城市繁荣合并建造
94.53M · 2026-03-29

随着数据密集型应用的快速发展,哈希索引已成为内存数据库、键值存储和重复数据删除系统的核心组件。传统哈希索引在面对持久内存(PMem)时,由于存储流量放大和内存效率低下,难以充分利用其大容量和持久性优势。为此,OceanBase研究人员联合厦门大学、昆士兰大学学生及教授提出了一种新型哈希索引设计MetoHash,通过层次化设计、批量持久、指纹过滤和重复合并等技术,有效解决了传统方案在存储I/O放大和内存效率方面的问题。
随着数据密集型应用的快速增长,能够实现常数级查找复杂度的哈希索引已成为构建内存数据库、键值存储和重复数据删除系统的核心组件。传统哈希索引在面对新兴的持久内存时,虽然利用了其大容量和数据持久性优势,却在存储流量放大和内存效率方面面临严峻挑战。
持久内存以其大容量、数据持久性、近DRAM性能等特性,为内存架构带来革命性变革。然而,PMem的固定访问粒度和持久化CPU缓存特性,使得传统哈希索引设计难以充分发挥其硬件潜力,其原因在于现有方案极易放大存储I/O或降低内存效率。
日前,一篇题为《MetoHash: A Memory-Efficient and Traffic-Optimized Hashing Index on Hybrid PMem-DRAM Memories》的论文被高性能计算顶级会议SC 2025录用,并荣获最佳学生论文提名(该会议录用的136篇论文中选择6篇)。该论文由厦门大学、昆士兰大学与OceanBase的研究人员联合完成。其中,厦门大学硕士生余子祥、邓光阳为共同第一作者,沈志荣教授为通讯作者;昆士兰大学鲍芝峰教授,以及OceanBase的徐泉清、杨传辉研究员共同参与了此项研究。
