







哈曼卡顿Harman Kardon One(哈曼卡顿智能音箱)
156.1MB · 2026-03-12

TRAE 国际版于 2 月 24 日正式上线新版计费方式后,我们收到的高频反馈之一是:为什么 Token 消耗得这么快?一段看似简单的对话,却对应了不低的 Dollar Usage,让不少同学在使用时难免有所顾虑。
在既定用量套餐下,如何更高效、更精细地使用 AI,将预算真正用在「刀刃」上?本文将从两个基础而关键的概念:「Token」和「上下文窗口」切入,帮助大家先理解用量消耗的原理,理解了 Token 消耗的原理后,我们就能对症下药,系统性地节省开销。
你可能在 AI Coding 过程中有过这些困惑:
只是让 AI 帮忙改个 Bug,怎么就消耗了这么多额度?
聊着聊着,AI 为什么突然“忘记”了我们刚刚说过的话?
为什么有时候用中文提问,反而比用英文更“贵"?
这些问题看似不同,但都围绕着一个核心概念:Token。理解 Token,就是掌握“降本增效”的关键。
Token 不是一个抽象的技术名词。它直接决定了:每次使用大模型完成一个任务要花多少钱,同样的输入能否获得的优质回答,AI 在工作过程中会不会在聊到一半时突然变“傻”,一秒健忘
这不是一个抽象的技术名词,它直接决定了你每次使用 AI 工具时要花多少钱、能获得多好的回答质量、以及 AI 会不会在聊到一半时突然变“傻”。理解 Token,就是掌握“降本增效”的关键。
在理解 Token 之前,我们先来弄清楚 AI 是怎么“写”出代码的。
想象一下,各种类型的 AI 工具,它们工作的核心原理都可以用一句话来概括:根据你已经给出的内容,预测下一个最可能出现的字词。
第一步:理解输入
