
简打卡
51.76M · 2026-03-28

随着以Claude Code为代表的代码大语言模型(Code Large Language Model,以下简称Code LLM)在软件工程领域的普及,其在企业级数据仓库(以下简称数仓)建设中的应用逐渐从单一的代码补全向全链路辅助演进。本文旨在探讨Code LLM在电商数仓环境下的深度集成逻辑与工程实践。文章首先界定了数据确权中的人机边界,分析了内部数据工具向Agentic工作流演进的趋势,并提出了“认知运行时与执行运行时解耦”的架构范式。
本文认为,大模型在企业级数据仓库中的落地核心,主要体现在两大维度:一是数据确权(Data Rights Confirmation) ,二是规范化输入输出(Standardized I/O) 。以此为框架,结合得物App真实数仓建设与研发实践,系统阐述了基于Galaxy MCP的基础设施集成方案,并对智能视觉埋点、AI OneData建模、智能周报生成、策略孵化中心等典型场景的架构设计与运行逻辑进行深入分析。最后,针对大模型应用中存在的幻觉问题与合规风险,本文提出一套系统性的治理与管控机制。
Code LLM引入数仓的建设流程,并非简单的工具替换,而是对现有研发范式、职责边界及工具链架构的系统性升级。在讨论具体的提效场景前,必须首先厘清底层的逻辑支柱;若未能厘清权责边界与架构定位,大模型的引入极易演变为不可控的技术债务与运维风险。
数仓建设的工程起点是原始数据(ODS 层)的接入,该环节涉及数据来源的合法性、数据所有权的界定、个人可识别信息(Personally Identifiable Information,PII)的合规审查,以及数据质量的责任归属。这些属性决定了数据接入不仅是技术动作,更是企业内部的核心数据确权过程。在引入 AI 辅助能力时,必须严格区分**「管理审批」与「技术实现」**的权责边界:
管理审批(人类主导): 数据的权限审批、合规性定责、业务口径的最终确认,属于具备法律与管理效力的行为。当前法律框架下,AI 不具备独立的民事主体资格,无法独立承担法律与管理责任,因此在确权决策环节,必须由明确的数据治理委员会或业务负责人完成人工审批与权责确认。
技术实现(AI 辅助): 在完成人工确权与审批后,涉及的 DDL 脚本编写、同步任务模板配置、基础数据质量校验(Data Quality Check,DQC)规则生成等技术执行工作,可由 Code LLM 基于已确权的元数据自动化生成,并经人工复核确认后上线执行。
