职业杀手
26.53M · 2026-03-25

很多研发团队都会陷入这样的恶性循环:需求迭代越快,代码腐化越严重,新人接手项目需要一周才能理清逻辑,改一行代码引发三个线上bug,线上问题定位全靠猜,技术债务越堆越高,最终整个项目变成不敢碰、不敢改的“屎山”。
本质上,这些问题的根源不是开发者能力不足,而是缺少一套可落地、可校验、全链路的Java工程化规范体系。规范不是束缚研发效率的条条框框,而是团队协作的“通用语言”,是降低沟通成本、减少技术债务、提升迭代效率的核心保障。一套完善的工程化体系,能让团队的每一行代码都符合统一标准,每一次协作都有明确流程,最终实现可持续的高质量研发交付。
代码规范是工程化体系的基石,所有规则均基于Java语言规范(JLS)、行业通用最佳实践制定,覆盖编码全流程,每一条规则都有明确的正例与反例,避免模糊不清的主观判断。
命名的核心原则是“见名知意”,禁止使用缩写、拼音、无意义的单字符,严格遵循Java语言的大小写约定,从命名上就能明确元素的职责与类型。
// 反例:包名使用大写、下划线,违反Java全局约定
package Com.MyCompany.User_Project;
// 反例:类名使用小驼峰,职责模糊
public class userInfo {
// 反例:常量未全大写,静态变量与常量混淆
public static final int maxCount = 100;
// 反例:方法名使用大驼峰,含义模糊
public void GetData() {}
// 反例:参数使用无意义单字符
public void query(String a) {}
}
// 正例:包名全小写,使用反域名格式,按业务模块划分
package com.mycompany.userproject.user.domain;
// 正例:类名大驼峰,明确表达实体职责
public class UserInfo {
// 正例:常量全大写,下划线分隔,明确含义
public static final int MAX_QUERY_COUNT = 100;
// 正例:方法名小驼峰,动词开头,明确表达行为
public List<UserInfo> queryUserListByDeptId(Long deptId) {}
// 正例:参数名明确表达含义,无歧义
public void queryUserByPhone(String userPhone) {}
}
public static final修饰的不可变元素(基本类型、String、不可变枚举)可称为常量,命名全大写;static final修饰的集合、数组等可变元素,属于静态变量,使用小驼峰命名,禁止当作常量使用。// 反例:可变集合被当作常量定义
public static final List<String> USER_TYPE_LIST = Arrays.asList("NORMAL", "VIP");
// 正例:不可变常量定义
public static final List<String> USER_TYPE_LIST = Collections.unmodifiableList(Arrays.asList("NORMAL", "VIP"));
// 正例:静态变量定义
private static List<String> userTypeCache = new ArrayList<>();
is开头,避免部分序列化框架的反射解析异常,使用can、has、is等语义前缀的形容词格式。// 反例:布尔字段以is开头,导致getter/setter解析异常
private boolean isDeleted;
// 正例:布尔字段语义清晰,无解析风险
private boolean deleted;
private boolean hasPermission;
private boolean canEdit;
格式规范的核心是消除团队成员的代码排版差异,避免Code Review时出现大量格式变更,让开发者只需要关注代码逻辑本身。所有格式规则均可通过IDE格式化配置实现自动化统一,无需人工干预。
*通配符导入,未使用的包必须清理,导入顺序按java.*、javax.*、第三方包、项目内部包分组,组间空一行分隔。空指针异常是Java线上最常见的运行时异常,通过固定的编码规范可从源头规避90%以上的空指针风险。
// 反例:直接调用对象方法,无空值校验
if (user.getUserName().equals("admin")) {}
// 反例:冗余的空值校验,可读性差
if (user != null) {
if (user.getDept() != null) {
if (user.getDept().getDeptId() != null) {}
}
}
// 正例:常量在前,规避空指针
if ("admin".equals(user.getUserName())) {}
// 正例:使用Objects工具类做非空校验
Objects.requireNonNull(user, "用户信息不可为null");
// 正例:使用空安全的流式调用,避免多层嵌套校验
Long deptId = Optional.ofNullable(user)
.map(User::getDept)
.map(Dept::getDeptId)
.orElse(0L);
Optional的设计初衷是为方法返回值提供明确的“可能为空”的语义标识,禁止滥用在其他场景。
// 反例:方法参数使用Optional,增加调用成本
public void queryUser(Optional<Long> userId) {}
// 反例:类字段使用Optional,增加内存开销
private Optional<String> userPhone;
// 反例:集合元素使用Optional,完全违背设计初衷
List<Optional<User>> userList;
// 反例:直接调用get()方法,不做空判断
User user = userDao.findById(userId).get();
// 正例:仅用于方法返回值,明确表达空语义
public Optional<User> findById(Long userId) {
if (userId == null) {
return Optional.empty();
}
return Optional.ofNullable(userMapper.selectById(userId));
}
// 正例:安全的消费式使用
userService.findById(userId)
.ifPresent(user -> log.info("查询到用户:{}", user.getUserName()));
// 正例:空值时抛出明确异常
User user = userService.findById(userId)
.orElseThrow(() -> new IllegalArgumentException("用户不存在, userId:" + userId));
集合是Java开发中最高频的工具,错误的使用方式会导致性能问题、并发异常、内存泄漏等风险。
预期元素个数 / 0.75 + 1,符合HashMap的负载因子默认规则。// 反例:无初始容量,插入1000个元素会触发多次扩容
List<String> list = new ArrayList<>();
Map<Long, User> userMap = new HashMap<>();
// 正例:指定初始容量,避免扩容
List<String> list = new ArrayList<>(1000);
Map<Long, User> userMap = new HashMap<>(1024);
ConcurrentModificationException,必须使用迭代器的remove方法。// 反例:foreach循环中删除元素,触发异常
for (String item : list) {
if (item.equals("test")) {
list.remove(item);
}
}
// 正例:使用迭代器安全删除
Iterator<String> iterator = list.iterator();
while (iterator.hasNext()) {
String item = iterator.next();
if (item.equals("test")) {
iterator.remove();
}
}
// 反例:无数据时返回null,增加调用方风险
public List<User> queryUserList() {
if (count == 0) {
return null;
}
return userMapper.selectAll();
}
// 正例:无数据时返回空集合
public List<User> queryUserList() {
if (count == 0) {
return Collections.emptyList();
}
return userMapper.selectAll();
}
异常处理的核心原则是“早抛出,晚捕获”,只捕获能处理的异常,无法处理的异常必须向上抛出,禁止任何形式的异常吞噬,保留完整的异常栈信息,为线上问题定位提供完整链路。
// 反例:捕获顶级Exception,吞掉所有异常,无日志无处理
public void updateUser(User user) {
try {
userDao.update(user);
} catch (Exception e) {
e.printStackTrace();
}
}
// 反例:捕获异常后重新抛出,丢失原异常栈信息
public void updateUser(User user) {
try {
userDao.update(user);
} catch (SQLException e) {
throw new BusinessException("更新失败");
}
}
// 正例:捕获具体异常,打印完整日志,保留原异常栈抛出
private static final Logger log = LoggerFactory.getLogger(UserService.class);
public void updateUser(User user) {
Objects.requireNonNull(user, "用户信息不可为null");
try {
userDao.update(user);
} catch (SQLException e) {
log.error("更新用户信息失败, userId:{}", user.getId(), e);
throw new BusinessException("用户信息更新失败", e);
}
}
日志是线上问题定位的唯一可靠依据,规范的日志打印能将问题定位时间从小时级缩短到分钟级,核心规则围绕“信息完整、级别正确、性能安全、脱敏合规”四个维度制定。
// 反例:使用字符串拼接,产生大量临时对象,影响性能
log.debug("查询到用户信息:" + user.getUserName() + ", userId:" + user.getId());
// 反例:异常日志未打印异常栈,无法定位问题
log.error("用户更新失败, userId:{}", user.getId());
// 反例:打印敏感信息,违反数据合规要求
log.info("用户登录成功, phone:{}, password:{}", user.getPhone(), user.getPassword());
// 正例:使用占位符,性能最优,参数清晰
log.info("用户登录成功, userId:{}, userName:{}", user.getId(), user.getUserName());
// 正例:异常日志最后一个参数传入异常对象,自动打印完整栈信息
log.error("用户更新失败, userId:{}", user.getId(), e);
// 正例:敏感信息脱敏打印,兼顾定位需求与合规要求
log.info("用户支付完成, userId:{}, bankCard:{}", user.getId(), maskBankCard(user.getBankCard()));
使用MDC全链路追踪上下文,在请求入口处注入traceId,贯穿整个请求链路,所有日志均携带traceId,可在分布式系统中快速筛选出单个请求的完整日志链路。
// 请求入口处注入traceId
public class TraceInterceptor implements HandlerInterceptor {
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) {
String traceId = UUID.randomUUID().toString().replace("-", "");
MDC.put("traceId", traceId);
return true;
}
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) {
MDC.clear();
}
}
<!-- logback配置中,日志格式添加traceId -->
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] [%X{traceId}] %-5level %logger{36} - %msg%n</pattern>
注释的核心原则是“代码无法表达的信息才需要注释”,禁止注释代码本身就能看懂的逻辑,避免注释与代码逻辑不一致的问题。
/**
* 用户领域服务接口
* 负责用户核心信息的增删改查与业务校验,所有方法均保证数据一致性
* @author 研发团队
* @since 1.0.0
*/
public interface UserService {
/**
* 根据用户ID查询用户详情
* @param userId 用户唯一标识,不可为null
* @return 对应用户详情,无数据时返回Optional.empty()
* @throws IllegalArgumentException 当userId为null时抛出
*/
Optional<User> findById(Long userId);
}
// 业务逻辑注释正例:说明特殊处理的原因,而非代码逻辑
// 因历史数据存在手机号为空的情况,此处需做空值过滤,避免下游校验失败
List<User> validUserList = userList.stream()
.filter(user -> user.getPhone() != null)
.toList();
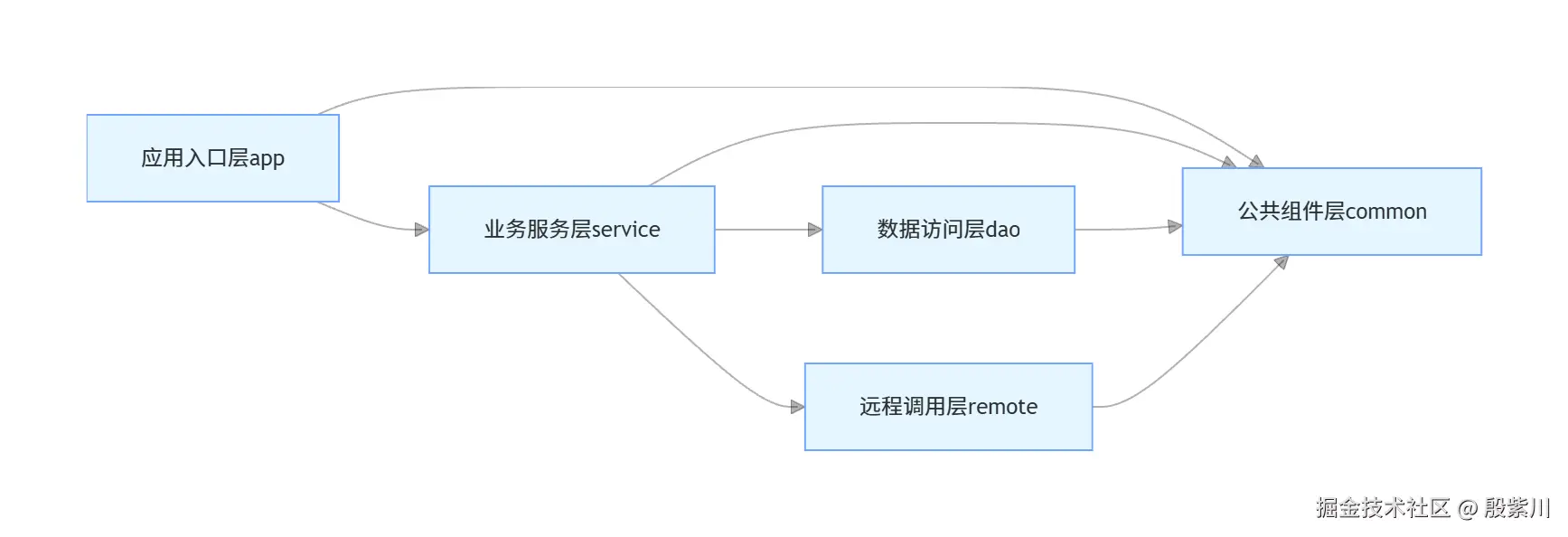
统一的工程结构是团队协作的基础,能让新人在10分钟内找到对应的代码模块,明确每个模块的职责边界,避免循环依赖、职责混乱的问题。
基于Maven标准目录结构,按业务职责拆分模块,采用分层架构,明确每层的依赖规则,禁止反向依赖与循环依赖。
| 模块 | 核心职责 | 允许依赖 | 禁止依赖 |
|---|---|---|---|
| app | 应用启动、配置管理、接口暴露、全局拦截器 | service、common | 禁止被其他模块依赖 |
| service | 核心业务逻辑、事务管理、业务校验 | dao、remote、common | 禁止依赖app模块 |
| dao | 数据访问、数据库交互、SQL封装 | common | 禁止依赖service、app模块 |
| remote | 第三方服务调用、接口适配、熔断降级 | common | 禁止依赖service、app模块 |
| common | 通用工具类、常量定义、异常类、通用DTO | 无内部模块依赖 | 禁止依赖其他业务模块 |
project-parent
├── user-common
│ └── src/main/java/com/mycompany/user/common
│ ├── constant
│ ├── exception
│ ├── dto
│ ├── utils
│ └── enums
├── user-dao
│ └── src/main/java/com/mycompany/user/dao
│ ├── mapper
│ ├── entity
│ └── repository
├── user-service
│ └── src/main/java/com/mycompany/user/service
│ ├── api
│ ├── impl
│ └── domain
├── user-remote
│ └── src/main/java/com/mycompany/user/remote
│ ├── client
│ ├── fallback
│ └── dto
└── user-app
└── src
├── main/java/com/mycompany/user/app
│ ├── UserApplication.java
│ ├── config
│ ├── controller
│ ├── interceptor
│ └── advice
├── main/resources
│ ├── application.yml
│ ├── application-dev.yml
│ ├── application-prod.yml
│ └── logback-spring.xml
└── test/java
依赖管理的核心是解决版本冲突问题,统一管理所有依赖的版本,避免不同模块引入不同版本的依赖,导致类加载异常。
dependencyManagement统一声明所有依赖的版本,子模块引入依赖时无需指定版本,保证全项目依赖版本一致。application.yml(公共配置)、application-dev.yml(开发环境)、application-test.yml(测试环境)、application-prod.yml(生产环境),通过启动参数指定激活的环境。server:
port: 8080
servlet:
context-path: /user-service
spring:
application:
name: user-service
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://${mysql.host:127.0.0.1}:${mysql.port:3306}/user_db?useUnicode=true&characterEncoding=utf8
username: ${mysql.username:root}
password: ${mysql.password}
mybatis:
mapper-locations: classpath:mapper/*.xml
configuration:
map-underscore-to-camel-case: true
log-impl: org.apache.ibatis.logging.slf4j.Slf4jImpl
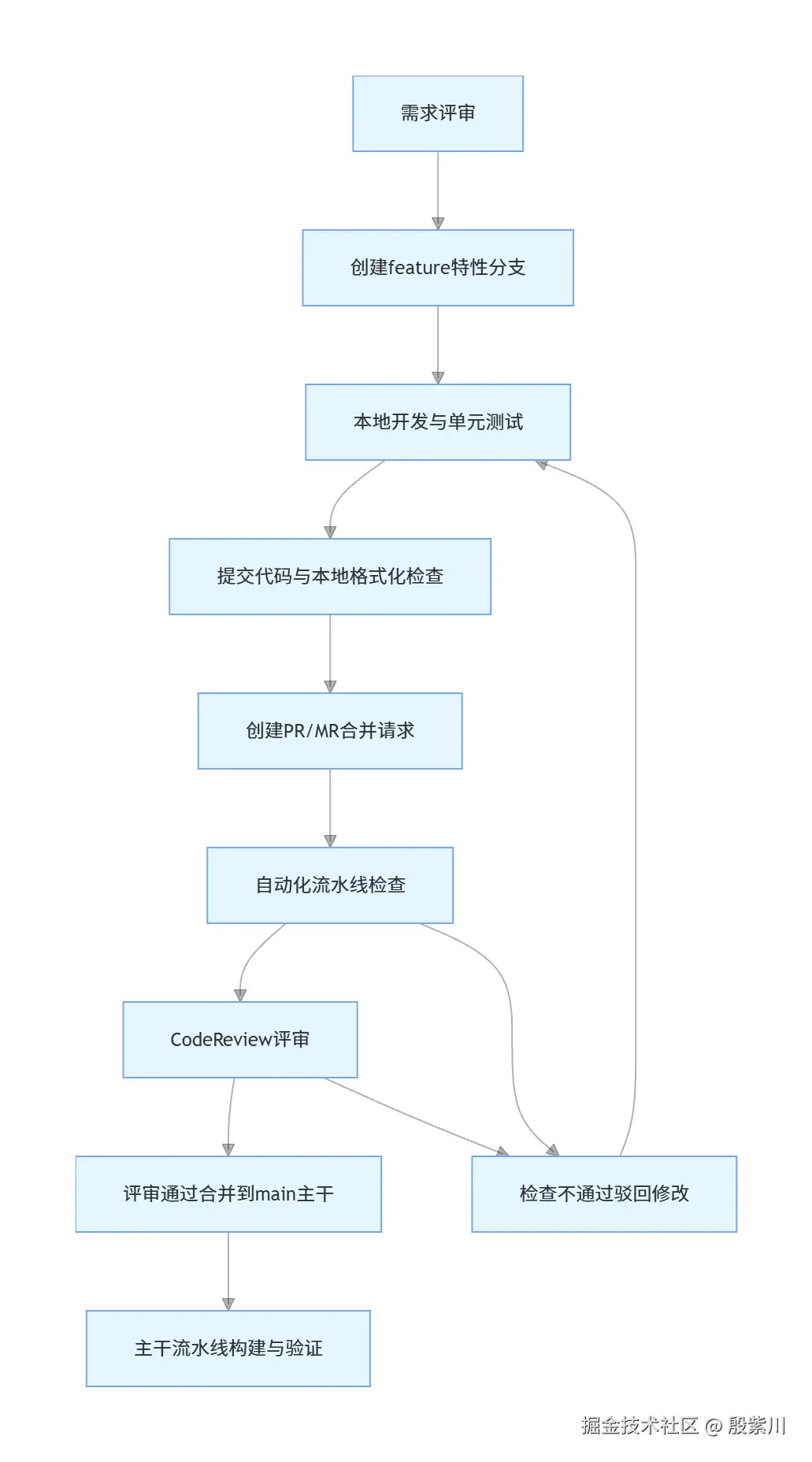
代码规范是基础,而规范的落地需要一套标准化的团队协作流程,确保每一行代码的提交、合并、发布都有明确的规则,避免团队协作混乱。
分支管理的核心是保证主干代码的稳定性,所有开发工作都在特性分支完成,经过校验后才能合并到主干,禁止直接向主干提交代码。这里采用行业主流的Trunk Based Development模式,适合持续集成、持续交付的研发团队,流程简单高效,避免多分支维护的复杂度。
| 分支类型 | 命名规范 | 核心职责 | 生命周期 |
|---|---|---|---|
| 主干分支 | main | 存放随时可发布的稳定代码,保护分支,禁止直接提交 | 长期 |
| 特性分支 | feature/业务模块-功能描述 | 新功能开发、需求迭代 | 临时,功能合并后删除 |
| 缺陷修复分支 | bugfix/缺陷编号-问题描述 | 线上缺陷修复、bug处理 | 临时,修复合并后删除 |
| 发布分支 | release/版本号 | 版本发布前的准备、测试、预发验证 | 临时,发布完成后合并到main并删除 |
| 热修复分支 | hotfix/版本号-问题描述 | 线上紧急问题修复,不影响其他功能 | 临时,修复发布后合并到main并删除 |
提交信息必须遵循Conventional Commits规范,格式统一,语义清晰,便于后续筛选提交记录、自动化生成CHANGELOG、回滚定位问题。
<type>(<scope>): <description>
| 类型 | 适用场景 | 示例 |
|---|---|---|
| feat | 新功能、新特性开发 | feat(user): 新增用户手机号登录功能 |
| fix | 缺陷修复、bug处理 | fix(order): 修复订单状态更新的并发问题 |
| docs | 文档修改、注释更新 | docs: 更新用户接口文档的参数说明 |
| style | 代码格式、排版修改,无业务逻辑变更 | style: 统一代码缩进与换行格式 |
| refactor | 代码重构,无业务逻辑变更、无bug修复 | refactor(user): 重构用户查询逻辑,提升可读性 |
| perf | 性能优化,无业务逻辑变更 | perf: 优化用户列表查询SQL,减少全表扫描 |
| test | 测试用例新增、修改、重构 | test: 补充用户支付流程的单元测试 |
| chore | 工程配置、依赖升级、工具类修改,无业务代码变更 | chore: 升级logback版本,修复安全漏洞 |
Code Review是保障代码质量的核心环节,不是形式主义,必须聚焦于代码逻辑、业务正确性、安全风险、性能问题,而非单纯的格式检查。
版本号严格遵循Semantic Versioning 2.0.0规范,格式为主版本号.次版本号.补丁版本号,每个版本号的升级都有明确的规则,避免版本号混乱。
仅靠文档和人工约束的规范,最终一定会流于形式,必须通过自动化工具,将所有规范嵌入到研发流程中,形成强制的质量门禁,不符合规范的代码无法提交、无法合并、无法发布。
静态代码检查是在编译阶段就能发现代码缺陷、规范问题的核心工具,将所有代码规范转化为可检查的规则,形成自动化的校验门禁。
工具组合:采用分层检查的工具组合,覆盖不同维度的代码问题
门禁规则:静态代码检查发现的阻断级、严重级问题,必须100%修复,否则无法合并代码;主要级问题修复率必须达到90%以上;次要级问题定期优化。
本地前置检查:通过Git Hooks将代码检查嵌入到提交环节,代码提交前必须通过本地格式化与基础检查,不符合规范的代码无法提交,提前发现问题,降低流水线的失败率。
测试是保障业务正确性的核心环节,通过标准化的测试规范,覆盖核心业务场景,避免代码变更引发线上问题。
单元测试规范:
被测试类名+Test,测试方法命名为测试场景_预期结果,采用Given-When-Then模式编写,结构清晰。import org.junit.jupiter.api.DisplayName;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.extension.ExtendWith;
import org.mockito.InjectMocks;
import org.mockito.Mock;
import org.mockito.junit.jupiter.MockitoExtension;
import java.util.List;
import static org.junit.jupiter.api.Assertions.*;
import static org.mockito.Mockito.*;
@ExtendWith(MockitoExtension.class)
@DisplayName("用户服务单元测试")
class UserServiceTest {
@Mock
private UserDao userDao;
@InjectMocks
private UserServiceImpl userService;
@Test
@DisplayName("根据用户ID查询用户-正常场景返回用户信息")
void findById_shouldReturnUserWhenUserIdIsValid() {
Long userId = 1L;
User mockUser = new User(userId, "testUser");
when(userDao.selectById(userId)).thenReturn(mockUser);
Optional<User> result = userService.findById(userId);
assertTrue(result.isPresent());
assertEquals(userId, result.get().getId());
verify(userDao, times(1)).selectById(userId);
}
@Test
@DisplayName("根据用户ID查询用户-参数为null时抛出异常")
void findById_shouldThrowExceptionWhenUserIdIsNull() {
assertThrows(NullPointerException.class, () -> userService.findById(null));
verifyNoInteractions(userDao);
}
}
CI/CD流水线是自动化规范落地的核心载体,将代码检查、编译、测试、打包、部署的全流程自动化,形成标准化的交付流程,避免人工操作带来的风险。
流水线核心阶段:
流水线规则:每一次代码提交都会触发主干流水线,只有流水线全阶段通过的制品,才能用于生产环境部署,禁止部署未经过流水线验证的代码。
很多团队的规范最终变成了“文档里的规范”,核心原因是只制定了规则,没有建立落地保障机制,陷入了为了规范而规范的误区。
Java工程化体系的核心,从来不是一堆条条框框的规则,而是“人-规范-工具”三位一体的协同体系。规范是团队协作的通用语言,工具是规范落地的强制保障,而人是体系的核心,所有的规范最终都是为了让开发者从重复的、低价值的工作中解放出来,专注于业务逻辑本身,提升团队的研发效率,降低技术债务,打造可持续的高质量研发交付能力。

