恐怖解谜密室逃脱
109.73M · 2026-03-09

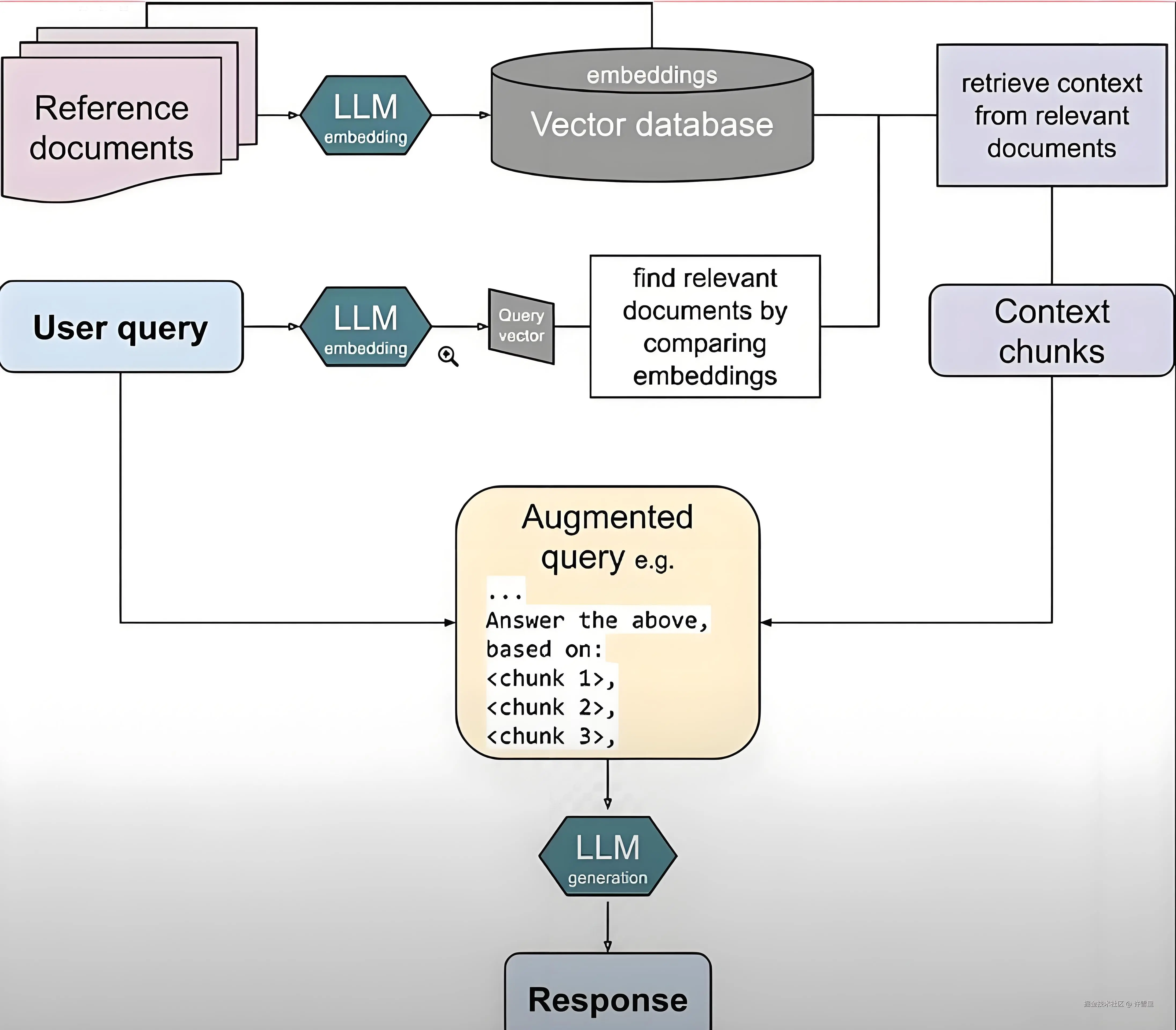
RAG(Retrieval-Augmented Generation,检索增强生成)是一种结合信息检索与文本生成的先进AI架构,其核心在于让大语言模型在回答问题前,先从外部知识库中“查找资料”,再基于查到的信息生成准确、有依据的回答。这种方法有效缓解了大模型常见的知识过时、幻觉等问题。
RAG的工作流程可分为三个关键阶段:数据准备 → 检索 → 生成,形成一个“先查后答”的闭环机制。
RAG的准确率瓶颈本质上是“检索上下文质量”的瓶颈。如果检索不到正确信息,再强的生成模型也无法给出正确答案。
RAG因其灵活性和高准确性,已在多个领域实现落地应用,尤其适合需要专业性、实时性、可解释性的场景。
RAG的核心技术组成主要包括以下几个关键部分:
上述组件协同工作,使得RAG能够在保持大语言模型强大生成能力的同时,通过外部知识库提供更准确、更可靠的问答结果。 本文选型 “Milvus(向量数据库)、Qwen(生成模型)、Qwen-embedding(嵌入模型)及SpringAI” 讲述及实践。
向量数据库是专门用于存储、管理和高效检索高维向量数据的新型数据库系统,它能将文本、图像、音频等非结构化数据,通过AI模型转化为蕴含语义特征的向量序列,再基于向量间的相似度实现“语义级检索”,解决传统数据库在非结构化数据处理上的局限性,为RAG智能问答、多模态搜索、智能推荐等AI应用提供底层支撑。
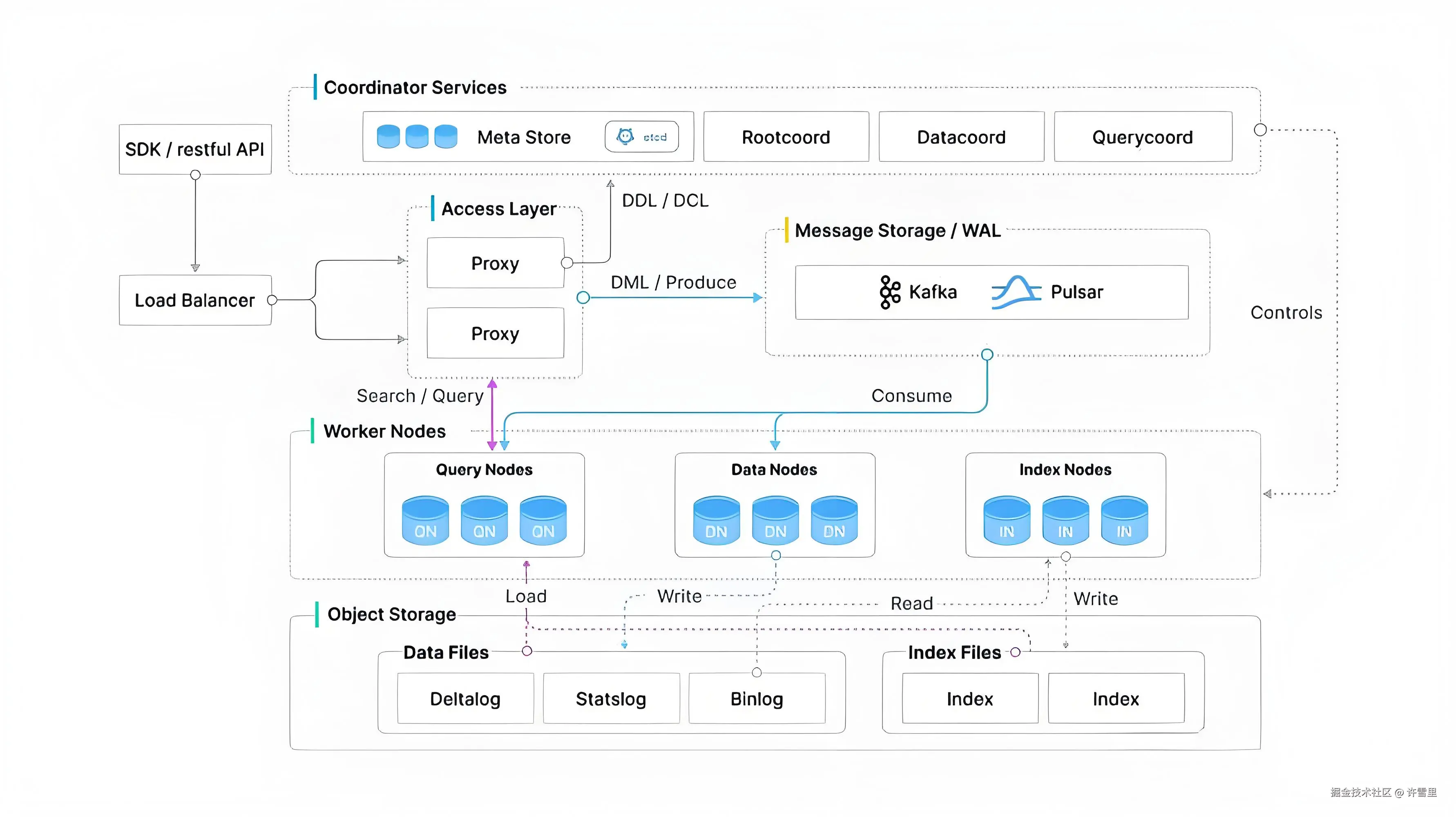
Milvus 是一款专为高维向量数据设计的云原生向量数据库,广泛应用于人工智能、机器学习和相似性搜索场景。它采用存储与计算分离的架构,具备高可用性、高性能和弹性扩展能力。
Milvus 的系统架构分为四个主要层次:
| 维度 | Milvus | 关系型数据库 | 说明 |
|---|---|---|---|
