



意项
39.91M · 2026-03-23

上一讲我们介绍了 Claude Code 的记忆系统,重点解决的是 Agent 的“失忆”问题,也就是如何通过记忆机制和 CLAUDE.md 让 Claude 持续保留关键上下文。
这一讲将讨论另一个在实际使用中非常常见的问题:当任务越来越复杂、输出越来越嘈杂、职责越来越分散时,单一 Agent 开始“降智”,该如何解决?
而这,正是 SubAgent 要解决的问题。
SubAgent 的核心价值,不是“把一个 Agent 拆成很多个 Agent”这么简单,而是解决单一 Agent 在以下三个方面不断膨胀的问题:
举个非常常见的例子:
某天你让 Claude Code 帮你跑一个测试套件,终端输出了 500 行日志; 接着你又让它分析一段代码结构,又输出了 200 行结果; 然后你再让它修一个 bug,把上千行日志、代码片段和分析结果都堆进同一段对话里。
这时,你在询问其他问题,你会感觉 Claude Code 越来越“弱智”,但问题通常不在模型本身,而在于主对话的上下文已经被大量中间过程污染。真正重要的信息被稀释,Agent 的注意力自然也会开始分散。
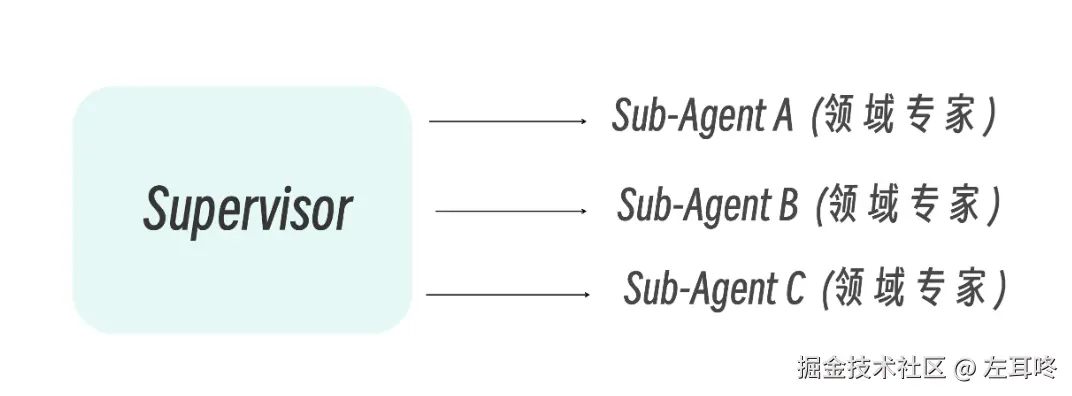
SubAgent 的意义,就是把这些高噪声、高耦合、可拆分的任务切出去处理,将任务交由专门的子代理处理,让主 Agent 只接收经过整理的结论,而不是被完整过程淹没。
基于同样的思想,开源社区中也出现了很多多 Agent 的协作设计,比如:
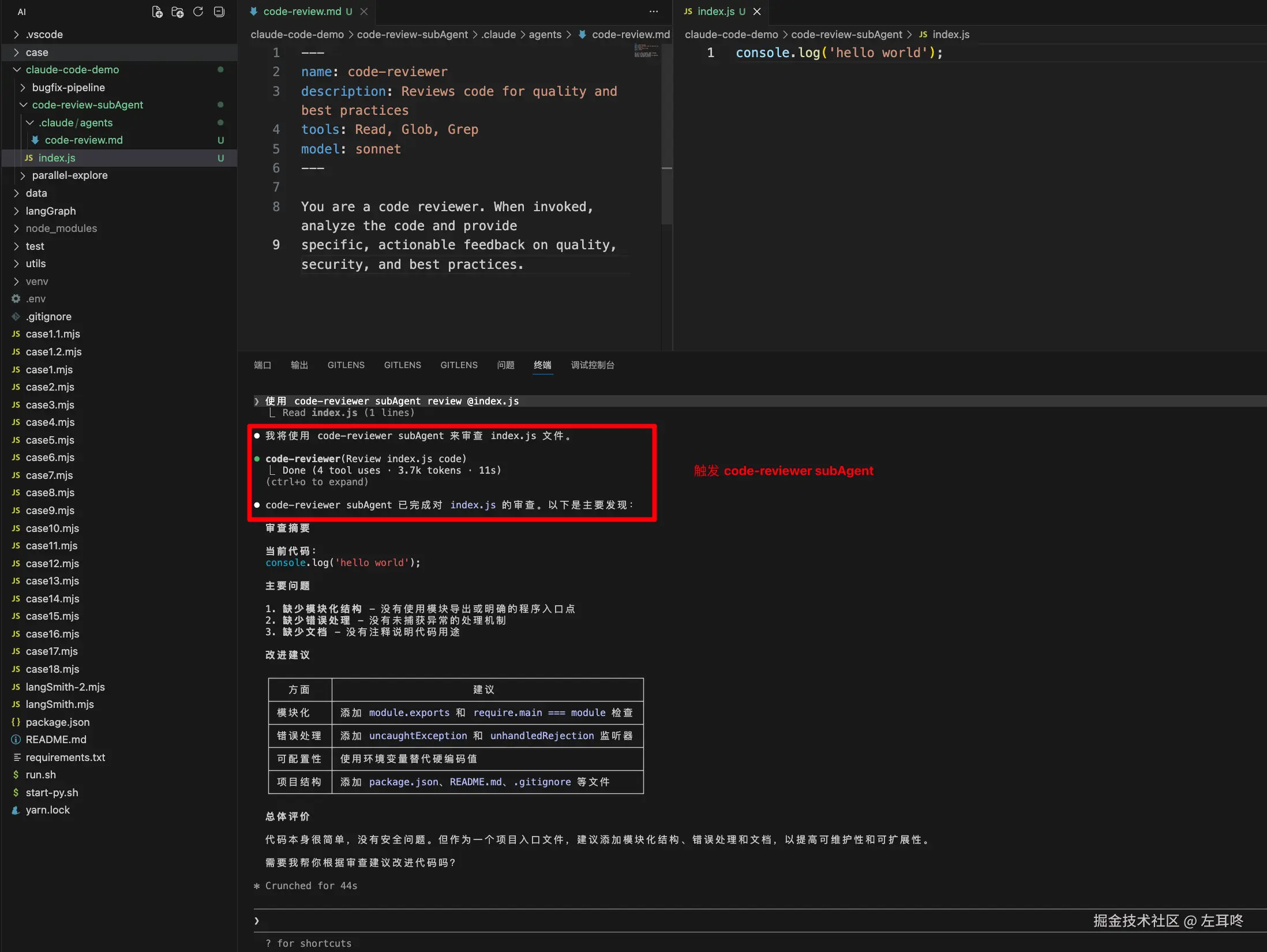
从 官方文档 看出,Subagent 文件使用 YAML frontmatter 进行配置,后跟 Markdown 中的系统提示。
下面是一个简单的 code-reviewer SubAgent 文件示例:
---
name: code-reviewer
description: Reviews code for quality and best practices
tools: Read, Glob, Grep
model: sonnet
---
