烹饪披萨机
110.73M · 2026-03-10

本章分析Topic创建流程:
注:本文基于4.2.0。
Broker注册发现,ZK模式通过临时ZNode= /brokers/{brokerId} 。
{"listener_security_protocol_map":{"PLAINTEXT":"PLAINTEXT"},
"endpoints":["PLAINTEXT://localhost:9092"],
"jmx_port":-1,"port":9092,"host":"localhost","version":4,"timestamp":"xxx"}
创建Topic,ZK模式Controller需要两阶段。
一阶段,assignment,Controller分配Topic分区。
创建ZNode= /brokers/topics/{topic} 。比如下面3分区2副本的topic,分区0在brokerId=111和222上。
{"version":2,"partitions":{"0":[111,222],"1":[222,111],
"2":[111,222]},"adding_replicas":{},"removing_replicas":{}}
二阶段,Controller/brokers/topics子节点变更,初始化分区Leader和ISR列表,ISR=副本列表中存活broker,Leader=ISR列表的第一个broker。
创建ZNode= /brokers/topics/{topic}/partitions/{partitionId}/state。比如根据上面分区0的assignment,broker=111和222都存活。
{"controller_epoch":9,"leader":111,
"version":1,"leader_epoch":5,"isr":[111,222]}
Controller处理完成:
BrokerServer.startup:broker启动的关键点
override def startup(): Unit = {
// 1. 启动raft组件
sharedServer.startForBroker()
metadataCache = new KRaftMetadataCache(config.nodeId, () => raftManager.client.kraftVersion())
lifecycleManager = new BrokerLifecycleManager()
// Broker与Controller发送心跳客户端,依赖Raft复制发送Fetch请求找到Controller(Leader)
val brokerLifecycleChannelManager = new NodeToControllerChannelManagerImpl()
// 2. StartupEvent,开始Broker注册
lifecycleManager.start(brokerLifecycleChannelManager...)
// 安装元数据publishers
brokerMetadataPublisher = new BrokerMetadataPublisher()
metadataPublishers.add(brokerMetadataPublisher)
FutureUtils.waitWithLogging(logger.underlying, logIdent,
"the broker metadata publishers to be installed",
sharedServer.loader.installPublishers(metadataPublishers), startupDeadline, time)
// 3. 等待controller通过heartbeat response(isCaughtUp=true)告知当前broker追上raft日志
FutureUtils.waitWithLogging(logger.underlying, logIdent,
"the controller to acknowledge that we are caught up",
lifecycleManager.initialCatchUpFuture, startupDeadline, time)
// 4. 等待首次元数据加载完毕
FutureUtils.waitWithLogging(logger.underlying, logIdent,
"the initial broker metadata update to be published",
brokerMetadataPublisher.firstPublishFuture , startupDeadline, time))
// 5. 立即触发一次broker心跳,从fenced->unfence
FutureUtils.waitWithLogging(logger.underlying, logIdent,
"the broker to be unfenced",
lifecycleManager.setReadyToUnfence(), startupDeadline, time)
// 6. 启动Acceptors,可以处理客户端请求
val enableRequestProcessingFuture = socketServer.enableRequestProcessing(authorizerFutures)
FutureUtils.waitWithLogging(logger.underlying, logIdent,
"all of the SocketServer Acceptors to be started",
enableRequestProcessingFuture, startupDeadline, time)
}
BrokerLifecycleManager.start:开始Broker注册,将StartupEvent入队,由lifecycle-manager单线程处理。
private[server] val eventQueue = new KafkaEventQueue(
threadNamePrefix + "lifecycle-manager-")
def start(highestMetadataOffsetProvider: () => Long,
channelManager: NodeToControllerChannelManager,
clusterId: String,
advertisedListeners: ListenerCollection,
supportedFeatures: util.Map[String, VersionRange],
previousBrokerEpoch: OptionalLong): Unit = {
this.previousBrokerEpoch = previousBrokerEpoch
// lifecycle-manager单线程处理
eventQueue.append(new StartupEvent(highestMetadataOffsetProvider,
channelManager, clusterId, advertisedListeners, supportedFeatures))
}
关于Broker Epoch:Broker每次正常启动,需要一个新的Epoch。Controller通过brokerId找到Broker端点,下发指令携带Epoch。如果Broker发现Epoch与自己不相等,可能是上次进程启动时的过期指令,不会接收。
在ZK模式中,Epoch是注册临时ZNode= /brokers/{brokerId} 的事务ID,即czxid;在KRaft模式中,Epoch通过Controller注册响应下发,缓存到内存,在Broker正常关闭时持久化到kafka_cleanshutdown文件,previousBrokerEpoch即为上次Broker进程的Epoch。
StartupEvent.run:发送BrokerRegistrationRequest,主要包括自己的brokerId和端点信息。
override def run(): Unit = {
// ...
// 发送BrokerRegistrationRequest
sendBrokerRegistration()
}
private def sendBrokerRegistration(): Unit = {
val data = new BrokerRegistrationRequestData().
// brokerId
setBrokerId(nodeId).
setIsMigratingZkBroker(false).
setClusterId(_clusterId).
setFeatures(features).
// 实例id,每次启动给一个uuid
setIncarnationId(incarnationId).
// 端点信息
setListeners(_advertisedListeners).
setRack(rack.orNull).
// 上次epoch
setPreviousBrokerEpoch(previousBrokerEpoch.orElse(-1L)).
setLogDirs(sortedLogDirs)
_channelManager.sendRequest(new BrokerRegistrationRequest.Builder(data),
new BrokerRegistrationResponseHandler())
communicationInFlight = true
}
ControllerApis.handleBrokerRegistration:Controller最终会返回broker一个新的epoch。
private def handleBrokerRegistration(request: RequestChannel.Request): CompletableFuture[Unit] = {
val registrationRequest = request.body[BrokerRegistrationRequest]
controller.registerBroker(context, registrationRequest.data).handle[Unit] { (reply, e) =>
def createResponseCallback(requestThrottleMs: Int,
reply: BrokerRegistrationReply,
e: Throwable): BrokerRegistrationResponse = {
if (e != null) {
new BrokerRegistrationResponse(new BrokerRegistrationResponseData().
setThrottleTimeMs(requestThrottleMs).
setErrorCode(Errors.forException(e).code))
} else {
new BrokerRegistrationResponse(new BrokerRegistrationResponseData().
setThrottleTimeMs(requestThrottleMs).
setErrorCode(NONE.code).
setBrokerEpoch(reply.epoch)) // 给broker分配新epoch
}
}
requestHelper.sendResponseMaybeThrottle(request,
requestThrottleMs => createResponseCallback(requestThrottleMs, reply, e))
}
}
QuorumController.registerBroker:
public CompletableFuture<BrokerRegistrationReply> registerBroker(
ControllerRequestContext context,
BrokerRegistrationRequestData request
) {
return appendWriteEvent("registerBroker", context.deadlineNs(),
() -> {
// ...
return clusterControl.
// zk用zcxid,kraft用nextWriteOffset=broker注册raft记录的写入offset
registerBroker(request, offsetControl.nextWriteOffset(),
new FinalizedControllerFeatures(controllerFeatures, Long.MAX_VALUE),
context.requestHeader().requestApiVersion() >= 3);
},
EnumSet.noneOf(ControllerOperationFlag.class));
}
ClusterControlManager.registerBroker:校验并构造RegisterBrokerRecord(Raft日志项),注册Broker到心跳管理器。
public ControllerResult<BrokerRegistrationReply> registerBroker(
BrokerRegistrationRequestData request,
long newBrokerEpoch,
FinalizedControllerFeatures finalizedFeatures,
boolean cleanShutdownDetectionEnabled
) {
if (!clusterId.equals(request.clusterId())) {
throw new InconsistentClusterIdException();
}
int brokerId = request.brokerId();
List<ApiMessageAndVersion> records = new ArrayList<>();
BrokerRegistration existing = brokerRegistrations.get(brokerId);
Uuid prevIncarnationId = null;
long storedBrokerEpoch = -2;
if (existing != null) {
prevIncarnationId = existing.incarnationId();
storedBrokerEpoch = existing.epoch();
// 如果相同epoch的心跳还存活,且实例id不一致,返回异常
if (heartbeatManager.hasValidSession(brokerId, existing.epoch())) {
if (!request.incarnationId().equals(prevIncarnationId)) {
throw new DuplicateBrokerRegistrationException();
}
}
}
ListenerInfo listenerInfo = ListenerInfo.fromBrokerRegistrationRequest(request.listeners());
RegisterBrokerRecord record = new RegisterBrokerRecord().
setBrokerId(brokerId).
setIsMigratingZkBroker(request.isMigratingZkBroker()).
setIncarnationId(request.incarnationId()).
setRack(request.rack()).
setEndPoints(listenerInfo.toBrokerRegistrationRecord());
if (!request.incarnationId().equals(prevIncarnationId)) {
// 如果非相同实例,代表broker是新进程,正常分配新epoch
int prevNumRecords = records.size();
record.setBrokerEpoch(newBrokerEpoch);
} else {
// 如果是相同实例,可能是broker侧认为超时,重新发送注册请求,更新record,epoch不变
record.setFenced(existing.fenced());
record.setInControlledShutdown(existing.inControlledShutdown());
record.setBrokerEpoch(existing.epoch());
}
records.add(new ApiMessageAndVersion(record, featureControl.metadataVersionOrThrow().
registerBrokerRecordVersion()));
if (!request.incarnationId().equals(prevIncarnationId)) {
heartbeatManager.remove(brokerId);
}
// 注册broker到心跳管理器
heartbeatManager.register(brokerId, record.fenced());
return ControllerResult.of(records, new BrokerRegistrationReply(record.brokerEpoch()));
}
// BrokerHeartbeatManager#register
private final HashMap<Integer, BrokerHeartbeatState> brokers;
void register(int brokerId, boolean fenced) {
BrokerHeartbeatState broker = brokers.get(brokerId);
long metadataOffset = -1L;
if (broker == null) {
broker = new BrokerHeartbeatState(brokerId, fenced, -1L, -1L);
brokers.put(brokerId, broker);
} else if (broker.fenced() != fenced) {
metadataOffset = broker.metadataOffset;
}
touch(brokerId, fenced, metadataOffset);
}
ClusterControlManager.replay:经过Raft写,过半Voter的高水位超过该broker注册日志项offset,应用日志到内存。
// brokerId -> 注册日志项offset
private final TimelineHashMap<Integer, Long> registerBrokerRecordOffsets;
// brokerId -> broker注册信息
private final TimelineHashMap<Integer, BrokerRegistration> brokerRegistrations;
public void replay(RegisterBrokerRecord record, long offset) {
registerBrokerRecordOffsets.put(record.brokerId(), offset);
int brokerId = record.brokerId();
ListenerInfo listenerInfo = ListenerInfo.fromBrokerRegistrationRecord(record.endPoints());
BrokerRegistration prevRegistration = brokerRegistrations.put(brokerId,
new BrokerRegistration.Builder().
setId(brokerId).
setEpoch(record.brokerEpoch()).
setIncarnationId(record.incarnationId()).
setListeners(listenerInfo.listeners()).
setSupportedFeatures(features).
setRack(Optional.ofNullable(record.rack())).
setFenced(record.fenced()).
setInControlledShutdown(record.inControlledShutdown()).
setIsMigratingZkBroker(record.isMigratingZkBroker()).
setDirectories(record.logDirs()).
build());
}
BrokerRegistrationResponseHandler:
private class BrokerRegistrationResponseHandler extends ControllerRequestCompletionHandler {
override def onComplete(response: ClientResponse): Unit = {
eventQueue.prepend(new BrokerRegistrationResponseEvent(response, false))
}
override def onTimeout(): Unit = {
eventQueue.prepend(new BrokerRegistrationResponseEvent(null, true))
}
}
private class BrokerRegistrationResponseEvent(response: ClientResponse, timedOut: Boolean) extends EventQueue.Event {
override def run(): Unit = {
communicationInFlight = false
if (timedOut) {
// 重新发送注册请求
scheduleNextCommunicationAfterFailure()
return
}
if (response.authenticationException() != null) {
scheduleNextCommunicationAfterFailure()
// else if 其他失败,scheduleNextCommunicationAfterFailure
} else {
val message = response.responseBody().asInstanceOf[BrokerRegistrationResponse]
val errorCode = Errors.forCode(message.data().errorCode())
if (errorCode == Errors.NONE) {
_brokerEpoch = message.data().brokerEpoch()
registered = true
initialRegistrationSucceeded = true
// 开始发送心跳
scheduleNextCommunicationImmediately()
} else {
scheduleNextCommunicationAfterFailure()
}
}
}
}
BrokerLifecycleManager.scheduleNextCommunication:投递CommunicationEvent事件。
private def scheduleNextCommunication(intervalNs: Long): Unit = {
val adjustedIntervalNs = if (nextSchedulingShouldBeImmediate) 0 else intervalNs
nextSchedulingShouldBeImmediate = false
val deadlineNs = time.nanoseconds() + adjustedIntervalNs
eventQueue.scheduleDeferred("communication",
new DeadlineFunction(deadlineNs),
new CommunicationEvent())
}
private class CommunicationEvent extends EventQueue.Event {
override def run(): Unit = {
if (communicationInFlight) {
nextSchedulingShouldBeImmediate = true
} else if (registered) {
// 如果已经注册,发送心跳
sendBrokerHeartbeat()
} else {
// 否则,发送注册(比如上面失败重试,也是走这里)
sendBrokerRegistration()
}
}
}
BrokerLifecycleManager.sendBrokerHeartbeat:心跳包
private def sendBrokerHeartbeat(): Unit = {
val metadataOffset = _highestMetadataOffsetProvider()
val data = new BrokerHeartbeatRequestData().
setBrokerEpoch(_brokerEpoch).
setBrokerId(nodeId).
setCurrentMetadataOffset(metadataOffset).
setWantFence(!readyToUnfence).
setWantShutDown(_state == BrokerState.PENDING_CONTROLLED_SHUTDOWN).
setOfflineLogDirs(offlineDirs.keys.toSeq.asJava)
val handler = new BrokerHeartbeatResponseHandler(offlineDirs.keys)
_channelManager.sendRequest(new BrokerHeartbeatRequest.Builder(data), handler)
communicationInFlight = true
}
QuorumController.processBrokerHeartbeat:记录心跳时间,提交raft请求到quorum-controller线程。
public CompletableFuture<BrokerHeartbeatReply> processBrokerHeartbeat(
ControllerRequestContext context,
BrokerHeartbeatRequestData request
) {
// 1. 记录心跳时间,如果自己不是leader,返回false
if (!clusterControl.trackBrokerHeartbeat(request.brokerId(), request.brokerEpoch())) {
throw ControllerExceptions.newWrongControllerException(latestController());
}
// 2. 提交raft请求到quorum-controller线程处理
return appendWriteEvent("processBrokerHeartbeat", context.deadlineNs(),
new ControllerWriteOperation<BrokerHeartbeatReply>() {
private final int brokerId = request.brokerId();
// broker是否准备下线
private boolean inControlledShutdown = false;
@Override
public ControllerResult<BrokerHeartbeatReply> generateRecordsAndResult() {
// 获取注册记录的offset
OptionalLong offsetForRegisterBrokerRecord =
clusterControl.registerBrokerRecordOffset(brokerId);
// 校验 并 构造Raft记录 和 响应reply
ControllerResult<BrokerHeartbeatReply> result = replicationControl.