第二步:预测下一个词
基于输入,计算每个词出现的概率
例如:def 概率 80%,function 概率 15%
选择概率最高的 def
第三步:更新 context,继续预测
context 变成:“帮我写一个 Python 排序函数 def”
再次预测,选择 sort_list
第四步:重复直到完成
继续生成 **( **、 **) **、 **: **等
直到生成完整函数
AI 就像打字机一样,一个词一个词地“蹦”出来,直到生成完整的函数。这一个个词,就是我们今天要聊的 Token。 这个过程叫做自回归生成(Autoregressive Generation) 。它有一个关键特点:每输出一个新词,都要重新“看”一遍之前所有的内容(你的输入 + 它已生成的部分)。这也解释了为什么 AI 的回答是逐字出现的。
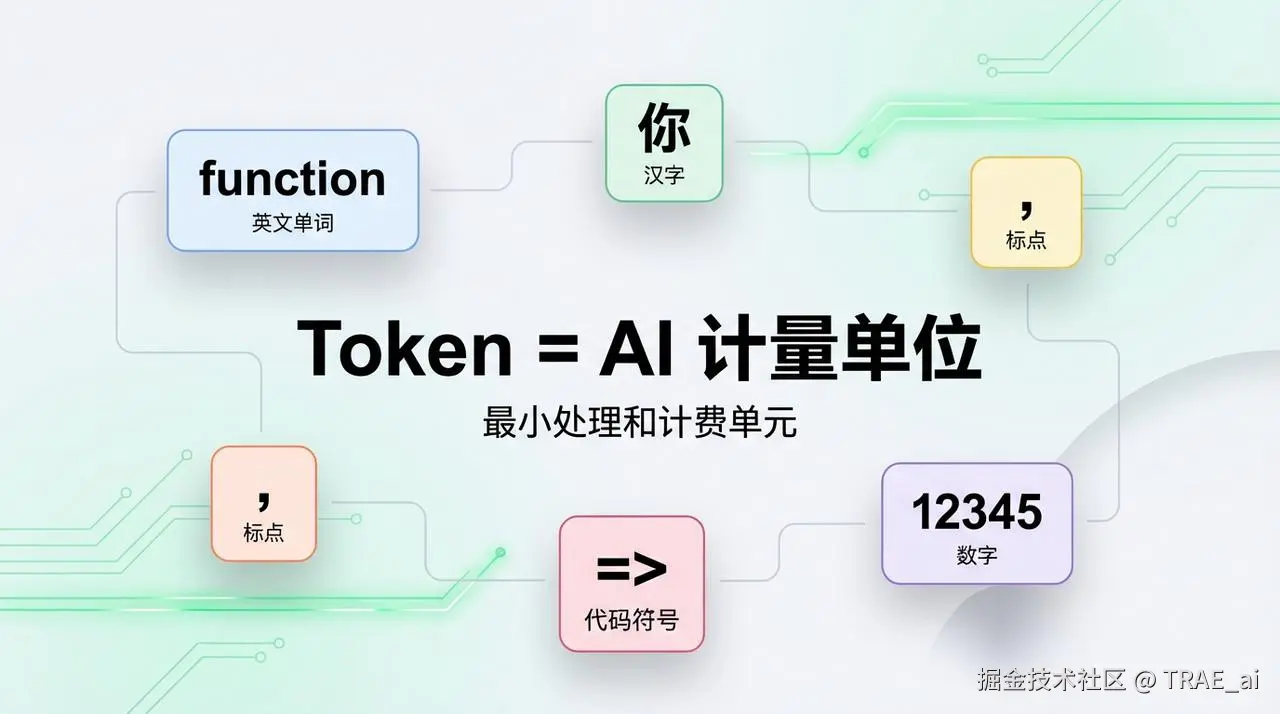
简单来说:Token 是 AI 处理文本的最小单位,也是它计费的“货币”。
AI 不直接阅读人类文字,而是先把文字拆成一个个 Token,再进行处理。你可以把 Token 理解为 AI 世界的“最小阅读单元”。
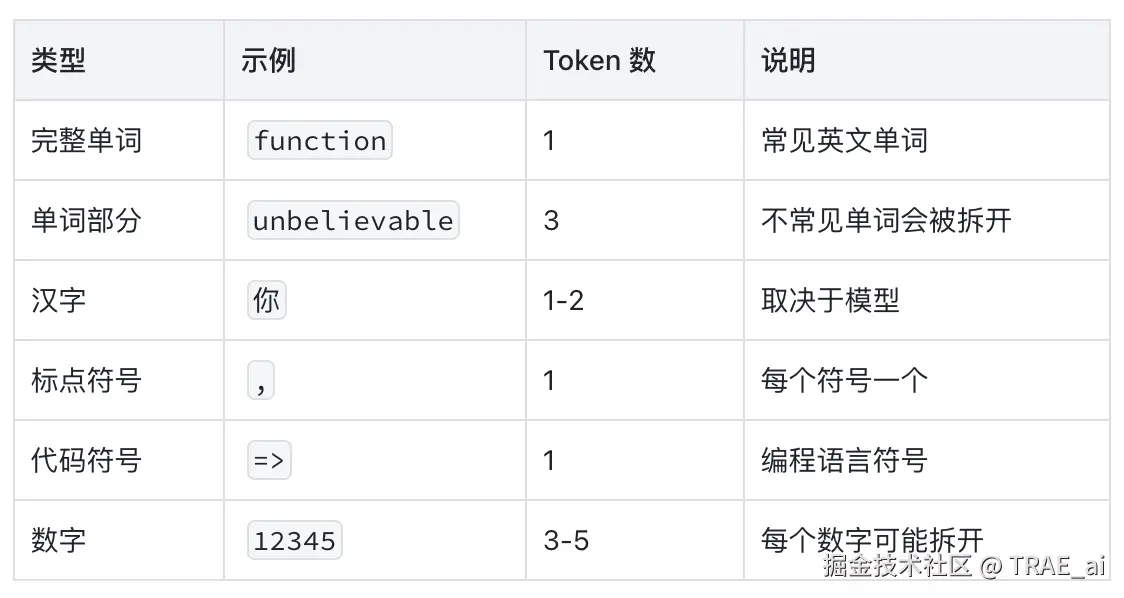
一个 Token 可能是:
这个“拆字”的过程叫做分词(Tokenization) ,是 AI 处理任何文本的第一步。现代大语言模型几乎都采用一种叫做 BPE(Byte Pair Encoding,字节对编码) 的分词算法。大家感兴趣的可以自行检索了解,这里就不过多赘述原理了。
对于 AI 的工作量来说,不论是理解你的问题,还是为你生成答案,都会按照 Token 计费。
所以每次你和 AI 互动,共包括 2 个费用:
输入 Token: 你发给 AI 的所有内容。
输出 Token: AI 回答给你的内容。
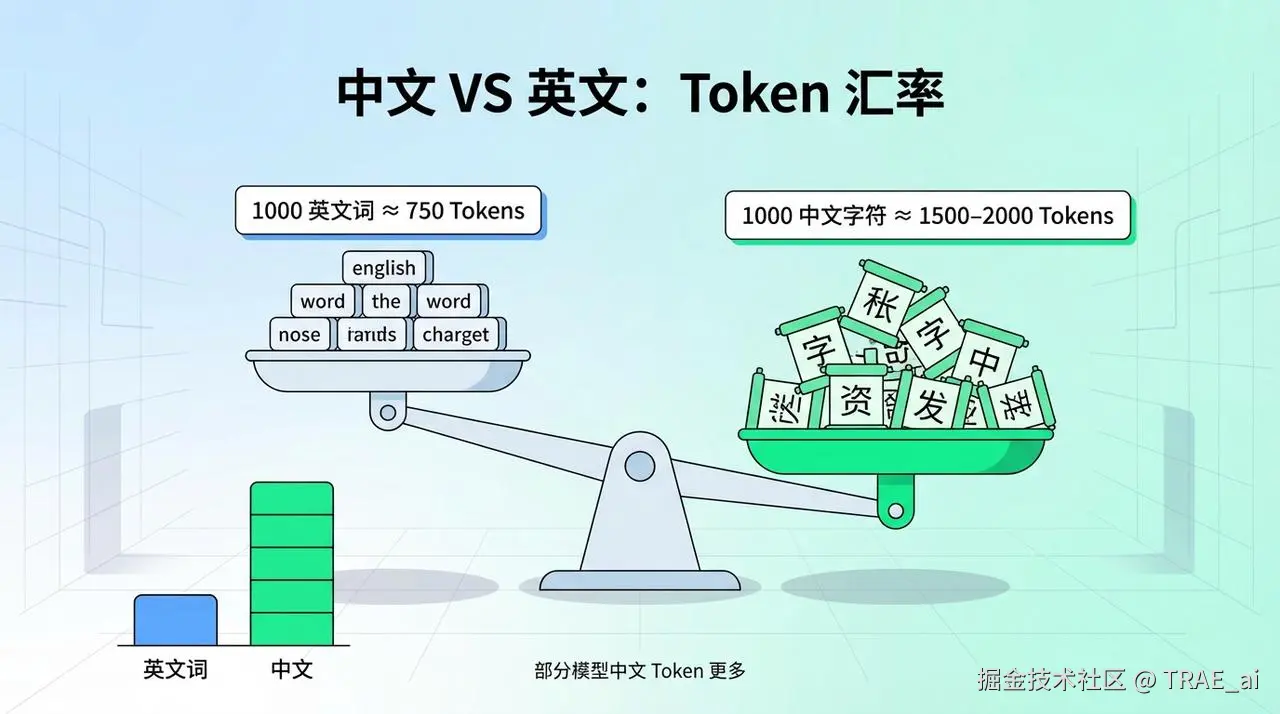
一个让中文用户比较“吃亏”的事实:对于 GPT 这类主要用英文语料训练的模型,处理中文的 Token 效率更低。
1000 个英文单词 ≈ 750 Tokens
1000 个中文字符 ≈ 1500-2000 Tokens
同样的意思,用中文表达消耗的 Token 几乎是英文的 2 倍。
但是现在我们的国产模型,例如 Doubao 等已经解决了这个问题,处理中文的效率和英文是基本相当的。
这里的核心原因:
训练数据分布 LLM 主要在英文文本上训练,英文的 tokenize 策略更优
词表设计,英文词表通常包含常见单词,中文词表需要覆盖更多字符
理解了 Token 的概念,我们来看另一个关键概念:上下文窗口(Context Window)。
上下文窗口就是 AI 一次能处理的最大 Token 数量(输入+输出),相当于 AI 的“工作台大小”。
你可以把上下文窗口想象成一条传送带:
传送带长度:模型的上下文窗口大小(比如 128K 或 200K Tokens)
传送的货物:你和 AI 交流的所有信息(问题、代码、对话历史等)
对话时,新内容不断传到带上。如果货物太多,最前面的货物会被挤下去,AI 就看不见了。这就是 AI “失忆”的真相:不是真的忘了,而是传送带满了,早期的内容被“挤”出去了。
这就是大家常常说 AI 为什么会“失忆”的原因。
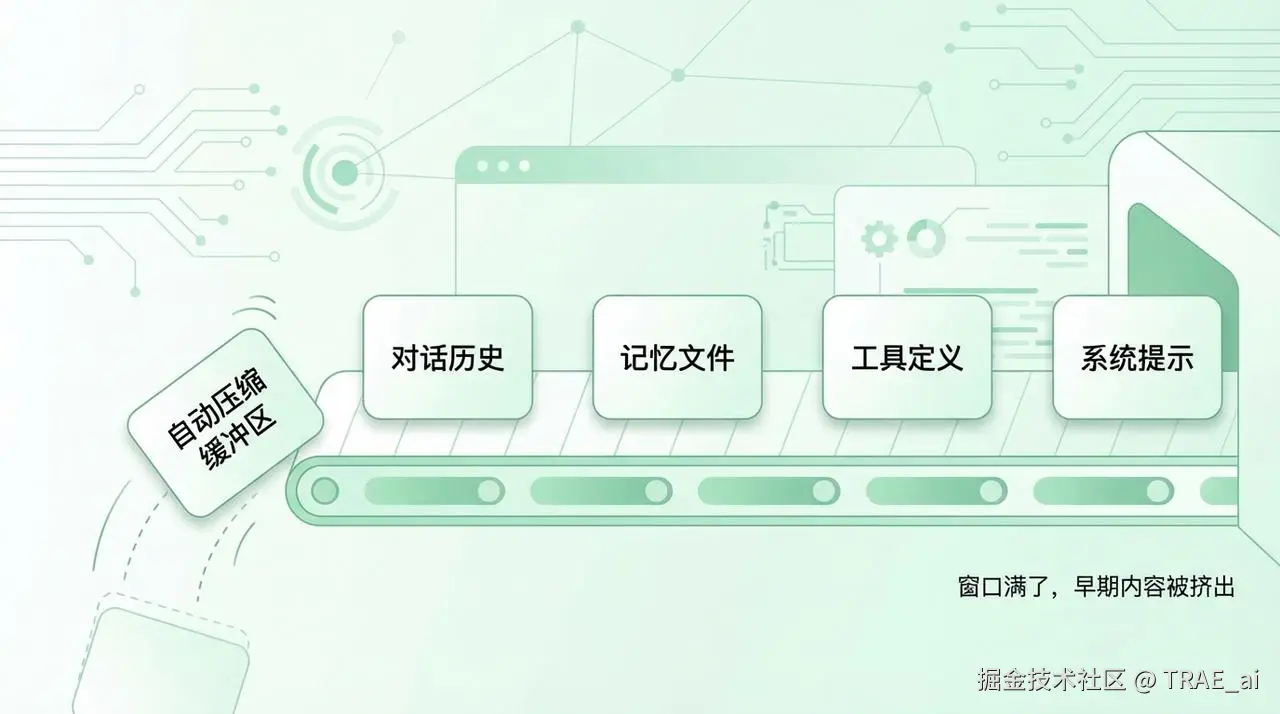
一个常常被忽略的真相是:你以为上下文窗口是空的,随时可用,但实际上,在你输入第一个字之前,它就已经被各种“系统文件”占用了很大一部分。
这张“桌子”上,除了你的对话,还必须摆放这些东西:
系统提示 (System Prompt): 定义 AI 角色和行为准则的“说明书”。这个占比较少。
工具定义 (Tool Definitions):AI 能使用的各种工具(如读文件、上网搜索)的详细说明书。这个占据了大头。
记忆文件 (Memory Files): 关于项目背景、你的个人偏好等的“备忘录”。
对话历史 (Chat History): 为了保持对话连贯,每一轮的交流都得摆上桌。
自动压缩缓冲区: 系统为管理对话而预留的“应急空间”。
你还没有开始正式进入 Coding 工作,可能你的上下文已经被占据了一大部分。
虽然现在主流模型的上下文窗口已经很大(128K、200K),但这并不意味着把越多东西塞进去越好。原因有三个:
AI 的核心机制是注意力(Attention),它会“看”上下文中的每个 Token,计算它们之间的相关性。但注意力是有限资源。当传送带上的“货物”太多时,AI 难以准确判断哪些信息重要,关键信息容易被淹没在噪音中,回答质量反而下降。
更大的上下文窗口意味着更高的计算成本,你需要为更多的 Token 付费。Attention 的计算量是 O(n²),窗口越大,计算量呈平方级增长。
窗口越大,生成每个词需要等待的计算时间越长,响应速度变慢。所以关键不是“塞更多”,而是“塞对的东西”,让 AI 看到最有价值的信息。
如果你觉得和 AI 聊天已经很耗 Token,那么使用 Coding Agent(或称 Agent 模式)的消耗则完全是另一个量级。
普通聊天是“一问一答”,而 Coding Agent 更像一个自主工作的初级程序员。当你给它一个任务,比如“修复这个 Bug”,它会在后台执行一连串你看不见的操作:
加载“大脑”和“工具箱”: 载入系统提示和所有可用的工具定义。
阅读和理解: 搜索并读取大量相关代码文件、配置文件和依赖项,以理解项目全貌。
思考和规划: 在内部进行多轮推理,制定解决问题的计划。
动手尝试: 生成代码、执行测试、分析结果。
循环纠错: 如果失败,它会分析错误日志,再次阅读代码,然后重新尝试。
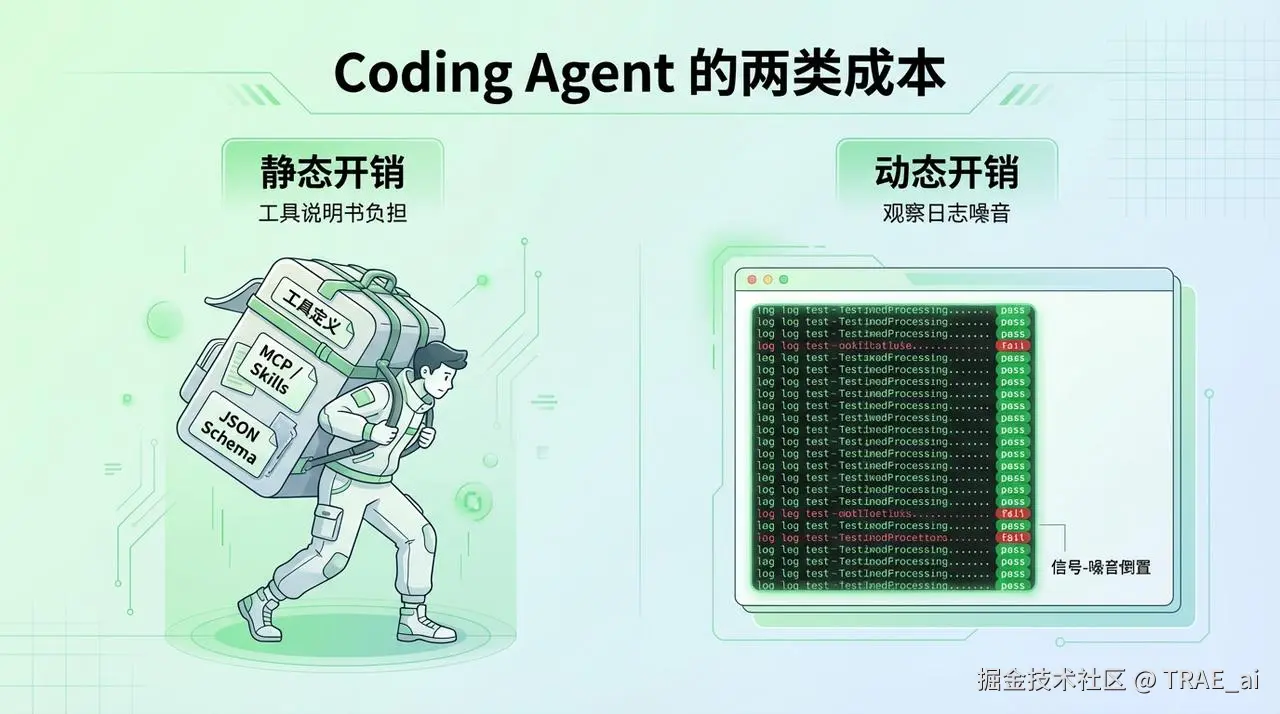
这些消耗主要来自两个方面: 【静态开销】 和 【 动态开销】 。
每个工具都需要一份详细的“说明书”(JSON Schema),告诉 AI 这个工具叫什么、能做什么、需要哪些参数。如果你的 AI 连接了大量工具,这些“说明书”会变得极其臃肿。
如何解决?
精简你的工具箱: 定期检查并删除那些不常用的 MCP 工具或 Skill。这是最立竿见影的办法。
优先使用“轻量化”工具: 一些新的技术方向,如 CLI 化工具和 Skill 的按需加载机制,正致力于解决这个问题。它们不再一次性把所有“说明书”都塞给 AI,而是只在需要时才加载,极大地节约了静态开销。随着 Skill 市场繁荣,如果同时有 Skill 和 MCP 可选,优先用 Skill。
Agent 是 【思考-行动-观察】 的循环中工作,而 【观察环节】 最容易产生噪音。
这里举一个典型的例子:假设 Agent 跑了一轮测试,结果是 97 个通过(pass),3 个失败(fail)。
噪音: 97 个成功用例会各自输出一堆日志,如“test_xxx passed”,占用了测试输出 99% 的篇幅。这些对 AI 的下一步决策几乎毫无帮助。
