

彩虹朋友拳击乱斗
68.23M · 2026-03-22

ArrayList 的所有方法都没有进行同步控制,多个线程同时添加、删除、修改同一个 ArrayList 实例时,会导致:
ArrayIndexOutOfBoundsException。List<Integer> list = new ArrayList<>();
ExecutorService executor = Executors.newFixedThreadPool(10);
for (int i = 0; i < 1000; i++) {
executor.submit(() -> list.add(1));
}
executor.shutdown();
// 结果:可能抛出异常,或最终 size 不等于 1000
ArrayList 是线程不安全的,根本原因在于其内部实现没有对共享数据的并发访问进行任何同步控制,导致多线程同时修改时会出现数据竞争。
ArrayList 底层是一个 Object 数组(elementData)和一个 int 类型的 size 字段,用于记录实际元素个数:
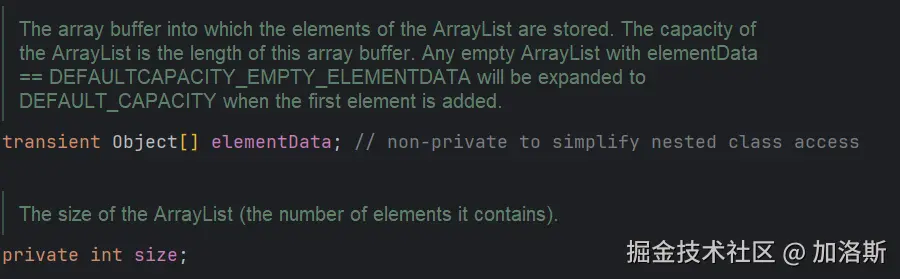
add、remove都会直接操作这个数组和 size。
假设两个线程同时执行 list.add(e),该方法大致步骤如下:
public boolean add(E e) {
ensureCapacityInternal(size + 1); // 检查是否需要扩容
elementData[size++] = e; // 插入元素并 size 自增
return true;
}
ensureCapacityInternal(size + 1) 会读取当前 size,判断数组是否已满。更常见的情况是:两个线程在扩容后都准备插入元素:
elementData[size] = e 时,size 还是旧值(比如 5);ArrayIndexOutOfBoundsException。size++ 实际上分为三步:读取 size → 加 1 → 写回 size。多线程环境下,这些步骤可能交错执行,导致:
size 值小于实际元素个数,或数组中有空位(null),后续操作可能出现问题。我们看一段如下的java代码
/**
* 演示 ArrayList 多线程并发问题
*/
@Test
public void testArrayListConcurrencyIssue() throws InterruptedException {
List<Integer> list = new ArrayList<>();
int threadCount = 5;
CountDownLatch latch = new CountDownLatch(threadCount);
// 创建 5 个线程,每个线程添加 1000 个元素
for (int i = 0; i < threadCount; i++) {
final int threadId = i;
new Thread(() -> {
try {
for (int j = 0; j < 1000; j++) {
list.add(threadId * 1000 + j);
}
} catch (Exception e) {
System.err.println("线程异常:" + e);
} finally {
latch.countDown();
}
}).start();
}
latch.await();
System.out.println("预期大小:" + (threadCount * 1000));
System.out.println("实际大小:" + list.size());
System.out.println("丢失元素:" + (threadCount * 1000 - list.size()));
if (list.size() < threadCount * 1000) {
System.out.println(" 检测到线程安全问题:数据丢失!");
}
}
其运行结果如下:
关于ArrayList多线程并发解决方案还是很多的,但是各有优缺点,我们来一个一个介绍。
它是将普通 ArrayList 转换为线程安全版本最直接的手段。synchronizedList 的核心设计思路是 装饰器模式。它并没有重新实现一个 List,而是将原有的 ArrayList 包裹起来,然后在每个方法的实现上都加上 synchronized 代码块,通过同一把 互斥锁 来保证线程安全。
// Collections类中的静态内部类
static class SynchronizedList<E> extends SynchronizedCollection<E> implements List<E> {
final List<E> list; // 被包装的原始ArrayList
SynchronizedList(List<E> list, Object mutex) {
super(list, mutex); // 将mutex(锁对象)传给父类
this.list = list;
}
public E get(int index) {
synchronized (mutex) { // 获取锁
return list.get(index); // 调用原ArrayList的方法
} // 释放锁
}
public void add(int index, E element) {
synchronized (mutex) { // 获取锁
list.add(index, element); // 调用原ArrayList的方法
} // 释放锁
}
// ... 其他所有方法都是同样的模式
}
优点
ArrayList 包装成线程安全的。RandomAccess 接口(如果原 List 实现了),所以随机访问的性能和 ArrayList 一样好。缺点
同时它也有着大量的其他问题,例如复合操作不具备原子性。即使使用了 synchronizedList,下面这段代码在多线程环境下仍然是错误的:
List<String> list = Collections.synchronizedList(new ArrayList<>());
// ... 假设list中已经有了一些元素
// 在多线程环境下执行这段代码
if (!list.contains("a")) { // 检查操作(已加锁)
list.add("b"); // 添加操作(已加锁)
}
此时你需要手动使用同一个锁对象来保证复合操作的原子性:
// 正确做法:使用list对象本身作为锁,锁住整个操作块
synchronized (list) {
if (!list.contains("特定元素")) {
list.add("特定元素");
}
}
其次的问题就是遍历时需要手动加锁。当使用迭代器遍历 synchronizedList 时,必须在外层加锁。
List<String> list = Collections.synchronizedList(new ArrayList<>());
// 错误示例:会抛出 ConcurrentModificationException
// 因为迭代器遍历期间,另一个线程可能修改了list
for (String item : list) {
// 处理item
}
// 正确示例
synchronized (list) {
for (String item : list) { // 在锁的保护下遍历
// 处理item
}
}
综上,如果在使用场景是读写比例均衡,或需要强一致性的场景,可以考虑使用Collections.synchronizedList,但是需要记住在遍历或者任何复合操作的情况下,都需要手动加锁来保证原子性。
/**
* 使用 Collections.synchronizedList 解决并发问题
*/
@Test
public void testSynchronizedList() throws InterruptedException {
List<Integer> list = Collections.synchronizedList(new ArrayList<>());
int threadCount = 10;
int opsPerThread = 50000;
CountDownLatch latch = new CountDownLatch(threadCount);
long startTime = System.currentTimeMillis();
for (int i = 0; i < threadCount; i++) {
final int threadId = i;
new Thread(() -> {
try {
for (int j = 0; j < opsPerThread; j++) {
synchronized (list) {
list.add(threadId * opsPerThread + j);
}
}
} finally {
latch.countDown();
}
}).start();
}
latch.await();
long endTime = System.currentTimeMillis();
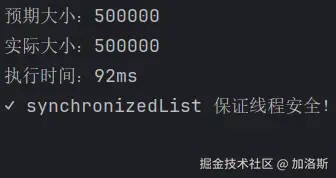
System.out.println("预期大小:" + (threadCount * opsPerThread));
System.out.println("实际大小:" + list.size());
System.out.println("执行时间:" + (endTime - startTime) + "ms");
if (list.size() == threadCount * opsPerThread) {
System.out.println(" synchronizedList 保证线程安全!");
}
}
这是Java并发包(JUC)中专门为读多写极少场景量身定做的一个方法。它的设计思想非常巧妙,采用了不变性和写时复制策略,彻底解决了并发冲突的问题。
public class CopyOnWriteArrayList<E> {
// 关键:使用 volatile 修饰的数组,保证修改后对其他线程的可见性
private transient volatile Object[] array;
// 添加元素的方法
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock(); // 写操作必须加锁,防止并发修改时复制出多个副本
try {
Object[] elements = getArray(); // 获取当前数组
int len = elements.length;
// 核心:复制一个新数组(长度+1)
Object[] newElements = Arrays.copyOf(elements, len + 1);
newElements[len] = e; // 在新数组上执行添加操作
setArray(newElements); // 将新数组设为当前数组
return true;
} finally {
lock.unlock();
}
}
// 读取元素的方法(没有加锁)
public E get(int index) {
return get(getArray(), index); // 直接从当前数组中获取
}
// 返回当前数组的快照
final Object[] getArray() {
return array;
}
}
这种设计带来的两个核心特性:
优点
Collections.synchronizedList。ConcurrentModificationException。因为迭代器操作的是独立的数组快照。缺点
volatile变量的语义,这个"不可见"的时间窗口非常短(写完成后,后续的读操作一定能看到)。synchronizedList。综上,如果你的业务要求严格的实时一致性(比如支付扣款后的余额查询),CopyOnWriteArrayList 就不适合了。
| 特性 | CopyOnWriteArrayList | Collections.synchronizedList |
|---|---|---|
| 实现原理 | 空间换时间:写时复制,读写分离 | 时间换安全:所有操作串行化 |
| 读锁 | 无锁 | 有锁(读读互斥) |
| 写锁 | 有锁(用ReentrantLock控制) | 有锁 |
| 内存占用 | 高(每次写创建新数组) | 低 |
| 数据一致性 | 弱一致性(迭代器快照) | 强一致性(锁保护) |
| 迭代异常 | 永不抛出 ConcurrentModificationException | 遍历期间如有修改会抛出异常 |
| 最佳场景 | 读多写极少(配置、白名单、器列表) | 读写均衡,或需要强一致性的场景 |
/**
* 演示使用 CopyOnWriteArrayList 解决并发问题
*/
@Test
public void testThreadSafeList() throws InterruptedException {
List<Integer> list = new CopyOnWriteArrayList<>();
int threadCount = 10;
int opsPerThread = 50000;
CountDownLatch latch = new CountDownLatch(threadCount);
long startTime = System.currentTimeMillis();
for (int i = 0; i < threadCount; i++) {
final int threadId = i;
new Thread(() -> {
try {
for (int j = 0; j < opsPerThread; j++) {
list.add(threadId * opsPerThread + j);
}
} finally {
latch.countDown();
}
}).start();
}
latch.await();
long endTime = System.currentTimeMillis();
System.out.println("预期大小:" + (threadCount * opsPerThread));
System.out.println("实际大小:" + list.size());
System.out.println("执行时间:" + (endTime - startTime) + "ms");
if (list.size() == threadCount * opsPerThread) {
System.out.println(" 线程安全,数据完整!");
}else {
System.out.println(" 检测到线程安全问题:数据不完整!");
}
}
通过上述代码可以看到,同样是50万量级的数据,使用CopyOnWriteArrayList的运行插入的时间是Collections.synchronizedList好几百倍,所以我们一定要注意使用场景的问题。
我们再来用一个读多写少的场景对比一下
/**
* 读多写少场景:synchronizedList vs CopyOnWriteArrayList
*/
@Test
public void testReadHeavyScenario() throws InterruptedException {
int threadCount = 10;
int writeCount = 1000;
int readCount = 1000000;
System.out.println("=== synchronizedList 读多写少 ===");
long syncTime = testSynchronizedList(threadCount, writeCount, readCount);
System.out.println("n=== CopyOnWriteArrayList 读多写少 ===");
long cowTime = testCopyOnWriteArrayList(threadCount, writeCount, readCount);
System.out.println("n=== 性能对比 ===");
System.out.println("synchronizedList: " + syncTime + "ms");
System.out.println("CopyOnWriteArrayList: " + cowTime + "ms");
System.out.println("CopyOnWriteArrayList " + (syncTime > cowTime ? "更快" : "更慢") +
",提升了 " + String.format("%.2f", (double)(syncTime - cowTime) / syncTime * 100) + "%");
}
private long testSynchronizedList(int threadCount, int writeCount, int readCount) throws InterruptedException {
List<Integer> list = Collections.synchronizedList(new ArrayList<>());
CountDownLatch latch = new CountDownLatch(threadCount);
long startTime = System.currentTimeMillis();
for (int i = 0; i < threadCount; i++) {
final int threadId = i;
new Thread(() -> {
try {
for (int j = 0; j < writeCount; j++) {
synchronized (list) {
list.add(threadId * writeCount + j);
}
}
for (int j = 0; j < readCount; j++) {
synchronized (list) {
if (!list.isEmpty()) {
list.get(list.size() - 1);
}
}
}
} finally {
latch.countDown();
}
}).start();
}
latch.await();
long endTime = System.currentTimeMillis();
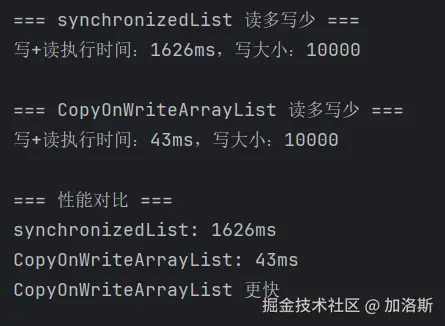
System.out.println("写+读执行时间:" + (endTime - startTime) + "ms,写大小:" + list.size());
return endTime - startTime;
}
private long testCopyOnWriteArrayList(int threadCount, int writeCount, int readCount) throws InterruptedException {
List<Integer> list = new CopyOnWriteArrayList<>();
CountDownLatch latch = new CountDownLatch(threadCount);
long startTime = System.currentTimeMillis();
for (int i = 0; i < threadCount; i++) {
final int threadId = i;
new Thread(() -> {
try {
for (int j = 0; j < writeCount; j++) {
list.add(threadId * writeCount + j);
}
for (int j = 0; j < readCount; j++) {
if (!list.isEmpty()) {
list.get(list.size() - 1);
}
}
} finally {
latch.countDown();
}
}).start();
}
latch.await();
long endTime = System.currentTimeMillis();
System.out.println("写+读执行时间:" + (endTime - startTime) + "ms,写大小:" + list.size());
return endTime - startTime;
}
上面的程序是十个线程,写入1万,读100万,可以看到在读百万量级数据的时候,用CopyOnWriteArrayList的时间几乎是提升了40倍。