SC由美国计算机协会(ACM)与美国电气电子工程师学会(IEEE)于1988年共同创办,是全球高性能计算领域公认的年度顶级盛会,是中国计算机学会CCF推荐的A类国际会议。SC 2025会议共收到643篇投稿,接收136篇,录用率21.2%。
本论文的核心思想是构建一个跨越CPU缓存、DRAM和PMem的三层索引架构,让数据在层次化存储中高效流动。
本文提出的MetoHash通过层次化设计、批量持久、指纹过滤、重复合并等关键技术,系统性地解决了现有方案在流量放大与内存效率上的痛点,为高性能键值存储、内存数据库、实时分析等应用提供了强大的底层支撑。
传统哈希索引在面对由持久内存(PMem)和动态随机存取内存(DRAM)构成的混合内存系统时,面临一个根本性矛盾:若为追求PMem的持久性而将索引完全置于其中,则会因PMem较高的访问延迟和固定的写入粒度导致严重的性能下降和I/O放大;若为追求速度而将索引完全置于DRAM,则又无法利用PMem的大容量和持久化优势。
MetoHash的创新核心理念在于“解耦与协同”。它不再将哈希索引视为一个单一的整体,而是将其功能拆解,并根据CPU缓存、DRAM和PMem的不同硬件特性进行重新部署,构建了一个三层的高效数据管理流水线。其目标是让热数据、元数据和海量持久化数据分别在最适合的存储层级上被处理,从而在整体上实现高吞吐、低延迟、低流量和高内存效率的统一。
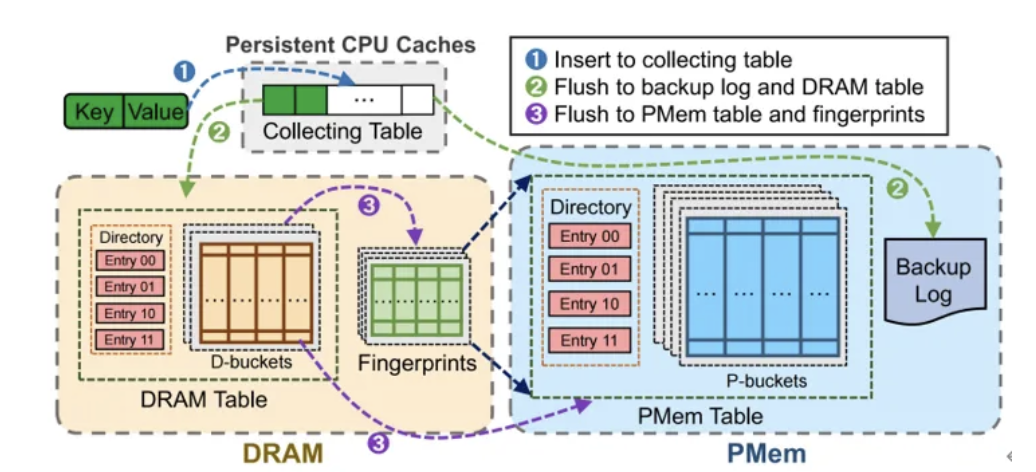
图1MetoHash的三层索引结构
此技术旨在根治向PMem进行小粒度插入时引发的“写放大”(Write Amplification)与频繁桶探测问题。其方案是在持久性CPU缓存中预分配多个与PMem访问粒度对齐的“收集表”(Collecting Table)。新到达的键值对根据哈希值被直接路由到相应收集表,并通过原子操作实现无锁快速插入,从而充分利用缓存的高速与持久化特性。当一个收集表被填满时,其包含的多个键值对将作为一个完整的、与PMem最佳写入粒度匹配的数据单元,被一次性顺序刷写到PMem的备份日志中。这种方法彻底消除了因写入粒度不匹配带来的额外I/O流量,充分利用PMem的写入带宽,同时将零散插入转化为高效批量操作。
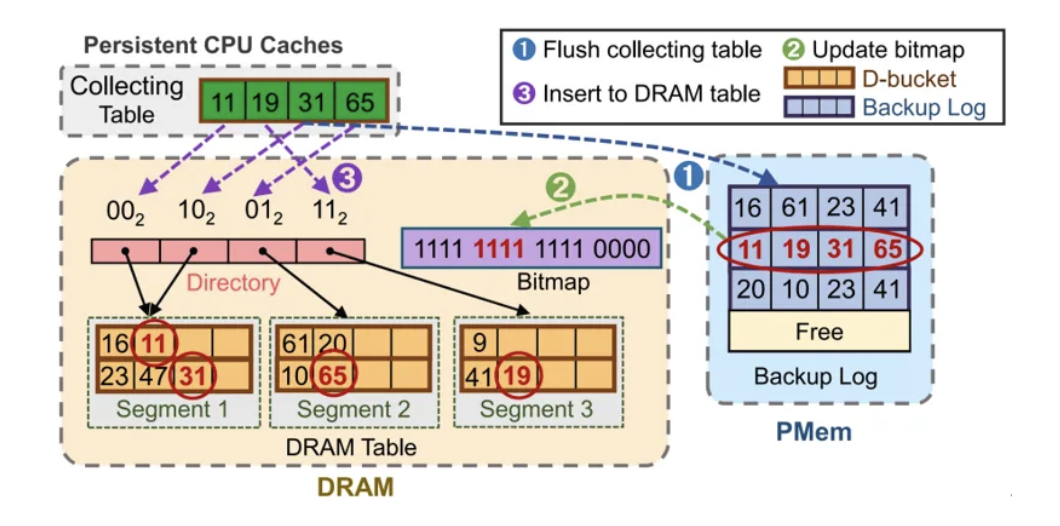
图2持久缓存刷入DRAM和PMem中
该技术致力于解决在混合多层索引中查询时在PMem层进行盲目、耗时的桶探测的瓶颈。其核心是在DRAM中维护一个紧凑的“指纹”目录,其本质为PMem主哈希表中的每个键哈希值的一个简短片段。
在进行查询时,系统首先计算查询键的指纹,并利用SIMD指令等在DRAM指纹目录中进行高速并行比对,迅速筛选出PMem中少数几个可能匹配的位置。只有这些候选位置,才需要访问PMem进行精确的键值比较。整个查询遵循PMem主表→ DRAM表→ CPU缓存收集表的反向路径,确保定位到有效值。这一设计将耗时的海量比对操作从慢速的PMem转移至高速的DRAM,极大减少了查询延迟与PMem访问压力。
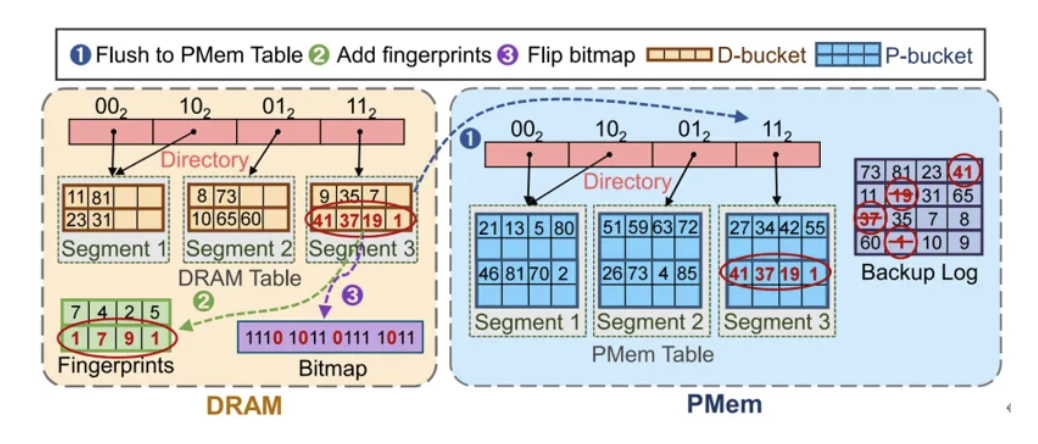
图3DRAM结构刷入PMem中,并在DRAM中保留指纹
为解决“先插入后检查”模式可能产生的键重复问题以及删除操作导致的空间碎片化问题,MetoHash在数据结构段分裂中引入合并与清理机制。
首先,DRAM桶与PMem桶在逻辑布局上严格对齐,使得DRAM桶满时其内容能高效批量刷写至PMem对应位置。当PMem中某个段需要分裂以扩容时,系统将旧段所有数据读入DRAM,在此过程中主动识别并消除同一键的多个版本的无效值,仅保留其最新的有效项,并将合并、去重后的结果写入新分配的段。此过程自然跳过了已标记删除的项,从而在完成容量扩展的同时,一举实现了存储空间的即时回收与整理,保持了PMem存储的紧凑性与查询效率。
在实际搭载英特尔傲腾持久内存的测试平台上,MetoHash与八种前沿方案进行了全面对比。
①吞吐量提升:在YCSB等各类负载下,其吞吐量平均超越以往方案86.1%至257.6%,并呈现近线性扩展能力。

图4MetoHash相较其他基线索引在不同负载下均有明显优势
②变长数据支持:在处理16B至256B的变长键值时,其吞吐量平均仍领先对比方案190.8%,尤其在小值主导的负载中优势显著。
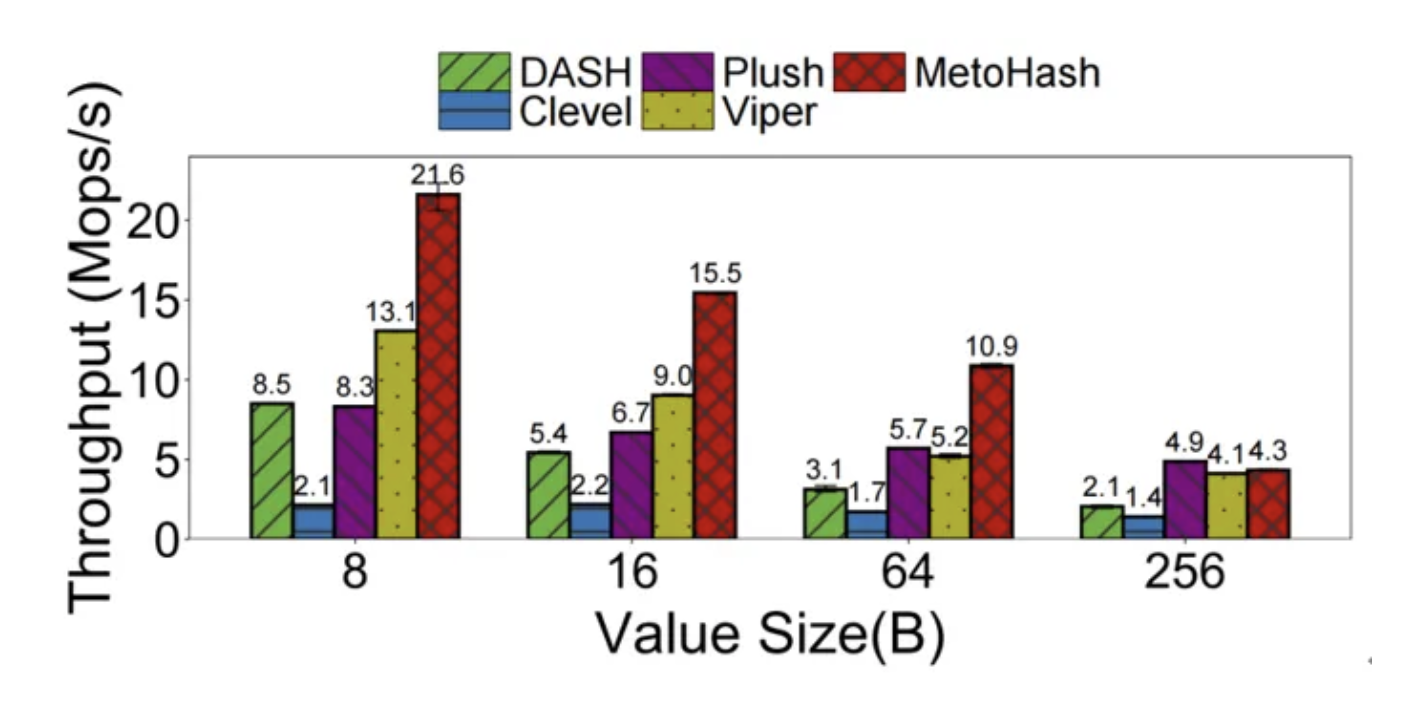
图5MetoHash相较于其他基线索引在不同键值对大小下均有明显优势
③内存效率权衡:相比将全部索引存于DRAM的方案(如VIPER),MetoHash的DRAM占用减少86.7%;相比PMem利用率低的方案(如Plush),MetoHash的PMem占用减少86.5%。
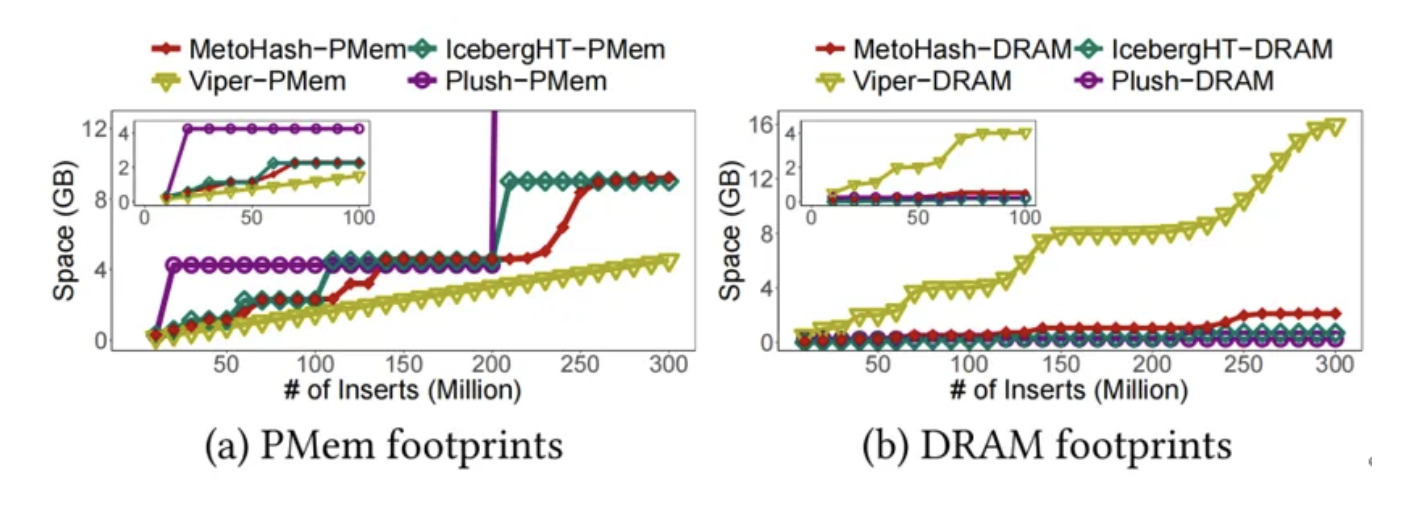
图6MetoHash相较于其他基线索引能够取得较好的DRAM/PMem效率权衡
这项工作提出的MetoHash混合内存哈希索引,为持久内存时代的高性能、高内存效率数据管理提供了系统的解决方案。在理论上,MetoHash首次通过缓存、DRAM、PMem三层协同的架构,解决了由PMem固定访问粒度引发的I/O放大与内存效率低下这一对核心矛盾。在实践中,其在多种负载下的吞吐量相较当前方案平均提升86.1%至257.6%,存储流量大幅降低,内存占用显著优化,在多种负载中验证了其卓越性能。
欢迎访问OceanBase官网获取更多信息:https://www.oceanbase.com/
,