信号: 真正有价值的,是那 3 个失败用例的错误信息。
如何解决?
过滤噪音: 为 AI 定制专用的测试脚本,让它只输出失败的用例和关键错误信息。
积累经验: 把解决过的问题、项目的架构决策、关键的脚本等沉淀为 AI 可读的“经验文档”(例如 AGENTS.md 或结构化的 **docs/ **目录)。这样,AI 在下次遇到类似问题时,可以直接查阅“笔记”,而不是每次都从零开始“摸索”。
目标驱动裁剪: 这是更前沿的思路,让 AI 在读取文件时,先明确“阅读目标”(比如“只查找错误处理相关的代码”),然后用一个轻量级模型提前“预筛选”一遍,只把最相关的几行代码送入主模型的上下文。这就像一个经验丰富的开发者,会带着问题去扫读代码,而不是逐行精读。
管理 Token 和上下文,就像优秀的程序员管理内存一样,是一种可以让 AI 更好地为你服务的核心技能。它并非要求你放弃便利、处处节省,而是鼓励你更聪明地与 AI 协作。
当你下一次看到高昂的 Token 消耗时,不妨停下来想一想:是我的问题太模糊,还是任务范围太大了?我是不是可以用更简单的方式解决?
举个例子,大家看完这个文章之后,可以立即去编辑器里检查一下有没有某个 MCP 服务是一个星期内,从来没有用过的,直接删掉吧!
下一篇我们将直接为大家带来【如何在 TRAE 中高效节省 Token 的实操技巧】,不见不散!
156.1MB · 2026-03-12
31.0MB · 2026-03-12
117.49M · 2026-03-12
Vite 凭什么比 Webpack 快50%?揭秘闪电构建背后的黑科技
我用 OpenClaw 搭了一套运营 Agent,每天自动生产内容、分发、追踪数据——独立开发者的运营平替