processBrokerHeartbeat(request, offsetForRegisterBrokerRecord.getAsLong());
inControlledShutdown = result.response().inControlledShutdown();
return result;
}
@Override
public void processBatchEndOffset(long offset) {
if (inControlledShutdown) {
// 如果准备下线,记录下线请求相关记录的结束offset
clusterControl.heartbeatManager().
maybeUpdateControlledShutdownOffset(brokerId, offset);
}
}
});
}
ReplicationControlManager.processBrokerHeartbeat:计算Broker下一个状态,如果状态变更,需要构造构建变更Raft日志记录,走Raft写。
ControllerResult<BrokerHeartbeatReply> processBrokerHeartbeat(
BrokerHeartbeatRequestData request,
long registerBrokerRecordOffset
) {
int brokerId = request.brokerId();
long brokerEpoch = request.brokerEpoch();
// 1. 校验broker的epoch和内存一致
clusterControl.checkBrokerEpoch(brokerId, brokerEpoch);
// 2. 根据 request 和 当前state,计算broker新状态
BrokerHeartbeatManager heartbeatManager = clusterControl.heartbeatManager();
BrokerControlStates states = heartbeatManager.calculateNextBrokerState(brokerId,
request, registerBrokerRecordOffset, () -> brokersToIsrs.hasLeaderships(brokerId));
List<ApiMessageAndVersion> records = new ArrayList<>();
// 3. 如果状态变更,构造BrokerRegistrationChangeRecord记录 是broker新状态
if (states.current() != states.next()) {
switch (states.next()) {
case FENCED:
case SHUTDOWN_NOW:
handleBrokerFenced(brokerId, records);
break;
case UNFENCED:
handleBrokerUnfenced(brokerId, brokerEpoch, records);
break;
case CONTROLLED_SHUTDOWN:
handleBrokerInControlledShutdown(brokerId, brokerEpoch, records);
break;
}
}
// 4. 返回包括
// isCaughtUp=broker的offset是否追上broker注册记录offset & 下一个状态
boolean isCaughtUp = request.currentMetadataOffset() >= registerBrokerRecordOffset;
BrokerHeartbeatReply reply = new BrokerHeartbeatReply(isCaughtUp,
states.next().fenced(),
states.next().inControlledShutdown(),
states.next().shouldShutDown());
return ControllerResult.of(records, reply);
}
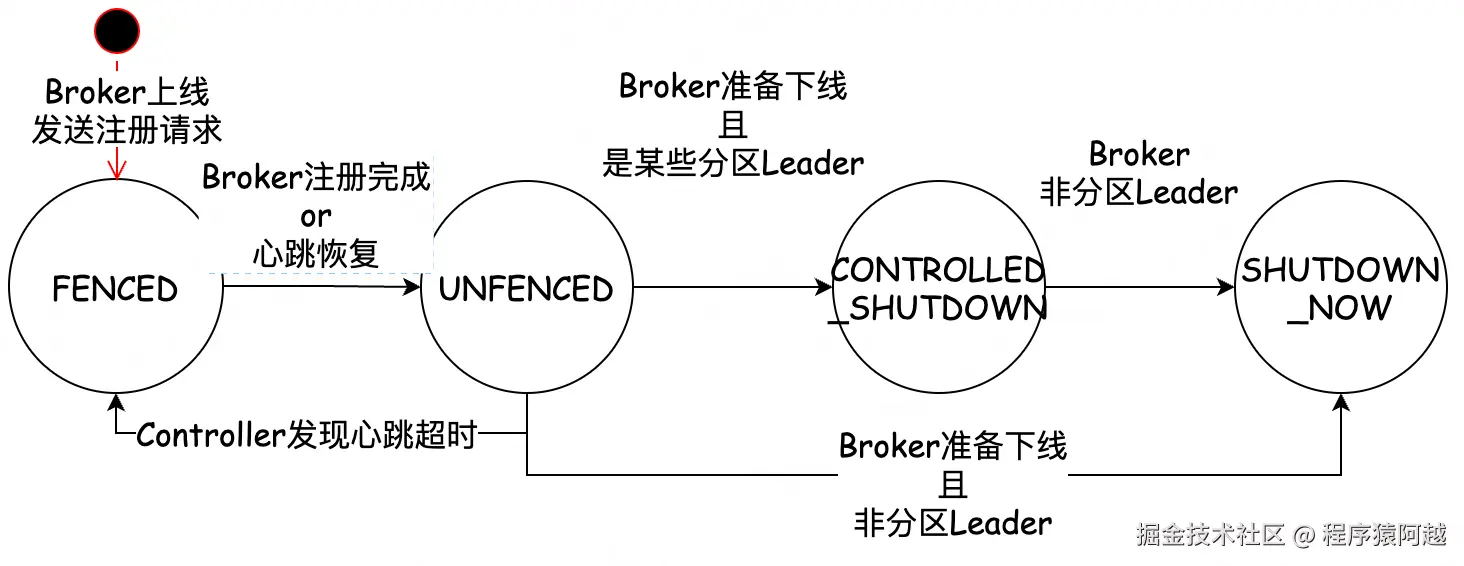
Broker有四种状态:
BrokerHeartbeatManager.calculateNextBrokerState:Broker状态转移。
BrokerControlStates calculateNextBrokerState(int brokerId,
BrokerHeartbeatRequestData request,
long registerBrokerRecordOffset,
Supplier<Boolean> hasLeaderships) {
BrokerHeartbeatState broker = heartbeatStateOrThrow(brokerId);
BrokerControlState currentState = currentBrokerState(broker);
switch (currentState) {
case FENCED:
// broker刚启动还未加载元数据 / 心跳超时被controller标记为fenced
if (request.wantShutDown()) {
// broker主动要求下线,直接SHUTDOWN_NOW
return new BrokerControlStates(currentState, SHUTDOWN_NOW);
} else if (!request.wantFence()) {
// broker想要解除隔离
if (request.currentMetadataOffset() >= registerBrokerRecordOffset) {
// broker当前offset >= 注册请求的offset,broker可以解除fence
// FENCED -> UNFENCED
return new BrokerControlStates(currentState, UNFENCED);
} else {
return new BrokerControlStates(currentState, FENCED);
}
}
// broker不想下线也不想解除隔离,保持不变
return new BrokerControlStates(currentState, FENCED);
case UNFENCED:
// broker正常运行
if (request.wantFence()) {
// broker主动想要被隔离,nosuch case
if (request.wantShutDown()) {
return new BrokerControlStates(currentState, SHUTDOWN_NOW);
} else {
return new BrokerControlStates(currentState, FENCED);
}
} else if (request.wantShutDown()) {
// broker想要下线
if (hasLeaderships.get()) {
// 如果broker是某些分区Leader,UNFENCED->CONTROLLED_SHUTDOWN,等待Leader重新被选举
return new BrokerControlStates(currentState, CONTROLLED_SHUTDOWN);
} else {
// 否则,broker可以立即下线,UNFENCED->SHUTDOWN_NOW
return new BrokerControlStates(currentState, SHUTDOWN_NOW);
}
}
// 正常运行期间的心跳包 UNFENCED->UNFENCED
return new BrokerControlStates(currentState, UNFENCED);
case CONTROLLED_SHUTDOWN:
// broker正在优雅下线
if (hasLeaderships.get()) {
// broker仍然是某些分区的leader,继续CONTROLLED_SHUTDOWN,等待自己被移除
// CONTROLLED_SHUTDOWN->CONTROLLED_SHUTDOWN
return new BrokerControlStates(currentState, CONTROLLED_SHUTDOWN);
}
// 所有存活broker中 当前最小的offset
long lowestActiveOffset = lowestActiveOffset();
if (broker.controlledShutdownOffset <= lowestActiveOffset) {
// shutdown请求 <= 最小的offset,代表已经被所有broker接收,可以关闭
// CONTROLLED_SHUTDOWN->SHUTDOWN_NOW
return new BrokerControlStates(currentState, SHUTDOWN_NOW);
}
// shutdown请求 > 最小offset,代表还没被所有broker接收,继续CONTROLLED_SHUTDOWN
// CONTROLLED_SHUTDOWN -> CONTROLLED_SHUTDOWN
return new BrokerControlStates(currentState, CONTROLLED_SHUTDOWN);
default:
// broker已经关闭
return new BrokerControlStates(currentState, SHUTDOWN_NOW);
}
}
ReplicationControlManager.handleBrokerFenced/handleBrokerUnfenced:不同状态,构建不同的Raft日志,包含:LeaderAndIsr变更PartitionChangeRecord(isr列表变更/leader选举都在构建Record时计算完成,见PartitionChangeBuilder#build)、Broker注册信息变更BrokerRegistrationChangeRecord。
// 隔离
void handleBrokerFenced(int brokerId, List<ApiMessageAndVersion> records) {
// broker注册信息
BrokerRegistration brokerRegistration = clusterControl.brokerRegistrations().get(brokerId);
// 生成leaderAndIsr变更日志
generateLeaderAndIsrUpdates("handleBrokerFenced", brokerId, NO_LEADER, NO_LEADER, records,
// 处理broker在isr里的分区,将broker从isr中移除,并重新选举leader
brokersToIsrs.partitionsWithBrokerInIsr(brokerId));
// 生成broker注册变更,变为FENCE
records.add(new ApiMessageAndVersion(new BrokerRegistrationChangeRecord().
setBrokerId(brokerId).setBrokerEpoch(brokerRegistration.epoch()).
setFenced(BrokerRegistrationFencingChange.FENCE.value()),
(short) 0));
}
// 解除隔离
void handleBrokerUnfenced(int brokerId, long brokerEpoch, List<ApiMessageAndVersion> records) {
// broker注册变更,UNFENCE
records.add(new ApiMessageAndVersion(new BrokerRegistrationChangeRecord().
setBrokerId(brokerId).setBrokerEpoch(brokerEpoch).
setFenced(BrokerRegistrationFencingChange.UNFENCE.value()),
(short) 0));
// leaderAndIsr变更,没有leader的分区
generateLeaderAndIsrUpdates("handleBrokerUnfenced", NO_LEADER, brokerId, NO_LEADER, records,
// 处理没有leader的分区
brokersToIsrs.partitionsWithNoLeader());
}
// 优雅下线
void handleBrokerInControlledShutdown(int brokerId, long brokerEpoch, List<ApiMessageAndVersion> records) {
if (!clusterControl.inControlledShutdown(brokerId)) {
records.add(new ApiMessageAndVersion(new BrokerRegistrationChangeRecord().
setBrokerId(brokerId).setBrokerEpoch(brokerEpoch).
setInControlledShutdown(BrokerRegistrationInControlledShutdownChange.IN_CONTROLLED_SHUTDOWN.value()),
(short) 1));
}
generateLeaderAndIsrUpdates("enterControlledShutdown[" + brokerId + "]",
// 处理broker在isr里的分区,将broker从isr中移除,并重新选举leader
brokerId, NO_LEADER, NO_LEADER, records, brokersToIsrs.partitionsWithBrokerInIsr(brokerId));
}
当KRaft写完成,两个记录被应用到内存。
ReplicationControlManager.replay:PartitionChangeRecord应用到内存,基本等于ZK的/brokers/topics/{topic}/partitions/{partitionId}/state,即LeaderAndIsr。
// topicId -> topic信息
private final TimelineHashMap<Uuid, TopicControlInfo> topics;
static class TopicControlInfo {
// topic名
private final String name;
private final Uuid id;
// 分区id -> 分区注册信息
private final TimelineHashMap<Integer, PartitionRegistration> parts;
}
// LeaderAndIsr
public class PartitionRegistration {
public final int[] replicas;
public final Uuid[] directories;
public final int[] isr;
public final int[] removingReplicas;
public final int[] addingReplicas;
public final int[] elr;
public final int[] lastKnownElr;
public final int leader;
public final LeaderRecoveryState leaderRecoveryState;
public final int leaderEpoch;
public final int partitionEpoch;
}
// brokerId在哪些分区的isr里 索引结构
private final BrokersToIsrs brokersToIsrs;
public class BrokersToIsrs {
// brokerId -> topicId -> partitionId
private final TimelineHashMap<Integer, TimelineHashMap<Uuid, int[]>> isrMembers;
}
ClusterControlManager.replay:BrokerRegistrationChangeRecord应用到内存,更新brokerRegistrations注册表。
// broker注册后,这里有数据
private final TimelineHashMap<Integer, BrokerRegistration> brokerRegistrations;
public void replay(BrokerRegistrationChangeRecord record) {
replayRegistrationChange(
record,
record.brokerId(),
record.brokerEpoch(),
fencingChange.asBoolean(),
inControlledShutdownChange.asBoolean(),
directoriesChange
);
}
private void replayRegistrationChange(...) {
BrokerRegistration curRegistration = brokerRegistrations.get(brokerId);
BrokerRegistration nextRegistration = curRegistration.cloneWith(
fencingChange,
inControlledShutdownChange,
directoriesChange
);
if (!curRegistration.equals(nextRegistration)) {
brokerRegistrations.put(brokerId, nextRegistration);
}
}
BrokerHeartbeatResponseEvent:
private class BrokerHeartbeatResponseEvent(response: ClientResponse, timedOut: Boolean,
currentOfflineDirs: Iterable[Uuid]) extends EventQueue.Event {
override def run(): Unit = {
communicationInFlight = false
if (timedOut) {
scheduleNextCommunicationAfterFailure()
return
}
if (response.authenticationException() != null) {
scheduleNextCommunicationAfterFailure()
// 其他失败scheduleNextCommunicationAfterFailure
} else {
val message = response.responseBody().asInstanceOf[BrokerHeartbeatResponse]
val errorCode = Errors.forCode(message.data().errorCode())
if (errorCode == Errors.NONE) {
val responseData = message.data()
currentOfflineDirs.foreach(cur => offlineDirs.put(cur, true))
_state match {
case BrokerState.STARTING =>
if (responseData.isCaughtUp) {
// broker日志追上controller
_state = BrokerState.RECOVERY
initialCatchUpFuture.complete(null)
}
scheduleNextCommunication(NANOSECONDS.convert(10, MILLISECONDS))
case BrokerState.RECOVERY =>
// broker初始化元数据完成
if (!responseData.isFenced) {
initialUnfenceFuture.complete(null)
_state = BrokerState.RUNNING
}
scheduleNextCommunicationAfterSuccess()
case BrokerState.RUNNING =>
// 运行期间的正常心跳
scheduleNextCommunicationAfterSuccess()
case BrokerState.PENDING_CONTROLLED_SHUTDOWN =>
if (!responseData.shouldShutDown()) {
// controller还不允许broker下线
if (!gotControlledShutdownResponse) {
scheduleNextCommunication(NANOSECONDS.convert(50, MILLISECONDS))
} else {
scheduleNextCommunicationAfterSuccess()
}
} else {
// controller将leader迁移完毕,关闭raft线程
beginShutdown()
}
gotControlledShutdownResponse = true
}
} else {
scheduleNextCommunicationAfterFailure()
}
}
}
}
BrokerLifecycleManager.scheduleNextCommunication:成功或失败后,再次发起心跳,间隔broker.heartbeat.interval.ms=2000。
private def scheduleNextCommunicationAfterFailure(): Unit = {
nextSchedulingShouldBeImmediate = false
scheduleNextCommunication(NANOSECONDS.convert(
config.brokerHeartbeatIntervalMs.longValue() , MILLISECONDS))
}
private def scheduleNextCommunicationAfterSuccess(): Unit = {
scheduleNextCommunication(NANOSECONDS.convert(
config.brokerHeartbeatIntervalMs.longValue() , MILLISECONDS))
}
private def scheduleNextCommunication(intervalNs: Long): Unit = {
val adjustedIntervalNs = if (nextSchedulingShouldBeImmediate) 0 else intervalNs
nextSchedulingShouldBeImmediate = false
val deadlineNs = time.nanoseconds() + adjustedIntervalNs
eventQueue.scheduleDeferred("communication",
new DeadlineFunction(deadlineNs),
new CommunicationEvent())
}
private class CommunicationEvent extends EventQueue.Event {
override def run(): Unit = {
if (communicationInFlight) {
nextSchedulingShouldBeImmediate = true
} else if (registered) {
// 注册成功,发送心跳
sendBrokerHeartbeat()
} else {
// 否则注册
sendBrokerRegistration()
}
}
}
QuorumController.registerMaybeFenceStaleBroker:Controller大约每1秒检测一次Broker心跳是否超时。
private void registerMaybeFenceStaleBroker(long fenceStaleBrokerIntervalNs) {
// 自己是leader(Controller)的情况下,定时检测broker心跳
periodicControl.registerTask(new PeriodicTask("maybeFenceStaleBroker",
replicationControl::maybeFenceOneStaleBroker,
// fenceStaleBrokerIntervalNs = 9(broker.session.timeout.ms) / 8 = 1秒
fenceStaleBrokerIntervalNs,
EnumSet.noneOf(PeriodicTaskFlag.class)));
}
ReplicationControlManager.maybeFenceOneStaleBroker:每次只检测一个心跳超时broker。
broker.session.timeout.ms=9000,如果broker超过9秒没发送心跳,将broker隔离。生成LeaderAndIsr和Broker注册变更记录,走Raft写。
ControllerResult<Boolean> maybeFenceOneStaleBroker() {
BrokerHeartbeatManager heartbeatManager = clusterControl.heartbeatManager();
// broker.session.timeout.ms = 9000,超过9s没心跳,隔离broker,
// 一次只处理一个broker
Optional<BrokerIdAndEpoch> idAndEpoch = heartbeatManager.tracker().maybeRemoveExpired();
int id = idAndEpoch.get().id();
long epoch = idAndEpoch.get().epoch();
List<ApiMessageAndVersion> records = new ArrayList<>();
// 生成LeaderAndIsr和Broker注册变更记录
handleBrokerFenced(id, records);
// 内存直接标记broker隔离,不等raft写
heartbeatManager.fence(id);
return ControllerResult.of(records, true);
}
相较于ZK模式,KRaft创建Topic更简单:
ReplicationControlManager.createTopic:quorum-controller单线程处理
private ApiError createTopic(ControllerRequestContext context,
CreatableTopic topic,
List<ApiMessageAndVersion> records,
Map<String, CreatableTopicResult> successes,
List<ApiMessageAndVersion> configRecords,
boolean authorizedToReturnConfigs) {
// 忽略admin自行指定assignment...
int numPartitions = topic.numPartitions() == -1 ?
defaultNumPartitions : topic.numPartitions();
short replicationFactor = topic.replicationFactor() == -1 ?
defaultReplicationFactor : topic.replicationFactor();
// 根据集群现状clusterDescriber,分配分区副本给不同broker
TopicAssignment topicAssignment = clusterControl.replicaPlacer().place(new PlacementSpec(
0,
numPartitions,
replicationFactor
), clusterDescriber);
// 构造分区注册信息,isr=assignment中的存活brokers,leader=isr[0]
for (int partitionId = 0; partitionId < topicAssignment.assignments().size(); partitionId++) {
PartitionAssignment partitionAssignment = topicAssignment.assignments().get(partitionId);
List<Integer> isr = partitionAssignment.replicas().stream().
filter(clusterControl::isActive).toList();
if (isr.isEmpty()) {
return new ApiError();
}
newParts.put(
partitionId,
buildPartitionRegistration(partitionAssignment, isr)
);
}
// topicID = uuid
Uuid topicId = Uuid.randomUuid();
// 响应admin的结果
CreatableTopicResult result = new CreatableTopicResult().
setName(topic.name()).
setTopicId(topicId).
setErrorCode(NONE.code()).
setErrorMessage(null);
successes.put(topic.name(), result);
// 构造raft记录包括TopicRecord/PartitionRecord
records.add(new ApiMessageAndVersion(new TopicRecord().
setName(topic.name()).
setTopicId(topicId), (short) 0));
records.addAll(configRecords);
for (Entry<Integer, PartitionRegistration> partEntry : newParts.entrySet()) {
int partitionIndex = partEntry.getKey();
PartitionRegistration info = partEntry.getValue();
records.add(info.toRecord(topicId, partitionIndex, new ImageWriterOptions.Builder(featureControl.metadataVersionOrThrow()).
setEligibleLeaderReplicasEnabled(featureControl.isElrFeatureEnabled()).
build()));
}
return ApiError.NONE;
}
private static PartitionRegistration buildPartitionRegistration(
PartitionAssignment partitionAssignment,
List<Integer> isr
) {
return new PartitionRegistration.Builder().
setReplicas(Replicas.toArray(partitionAssignment.replicas())).
setDirectories(Uuid.toArray(partitionAssignment.directories())).
setIsr(Replicas.toArray(isr)).
setLeader(isr.get(0)).
setLeaderRecoveryState(LeaderRecoveryState.RECOVERED).
setLeaderEpoch(0).
setPartitionEpoch(0).
build();
}
ControllerWriteEvent,quorum-controller线程处理元数据变更:
public void run() throws Exception {
// 如果curClaimEpoch=-1,代表自己已经不是controller,返回异常
int controllerEpoch = curClaimEpoch;
if (!isActiveController(controllerEpoch)) {
throw ControllerExceptions.newWrongControllerException(latestController());
}
// 1. 生成TopicRecord和PartitionRecord(见5-1)
ControllerResult<T> result = op.generateRecordsAndResult();
if (result.records().isEmpty()) {
//...
