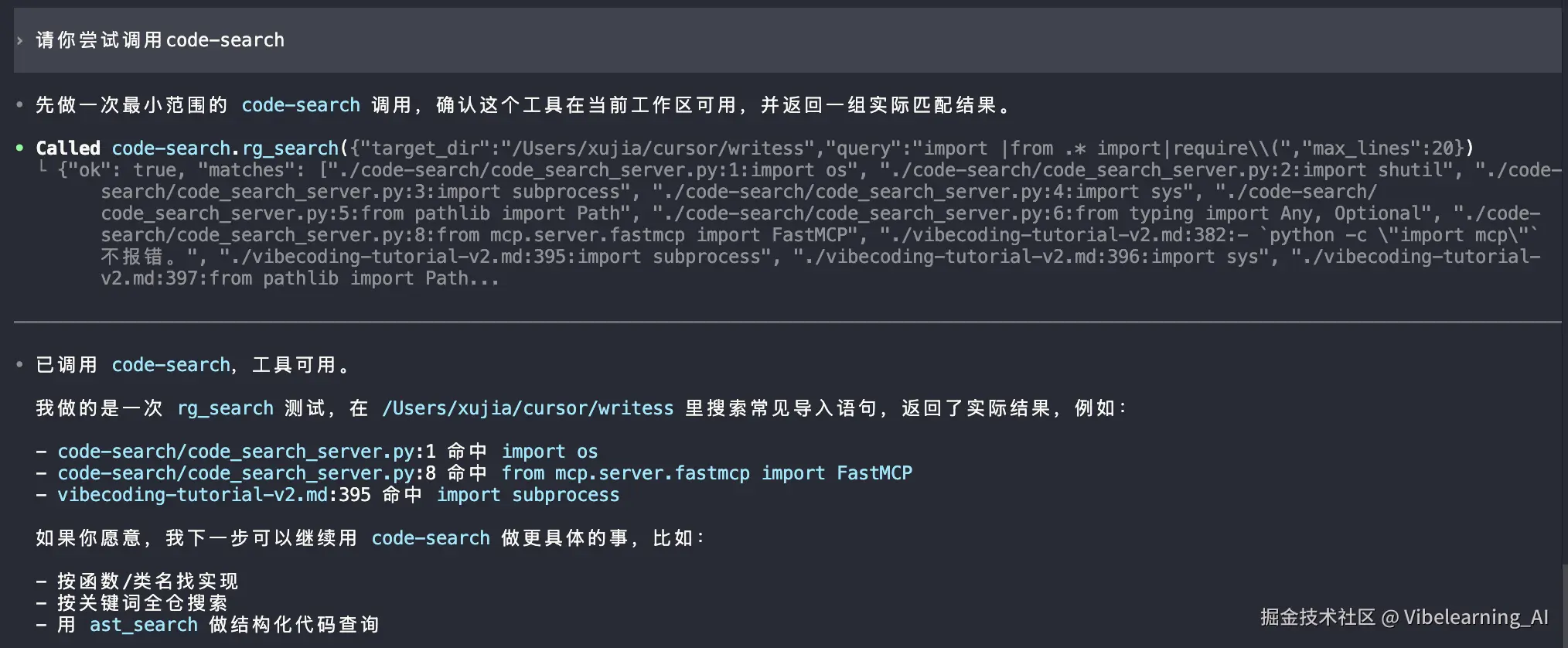
重启之后,用你工具里的 MCP 检查命令看一下 code-search 是不是已经连上了。然后试着让 AI 调用一下,比如跟它说:"用 rg_search 在我的项目目录里搜一下 TODO",看看它能不能正常返回结果。
示例:codex /mcp检查链接
示例:codex 调用测试
延伸阅读:
如果打算把 MCP 长期用下去,建议抽空看一遍 Python 和 TypeScript 两个 SDK 的 README,搞清楚 SDK 的生命周期、安全策略和进阶配置。
不管模型多强,它的发挥总是有波动:有可能不是降智,只是佬的提示词没有上一次写的用心或者这次有点不耐烦了,所以把流程写死,让它必须按格式交作业。 通过写流程来提高模型输出的稳定性。
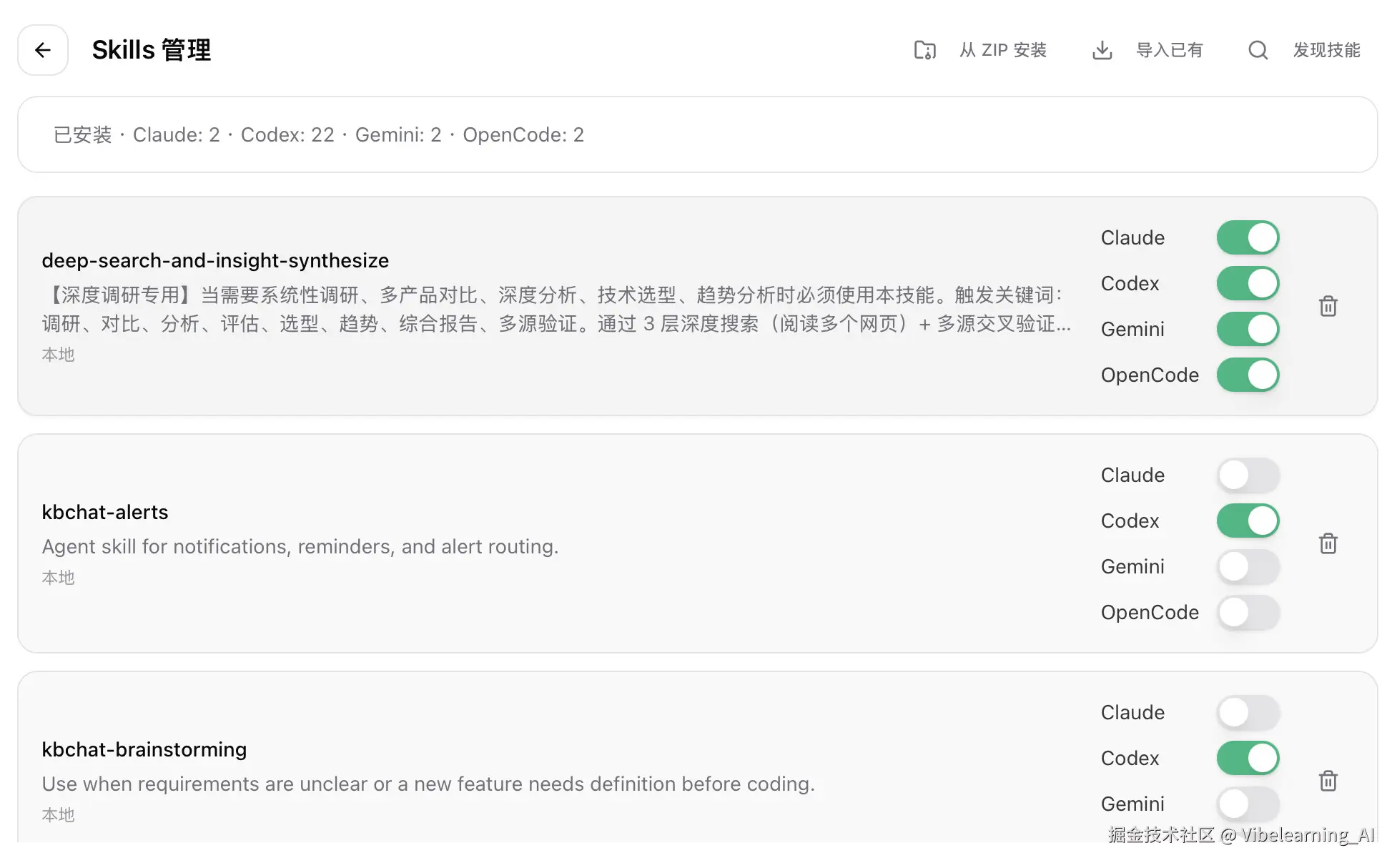
不把流程固化(Skills),你很快就会陷入这种循环:
Skills 的价值就是把这些正确做法固定下来,一次梳理,长期复用。
一张合格的卡片,至少覆盖这几个方面:
写出来的卡片不能只是一段复制粘贴的文本,它需要一个稳定的位置:
skills/bugfix.md),然后在 AGENTS.md 中引用它:请在每次排障时,严格遵循 skills/bugfix.md 中定义的流程卡片。AGENTS.md 的对应章节里,方便 AI 工具自动读取。(真的是次选,直接写在这会加很多input token不同工具的引用机制不同,但是ccswitch依旧有一套管理系统(歌颂ccs
跟它沟通时,直接规定好他需要交付的内容:
请你严格按照以下清单进行交付,并且每一项都必须附上证明:
1) 提取出最小规模的复现逻辑(提供可执行的命令或步骤)。
2) 确诊根因所在(必须引用具体的代码行号或日志证据)。
3) 提出修复方案,并解释你为什么要这样改。
4) 给出修复后的对比 diff。
5) 执行自动化测试并直接贴上输出日志。
6) 补充一段回归测试代码(如果客观上没法写,请写明技术原因)。
什么时候可以确定这是一张可以复用且质量不错的卡?
在这里推荐一个skills集合网站:skillsmp.com/zh
延伸阅读:
如果你想了解"卡片"这套理念是怎么被做成通用标准的,可以看看 Anthropic 团队的思路和 Agent Skills Standard。
Skill: Bugfix(标准排障流程卡)
Inputs required(初始信息):
- 复现步骤或触发崩溃的命令
- 报错日志/Trace
- 你怀疑的影响范围(可选)
Outputs required(必须交付):
1) 最小复现
2) 根因定位(引用代码行号和日志)
3) 修复 diff
4) 验证通过的输出
5) 回归测试(写不了说明技术原因)
Failure strategy(卡住了怎么办):
- 没法复现:列一份"需要补充的信息清单"。
- 偶现失败(Flaky test):逐一排查变量(依赖版本/时区/网络/并发/随机种子)。