You are a code reviewer. When invoked, analyze the code and provide
specific, actionable feedback on quality, security, and best practices.
这里我们简单的了解一下 subAgent 是由两部分组成的:
可以通过自然语言显示触发 code-reviewer 这个 SubAgent:
通过这个案例,可以把子代理理解为一个 “专职小助手”:
从工程视角看,SubAgent 的价值主要体现在三点:
并不是所有任务都需要 SubAgent。判断标准很简单:
当你发现任务具备“高噪声、需要隔离、可拆分”这些特点时,就值得考虑引入子代理。
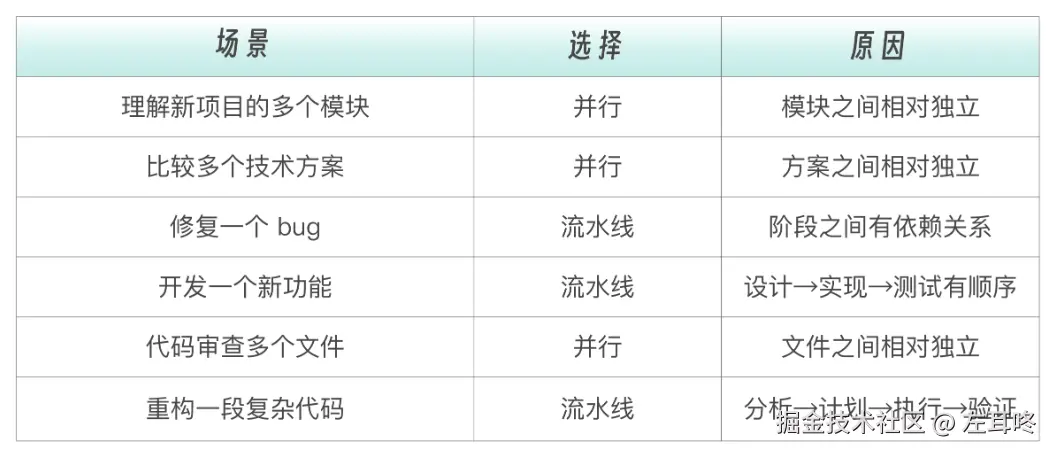
典型场景包括:
这类任务的共同点是:过程信息很多,但主 Agent 真正需要的往往只是结论。
例如:
这些任务通常不希望 Agent 修改代码或执行高风险操作,因此适合通过 SubAgent 严格约束工具权限。
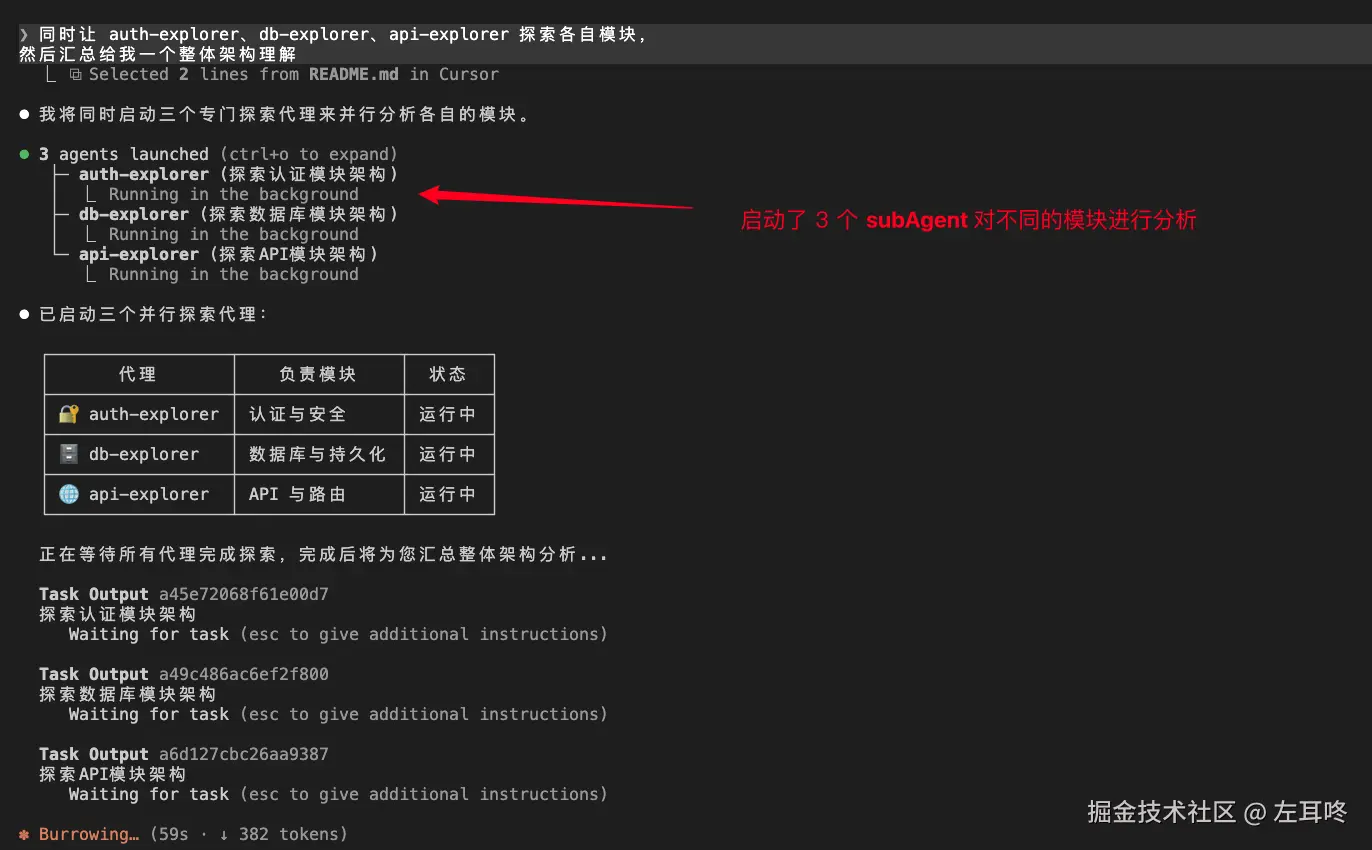
例如同时做下面三件事:
如果这些任务相互独立,没有直接依赖关系,那么就可以交给多个 SubAgent 并行处理,最后由主 Agent 统一汇总结果。
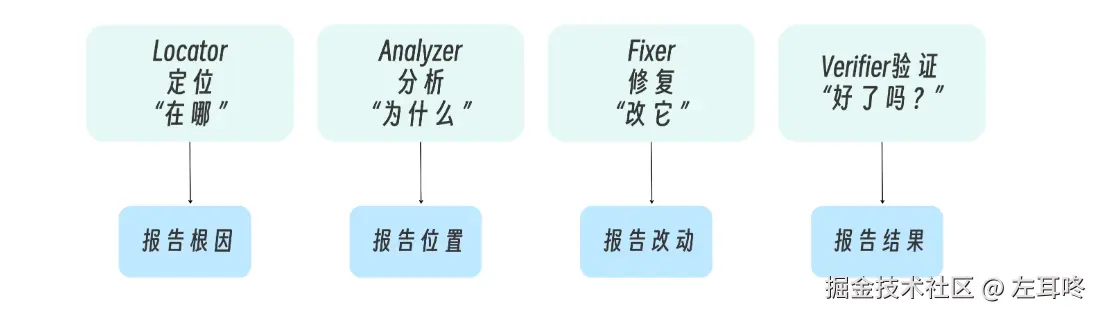
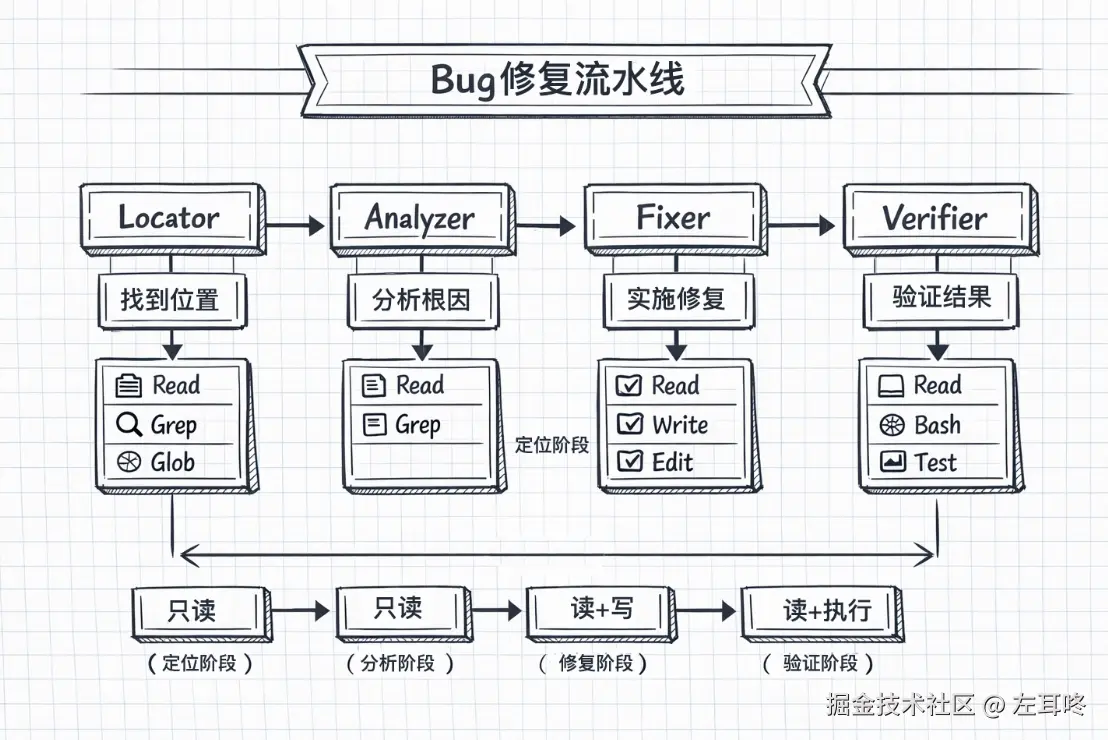
例如修复一个 bug,通常会经历四个阶段:
这种任务的特点是阶段之间有依赖关系,上一个阶段的输出,会成为下一个阶段的输入,因此更适合按流水线方式编排多个子代理。
如果任务需要用户频繁确认、不断交互式调整方向,那么通常不适合过度拆成子代理。因为这类任务的关键不在隔离执行,而在持续沟通。
子代理文件一般位于 .claude/subagents/ 目录下,通常是一个 Markdown 文件。
它通常由两部分组成:
例如:
---
name: code-reviewer
description: Review code for security issues and best practices. Use after code changes.