} else {
long offset = appendRecords(log, result, maxRecordsPerBatch,
records -> {
int recordIndex = 0;
// 2. 提交到raft线程执行raft写
long lastOffset = raftClient.prepareAppend(controllerEpoch, records);
long baseOffset = lastOffset - records.size() + 1;
for (ApiMessageAndVersion message : records) {
long recordOffset = baseOffset + recordIndex;
try {
// 3. controller不等待HW增加,直接应用到内存
replay(message.message(), Optional.empty(), recordOffset);
} catch (Throwable e) {
throw fatalFaultHandler.handleFault(failureMessage, e);
}
recordIndex++;
}
raftClient.schedulePreparedAppend();
offsetControl.handleScheduleAppend(lastOffset);
return lastOffset;
}
);
op.processBatchEndOffset(offset);
resultAndOffset = ControllerResultAndOffset.of(offset, result);
}
// 4. 客户端响应future放到队列,等HW增加超过这个offset,则调用future.complete响应客户端
if (!future.isDone()) {
deferredEventQueue.add(resultAndOffset.offset(), this);
}
}
KafkaRaftClient.appendBatch:raft线程执行pollLeader
private void appendBatch(
LeaderState<T> state,
BatchAccumulator.CompletedBatch<T> batch,
long appendTimeMs
) {
try {
int epoch = state.epoch();
// 1. 写log
LogAppendInfo info = appendAsLeader(batch.data);
// 2. future=HW增加超过写入offset
OffsetAndEpoch offsetAndEpoch = new OffsetAndEpoch(info.lastOffset(), epoch);
CompletableFuture<Long> future = appendPurgatory.await(
offsetAndEpoch.offset() + 1, Integer.MAX_VALUE);
// 3. 执行commit回调RaftClient.Listener
future.whenComplete((commitTimeMs, exception) -> {
if (exception != null) {
} else {
batch.records.ifPresent(records ->
maybeFireHandleCommit(batch.baseOffset, epoch, batch.appendTimestamp(), batch.sizeInBytes(), records)
);
}
});
} finally {
batch.release();
}
}
这里Follower包含两种角色:
KafkaRaftClient.buildFetchRequest:raft线程执行pollFollower,发送FetchRequest给Controller,参数包括:
private FetchRequestData buildFetchRequest() {
FetchRequestData request = RaftUtil.singletonFetchRequest(
log.topicPartition(),
log.topicId(),
fetchPartition -> fetchPartition
.setCurrentLeaderEpoch(quorum.epoch())
.setLastFetchedEpoch(log.lastFetchedEpoch())
.setFetchOffset(log.endOffset().offset())
.setReplicaDirectoryId(quorum.localDirectoryId())
.setHighWatermark(quorum.highWatermark().map(LogOffsetMetadata::offset).orElse(-1L))
);
return request
.setMaxBytes(MAX_FETCH_SIZE_BYTES)
.setMaxWaitMs(fetchMaxWaitMs)
.setClusterId(clusterId)
.setReplicaState(new FetchRequestData.ReplicaState().setReplicaId(quorum.localIdOrSentinel()));
}
详细内容可以参考上一章源码分析,Leader会根据follower的offset,响应Follower需要截断或需要snapshot,这里仅分析正常同步日志。
KafkaRaftClient#tryCompleteFetchRequest:拉日志,更新高水位,触发高水位回调。
private FetchResponseData tryCompleteFetchRequest(...) {
Optional<Errors> errorOpt = validateLeaderOnlyRequest(request.currentLeaderEpoch());
long fetchOffset = request.fetchOffset();
int lastFetchedEpoch = request.lastFetchedEpoch();
LeaderState<T> state = quorum.leaderStateOrThrow();
final Records records;
if (validOffsetAndEpoch.kind() == ValidOffsetAndEpoch.Kind.VALID) {
// 拉日志
LogFetchInfo info = log.read(fetchOffset, Isolation.UNCOMMITTED);
// 尝试更新高水位
if (state.updateReplicaState(replicaKey, currentTimeMs, info.startOffsetMetadata)) {
// 触发高水位回调
onUpdateLeaderHighWatermark(state, currentTimeMs);
}
records = info.records;
}
}
LeaderState.maybeUpdateHighWatermark:因为Follower发送了自己的写入进度LEO,Leader发现过半Voter副本LEO > 当前HW,更新HW = 过半Voter的副本LEO。
// 副本id(brokerId)和 副本状态
private Map<Integer, ReplicaState> voterStates = new HashMap<>();
// HW
private Optional<LogOffsetMetadata> highWatermark = Optional.empty();
private boolean maybeUpdateHighWatermark() {
// 副本按照offset降序
ArrayList<ReplicaState> followersByDescendingFetchOffset = followersByDescendingFetchOffset()
.collect(Collectors.toCollection(ArrayList::new));
// 获取第 voters.size / 2 的副本 的 offset
int indexOfHw = voterStates.size() / 2;
Optional<LogOffsetMetadata> highWatermarkUpdateOpt = followersByDescendingFetchOffset.get(indexOfHw).endOffset;
if (highWatermarkUpdateOpt.isPresent()) {
LogOffsetMetadata highWatermarkUpdateMetadata = highWatermarkUpdateOpt.get();
long highWatermarkUpdateOffset = highWatermarkUpdateMetadata.offset();
if (highWatermarkUpdateOffset > epochStartOffset) {
// epochStartOffset是leader的起始offset(当时的LEO)
if (highWatermark.isPresent()) {
LogOffsetMetadata currentHighWatermarkMetadata = highWatermark.get();
if (highWatermarkUpdateOffset > currentHighWatermarkMetadata.offset()
|| (highWatermarkUpdateOffset == currentHighWatermarkMetadata.offset() &&
!highWatermarkUpdateMetadata.metadata().equals(currentHighWatermarkMetadata.metadata()))) {
highWatermark = highWatermarkUpdateOpt;
return true;
}
return false;
} else {
highWatermark = highWatermarkUpdateOpt;
return true;
}
}
}
return false;
}
public static class ReplicaState implements Comparable<ReplicaState> {
// brorkerId
private ReplicaKey replicaKey;
private Endpoints listeners;
// 同步进度
private Optional<LogOffsetMetadata> endOffset;
// 上次fetch时间
private long lastFetchTimestamp;
// 上次fetch时,leader的LEO
private long lastFetchLeaderLogEndOffset;
// 上次追上leader的LEO的时间
private long lastCaughtUpTimestamp;
private boolean hasAcknowledgedLeader;
}
KafkaRaftClient.onUpdateLeaderHighWatermark:Leader高水位升高,Leader完成相关future
private void onUpdateLeaderHighWatermark(
LeaderState<T> state,
long currentTimeMs) {
state.highWatermark().ifPresent(highWatermark -> {
// 高水位升高了,可以完成leader创建topic的future,执行commit
appendPurgatory.maybeComplete(highWatermark.offset(), currentTimeMs);
// 高水位变化,也需要通知follower挂起的fetch请求,
// 即使没有新Raft日志,也需要让follower发现高水位升高,从而执行commit
fetchPurgatory.completeAll(currentTimeMs);
});
}
KafkaRaftClient.handleFetchResponse:follower写log,更新hw,触发commit回调。
private boolean handleFetchResponse(
RaftResponse.Inbound responseMetadata,
long currentTimeMs) {
// ...
// 写log
appendAsFollower(FetchResponse.recordsOrFail(partitionResponse));
// 同步leader的hw
OptionalLong highWatermark = partitionResponse.highWatermark() < 0 ?
OptionalLong.empty() : OptionalLong.of(partitionResponse.highWatermark());
updateFollowerHighWatermark(state, highWatermark);
}
private void updateFollowerHighWatermark(
FollowerState state,
OptionalLong highWatermarkOpt
) {
highWatermarkOpt.ifPresent(highWatermark -> {
long newHighWatermark = Math.min(endOffset().offset(), highWatermark);
// 更新hw
if (state.updateHighWatermark(OptionalLong.of(newHighWatermark))) {
// 触发commit回调
log.updateHighWatermark(new LogOffsetMetadata(newHighWatermark));
updateListenersProgress(newHighWatermark);
}
});
}
KafkaRaftClient.updateListenersProgress:高水位变更,触发N个Listener回调,把Raft日志应用到内存。
private void updateListenersProgress(long highWatermark) {
// 处理N个Listener
for (ListenerContext listenerContext : listenerContexts.values()) {
listenerContext.nextExpectedOffset().ifPresent(nextExpectedOffset -> {
// 如果listener已经应用的offset < hw,执行回调
if (nextExpectedOffset < highWatermark) {
LogFetchInfo readInfo = log.read(nextExpectedOffset, Isolation.COMMITTED);
listenerContext.fireHandleCommit(nextExpectedOffset, readInfo.records);
}
});
}
}
Raft写完成应用到内存,走RaftClient.Listener,一共有两个实现:
QuorumMetaLogListener.handleCommit:
public void handleCommit(BatchReader<ApiMessageAndVersion> reader) {
appendRaftEvent("handleCommit[baseOffset=" + reader.baseOffset() + "]", () -> {
try {
boolean isActive = isActiveController();
while (reader.hasNext()) {
Batch<ApiMessageAndVersion> batch = reader.next();
long offset = batch.lastOffset();
int epoch = batch.epoch();
List<ApiMessageAndVersion> messages = batch.records();
if (messages.isEmpty()) {
} else if (isActive) {
// 如果自己是controller,active
// raft写前已经replay到内存,可以deferredEventQueue完成hw前的客户端请求
offsetControl.handleCommitBatch(batch);
deferredEventQueue.completeUpTo(offsetControl.lastStableOffset());
} else {
// 如果自己不是controller,standby,需要replay到内存
int recordIndex = 0;
for (ApiMessageAndVersion message : messages) {
long recordOffset = batch.baseOffset() + recordIndex;
try {
replay(message.message(), Optional.empty(), recordOffset);
} catch (Throwable e) {
throw fatalFaultHandler.handleFault();
}
recordIndex++;
}
offsetControl.handleCommitBatch(batch);
}
}
} finally {
reader.close();
}
});
}
private void replay(ApiMessage message, Optional<OffsetAndEpoch> snapshotId, long offset) {
MetadataRecordType type = MetadataRecordType.fromId(message.apiKey());
switch (type) {
case TOPIC_RECORD:
replicationControl.replay((TopicRecord) message);
break;
case PARTITION_RECORD:
replicationControl.replay((PartitionRecord) message);
break;
// ...
}
}
ReplicationControlManager.replay:TopicRecord和PartitionRecord更新到内存Map。
// topicId -> topic信息 -> 分区信息
private final TimelineHashMap<Uuid, TopicControlInfo> topics;
// topic名 -> topicId
private final TimelineHashMap<String, Uuid> topicsByName;
// brokerId -> topicId -> partitionId
// 快速查询broker在哪些分区的isr里
private final BrokersToIsrs brokersToIsrs;
// brokerId -> topicId -> partitionId --- elr
private final BrokersToElrs brokersToElrs;
public void replay(TopicRecord record) {
Uuid existingUuid = topicsByName.put(record.name(), record.topicId());
topics.put(record.topicId(),
new TopicControlInfo(record.name(), snapshotRegistry, record.topicId()));
}
public void replay(PartitionRecord record) {
TopicControlInfo topicInfo = topics.get(record.topicId());
PartitionRegistration newPartInfo = new PartitionRegistration(record);
PartitionRegistration prevPartInfo = topicInfo.parts.get(record.partitionId());
if (prevPartInfo == null) {
// 新分区
topicInfo.parts.put(record.partitionId(), newPartInfo);
updatePartitionInfo(record.topicId(), record.partitionId(), null, newPartInfo);
updatePartitionDirectories(record.topicId(), record.partitionId(), null, newPartInfo.directories);
updateReassigningTopicsIfNeeded(record.topicId(), record.partitionId(),
false, isReassignmentInProgress(newPartInfo));
} else if (!newPartInfo.equals(prevPartInfo)) {
// 分区变更
topicInfo.parts.put(record.partitionId(), newPartInfo);
updatePartitionInfo(record.topicId(), record.partitionId(), prevPartInfo, newPartInfo);
updatePartitionDirectories(record.topicId(), record.partitionId(), prevPartInfo.directories, newPartInfo.directories);
updateReassigningTopicsIfNeeded(record.topicId(), record.partitionId(),
isReassignmentInProgress(prevPartInfo), isReassignmentInProgress(newPartInfo));
}
if (newPartInfo.hasPreferredLeader()) {
imbalancedPartitions.remove(new TopicIdPartition(record.topicId(), record.partitionId()));
} else {
imbalancedPartitions.add(new TopicIdPartition(record.topicId(), record.partitionId()));
}
}
private void updatePartitionInfo(
Uuid topicId,
Integer partitionId,
PartitionRegistration prevPartInfo,
PartitionRegistration newPartInfo) {
HashSet<Integer> validationSet = new HashSet<>();
Arrays.stream(newPartInfo.isr).forEach(validationSet::add);
Arrays.stream(newPartInfo.elr).forEach(validationSet::add);
brokersToIsrs.update(topicId, partitionId, prevPartInfo == null ? null : prevPartInfo.isr,
newPartInfo.isr, prevPartInfo == null ? NO_LEADER : prevPartInfo.leader, newPartInfo.leader);
brokersToElrs.update(topicId, partitionId, prevPartInfo == null ? null : prevPartInfo.elr,
newPartInfo.elr);
}
TopicControlInfo:可以对应ZK的 /brokers/topics/{topic} 和 /brokers/topics/{topic}/partitions/{partitionId}/state 。
static class TopicControlInfo {
private final String name;
private final Uuid id;
private final TimelineHashMap<Integer, PartitionRegistration> parts;
}
public class PartitionRegistration {
public final int[] replicas;
public final Uuid[] directories;
public final int[] isr;
public final int[] removingReplicas;
public final int[] addingReplicas;
public final int[] elr;
public final int[] lastKnownElr;
public final int leader;
public final LeaderRecoveryState leaderRecoveryState;
public final int leaderEpoch;
public final int partitionEpoch;
}
MetadataLoader.handleCommit:读raft写入的记录(上次commit之后,hw之前),通过n个MetadataPublisher发布给n个组件。
public void handleCommit(BatchReader<ApiMessageAndVersion> reader) {
eventQueue.append(() -> {
try (reader) {
// 1. 读(当前应用的offset, hw)之间的raft记录,组装本次变更delta
while (reader.hasNext()) {
Batch<ApiMessageAndVersion> batch = reader.next();
long elapsedNs = batchLoader.loadBatch(batch, currentLeaderAndEpoch);
}
// 2. 通过MetadataPublisher(s) 发布 最新image 和 delta
batchLoader.maybeFlushBatches(currentLeaderAndEpoch, true);
} catch (Throwable e) {
faultHandler.handleFault();
}
});
}
MetadataBatchLoader.applyDeltaAndUpdate:发布元数据变更,包括最新全量image和变更delta。
private MetadataImage image;
private MetadataDelta delta;
private void applyDeltaAndUpdate(MetadataDelta delta, LogDeltaManifest manifest) {
image = delta.apply(manifest.provenance());
// 回调MetadataPublisher
callback.update(delta, image, manifest);
resetToImage(image);
}
public final void resetToImage(MetadataImage image) {
this.image = image;
this.delta = new MetadataDelta.Builder().setImage(image).build();
this.lastOffset = image.provenance().lastContainedOffset();
this.lastEpoch = image.provenance().lastContainedEpoch();
this.lastContainedLogTimeMs = image.provenance().lastContainedLogTimeMs();
this.numBytes = 0;
this.numBatches = 0;
this.totalBatchElapsedNs = 0;
}
MetadataImage:全量Image,即全量元数据,包括:TopicsImage-Topic元数据、ClusterImage-集群元数据(broker和controller集合)。
public record MetadataImage(MetadataProvenance provenance,
FeaturesImage features, ClusterImage cluster,
TopicsImage topics, ConfigurationsImage configs, ClientQuotasImage clientQuotas,
ProducerIdsImage producerIds, AclsImage acls, ScramImage scram,
DelegationTokenImage delegationTokens) {
}
public record ClusterImage(
Map<Integer, BrokerRegistration> brokers,
Map<Integer, ControllerRegistration> controllers) {}
public class BrokerRegistration {
private final int id;
private final long epoch;
private final Uuid incarnationId;
private final Map<String, Endpoint> listeners;
}
public record TopicsImage(ImmutableMap<Uuid, TopicImage> topicsById,
ImmutableMap<String, TopicImage> topicsByName) {}
public record TopicImage(String name,
Uuid id, Map<Integer, PartitionRegistration> partitions) {}
MetadataBatchLoader.loadBatch:针对当前全量MetadataImage + raft记录,可以得到MetadataDelta增量变更。
private MetadataDelta delta;
public long loadBatch(Batch<ApiMessageAndVersion> batch,
LeaderAndEpoch leaderAndEpoch) {
for (ApiMessageAndVersion record : batch.records()) {
replay(record);
}
}
private void replay(ApiMessageAndVersion record) {
delta.replay(record.message());
}
public final class MetadataDelta {
// 变更前的image
private final MetadataImage image;
// cluster变更
private ClusterDelta clusterDelta = null;
// topic变更
private TopicsDelta topicsDelta = null;
}
public final class TopicsDelta {
// 变更前topic元数据
private final TopicsImage image;
// 变更的topic
private final Map<Uuid, TopicDelta> changedTopics = new HashMap<>();
}
BrokerMetadataPublisher:Broker角色处理元数据的核心类。
override def onMetadataUpdate(
delta: MetadataDelta,
newImage: MetadataImage,
manifest: LoaderManifest): Unit = {
// KRaftMetadataCache缓存Image
metadataCache.setImage(newImage)
if (_firstPublish) {
// 首次加载元数据,触发LogManager初始化,数据恢复
initializeManagers(newImage)
}
// topic元数据变更
Option(delta.topicsDelta()).foreach { topicsDelta =>
replicaManager.applyDelta(topicsDelta, newImage)
}
// ...
}
ReplicaManager.applyDelta:topic变更,发现自己成为新分区leader或follower,执行makeLeader或makeFollower(ZK模式正常逻辑)。
def applyDelta(delta: TopicsDelta, newImage: MetadataImage): Unit = {
val localChanges = delta.localChanges(config.nodeId)
val metadataVersion = newImage.features().metadataVersionOrThrow()
replicaStateChangeLock.synchronized {
if (!localChanges.leaders.isEmpty || !localChanges.followers.isEmpty) {
// 如果自己是某些分区leader,停止fetch,makeLeader
if (!localChanges.leaders.isEmpty) {
applyLocalLeadersDelta(leaderChangedPartitions, delta, lazyOffsetCheckpoints, localChanges.leaders.asScala, localChanges.directoryIds.asScala)
}
// 自己是某些分区follower,开始向leader发送fetch,makeFollower
if (!localChanges.followers.isEmpty) {
applyLocalFollowersDelta(followerChangedPartitions, newImage, delta, lazyOffsetCheckpoints, localChanges.followers.asScala, localChanges.directoryIds.asScala)
}
}
}
// ...
}
客户端向配置bootstrap.servers中的任意Broker角色节点,发送MetadataRequest请求获取必要元数据。
KafkaApis.handleTopicMetadataRequest:Broker处理请求,获取topic和broker元数据。
def handleTopicMetadataRequest(request: RequestChannel.Request): Unit = {
//...
// topics
val topicMetadata = getTopicMetadata(request, ...)
// ...
// brokers
val brokers = metadataCache.getAliveBrokerNodes(request.context.listenerName)
}
KafkaApis.getTopicMetadata:获取Topic元数据,如果不存在则调用controller创建。
private def getTopicMetadata(...): Seq[MetadataResponseTopic] = {
// 1. 获取缓存元数据
val topicResponses = metadataCache.getTopicMetadata(topics.asJava, listenerName,
errorUnavailableEndpoints, errorUnavailableListeners)
// 2. topic不存在 转发到controller自动创建topic
val nonExistingTopics = topics.diff(topicResponses.asScala.map(_.name).toSet)
autoTopicCreationManager.createTopics(nonExistingTopics, controllerMutationQuota, Some(request.context))
topicResponses.asScala ++ nonExistingTopicResponses
}
KRaftMetadataCache.getTopicMetadata:从Raft复制得到的内存MetadataImage获取Topic元数据。
@volatile private var _currentImage: MetadataImage = MetadataImage.EMPTY
override def getTopicMetadata(topics: util.Set[String],...):
util.List[MetadataResponseTopic] = {
val image = _currentImage
topics.stream().flatMap(topic =>
// ...
).collect(Collectors.toList())
}
KRaftMetadataCache.getAliveBrokerNodes:同理获取Broker元数据,过滤fenced节点返回。
override def getAliveBrokerNodes(listenerName: ListenerName): util.List[Node] = {
_currentImage.cluster.brokers.values.stream
.filter(Predicate.not(_.fenced)) // fenced即心跳超时的broker
.flatMap(broker => broker.node(listenerName.value).stream)
.collect(Collectors.toList())
}
简单总结Topic创建:
BrokerRegistrationRequest,Controller把Broker注册信息写入Raft,返回broker epoch = Raft记录的offset,这代替了ZK模式中,Broker Epoch临时ZNode= /brokers/{brokerId} 的事务ID;BrokerHeartbeatRequest,默认间隔broker.heartbeat.interval.ms=2000。刚启动时 Broker 先处于 FENCED,只有Broker复制进度 追上注册记录对应的 offset,才会转成 UNFENCED,解除隔离正式上线;broker.session.timeout.ms=9000,Broker超过 9 秒没心跳就会被重新 FENCED,Controller 构造 BrokerRegistrationChangeRecord、PartitionChangeRecord,执行Raft写并更新内存Broker元数据;CreateTopicsRequest 时,Controller 基于这份 Broker 视图来分配副本,初始化分区ISR和Leader,生成 TopicRecord 和 PartitionRecord,执行Raft写更新内存Topic元数据;MetadataImage不可变对象,这些 Raft Record 写入并提交后,各 Broker 通过 MetadataLoader 合并Raft记录和当前MetadataImage生成新的MetadataImage不可变对象。MetadataPublisher发布元数据,Broker 生成 Log 并 执行 leader/follower 切换,MetadataImage 保存在KRaftMetadataCache中;MetadataRequest 从KRaftMetadataCache的MetadataImage获取Topic和Broker元数据;