| 数据组织结构 | Database → Collection → Partition → Segment → Entity | Database → Table → Row | Milvus 以 Segment 为最小存储单元,支持分片;关系库以页或块为单位 |
| 存储介质 | 对象存储(S3/MinIO)+ 元数据存储(etcd)+ 消息队列(Pulsar/Kafka) | 磁盘文件 + 日志(Redo Log) | Milvus 使用对象存储持久化数据,元数据由 etcd 管理;关系库依赖本地存储 |
| 索引机制 | 支持多种 ANN 索引(HNSW、IVF、FLAT 等) | B-tree、Hash、Bitmap 等 | Milvus 为高维向量优化索引,支持近似搜索;关系库为低维结构化字段设计 |
| Milvus 术语 | 关系型数据库术语 | 说明 |
|---|---|---|
| Database | Database | 数据库是组织和管理数据的逻辑单元。为了提高数据安全性并实现多租户,你可以创建多个数据库,为不同的应用程序或租户从逻辑上隔离数据。Milvus 在集合之上引入了数据库层,为管理和组织数据提供了更有效的方式,同时支持多租户 |
| Collection | Table | 数据集合,定义字段结构。用于存储和管理实体的主要逻辑对象。 |
| Partition | Partition | 集合内的物理分区 |
| Segment | Page / Block | 定义数据类型和数据属性的元信息。每个 Collections 都有自己的 Collections Schema,该 Schema 定义了 Collections 的所有字段、自动 ID(主键)分配启用和 Collection 说明 |
| Field | Column | 字段类型支持标量与向量 |
| Entity | Row | 单条数据记录 |
| Index | Index | 向量索引,类型多样 |
Milvus 提供了 Docker Compose 配置文件:
wget -O docker-compose.yml
sudo docker compose up -d
Creating milvus-etcd ... done
Creating milvus-minio ... done
Creating milvus-standalone ... done
启动完成后可以访问 Milvus WebUI网址( )了解有关 Milvus 实例的更多信息。
Attu是 Milvus 官方推出的图形化管理工具,提供直观的可视化界面,方便用户查看和管理向量数据库。通过 Attu,用户可以轻松完成数据库架构设计、数据操作、向量搜索等复杂任务,大大降低 Milvus 的使用门槛。
docker run -d --name milvus-attu
-p 8000:3000
-e MILVUS_URL=localhost:19530
zilliz/attu:v2.6
Attu 启动完成后可以访问( ),以图形化方式查看和管理Milvus 实例。
RAG系统依赖Embedding与Generation两类模型:
本文分别选择 “qwen3-embedding” 与 “qwen3.5” 作为嵌入模型与生成模型,Ollama本地安装如下;
admin@Mac-miniM4 milvus % ollama list
NAME ID SIZE MODIFIED
qwen3.5:2b 324d162be6ca 2.7 GB 3 hours ago
qwen3-embedding:0.6b ac6da0dfba84 639 MB 4 hours ago
RAG 知识库的核心价值在于「结构化检索(关系型)+ 语义检索(向量)」的融合,实体模型设计需同时兼顾关系型数据的结构化关联能力和向量数据的语义匹配能力,既要保证实体间的逻辑关联清晰,又要实现基于语义的精准检索。以下聚焦「关系型 + 向量数据融合」的实体模型设计,包含核心实体定义、数据存储分工、关联逻辑、落地实现四大核心模块。
实体分工总览:
| 数据类型 | 存储载体 | 存储内容 | 核心作用 |
|---|---|---|---|
| 关系型数据 | MySQL/PostgreSQL | 文档 / Chunk / 业务实体的元数据、实体间关联关系、检索过滤字段(状态 / 租户 / 类型) | 结构化筛选、实体关联、结果回溯 |
| 向量数据 | Milvus/PGVector/FAISS | Chunk 的 Embedding 向量、向量索引(IVF_FLAT/HNSW) | 语义相似度检索 |
关系型实体表设计(核心元数据 + 关联):
Knowledge(知识库实体,关系型):存储知识库定义元数据,维护知识库Embedding模型、向量数据库设置信息。
Document(文档实体,关系型):存储文档级结构化元数据,是所有子实体的根节点,不存储完整内容和向量。
Chunk(文本块实体,关系型): 存储 Chunk 的元数据,仅保留向量 ID(与向量库绑定),不存储原始向量,是关系型与向量数据的核心桥梁。
向量数据模型设计(语义检索核心): Milvus 中创建「knowledge_vector_collection」集合,与关系型 Chunk 表的vector_id一一对应:
使用SpringAI进行模型与向量数据库集成,需要添加如下依赖:
<!-- milvus -->
<dependency>
<groupId>io.milvus</groupId>
<artifactId>milvus-sdk-java</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-ollama</artifactId>
</dependency>
核心流程为:「文档分块 → 向量化 → Milvus 入库」
// 1、初始化Embedding模型
EmbeddingModel embeddingModel = OllamaEmbeddingModel
.builder()
.defaultOptions(OllamaEmbeddingOptions
.builder()
.model(EMBEDDING_MODEL_NAME)
.dimensions(VECTOR_DIMENSION)
.build())
.ollamaApi(ollamaApi)
.build();
// 2、知识文档正文分块