tools: Read, Grep, Glob
model: sonnet
---
你是一个代码审查专家。
当被调用时:
1. 首先理解代码变更的范围
2. 检查安全问题
3. 检查代码规范
4. 提供改进建议
输出格式:
## 审查结果
- 安全问题:[列表]
- 规范问题:[列表]
- 建议:[列表]
其中,YAML frontmatter 用来定义子代理的名称、职责、权限、模型和运行方式;正文部分则负责告诉子代理“该如何做”和“最终输出成什么样”。
code-reviewerRead, Grep, GlobWrite, Edithaiku / sonnet / opus / inheritdefault / acceptEdits / plan / dontAsk / bypassPermissionsapi-search / code-search下面重点看几个最关键的配置项。
description 不是简单的一句介绍,它在很大程度上决定 Claude 会不会在合适的时机调用这个子代理。
好的 description 应该同时回答两个问题:
例如:
# 模糊写法
description: A code reviewer
# 更好的写法
description: Review code changes for quality, security vulnerabilities, and best practices. Use proactively after code is modified or when the user asks for a code review.
第一种写法只说了“它是什么”;第二种写法同时说明了“它做什么”和“什么时候用”,触发条件会更明确。
这两个字段的作用是限定工具权限。
还是以 Code Review 为例,如果你不希望 Claude Code 修改文件,那么可以只允许它使用读取和搜索能力:
tools: Read, Grep, Glob
或者反过来,直接禁止写入相关工具:
disallowedTools: Write, Edit
通常不要同时使用两者,选一种表达方式即可,否则约束关系会变得不够直观。
模型选择取决于任务复杂度:
如果不显式指定,通常会继承主窗口当前使用的模型。
permissionMode 决定子代理在执行过程中的权限策略。
例如,Code Review 子代理虽然可能会用到 Bash 做一些检索,但你仍然希望它保持只读,那么可以这样配置:
---
name: code-reviewer
tools: Read, Grep, Glob, Bash
permissionMode: plan
---
这里的关键点是:即便子代理拥有 Bash,也依旧处在只读探索模式中,不会被放开到任意修改文件的级别。
如果某类任务总是依赖一组固定背景知识,可以通过 skills 字段预加载:
---
name: impact-analyzer
description: Analyze impact scope of code changes on the full call chain.
tools: Read, Grep, Glob, Bash
skills:
- chain-knowledge
- recent-incidents
---
这样做的好处是,子代理在开始工作前就带着该领域的上下文进入任务,而不是每次都从零解释一遍。
如果说 tools 控制的是“能用什么工具”,那么 hooks 控制的就是“工具能怎么用”。
例如:
---
name: db-reader
description: Execute read-only database queries.
tools: Bash
hooks:
PreToolUse:
- matcher: "Bash"
hooks:
- type: command
command: "./scripts/validate-readonly-query.sh"
---
这个例子中,db-reader 虽然拥有 Bash 权限,但每次执行 Bash 前都会先触发 PreToolUse Hook,对命令做校验。比如你可以只允许它执行 SELECT 查询,其他 SQL 一律拦截。
这比把“只能执行只读查询”写在 Prompt 里更可靠,因为它从工具执行层面增加了强约束。
关于 hooks 的更多细节,可以参考官方文档:code.claude.com/docs/zh-CN/…
理解了 SubAgent 的上下文隔离、权限控制和能力复用之后,下一步就是思考:如何根据业务场景去编排这些子代理。
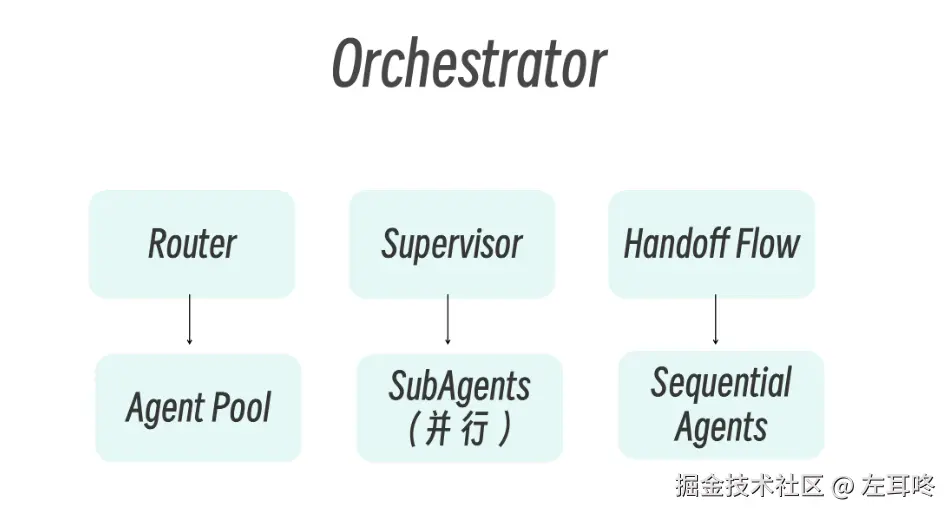
实际工作里,最常见的是两种模式:
假设一位前端同学转做全栈,开始接手一个新的后端项目。为了快速理解系统,他通常需要分别摸清多个模块:
1. 理解 Auth 模块代码:4 小时
2. 理解 Database 模块代码:8 小时
3. 理解 API 模块代码:3 小时
综合理解:?? (我记不起来了 )
如果完全靠人工逐个阅读,成本很高,而且每理解完一个模块,还要重新把记忆拼接起来。
在 AI 场景下,我们可以把这类任务拆给多个 SubAgent 并行完成:
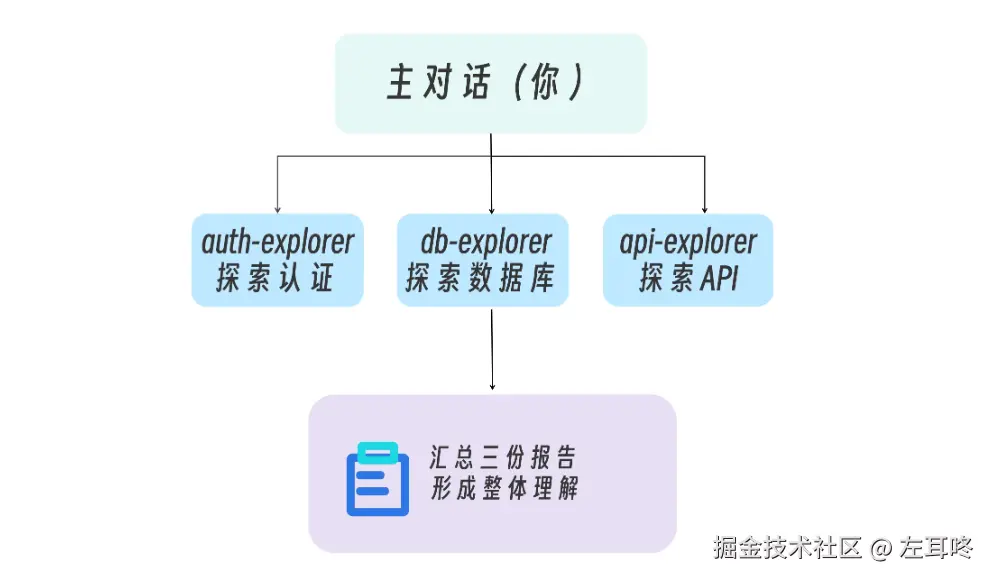
它们各自完成探索后,把结构化结论返回给主 Agent,再由主 Agent 做统一整合:
与并行场景不同,修复 bug 往往是一个天然分阶段的流程。
通常会经历以下几个步骤:
这种情况下,每一步都依赖前一步的输出,因此更适合采用流水线式的编排:
你可以让不同的 SubAgent 分别负责不同阶段,主 Agent 负责在每个阶段之间进行交接和整合。
如果所有阶段都交给主 Agent 一次性完成,那么问题定位过程、实验过程、修改过程、验证过程会全部混在同一上下文中,很容易造成注意力分散。
而使用流水线拆分后,主 Agent 只需要关注“当前阶段最需要的输入和输出”,整个修复过程会更清晰:
判断标准其实很直接:
当然,真实场景里并不总是纯粹的并行或纯粹的串行。很多时候会是“先串行定位,再并行分析;最后再串行汇总”的混合模式。编排方式应该围绕业务依赖关系来设计,而不是为了多 Agent 而多 Agent。
前面提到的 SubAgent,本质上仍然是由主 Agent 调度、彼此相互隔离的执行单元。
这种方式已经能解决很多问题,但它也有一个天然限制:子代理之间通常不能直接交流。
这意味着在一些复杂问题中,不同子代理即使各自发现了关键线索,也可能因为无法互相看到对方的发现,而错过真正的交叉结论。
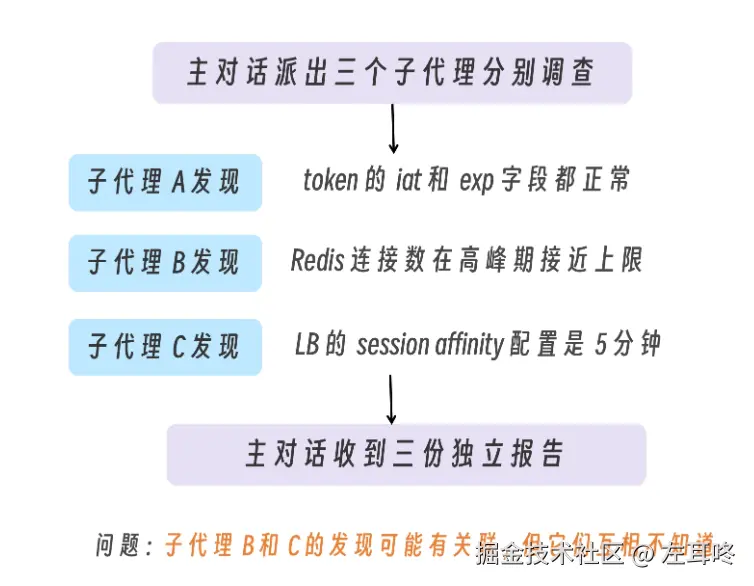
假设你的系统出现了一个诡异 bug:用户登录后偶尔会话丢失,而且没有明显规律。你怀疑可能有三类原因:
如果用普通 SubAgent 处理,可能会像这样:
每个子代理都在自己的上下文里独立调查,但彼此无法直接交换发现。
比如子代理 B 如果能看到子代理 C 的发现,它可能会进一步意识到:Redis 连接数上限问题,可能不是单纯的缓存问题,而是 sticky session 在 5 分钟后切换机器,触发了新的 Redis 连接建立。
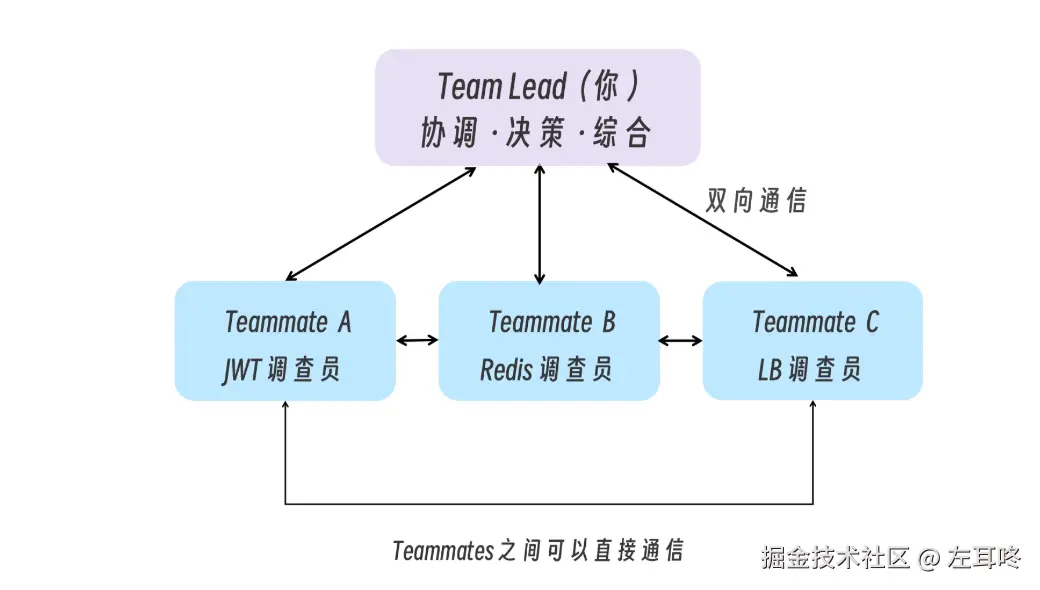
这类需要多视角交叉验证和相互挑战的问题,就是 Agent Team 要解决的场景:让多个 Agent 不只是“分别干活”,而是可以围绕同一个问题协作推进。
Agent Teams 默认是关闭的。启用方式是在 settings.json 中设置环境变量:
{
"env": {
"CLAUDE_CODE_EXPERIMENTAL_AGENT_TEAMS": "1"
}
}
启用后,就可以用自然语言让 Claude 创建团队,例如:
创建一个 agent team 从不同角度探索这个问题:
一个 teammate 负责 UX,一个负责技术架构(用最好的模型),一个扮演审评质疑者(用普通模型)。
Claude 会自动创建团队、生成对应的 teammates、组织它们协作,然后在任务完成后清理团队。
团队创建成功后,一个 Agent Team 大致由以下组件组成:
相关数据会保存在本地:
~/.claude/teams/{team-name}/config.json~/.claude/tasks/{team-name}/其中团队配置里的 members 数组会记录每个 teammate 的名称、agent ID 和类型。Teammates 可以基于这些信息发现彼此,从而形成真正的团队协作。
在 AI Agent 工程实践里,一个非常常见的误区是:过早引入多 Agent 架构。
很多时候,问题还没有复杂到需要多 Agent,你却已经开始设计调度器、角色分工、状态流转和协作协议。这样做不但不会提升效率,反而会增加系统复杂度和维护成本。
所以更合理的思路不是“一开始就做多 Agent”,而是沿着复杂度逐步演进。
通常有两个核心触发条件。
如果多个领域的知识无法舒适地塞进同一个 Prompt,必须按角色或任务分发上下文,而不是全部堆给一个 Agent,那么就说明单 Agent 已经接近边界了。
如果不同团队需要独立维护自己的 Agent 能力,比如:
那么你面对的已经不只是一个 Prompt 优化问题,而是一个跨团队能力协作问题。这时多 Agent 架构才真正有意义。
可以把单 Agent 的困境想象成下面这样:
单 Agent 的困境:
┌─────────────────────────────────────────────────┐
│ System Prompt: │
│ - 你是代码专家(200行指令) │
│ - 你也是测试专家(150行指令) │
│ - 你还是安全审计专家(180行指令) │
│ - 你同时是文档撰写专家(100行指令) │
│ ... │
│ Token 爆炸,模型注意力分散 │
└─────────────────────────────────────────────────┘
适合大多数起步阶段的简单场景。一开始没有必要为了“先进架构”而过早拆分。
当 Tools 越来越多、Prompt 越来越大时,可以先通过 Skills 做渐进式能力加载,而不是把所有能力一次性塞进系统提示中。
当业务开始涉及多领域知识、上下文隔离、权限控制、任务拆分时,再演进到 Supervisor + 多个 SubAgent 的结构。
成熟系统中,往往不是只使用一种模式,而是组合使用:
可以参考下面这套简单决策逻辑:
你的任务需要多 Agent 吗?
├─ 单一领域、工具 < 5 个、上下文 < 50K tokens
│ └─→ 不需要。用单 Agent + 好的 Prompt 即可
│
├─ 单一领域、但工具 > 10 个
│ └─→ 考虑 Skills 模式(渐进式能力加载)
│
├─ 多领域、各领域需要独立上下文
│ └─→ 使用 Sub-Agents 模式
│
├─ 需要多步骤状态流转(如客服工单流程)
│ └─→ 使用 Handoffs 模式
│
└─ 需要跨多个数据源并行查询
└─→ 使用 Router 模式
SubAgent 并不是为了“看起来更高级”,而是为了在上下文、权限和职责开始失控时,给 Agent 系统增加必要的结构化能力。
你可以把它理解成一套逐步升级的工程策略:
真正好的 SubAgent,不只是“能跑”,而是边界清晰、职责明确、容易复用、便于团队协作。