明确这一边界,既保障了企业数据资产的安全与合规,也为后续工程环节的 AI 深度介入提供了合规前提。
传统的数仓研发平台(如得物 App 内部数据研发平台 Galaxy)、BI 系统及指标字典,在形态上多属于被动式内部 SaaS 工具:即工具仅提供标准化的功能模块与图形化界面(GUI),无法主动理解并完成用户的业务意图,需依赖工程师的专业技能手动操作,属于典型的「人找功能」的被动响应模式,工具的价值上限取决于功能丰富度与用户的专业熟练度。
Code LLM 的引入,促使内部数据工具向 Agentic(智能体化)工作流演进。在这一模式下,核心交互方式由 GUI 转向意图驱动的自然语言交互界面(Language User Interface,LUI);系统不再仅仅提供「编写 SQL 的环境」,而是能够接收业务意图(如「按特定维度统计退款归因」),在预设的权限与规则边界内,通过调用底层 API 自主完成元数据检索、逻辑组装,并输出最终的数据洞察或代码草案。这种演进重构了数据工具的核心价值逻辑:从「为专业人员提供功能组件」,转向「为业务用户交付可落地的任务结果」。
在探讨 AI 与现有数仓架构的融合时,需先明确大模型在系统中的核心定位:大模型无法替代 Spark、Flink、ClickHouse 等传统大数据计算与存储引擎的核心算力能力,其核心价值是促成了计算架构中「认知决策」与「执行落地」的解耦分离,我们将其拆解为两个核心模块:认知运行时(Cognitive Runtime) 与执行运行时(Execution Runtime) 。
认知运行时: 由 LLM 充当核心载体,负责处理非结构化需求解析、业务逻辑到 SQL 的语义映射、代码规范校验及调优策略生成,核心处理语义与逻辑的推演工作。该模块不直接触碰物理数据,仅在数据权限管控体系的约束下,操作已确权授权的元数据(Metadata)与抽象语法树(Abstract Syntax Tree,AST)。
执行运行时: 由传统大数据计算引擎充当核心载体,负责海量数据的物理扫描、分布式计算与存储落地,核心处理确定性的算力调度与执行任务。
这种解耦架构,使得数仓系统既能保有传统引擎的高吞吐、高可靠特性,又能具备大模型的语义理解与逻辑泛化能力,同时与前文的权责边界、合规要求形成了架构层面的呼应。
当我们试图用 AI 优化数仓系统时,若仅仅停留在「单点提效」的表层,最终往往会陷入「为了用 AI 而用 AI」的陷阱。大语言模型基于概率分布生成文本,存在固有的幻觉风险;在对数据准确性、口径一致性要求极高的数仓场景中,无约束的自然语言对话式开发(业内俗称 Vibe Coding,即无明确规范、凭感觉自由编码的模式),会导致代码风格发散、业务口径不一致、数据失真等严重问题,甚至引发合规风险。
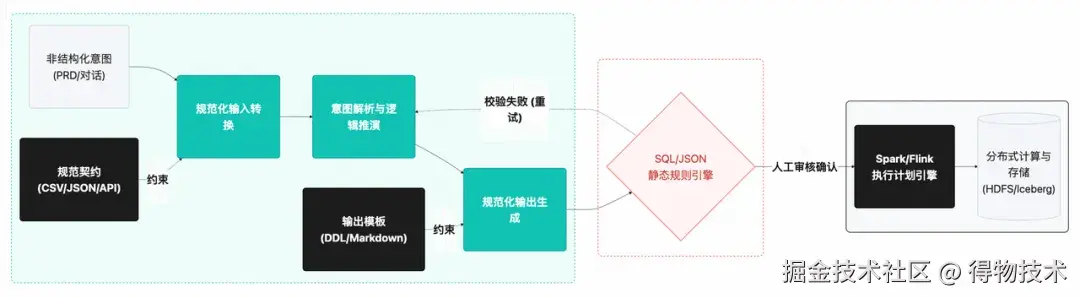
剥离掉「AI 写代码」的表层形式,触碰数仓与 AI 融合的本质,其核心在于构建规范化的输入与输出(Standardized I/O)契约。无论是埋点设计、OneData 建模,还是周报生成与策略孵化,其底层逻辑高度一致:将模糊的业务需求,通过结构化模板、CSV、JSON 或 API 接口(规范化输入)喂给模型,并强制模型按照预设的 Markdown 模板、DDL 规范或报告框架(规范化输出)进行交付。这种基于规范的驱动开发模式(Spec-Driven Development,SDD),将大模型不可控的自由文本生成,转化为基于规范契约的受限定向编译,从根源上压缩了幻觉的产生空间,构成了 AI 在数仓中规模化应用的安全底座。
综上,明确的数据确权边界,与标准化的输入输出契约,共同构成了 Code LLM 在企业级数仓中安全、合规、规模化落地的两大核心支柱。
要实现上述的“规范化输入与输出”,大模型必须具备感知和操作企业真实数据环境的能力。在实践中,研发团队基于模型上下文协议(Model Context Protocol, MCP),为内部数据研发平台(Galaxy)构建了标准化的集成底座。
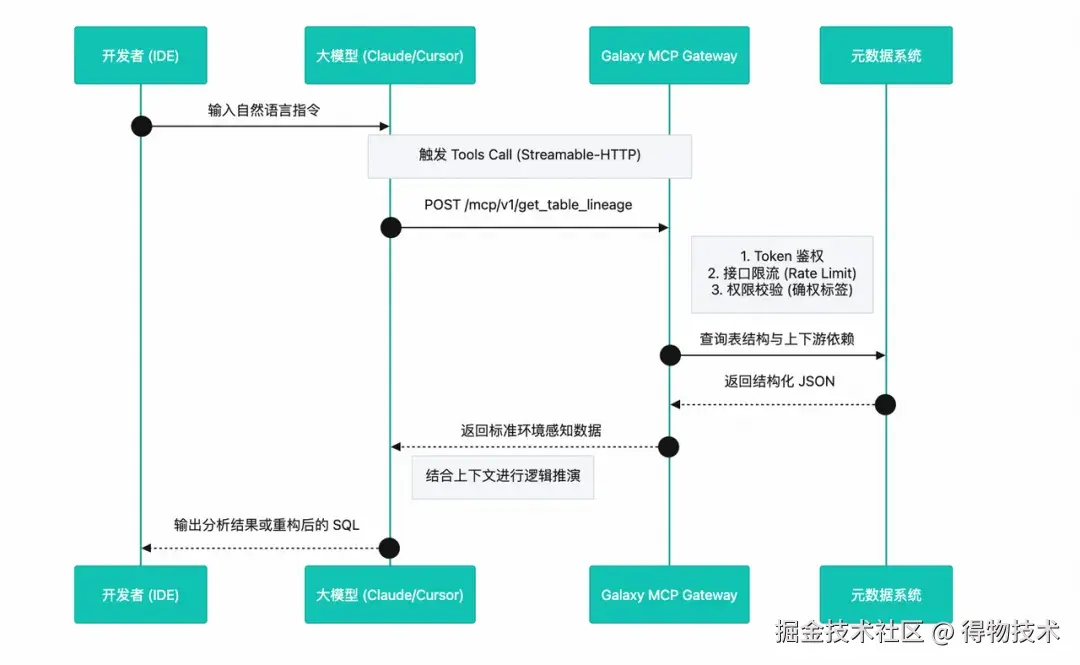
Galaxy MCP 充当了 Code LLM与企业内部数据资产之间的桥梁。传统模式下,工程师需要手动复制表结构、日志信息喂给大模型;而在 MCP 架构下,大模型被赋予了“手和眼”。
通过提供统一的 HTTP Streamable 接口与 Bearer Token 鉴权机制,MCP 使得大模型能够在安全受控的前提下,直接调用底层数据平台的 API。这种集成的本质,是为大模型提供了标准化的环境感知输入。
Galaxy MCP 向大模型暴露了一系列高度结构化的工具(Tools),这些工具构成了 Agent 执行复杂任务的基础原子。核心 API 及其对应的数仓场景映射如下:
在工程落地中,Galaxy MCP 实现了与主流 AI IDE 的无缝集成。通过上述配置,开发者在 IDE 中只需输入自然语言指令(如:“读这个表试试:xxx.table_name”),底层大模型即可自动路由至 Galaxy MCP,完成鉴权、API 调用与结果解析的闭环。这标志着数仓开发正式迈入 Agentic 时代。
本章将结合得物App数仓研发实证,以实际应用阐述上述底层逻辑在实际业务线中的落地场景。下面的每一个场景,均是在内部经过多轮POC验证,是“规范化输入与输出”理念的具体投射。
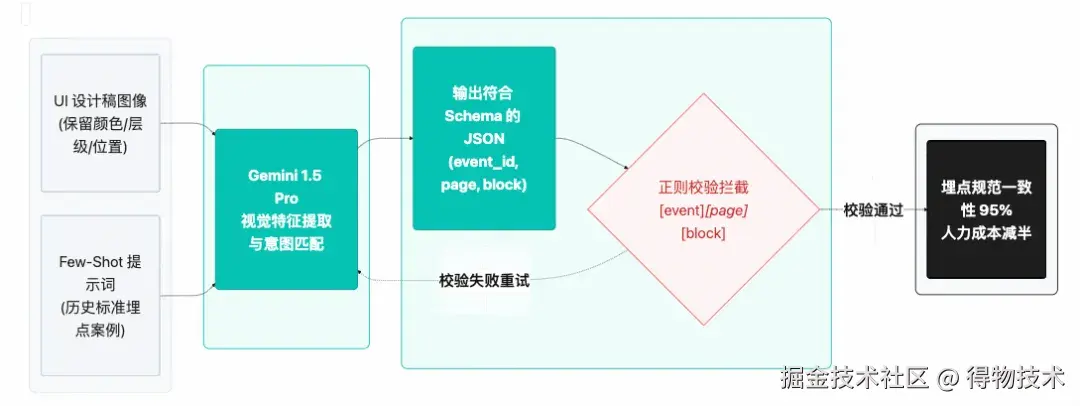
业务背景: 埋点设计是数仓数据采集的前置环节。传统流程长期存在三大痛点:
like_click 与 click_like_btn 混用),极大增加下游清洗成本。规范化 I/O 逻辑:
event_id 必须严格符合 [event]_[page]_[block] 的格式,且事件与参数定义强绑定业务规范字典,杜绝开发随意造词。参数收敛: 基于历史权威字典,自动映射并收敛同义参数,消除发散。参数完备性: 结合业务场景自动补全必填上下文参数,避免漏埋。实测效能: 在某社区线双周迭代抽样中,埋点设计人力投入从平均10人日缩减至5人日。更核心的收益在于:
业务背景: OneData 方法论要求严格的数据分层与指标口径统一。但在人工执行时,面对复杂的表血缘关系,规范的遵守率往往存在波动,且梳理历史口径耗时巨大。一个典型的 OneData 项目,纯人工梳理口径溯源、编写白皮书往往需要耗费数月。
规范化 I/O 逻辑:
实测效能: 在某业务线包含 34 张表、涉及 6 个粒度的 OneData 重构项目中,对比历史同等规模项目的纯人工评估耗时(约 60 人日),采用 AI 辅助与人工复核结合的模式,整体交付周期缩短至 16 人日(提效约 74%)。由于机器执行规范的绝对一致性,文档的格式统一度达到 100%。
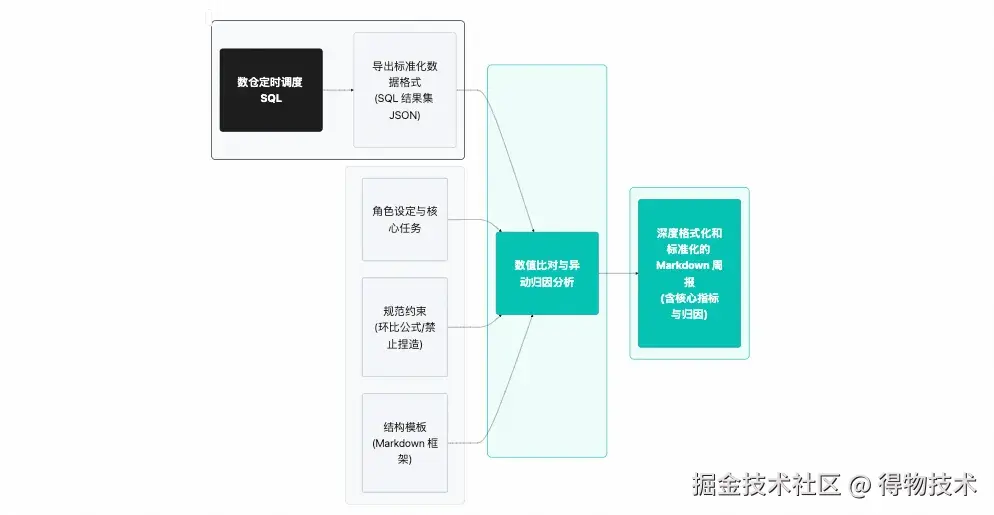
业务背景: 传统 BI 报表只能展示数据,无法解释数据。业务方需要的是“为什么跌了”,而不是“跌了多少”。但如果直接让 LLM 读取原始 CSV 数据生成周报,极易出现“幻觉”(如 1+1=3 的计算错误),因为 LLM 本质上是概率模型,不擅长精确的数学运算。
规范化 I/O 逻辑: 系统设计上存在两条并行路径,而其底层逻辑的起点是同一份 Prompt 规范文档。
该规范文档充当单一可信源(Single Source of Truth):在研发阶段,LLM 读取规范文档中精确定义的字段口径、聚合顺序与格式规则,将其编译为 Python 确定性计算模块(Spec-to-Code);在运行时,同一份规范又作为约束契约传入 LLM,驱动语义叙事输出。这意味着规范的变更(如修改 WoW 计算口径)只需更新一处,两条路径同步收敛。
路径一(Python 计算层): 由 LLM 依据规范编译生成的 Python 模块负责所有确定性运算——WoW/YoY 计算、渠道贡献度排序、量级格式化(万/亿分档)——输出已预渲染的 Markdown 文本片段,不再含任何原始数值。
路径二(LLM 叙事层): 模型接收的是无需再做任何数学运算的结构化文本,其唯一任务是完成跨模块的趋势判断与业务归因叙述(如"供给下降叠加搜索量上升 → 供需错配")。
核心价值: 这一架构的核心价值在于:将 LLM 的不确定性严格限制在语义层,将数值精度的责任锁定在代码层,两者各自处于自身最可控的能力边界内,从根本上规避了"让模型直接计算 CSV 原始数据"所带来的计算幻觉与格式漂移风险。
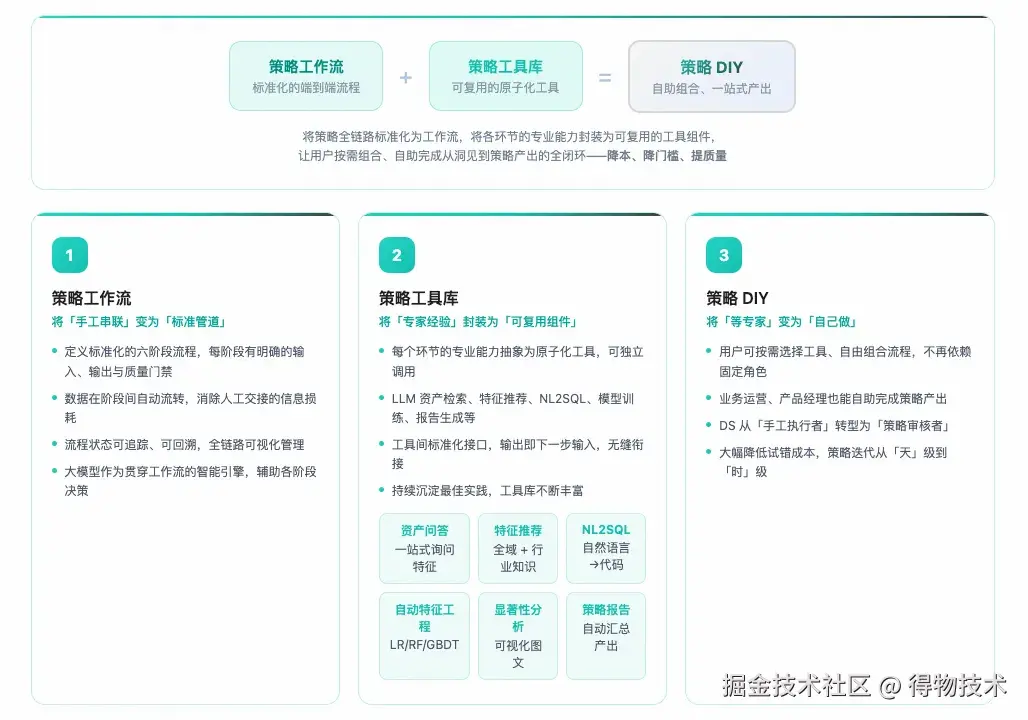
业务背景: 区别于纯粹的 Coding 提效,业务冷启动阶段(如违规作者探查)涉及完整的策略工作流:定义目标 -> 数据收集 -> 特征筛选 -> 模型训练 -> 效果回收。该过程涉及业务方、分析师、数据科学家等多个角色,存在巨大的信息损耗与特征选择的“效率孤岛”。特征选择的质量高度依赖于个人的隐性能力。
规范化 I/O 逻辑:
策略孵化中心将这一复杂的非线性探索过程,重构为基于 AI Agent 的标准化流水线,包含四大核心模块:
项目演进里程碑:
实测效能: 策略生成到落地的整体周期由 10 人日缩短至 1-2 人日,提效 3-5 倍。AI 的介入不仅加快了策略迭代的频率(策略新鲜度),更通过标准化流程降低了对个人隐性经验的依赖,使得策略的专业度与准确率显著提升。
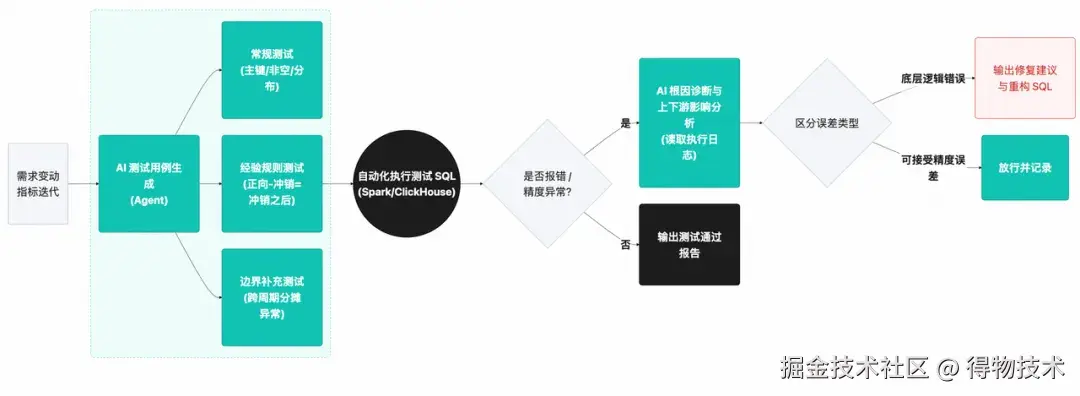
业务背景: 财务级数据指标(如实收、补贴、平台服务费等)具有严格的勾稽关系。针对此类指标编写覆盖全面的边界测试用例耗时极长,且业务语言(如“邮费返利抵减技术服务费”)转化为测试 SQL 极其困难。
规范化 I/O 逻辑:
实测效能: 构建了“质量守夜人”机制,测试覆盖率大幅提升。在某财务项目中,模型自动生成了 20 余个复杂的校验 SQL,将数据质量卡点前置到开发阶段,显著降低了上线后的数据事故率,实现了从“人工抽测”到“机器全量自动化校验”的范式跃迁。
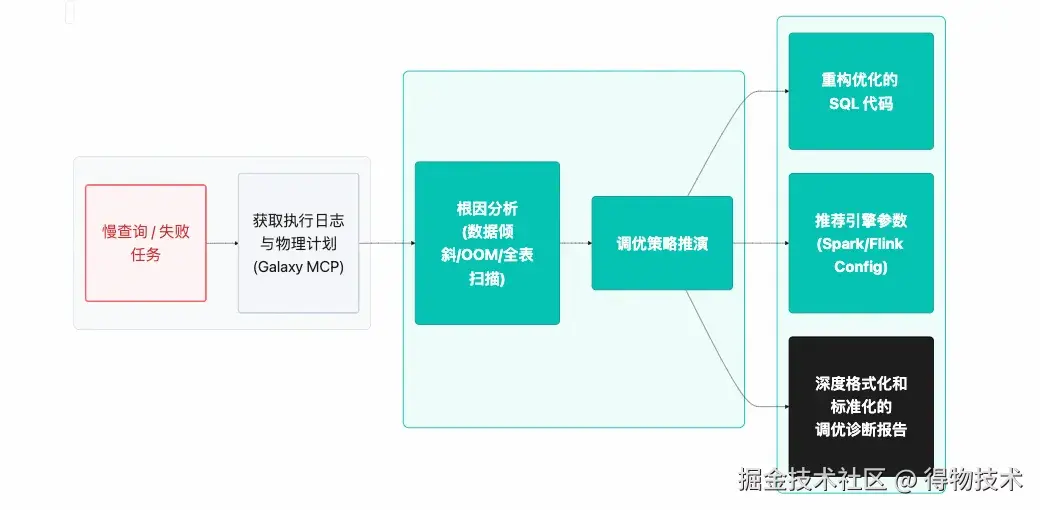
业务背景: 数仓日常运维中,Spark 任务的排查与调优(如数据倾斜、OOM、执行计划不合理)高度依赖工程师的个人经验。排查过程需要频繁查看 Spark UI,分析 DAG 图、Stage 耗时、Shuffle 数据量等,耗时且门槛高。
规范化 I/O 逻辑:
实测效能: 将单次复杂任务排查时间从数小时缩减至分钟级。不仅大幅提升了运维效率,更将资深专家的调优经验固化为标准化的 Agent 技能(Skill),显著降低了团队的整体技术门槛。
在上述所有工程实践中,提示词(Prompt)不再是简单的自然语言对话,而是演变为了系统架构的一部分。高质量的提示词工程是实现规范化 I/O 的核心载体。
在传统的开发模式中,系统配置通常是 YAML、JSON 或 XML 文件,用于指定数据库连接、调度频率等确定性参数。而在 AI Native 的数仓架构中,提示词承载了业务规则、编码规范与逻辑约束,成为了认知运行时的“配置文件”。这些提示词被纳入版本控制系统(如 Git),与底层代码同等对待,接受严格的 Code Review。
以智能周报生成场景为例,其核心的 周报数据prompt 采用了高度结构化的模块设计:
# 角色设定 (Role Definition)
你是一位资深的电商数据分析师,擅长从复杂的数据指标中提取业务洞察。
# 核心任务 (Core Task)
请基于提供的 [SQL 结果集 JSON],撰写本周的业务周报。
# 规范约束 (Constraints)
1. 必须使用 Markdown 格式,包含二级标题与无序列表。
2. 严禁捏造数据,所有数值必须来源于输入的数据集。
3. 环比计算公式为:(本期值 - 上期值) / 上期值,保留两位小数。
# 结构模板 (Output Template)
## 一、 核心指标概览
- GMV:[数值] (环比 [百分比])
- 转化率:[数值] (环比 [百分比])
## 二、 异动归因分析
[基于数据波动的具体分析]
这种模块化的提示词设计,将角色设定、任务描述、约束条件与输出模板严格分离,最大程度地降低了模型的幻觉概率,确保了输出结果的工程级可用性。
在电商数仓中引入 Code LLM,必须建立系统性的风险管控体系,以应对大模型固有的技术缺陷及企业合规要求。
大模型在处理复杂表关联时,可能捏造不存在的字段或错误理解业务逻辑。管控方案包括:
数据仓库包含大量商业机密与用户隐私,使用 LLM(特别是调用外部公有云 API 时)存在数据泄露风险。管控方案包括:
Code LLM 对电商数据仓库的介入,绝非停留在代码补全的表层提效,而是推动了数仓研发范式的底层演进。通过界定数据确权的管理边界,研发团队能够安全地将技术实现环节交由 AI 辅助;通过引入规范驱动开发(SDD)与 Agentic 工作流,并以“规范化的输入与输出”为核心,有效抑制了大模型的不确定性。
从 Galaxy MCP 的底层基础设施打通,到智能埋点、OneData 建模、周报自动化,再到端到端的策略孵化中心,大模型正在重塑数据流转的每一个节点。在这一演进过程中,数据工程师的核心职责正在发生转移:从繁重的 SQL 编码与基础排错,转向业务逻辑的抽象、规范契约的制定以及系统架构的最终决策。未来,基于 LLM 的认知运行时将与大数据执行运行时更加深度地融合,持续推动数据仓库向智能化、自动化的方向演进。
1.Claude Code + OpenSpec 正在加速 AICoding 落地:从模型博弈到工程化的范式转移|得物技术
2.大禹平台:流批一体离线Dump平台的设计与应用|得物技术
3.基于 Cursor Agent 的流水线 AI CR 实践|得物技术
4.从IDE到Terminal:适合后端宝宝体质的Claude Code工作流|得物技术
5.AI编程能力边界探索:基于 Claude Code 的 Spec Coding 项目实战|得物技术
关注得物技术,每周更新技术干货
要是觉得文章对你有帮助的话,欢迎评论转发点赞~
未经得物技术许可严禁转载,否则依法追究法律责任。
Cursor 和 Claude Code:AI 编程的两种哲学
Day10 学习日志:用 LangChain 搭一套可落地的**制度 RAG**(检索 + 生成)