List<String> chunks = splitDocument(doc.getContent());
// 3、Chunk文档向量化处理
List<float[]> vectors = embeddingModel.embed(texts);
// 4、知识数据向量化入库
List<JsonObject> vectorData = process(vectors);
UpsertResp upsertResp = client.upsert(UpsertReq.builder()
.collectionName(collectionName)
.data(vectorData)
.build());
核心流程为:「问题向量化 → Milvus 检索」
// 1、问题向量化
float[] keywordVector = embed(List.of(keyword)).get(0);
// 2、向量 检索
SearchReq searchReq = SearchReq.builder()
.collectionName(buildCollectionName(kbId))
.data(Collections.singletonList(new FloatVec(keywordVector)))
.annsField("contentVector")
.outputFields(Arrays.asList("id", "chunkId", "contentVector"))
.limit(TOP_K_COUNT)
.searchParams(Map.of("radius", SIMILARITY_THRESHOLD)) // 相似度阈值
.build();
SearchResp searchResp = client.search(searchReq);
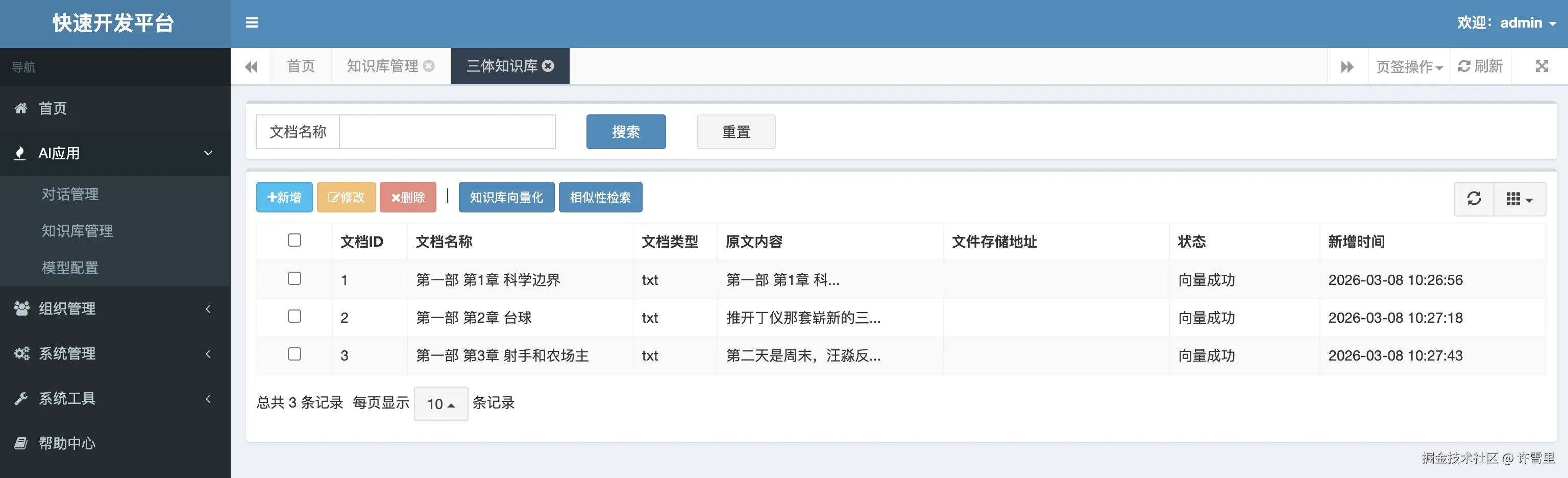
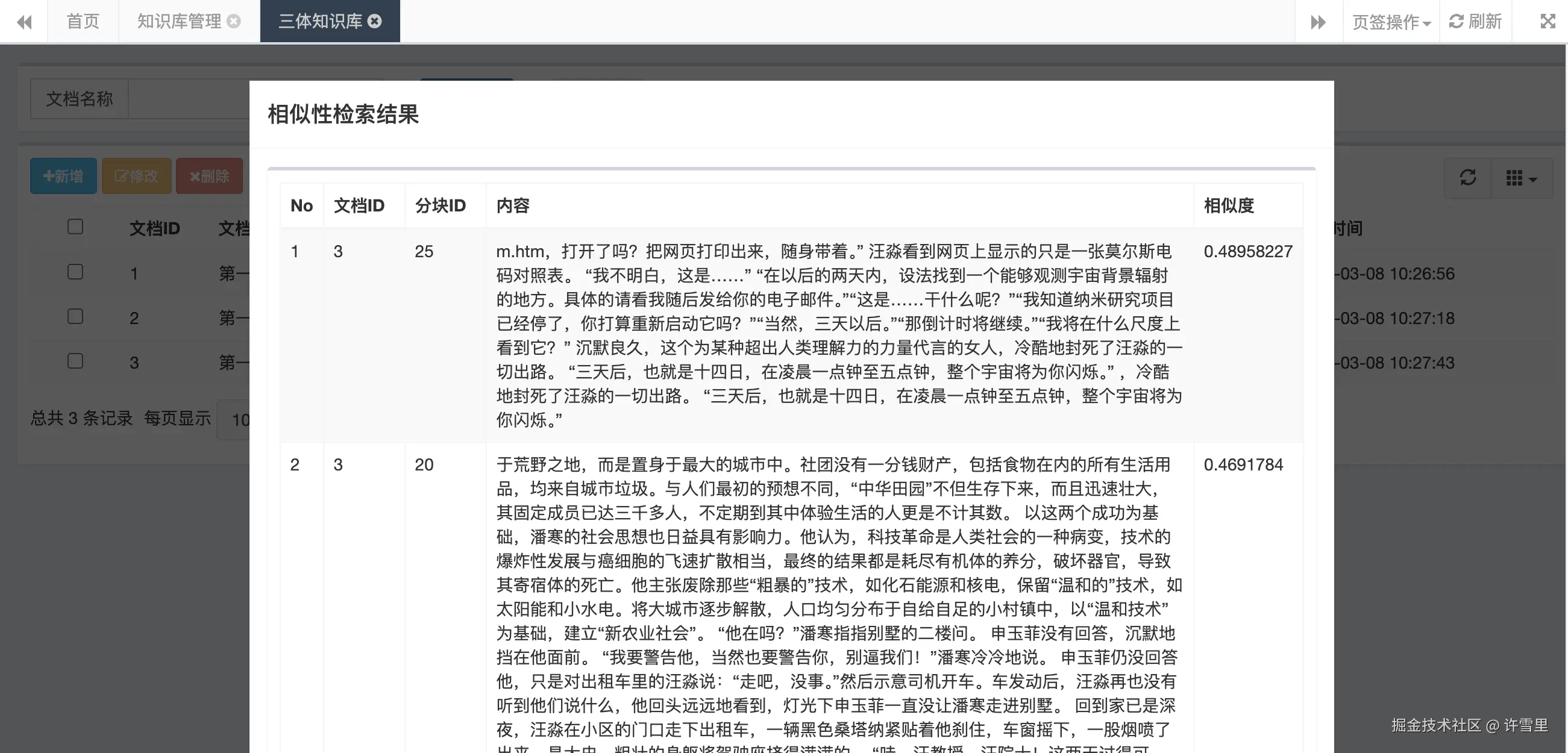
知识库系统交互见下文,支持针对文档进行新建、管理、向量化/Embedding、相似度检索等操作。为RAG、 部分截图如下: