

职业杀手
26.53M · 2026-03-25

这篇文章想回答的,其实只有一个核心问题:为什么同样是调用一次大模型,有的平台按美元计费,有的平台显示的是“点数”“余额”“倍率”,而且开启缓存、开启 thinking 之后,扣费逻辑还会明显变化?
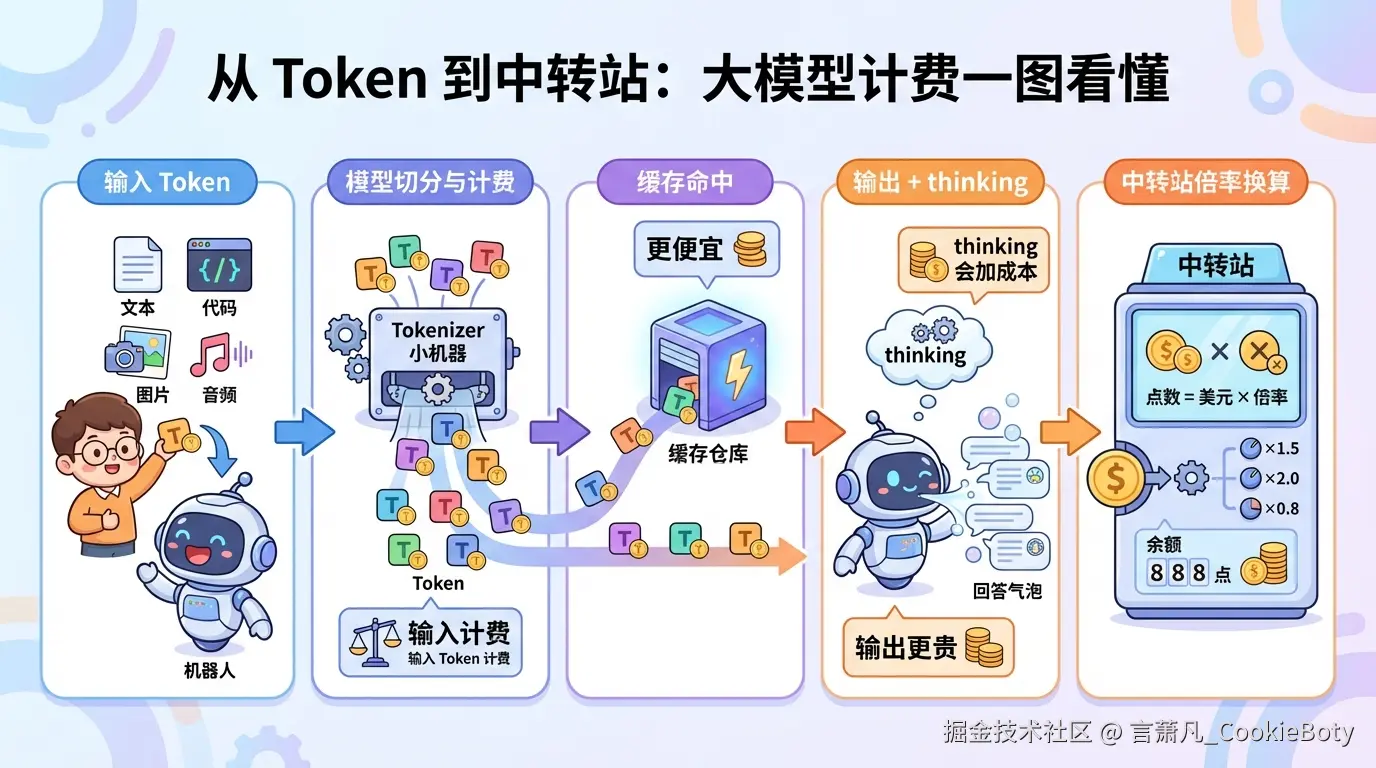
要把这件事讲明白,最好的顺序不是直接从“中转站倍率”讲起,而是先回到最底层:Token 是什么,模型到底按什么计费。只有先把官方的计费结构看清楚,后面再理解中转站为什么要引入倍率、配额和折算系数,才不会混淆。
在大模型的世界里,模型并不是按“字数”“句子数”或者“消息条数”来计费,而是按 Token 来计费。
你可以把 Token 理解为:模型处理信息时使用的最小计量单位之一。在最常见的文本场景里,它既不是严格意义上的一个汉字,也不一定等于一个英文单词,而是模型在内部切分文本后得到的一段段片段。
举个直观的例子:
所以,Token 更像是模型的“计算字节”。你给模型输入的内容,要先变成 Token;模型生成的回答,也会以 Token 的形式逐步输出。
这也是为什么大模型的价格表几乎都不是写“每千字多少钱”,而是写“每百万 Token 多少钱”。因为对模型厂商来说,真正稳定、可计算、可计费的单位是 Token,而不是自然语言里的“字”或“词”。
Token 不是字数,而是模型处理单位
这是最容易误解的一点。
很多人会下意识地认为:
但真实情况通常没有这么简单。
因为模型使用的是分词器(tokenizer)来切分内容,而不是按照自然语言语法来数数。于是:
所以,Token 更准确的理解方式不是“文字长度”,而是模型内部处理内容时的离散单位。
Token 数并不是只由“内容长度”决定,还和内容形态有关。
比如下面几类内容,通常都会让 Token 结构发生明显变化:
这也是为什么很多人实际使用时会发现:看起来字数不多,但账单并不低。因为模型看到的不是“字数”,而是经过切分后的 Token 序列。
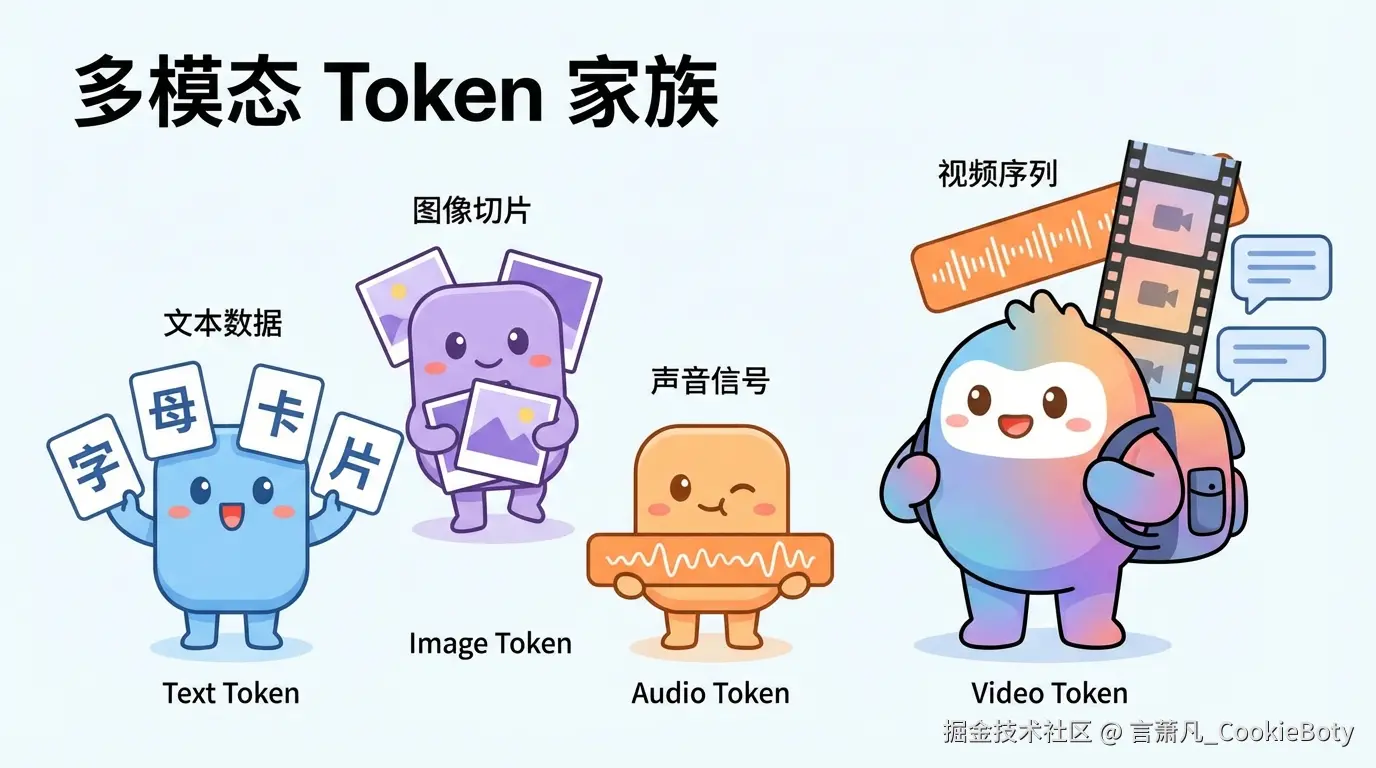
当模型进入多模态场景之后,Token 的概念并没有消失,只是它不再只对应“文本片段”。
更准确地说:多模态模型会把图片、音频、视频等输入,先转换成模型可以处理的内部表示,再映射到可计费的 Token 或 Token 等价单位。
因此,多模态里的 Token 可以粗略分成几类理解:
这里最关键的一点是:多模态并不是不按 Token 计费,而是把非文本信息也折算成了模型可处理的 Token 结构。
图片 Token 的计算方式,不同厂商差异很大,但底层思路通常相似:
先把图片标准化,再按视觉块(patch / tile / region)或分辨率等级折算成若干视觉 Token。
常见的影响因素包括:
所以在很多视觉模型里,并不存在一个简单通用的公式说“1 张图 = 固定多少 Token”。更常见的情况是:
low detail 和 high detail 模式下,Token 消耗可能差很多。也就是说,图片真正影响的不是‘张数’,而是图片经过模型预处理之后,需要多少视觉计算单元。
音频场景和图片类似,也不是简单按“文件个数”收费,而更接近按时间长度 × 编码粒度来折算。
常见逻辑是:
所以音频成本通常主要受这些因素影响:
很多时候你看到“语音模型更贵”或“实时语音特别耗费”,本质上并不是平台在乱加价,而是模型需要持续处理高密度时间序列数据。
视频往往是多模态里最复杂的一种,因为它通常不是单一输入,而是三部分叠加:
所以一个视频请求的消耗,很多时候可以近似理解为:
视频成本 ≈ 抽帧后的图像成本 + 音频成本 + 文本上下文成本
如果平台对视频做的是“定时抽帧”而不是逐帧分析,那么成本会和:
直接相关。
因此,视频不是“一个文件一次计费”这么简单,而是一个组合型的 Token 消耗体。
到了多模态阶段,Token 更不能简单横向比较了。原因在于:
所以,当你看多模态价格表时,最稳妥的理解方式不是强行追问“1 张图到底等于多少 Token”,而是先看厂商到底公布的是哪一种计费口径:
如果只想留下一句最实用的话,那么可以这样记:
文本模型里的 Token,是文本被切分后的处理单位;多模态模型里的 Token,则是文本、图像、音频、视频等信息被模型编码后形成的统一计算单位或等价计费单位。
所以,无论是纯文本还是多模态,厂商真正计费的都不是“你发了几句话、几张图、几个文件”,而是:模型为了理解这些输入、并生成输出,实际消耗了多少可计算的内部单位。
从厂商视角看,Token 是最适合做计费单位的,因为它直接对应了模型推理时的实际消耗。
一次调用模型,至少会发生两件事:
这两部分都会消耗算力,因此绝大多数模型厂商都会把账单拆成两类:
于是,最基础的计费逻辑就成立了:
Cost = 输入成本 + 输出成本
进一步写成标准公式,就是:
Cost = Tin / 1,000,000 × Pin + Tout / 1,000,000 × Pout
其中:
这就是大模型最原始、最通用的官方计费框架。
理解计费时,有三个结论必须先记住。
大多数厂商都会把输入价格和输出价格分开,而且输出往往比输入更贵。原因很简单:生成内容比单纯读取内容更消耗推理资源。
所以,同样是 1 万个 Token:
这也是为什么很多人会误以为“我明明只问了一个简单问题,为什么扣费不低”——因为真正贵的,可能不是你发出去的那段提示词,而是模型生成出来的大段回答。
不是说你只发了一条消息,费用就一定低;也不是说多轮对话就一定更贵。真正决定成本的,是每一轮累计消耗了多少 Token。
如果你的提示词很长、上下文很多、模型输出很长,那么哪怕只调用一次,也可能比多轮短对话更贵。
在多轮对话中,模型并不是“记住了你上一次说过的话”这么简单。更准确地说,系统通常会把前面的消息重新整理后再传给模型,于是这些历史内容也会继续占用输入 Token。
因此,对话越长,上下文越大,输入成本往往也会越来越高。这也是后面谈缓存和中转站时必须关注的前提。
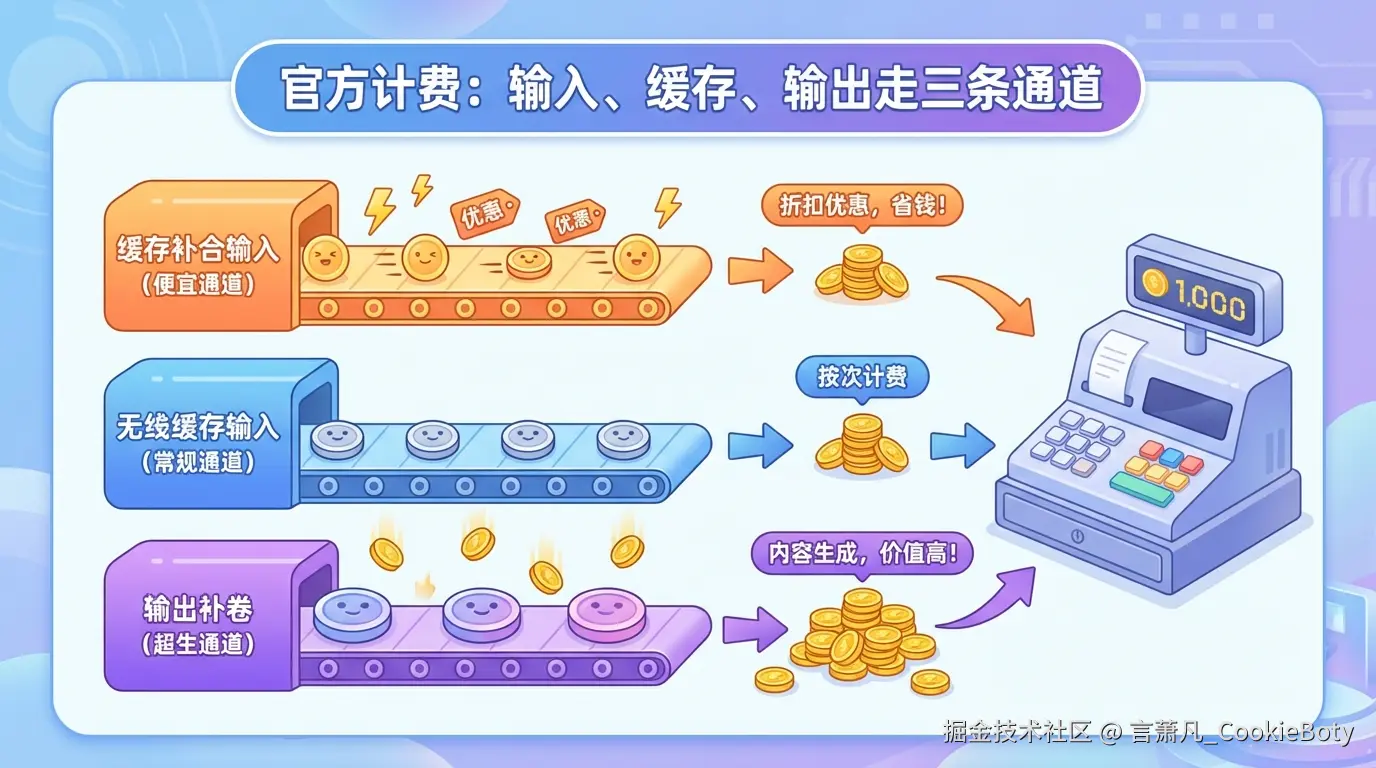
当模型厂商支持缓存之后,输入侧就不再只有一种价格了。
缓存的核心思路是:如果你每次请求里都有一大段重复的前缀内容,比如系统提示词、固定知识库上下文、工具定义、统一模板等,那么这些内容没必要每次都按完整成本重复处理。于是厂商会把其中命中的部分,按更低的价格计费。
这时,输入 Token 通常要拆成两部分:
对应的公式也会变成:
Cost = Tuncached / 1,000,000 × Pin
+ Tcached / 1,000,000 × Pcache
+ Tout / 1,000,000 × Pout
其中:
这里最重要的一点是:缓存优化的是输入侧成本,不是整次请求的全部成本。
也就是说:
所以,缓存命中不等于“这次调用几乎不要钱”,它只是让重复输入这部分更便宜了。
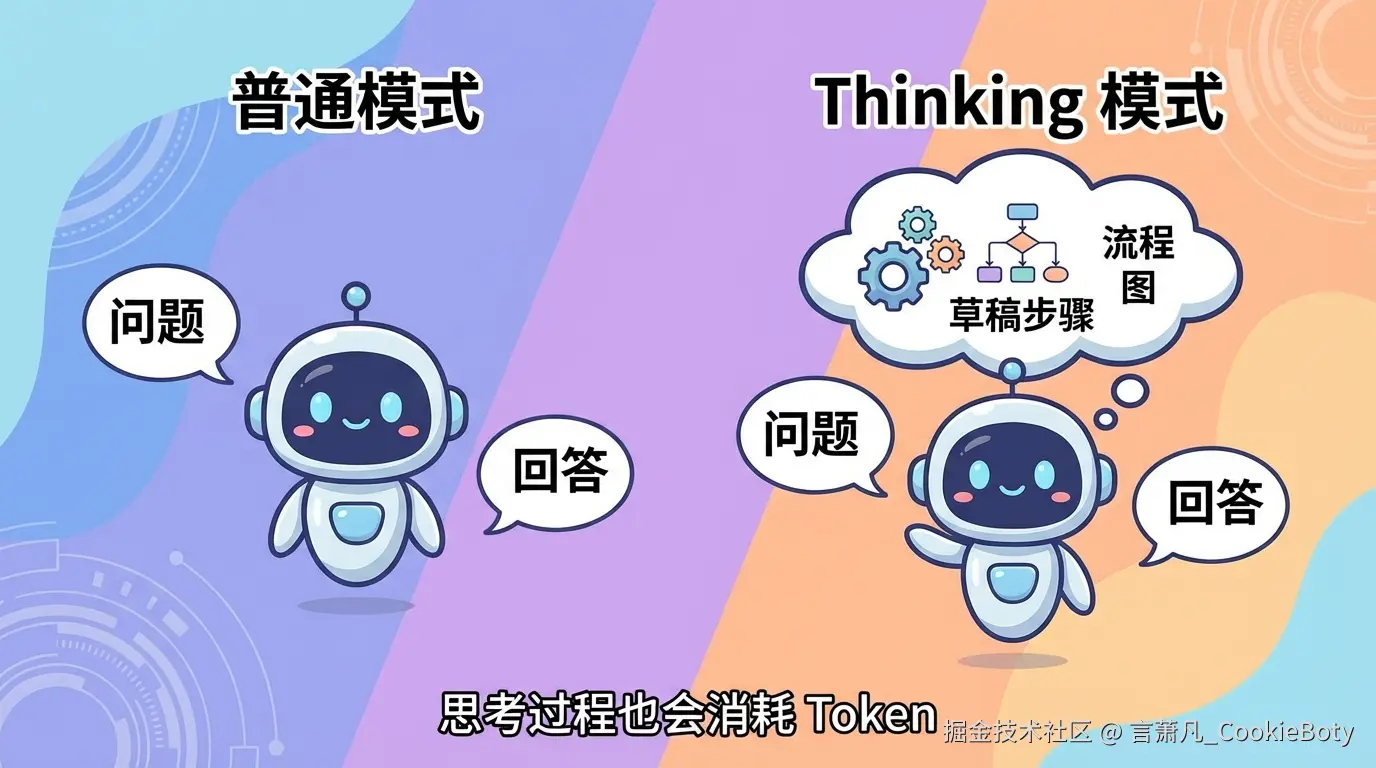
除了缓存,另一个经常让人困惑的变量,是 thinking / reasoning 模式。
它本质上意味着:模型在输出最终答案之前,可能会先生成一部分用于推理、规划、分析的中间 Token。这些 Token 有时对用户可见,有时部分可见,有时只体现在统计口径里,但它们通常都会带来额外成本。
因此,thinking 模式和普通模式的差别,可以先粗略理解为:
普通模式:
Cost_normal = 输入成本 + 输出成本 + 缓存相关成本
thinking 模式:
Cost_thinking = 输入成本 + 输出成本 + 缓存相关成本 + 思考 Token 成本
更直白地说,thinking 模式之所以更贵,往往不是因为“模型换了一套完全不同的收费体系”,而是因为它在原本的输入/输出结构之外,又额外产生了更多需要计费的 Token。
在实际产品里,这些思考 Token 往往更接近输出侧开销;而在多轮对话中,如果上一轮的思考内容被完整回传到下一轮,它又可能再次进入输入侧成本。
所以,thinking 模式的本质不是“神秘加价”,而是 Token 结构更复杂了。
到这里,其实可以先把官方计费逻辑浓缩成一句最实用的话:
大模型官方计费,本质上就是在计算三类东西:未缓存输入、缓存命中输入、输出;如果开启 thinking,再额外考虑思考 Token 带来的成本。
也就是说,官方世界关心的核心变量始终是:
只要这一层搞清楚,后面看中转站的“倍率”“点数”“配额”,就会顺很多。因为中转站并没有发明一套脱离官方规则的物理定律,它只是把这些官方成本,重新包装成了自己的结算体系。
讲完 Token 和官方计费,再来看“中转站”就容易多了。
所谓中转站,通常可以理解为:位于用户和上游模型厂商之间的一层聚合与转发服务。
它一般会做几类事情:
所以,中转站并不等于模型本身,它更像是一个“流量分发与结算层”。
从用户角度看,中转站的价值往往在于:
但也正因为它处于“中间层”,所以它展示出来的扣费方式,未必和上游厂商价格表一模一样。
很多人第一次看中转站面板时,最困惑的并不是价格本身,而是“倍率”这个概念。
因为在 OpenAI、Anthropic、Google 这类上游厂商的价格页里,更常见的是:
它们描述的,本质上都是每百万 Token 的官方单价。
而到了中转站里,界面语言往往会变成:
这说明一件事:倍率通常不是上游厂商的原生计费单位,而是中转站为了把官方成本折算成平台内部余额、点数或配额,而人为引入的一层结算抽象。
说得更直接一点:
官方世界在算货币成本,中转站世界在算平台额度;倍率,就是连接这两套计量体系的换算系数。
因此,中转站并不是创造了一套脱离官方价格的全新物理定律,而是把官方的输入、缓存输入、输出、thinking 成本,重新包装成了自己的扣费语言。
如果再往深一层看,所谓“倍率”,本质上是在回答下面这个问题:
同样消耗 1 个 Token,不同模型、不同渠道、不同用户组,应该从平台余额里扣掉多少“内部单位”?
于是,中转站通常不会直接把“美元价格”原样展示给用户,而是会先选定一个内部计费基准,再把不同成本映射进去。
你可以把它理解成下面这种抽象:
平台内部单价 = 官方单价 × 平台折算系数
如果进一步写成输入 / 输出分离的形式,就是:
内部输入单价 = 官方输入单价 × 折算系数
内部输出单价 = 官方输出单价 × 折算系数
但很多中转站并不直接展示“内部输入单价”和“内部输出单价”,而是把它继续拆成几个更方便运营配置的变量:
所以,倍率真正折算的并不是一个抽象标签,而是不同 Token 类型在平台内部的结算权重。
很多人看到某个平台的 GPT-4o 倍率是 10,另一个平台是 3,第一反应是“前者更贵”。但这其实未必成立。
因为倍率本身不是统一货币单位,它至少会受到四层因素共同影响。
同样是某个模型,平台接入的可能是:
这些渠道的真实成本、稳定性和可持续性都不一样,因此倍率自然不会一样。
有些平台卖的不只是“能不能调用”,还包括:
于是你看到某些模型后面带 -official、-fast、-stable 之类的标记,本质上往往是在告诉你:这不仅是模型名差异,更是服务等级差异。 服务质量越高,倍率通常也越高。
中转站不是单纯的“成本搬运工”,它还会做运营策略:
因此,倍率里通常不只有“技术成本”,还包含平台自己的商业策略。
如果平台是r民币充值、美元成本,那么它还要处理:
这就是为什么有些平台会出现一种表面上看起来很奇怪的现象:
充值 1 元,却给你记 1 美元口径的余额;为了把这个差额补回来,就会把模型倍率整体抬高。
所以,倍率不是纯技术参数,而是“上游成本 + 服务质量 + 运营策略 + 货币体系”共同叠加后的结果。
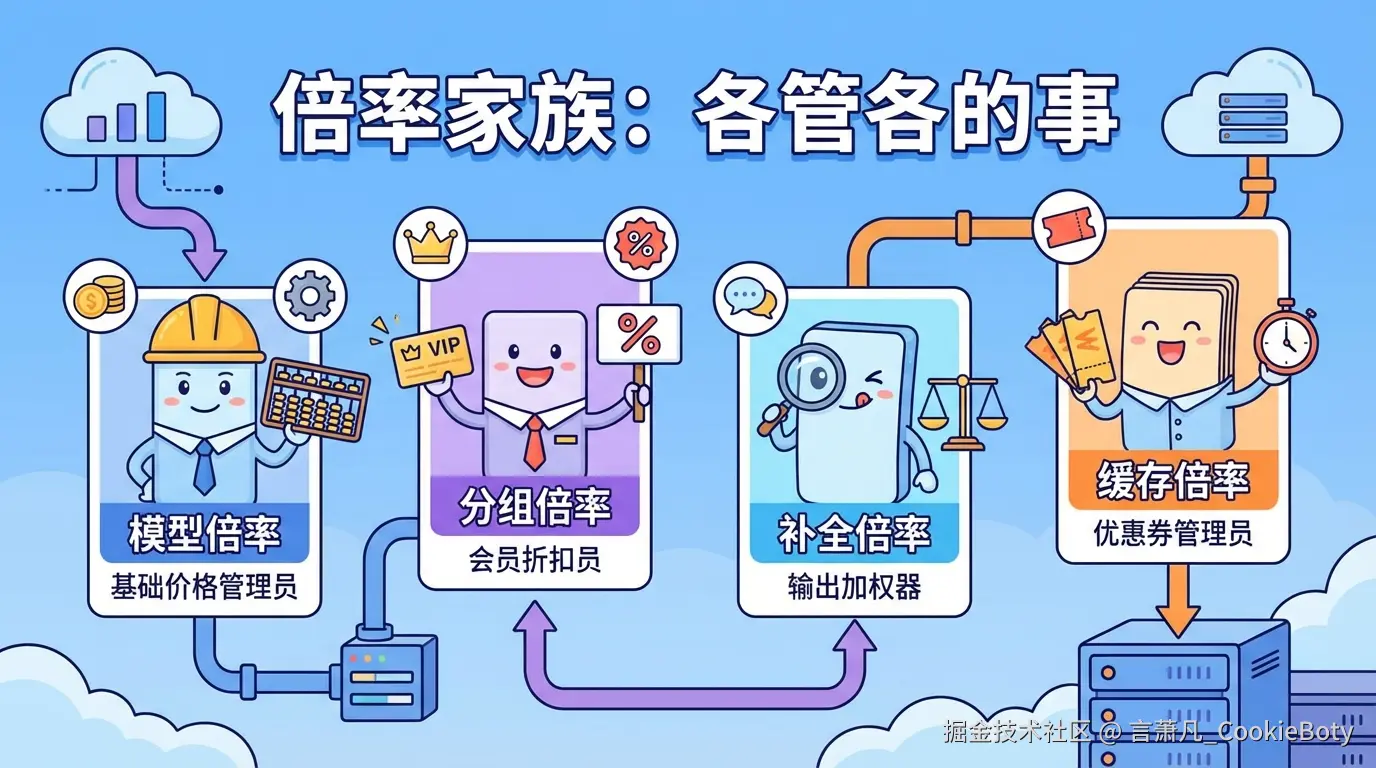
这一节最容易混淆的地方在于:补全倍率、缓存倍率,和分组倍率并不是同一个层级的概念。
很多中转站会把这些词都统一写成“倍率”,再配合站内余额、点数、额度这些内部单位一起展示,于是用户很容易误以为:它们全都是平台自己发明出来的收费规则。
但更准确地说,这里至少要分成两层:
也就是说,补全和缓存首先是上游模型本身就存在的计费方式;而分组倍率,才是平台为了统一调价而额外叠加的一层运营参数。
先把最底层说清楚。
对绝大多数主流大模型来说,官方计费本来就会区分:
所以,很多中转站面板里所谓的“补全倍率”“缓存倍率”,本质上并不是平台凭空创造出来的新概念,而是在映射上游 input / output / cache 的价格差异。
换句话说:
在绝大多数模型里,缓存命中通常大约按普通输入价格的 1/10 结算;但也有少数模型会进一步细分成:
因此,如果一个中转站把“补全倍率”“缓存倍率”单独拿出来强调,很多时候它讲的并不是站内独创规则,而只是把上游大模型原本就有的计费结构,用站内配额语言重新包装了一遍。
真正进入中转站自己的体系后,才会出现“模型倍率”这类平台侧参数。
模型倍率决定的是:同样一组 input / output / cache 消耗,在这个站里最终按多高的站内权重结算。
它本质上承接的是:
这也是为什么很多中转站会先把站内金额单位调大,再在倍率层面做文章。表面上看倍率很多、结构很复杂,但其中有一部分其实只是把上游官方成本重新折算成站内内部单位。
所以,模型倍率更接近平台折算系数,而不是上游模型的原生价格字段。
分组倍率的定位要单独拎出来,因为它和补全、缓存不是一个概念。
分组倍率决定的是:平台要不要对某一组用户、某一类套餐、某一个渠道分组做统一加价或打折。
例如:
这类倍率并不对应 input、output 或 cache 的物理成本差异,而是平台运营层面对一整组流量做统一调整。
所以它的本质不是“模型怎么收费”,而是:平台准备让哪一组用户按什么系数结算。
如果把这些概念放在一起看,更准确的理解顺序应该是:
一句话总结就是:
有了上面的定义后,就可以把中转站的扣费逻辑写得更完整。
如果先不考虑缓存和 thinking,只保留最常见的输入/输出结构,那么可以写成:
Quota_basic = (Tin + Tout × Rout) × Rmodel × Rgroup
其中:
这正对应很多 OneAPI / NewAPI 系统里最常见的基础扣费表达。
如果平台支持缓存命中折算,那么更准确的形式应该写成:
Quota_cache = (Tuncached + Tcached × Rcache + Tout × Rout) × Rmodel × Rgroup
其中:
这条公式比“输入 + 输出 × 补全倍率”更完整,因为它能解释:为什么同样是 10 万输入 Token,有的人扣得很多,有的人扣得很少——差别往往就在缓存命中率。
如果模型开启了 thinking / reasoning,那么输出侧通常还会多出一部分推理 Token,于是可以进一步写成:
Quota_thinking = (Tuncached + Tcached × Rcache + (Tvisible + Tthink) × Rout) × Rmodel × Rgroup
其中:
这条式子能够解释一个很常见的现象:
为什么有些问题看起来不复杂,但一开 reasoning,平台消耗会立刻明显上升。
因为从平台视角看,它并不关心这些 Token 是“用户看见的回答”还是“模型内部思考过程”,只要上游按 Token 收费,平台就必须把它折算进去。
这一点其实是中转站里最容易踩坑的地方。
很多用户会把不同平台的倍率数字直接横向比较,比如:
于是就得出“B 站贵了 10 倍”的结论。
但这个结论常常并不成立,因为你忽略了另一个变量:平台余额单位本身是什么。
真正应该比较的,不是“倍率的绝对值”,而是单位 Token 最终折合成了多少真实货币成本。
可以把它抽象成:
实际输入单价 ≈ 余额单位价值 × Rmodel × Rgroup
实际输出单价 ≈ 余额单位价值 × Rout × Rmodel × Rgroup
如果再把充值口径算进去,那么跨平台比较时,更接近现实的判断方式是:
实际r民币成本 ≈ 充值回了 × 平台倍率体系 × Token 消耗结构
这也就是为什么会出现这样一种情况:
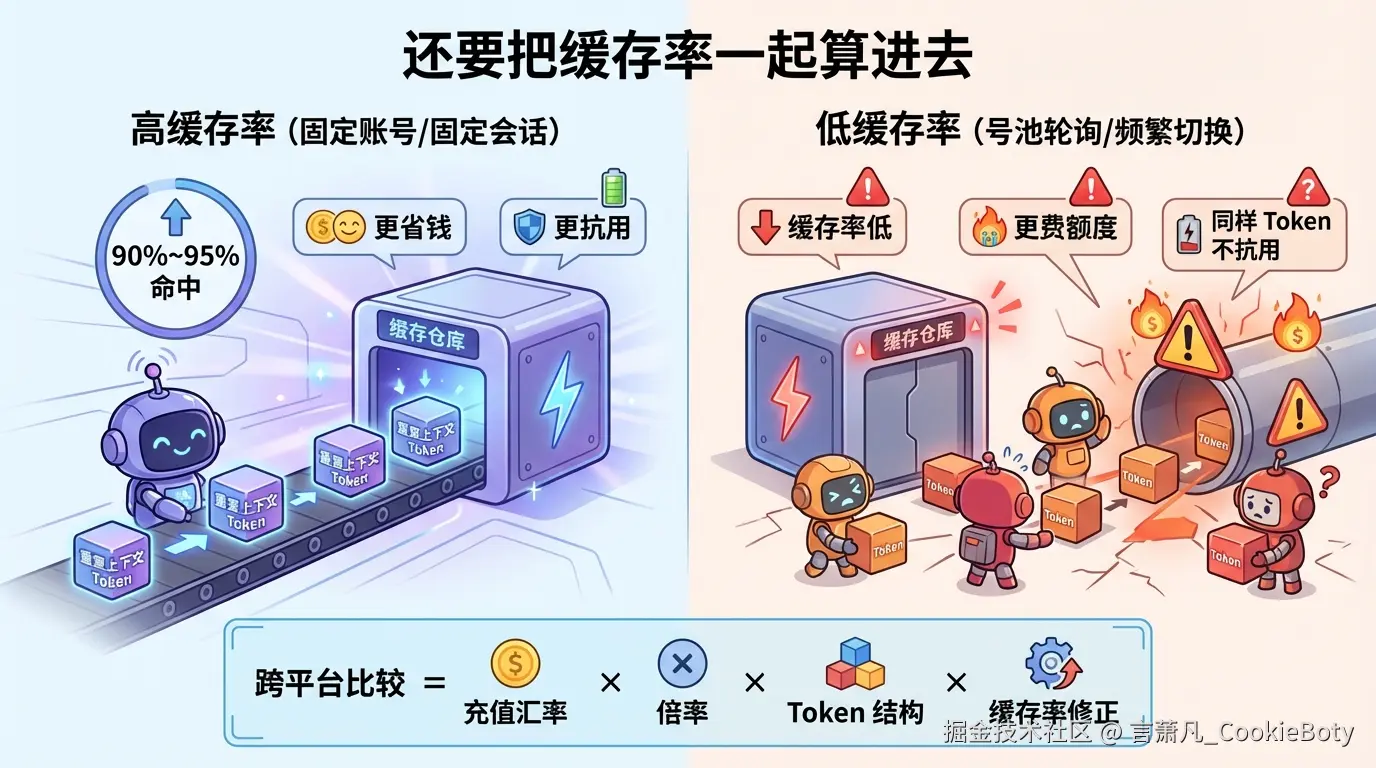
很多人在跨平台比较价格时,还会漏掉一个非常关键的变量:缓存率(或缓存命中率)。
因为平台展示给你的往往只是:
但你真正“花出去”的有效成本,还取决于请求里有多少输入命中了缓存。
在编程场景里,如果是固定账号持续使用,例如自己用 Max 或稳定拼车,常见会出现 90% ~ 95% 的输入 Token 走缓存。换句话说,缓存 Token 数可能达到写入 Token 数的 10 ~ 20 倍。这时,实际费用往往不会等于“全部按普通输入 Token 原价结算”,而更接近 按标称 Token 价格的 80% ~ 85% 来理解。
反过来说,如果某个中转站表面倍率不高、兑换比例也不差,但因为号池轮询、账号频繁切换或缓存技术做得一般,导致你的缓存率明显偏低,那么你的实际单位成本就会上升。于是就会出现一种常见感受:
不是平台给的 Token 数是假的,而是因为缓存率低,同样的 Token 更“不抗用”。
从实践上看,可以把常见模式粗略分成三类:
所以,跨平台比较时,更接近真实的判断方式应该是:
实际r民币成本 ≈ 充值回了 × 平台倍率体系 × Token 消耗结构 × 缓存率修正
或者换句话说:
比较价格,不能只看“¥多少 = $1” 或倍率数字,还要看这个平台能不能把你的高重复上下文真正缓存住。
所以,倍率只能在同一平台内部比较模型相对贵贱,不能脱离充值规则和缓存率去跨平台直接比较。
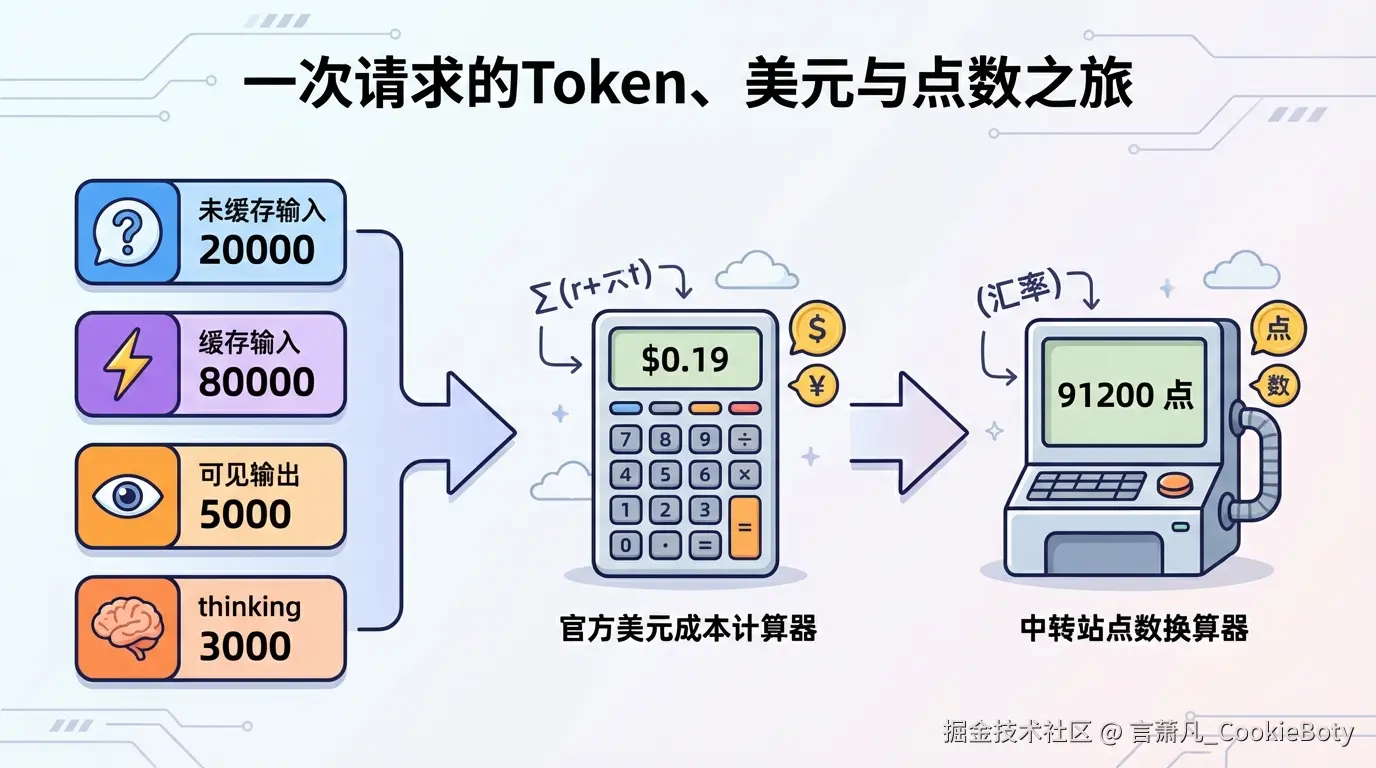
假设某次请求中:
再假设上游官方价格是:
那么按官方计费估算:
Cost = 20000/1,000,000 × 2.50
+ 80000/1,000,000 × 0.25
+ (5000 + 3000)/1,000,000 × 15
计算后得到:
Cost = 0.05 + 0.02 + 0.12 = 0.19 美元
现在假设某个中转站进一步定义:
那么它的配额消耗就可能写成:
Quota = (20000 + 80000 × 0.1 + (5000 + 3000) × 6) × 1.2
= (20000 + 8000 + 48000) × 1.2
= 76000 × 1.2
= 91200
这时你在平台面板里看到的,可能就不是“0.19 美元”,而是“扣除了 91200 点额度”。
单位虽然变了,但底层逻辑没有变:
如果把“怎么理解倍率”进一步落到实践层面,那么判断一个平台是否靠谱,至少要看三件事。
一个靠谱的平台,哪怕不用“美元单价”直接展示,也至少应该能让你看出:
如果这些都说不清,只给一个笼统倍率数字,那透明度通常不够。
正规的中转站,通常会公开:
如果平台只有一个模糊的“倍率很低”,却没有明细页、模型页或计费页,那么风险通常更高。
如果某个平台价格长期明显低于官方理论成本,就要提高警惕。因为这往往意味着它可能依赖:
这种平台也许适合测试或体验,但未必适合生产环境。
为了避免混淆,最后把几个最常见的误区集中说清楚。
缓存只会降低命中的输入部分,不会把未命中的输入和输出一起变便宜。真正昂贵的部分,很多时候依然是输出和 reasoning。
它通常对应的是官方“输出比输入更贵”的现实,只不过平台把这种差异,用一个更容易运营配置的比例表达出来。
thinking 本质上仍然是 Token 消耗,只不过这些 Token 来自模型的推理过程,因此会额外抬高输出侧成本。
也可能是渠道不同、QoS 不同、回了不同、补贴策略不同。倍率差异本身并不自动等于平台不正规。
跨平台比较时,真正重要的是“最终单位 Token 折合多少钱”,而不是后台写了一个多大的倍率数字。
如果你只想留下最有用的结论,那么记住下面四条就够了。
Cost_normal = 未缓存输入 / 1,000,000 × 输入单价
+ 缓存命中输入 / 1,000,000 × 缓存单价
+ 可见输出 / 1,000,000 × 输出单价
Cost_thinking = 未缓存输入 / 1,000,000 × 输入单价
+ 缓存命中输入 / 1,000,000 × 缓存单价
+ (可见输出 + 思考 Token) / 1,000,000 × 输出单价
Quota_basic = (输入 Token + 输出 Token × 补全倍率)
× 模型倍率 × 分组倍率
Quota_full = (未缓存输入 + 缓存输入 × 缓存倍率 + (可见输出 + 思考 Token) × 输出倍率)
× 模型倍率 × 分组倍率
这四条公式,基本就能把“官方怎么计费”和“中转站为什么这么扣费”完整串起来。
整件事最值得记住的,其实就是一句话:
官方计费看的是 Token 结构——输入、缓存输入、输出,以及 thinking 带来的额外 Token;中转站做的,则是在这套结构之上,再叠加模型倍率、补全倍率、分组倍率和缓存倍率,把官方成本映射成自己的余额与配额规则。
所以,理解大模型计费最好的路径永远是:先理解 Token,再理解官方价格,再理解中转站倍率。顺序一旦反过来,很多概念就很容易越看越乱。

