黑洞酷走
28.94M · 2026-03-22

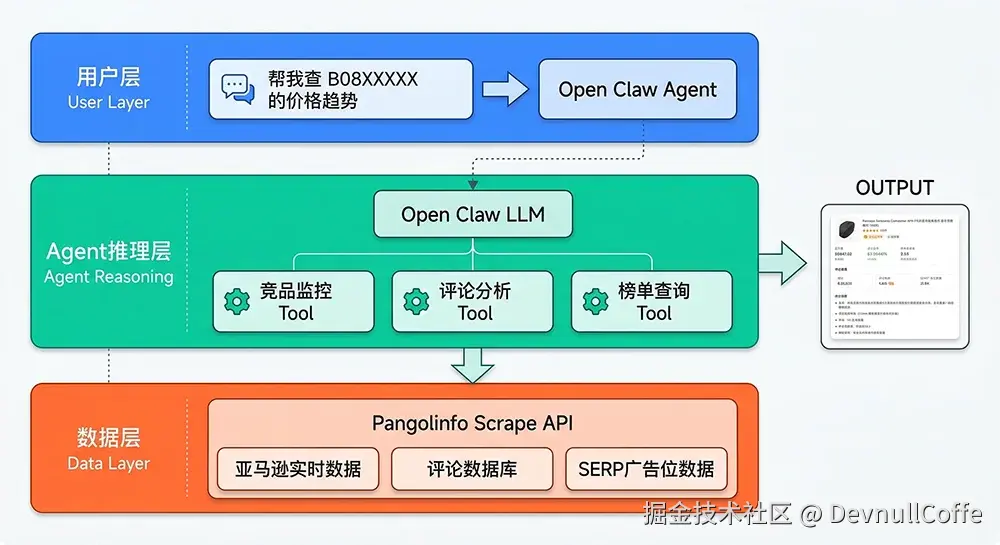
Open Claw 跨境电商的核心价值在于工具调用(Tool Use)打通 LLM 推理和实时电商数据。五个最具工程价值的场景:
数据层统一接入:Pangolinfo Scrape API(支持 Amazon/Walmart/Shopee,分钟级实时数据,JSON 格式输出)
跨境电商数据有三个特征,让它天然适合 Agent 化处理:
时效性强:BSR 排名每小时更新,价格每天可能多次变化,大促期间变化更频繁。传统 SaaS 工具的缓存周期(1-3天)在竞争激烈的类目里几乎等于过期数据。
多维度关联:单一数据维度(只看价格、只看 BSR)价值有限,真正有价值的分析是多维度关联——价格降低 → BSR 提升 → 评论增速加快 → 是否值得跟进促销。这种关联分析,LLM 天然擅长。
查询灵活多变:运营提出的问题五花八门,不可能用固定的仪表盘覆盖所有查询需求。Agent 的自然语言接口让任意查询成为可能。
┌─────────────────────────────────────────────────────┐
│ Open Claw Architecture │
│ │
│ 用户输入(自然语言) │
│ ↓ │
│ LLM 推理层(意图理解 + 工具选择) │
│ ↓ ↑ │
│ Tool Router ──────────────→ Tool Results │
│ ┌────────┐ ┌────────┐ ┌──────────────────────┐ │
│ │Price │ │Reviews │ │Category Bestsellers │ │
│ │Monitor │ │Scraper │ │Scanner │ │
│ └────────┘ └────────┘ └──────────────────────┘ │
│ ↓ ↓ ↓ │
│ Pangolinfo Scrape API(统一数据入口) │
│ ↓ ↓ ↓ │
│ Amazon Walmart Shopee / eBay │
└─────────────────────────────────────────────────────┘
关键设计原则:LLM 不存任何电商数据,纯推理;数据完全来自实时 API 调用;Tool 层定义清晰,职责单一。
Open Claw Agent 的工具选择准确率取决于 Tool Description 的质量。以下是实践中有效的描述模式:
# 好的 Tool Description 示例
GOOD_TOOL = {
"name": "get_amazon_product_realtime",
"description": """
获取亚马逊指定 ASIN 的实时商品数据。
【使用时机】:
- 用户询问某个特定 ASIN 的当前价格、BSR 排名、评分
- 需要检测竞品是否有促销活动
- 需要确认商品是否在售/是否有库存
【不要在以下情况使用】:
- 需要分析历史价格趋势(使用 get_price_history_tool)
- 需要类目榜单数据(使用 get_category_rankings_tool)
- ASIN 未知时(应先搜索关键词获取 ASIN 列表)
""",
"input_schema": {
"type": "object",
"properties": {
"asin": {
"type": "string",
"description": "Amazon ASIN,10位字母数字,如 B08N5WRWNW。注意区分大小写。"
},
"marketplace": {
"type": "string",
"enum": ["US", "UK", "DE", "JP", "CA"],
"default": "US"
}
},
"required": ["asin"]
}
}
# 差的 Tool Description 示例(过于模糊)
BAD_TOOL = {
"name": "get_product",
"description": "获取产品信息", # 太模糊!LLM 不知道何时用
"input_schema": {
"type": "object",
"properties": {
"id": {"type": "string"} # 参数名不清晰
}
}
}
| 粒度 | 示例 | 适用场景 |
|---|---|---|
| 过细 | 分别有"获取价格"和"获取BSR"两个工具 | 导致 Agent 多余的工具调用,增加延迟 |
| 适中 | "获取商品当前状态"(含价格+BSR+评分+库存) | 推荐,单次调用覆盖主要数据需求 |
| 过粗 | "获取所有电商数据" | 单次请求数据量过大,浪费 token |
图1:Open Claw 跨境电商架构——用户自然语言→LLM推理层选择Tool→Pangolinfo Scrape API实时数据返回,无缓存延迟
Open Claw Scheduler(每4小时触发)
↓
MonitorAgent.run(asin_watchlist)
↓
Pangolinfo Scrape API(并行请求)
↓
AlertDetector.check(current, baseline)
↓
NotificationRouter(Slack/企业微信/邮件)
↓
BaselineStore.update(Redis/SQLite)
import asyncio
import aiohttp
import json
import logging
from dataclasses import dataclass, asdict
from datetime import datetime
from typing import List, Optional, Dict, Any
from enum import Enum
logger = logging.getLogger(__name__)
class AlertSeverity(Enum):
HIGH = "HIGH"
MEDIUM = "MEDIUM"
LOW = "LOW"
@dataclass
class PriceAlert:
asin: str
marketplace: str
severity: AlertSeverity
alert_type: str
message: str
current_price: Optional[float]
previous_price: Optional[float]
current_bsr: Optional[int]
previous_bsr: Optional[int]
triggered_at: str
class AsyncPangolinScraper:
"""
异步版 Pangolinfo 采集客户端
支持高并发批量请求
"""
BASE_URL = "https://api.pangolinfo.com/v1"
def __init__(self, api_key: str,
max_concurrent: int = 10,
timeout: int = 30):
self.api_key = api_key
self.semaphore = asyncio.Semaphore(max_concurrent)
self.timeout = aiohttp.ClientTimeout(total=timeout)
async def fetch_product(self, session: aiohttp.ClientSession,
asin: str, marketplace: str = "US") -> Dict:
"""异步获取单个 ASIN 数据"""
async with self.semaphore: # 并发限制
headers = {"Authorization": f"Bearer {self.api_key}"}
payload = {
"source": "amazon_product",
"asin": asin,
"marketplace": marketplace,
"fields": [
"price", "original_price", "bsr", "bsr_category",
"rating", "review_count", "availability",
"seller_type", "deal_type"
],
"output_format": "json"
}
try:
async with session.post(
f"{self.BASE_URL}/scrape",
headers=headers,
json=payload,
timeout=self.timeout
) as resp:
resp.raise_for_status()
data = await resp.json()
return {"success": True, "asin": asin, "data": data}
except asyncio.TimeoutError:
logger.warning(f"Timeout fetching {asin}")
return {"success": False, "asin": asin, "error": "timeout"}
except Exception as e:
logger.error(f"Error fetching {asin}: {e}")
return {"success": False, "asin": asin, "error": str(e)}
async def batch_fetch(self, asin_list: List[str],
marketplace: str = "US") -> List[Dict]:
"""批量异步获取,自动并发控制"""
async with aiohttp.ClientSession() as session:
tasks = [
self.fetch_product(session, asin, marketplace)
for asin in asin_list
]
results = await asyncio.gather(*tasks, return_exceptions=False)
return results
class AlertEngine:
"""告警检测引擎"""
def __init__(self, config: Dict):
self.config = config
def detect_alerts(self, current: Dict,
baseline: Optional[Dict]) -> List[PriceAlert]:
alerts = []
asin = current.get("asin", "")
marketplace = current.get("marketplace", "US")
now = datetime.utcnow().isoformat() + "Z"
current_price = current.get("price")
current_bsr = current.get("bsr")
baseline_price = baseline.get("price") if baseline else None
baseline_bsr = baseline.get("bsr") if baseline else None
# ── 价格大幅下降 ──────────────────────────────
if (current_price and baseline_price and
baseline_price > 0):
drop_pct = (baseline_price - current_price) / baseline_price * 100
if drop_pct >= self.config.get("price_drop_threshold", 12):
alerts.append(PriceAlert(
asin=asin, marketplace=marketplace,
severity=AlertSeverity.HIGH,
alert_type="price_drop",
message=(f"价格下降 {drop_pct:.1f}%: "
f"${baseline_price:.2f} → ${current_price:.2f}"),
current_price=current_price,
previous_price=baseline_price,
current_bsr=current_bsr,
previous_bsr=baseline_bsr,
triggered_at=now
))
# ── BSR 大幅提升 ──────────────────────────────
if (current_bsr and baseline_bsr and
baseline_bsr > current_bsr):
improvement = baseline_bsr - current_bsr
if improvement >= self.config.get("bsr_spike_threshold", 300):
alerts.append(PriceAlert(
asin=asin, marketplace=marketplace,
severity=AlertSeverity.MEDIUM,
alert_type="bsr_spike",
message=(f"BSR 提升 {improvement} 位: "
f"{baseline_bsr} → {current_bsr}"),
current_price=current_price,
previous_price=baseline_price,
current_bsr=current_bsr,
previous_bsr=baseline_bsr,
triggered_at=now
))
# ── 促销活动检测 ──────────────────────────────
if (self.config.get("detect_promotions", True) and
current.get("active_deal")):
alerts.append(PriceAlert(
asin=asin, marketplace=marketplace,
severity=AlertSeverity.HIGH,
alert_type="promotion_detected",
message=f"检测到促销:{current.get('active_deal')}",
current_price=current_price,
previous_price=baseline_price,
current_bsr=current_bsr,
previous_bsr=baseline_bsr,
triggered_at=now
))
return alerts
async def run_monitoring_cycle(
scraper: AsyncPangolinScraper,
alert_engine: AlertEngine,
asin_watchlist: List[str],
baseline_store: Dict,
marketplace: str = "US"
) -> List[PriceAlert]:
"""
执行一次完整的监控周期
Returns: 本次发现的所有告警列表
"""
logger.info(f"开始监控周期,ASIN 数量:{len(asin_watchlist)}")
# 并行获取所有 ASIN 当前数据
results = await scraper.batch_fetch(asin_watchlist, marketplace)
all_alerts = []
for result in results:
if not result.get("success"):
logger.warning(f"获取 {result.get('asin')} 失败:{result.get('error')}")
continue
asin = result["asin"]
current_data = result["data"]
current_data["asin"] = asin
current_data["marketplace"] = marketplace
# 与基准线对比
baseline = baseline_store.get(asin)
alerts = alert_engine.detect_alerts(current_data, baseline)
all_alerts.extend(alerts)
if alerts:
logger.info(f"ASIN {asin} 触发 {len(alerts)} 个告警")
# 更新基准线
baseline_store[asin] = current_data
logger.info(f"监控周期完成,共发现 {len(all_alerts)} 个告警")
return all_alerts
# 使用示例
async def main():
scraper = AsyncPangolinScraper(
api_key="your_pangolinfo_api_key",
max_concurrent=8
)
alert_engine = AlertEngine({
"price_drop_threshold": 12.0, # 价格下降超过12%触发
"bsr_spike_threshold": 300, # BSR提升超过300位触发
"detect_promotions": True
})
watchlist = [
"B08N5WRWNW", "B09XXXXXX1", "B09XXXXXX2",
"B09XXXXXX3", "B09XXXXXX4", "B09XXXXXX5"
]
baseline_store = {} # 生产环境使用 Redis
alerts = await run_monitoring_cycle(
scraper, alert_engine, watchlist, baseline_store
)
for alert in alerts:
print(f"[{alert.severity.value}] {alert.asin}: {alert.message}")
if __name__ == "__main__":
asyncio.run(main())
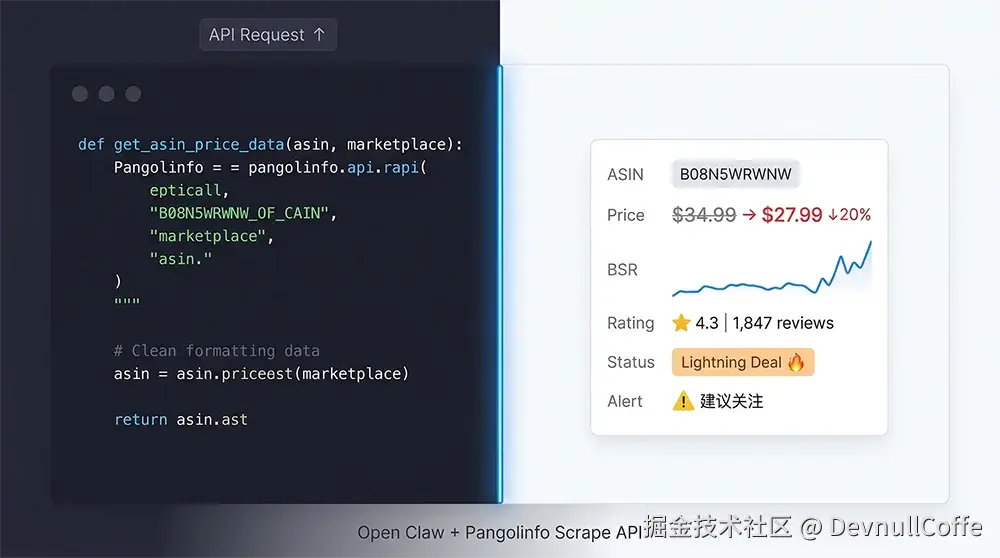
图2:Open Claw 异步并发监控的实时效果——左侧Python异步代码,右侧为 Pangolinfo API 返回的竞品实时数据(价格降20%、Lightning Deal、BSR提升)
对于大批量评论分析,使用 LLM 的流式输出可以显著提升用户体验:
import anthropic
def analyze_reviews_streaming(reviews_data: str, category: str):
"""
流式输出评论分析结果
适合在 Web UI 或终端实时展示分析进度
"""
client = anthropic.Anthropic()
prompt = f"""
分析以下 { category } 类目亚马逊商品评论,识别用户最关注的痛点和诉求:
{reviews_data}
请输出:
1. 差评核心痛点 TOP10(按频率排序)
2. 好评核心价值点 TOP5
3. 产品优化建议(具体可落地)
4. Listing Bullet Points 优化建议(3条)
"""
print("=== AI 评论分析报告 ===n")
with client.messages.stream(
model="claude-3-7-sonnet-20250219",
max_tokens=2000,
messages=[{"role": "user", "content": prompt}]
) as stream:
for text in stream.text_stream:
print(text, end="", flush=True)
print("nn=== 分析完成 ===")
| 方案 | 竞品监控延迟 | 开发成本 | 数据实时性 | 扩展性 |
|---|---|---|---|---|
| 人工监控 | 12-24小时 | 低(人力成本) | 低 | 差 |
| 传统 SaaS 工具 | 1-3天(缓存) | 中 | 低-中 | 受限 |
| Open Claw + 第三方 API | 分钟级 | 中-高 | 高 | 优 |
| 自建爬虫 | 小时级(维护稳定后) | 极高 | 高 | 中 |
结论:Open Claw + Pangolinfo API 在开发成本和数据实时性之间取得了最佳平衡。自建爬虫维护成本随亚马逊反爬策略升级持续增加;传统 SaaS 工具的数据时效性无法满足 Agent 实时查询需求;Open Claw 集成方案是当前最具性价比的跨境电商 AI Agent 技术路径。
Open Claw 跨境电商数据自动化的核心技术要点:

