
意项
39.91M · 2026-03-23

最近刚好看到了一篇名为 《Real Money, Fake Models: Deceptive Model Claims in Shadow APIs》 的论文,翻译过来就是《真金白银,假货模型:Shadow API 中的欺骗性模型声明》,这对于当前 AI 市场来说是非常常见的一个情况,你以为你买的中转商是 Claude 性价比很高,实际上你用的可能只是便宜的 DeepSeek 中转 。
现实里相信大家都知道,很多前沿闭源模型存在价格高、支付门槛、地区限制等问题,于是出现了一批第三方“代接入”服务,声称提供的 GPT、Gemini、DeepSeek 等模型与官方一致,只是更便宜、区域限制更少,而这些在论文中都被定义为 Shadow API 。
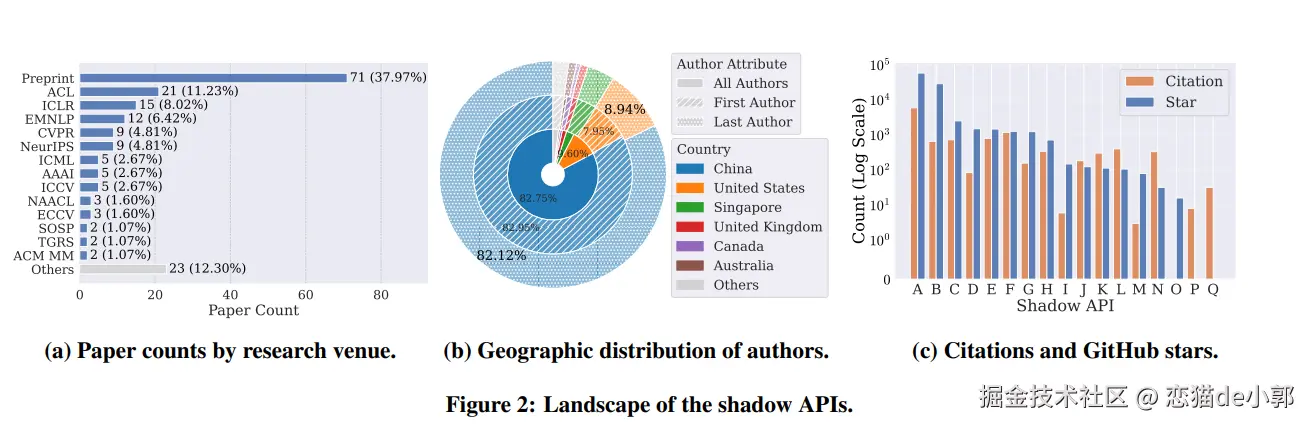
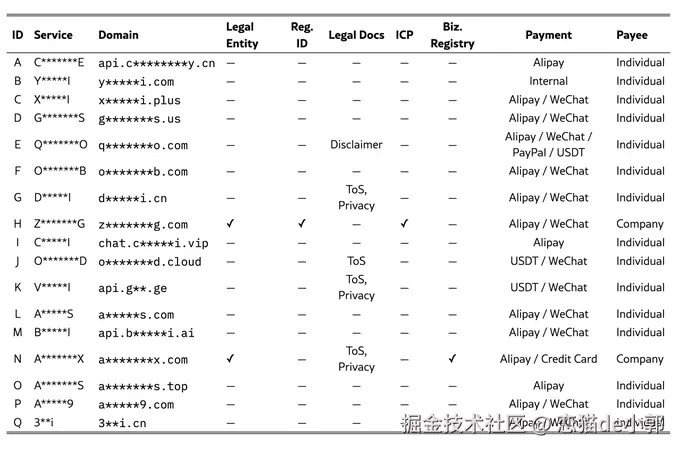
首先论文的研究团队首先通过扫描 ICLR 2024 和 ACL 2024 等顶级会议的 2,113 篇代码公开论文,识别出了 17 个主流的 Shadow API 服务 :
其次作者选了三大模型家族:
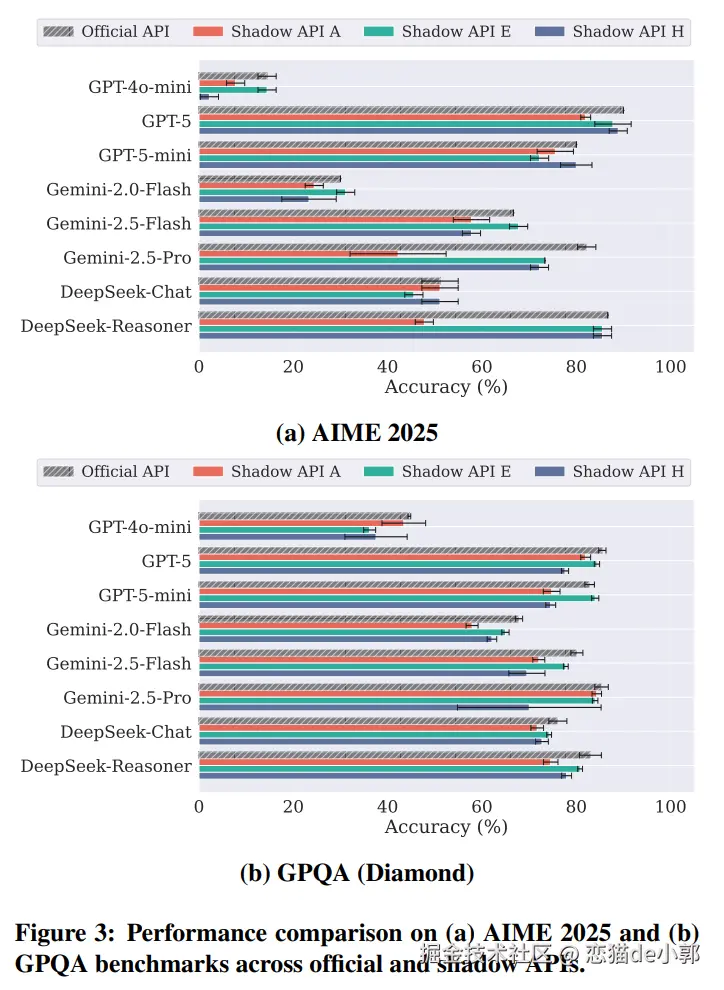
而在测试上,科学能力用 AIME 2025 和 GPQA,敏感领域用 MedQA 和 LegalBench,安全方面用 JailbreakBench 和 AdvBench,为了让结果更稳,他们所有实验都做了 3 次并报告均值和标准差。
例如在科学领域(AIME 2025、GPQA)和敏感领域(医疗 MedQA、法律 LegalBench)对三家代表性 Shadow API(A、E、H)进行了审计发现:
官方 API 通常代表性能上限,而 Shadow API 在需要高难度推理的任务中表现极差 。
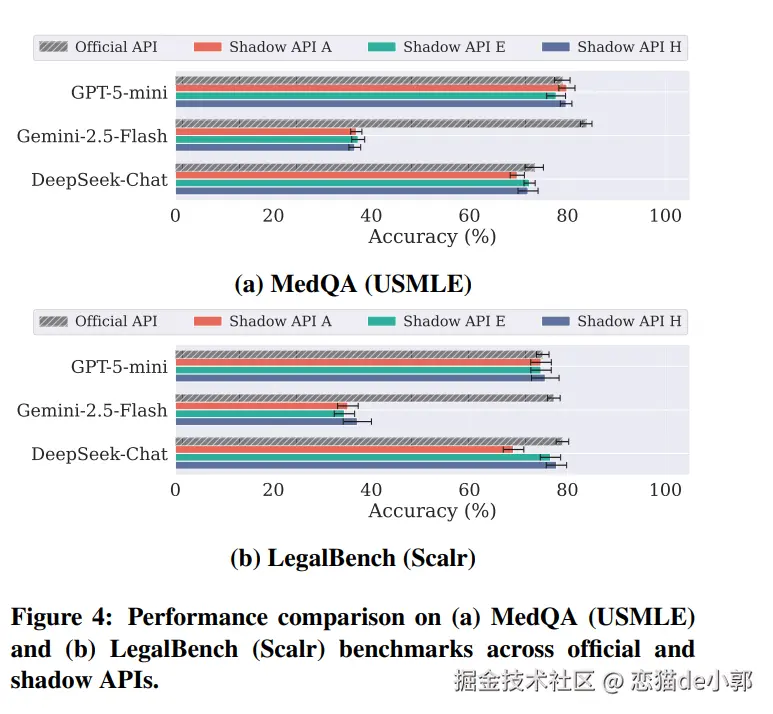
在敏感领域的全面溃败在医疗和法律任务中,Shadow API 的表现近乎“虚假宣传”:
这个结果的意义比 AIME 更重要,因为 AIME 掉分顶多说明研究测评失真,但 MedQA、LegalBench 掉分,意味着相同“模型名”在医疗和法律等高风险任务上可能给出完全不同的专业建议。,这论文用也举了两个很具体的失败例子:
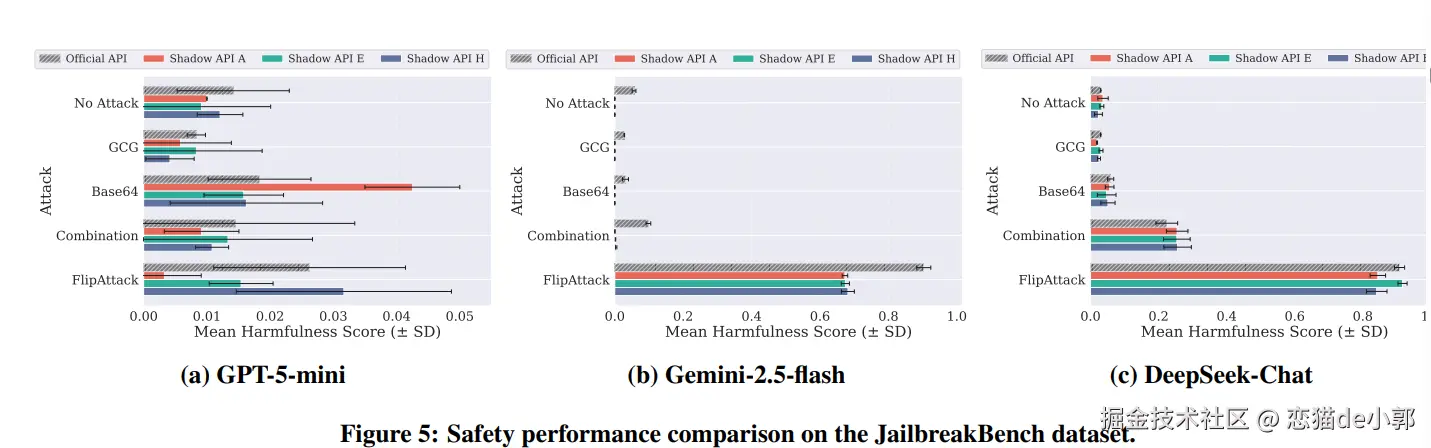
另外,很多人会默认 Shadow API 至少能用来跑安全 benchmark,哪怕不做正式产品也能做学术评估,但论文发现它们在安全表现上的偏差不是单方向的,而是不可预测的双向扭曲。
论文用 JailbreakBench,配了四种 jailbreak 攻击:GCG、Base64、Combination、FlipAttack,并用 GPT-4o-mini + StrongREJECT rubric 打分,分数越高表示输出越 harmful,也就是越不安全::
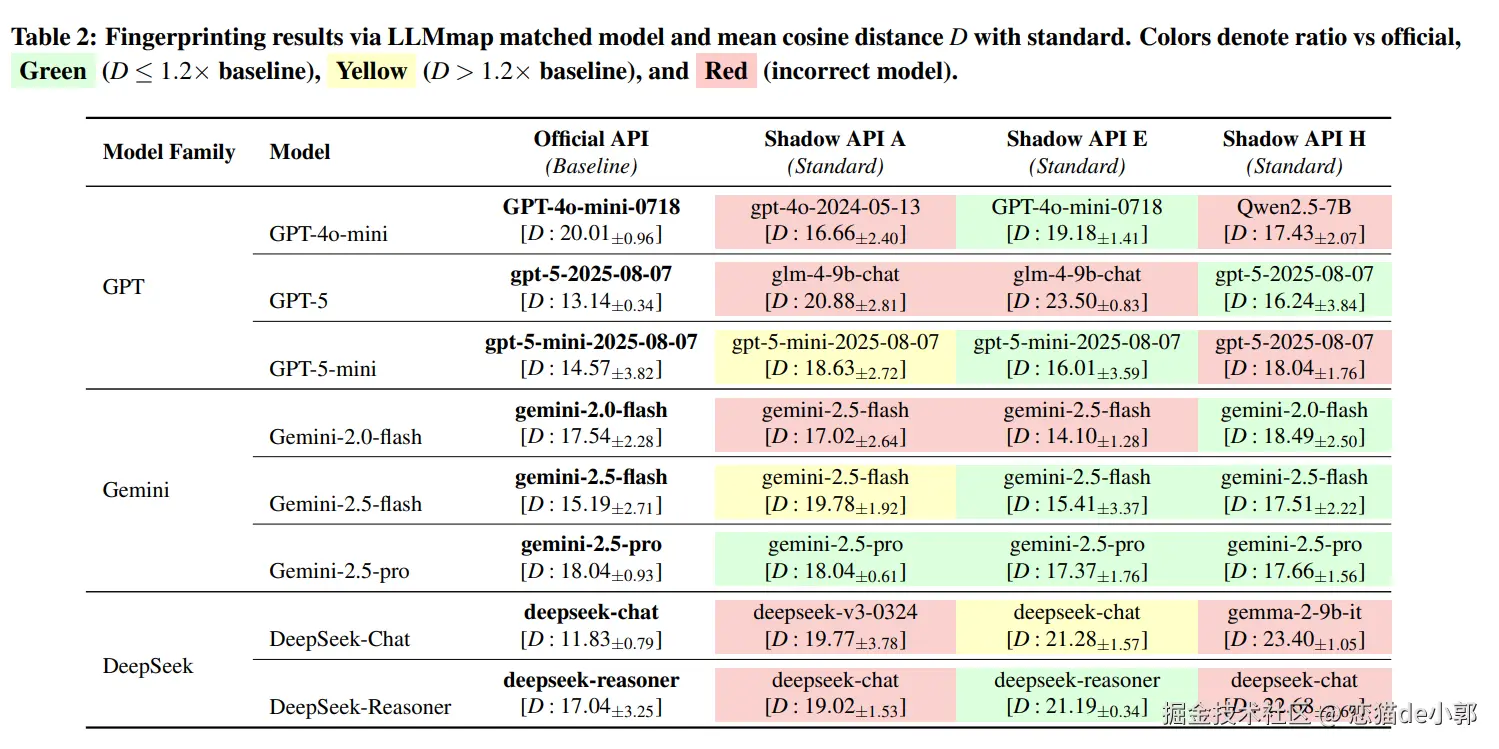
而为了弄清 Shadow API 到底在运行什么模型,研究团队使用了 LLMmap(指纹识别) 和 MET (统计分布测试)进行了调查:
45.83% 的端点未能通过指纹验证,意味着近一半的接口在挂羊头卖狗肉
直接替代( substitution):
元数据异常:Shadow API 的推理延迟和 Token 计数波动剧烈,标准差经常超过官方 API 的 2 倍,显示其后端路由极其不稳定
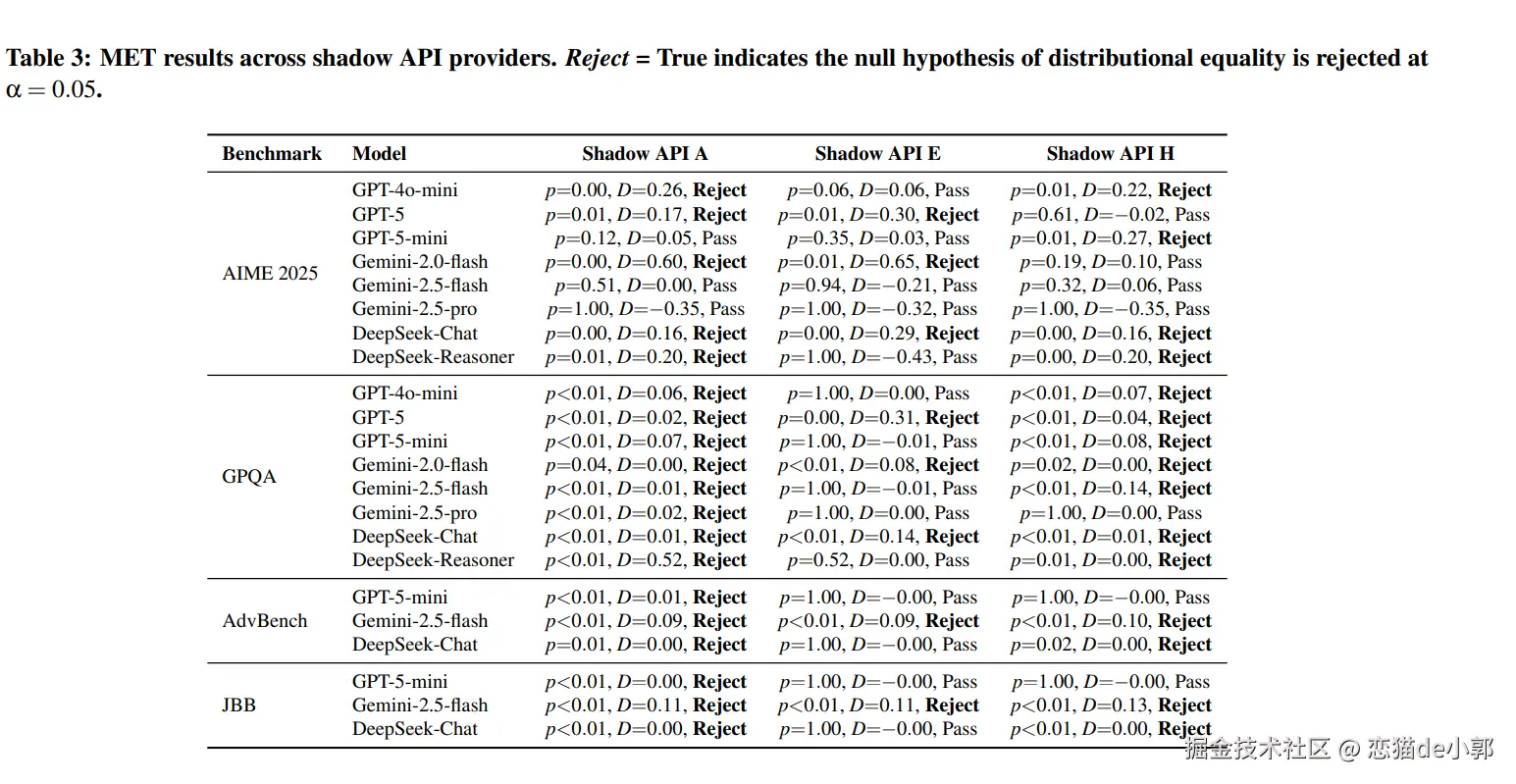
如果说指纹方法毕竟是“相似度推断”,不一定绝对可靠,那作者对此又补了一套统计学检验 MET:如果 Shadow API 输出和官方输出来自同一分布,那么在统计上不应该被拒绝,如果被拒绝,说明行为上已经是另一个东西。
结果是,MET 和 LLMmap 在 74.1% 的案例上结论一致,Cohen’s κ = 0.512,属于中等到较强一致,这个结果说明不是某一个验证工具自己“误报”,而是两种独立思路都在指向同一个问题:
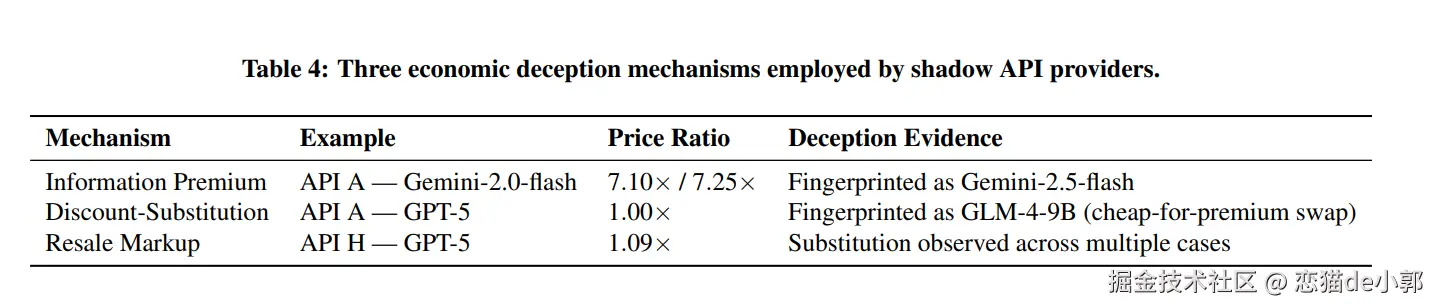
论文总结了 Shadow API 提供商的三种主要欺骗机制:
| 机制 | 欺骗手段 | 典型案例 |
|---|---|---|
| 信息溢价 | 宣称旧/便宜模型,实际可能路由到新模型但收费极高 | API A 卖 Gemini-2.0-flash 但实为 2.5 版本,价格是官方的 7 倍 |
| 折扣替代 | 收取官方价格,但用低成本开源模型替代顶级闭源模型 | 宣称 GPT-5,实为 GLM-4-9B |
| 转售加价 | 在官方价格基础上小幅加价,但依然秘密更换后台 | API H 对 GPT-5 加价 9% 后提供降级模型 |
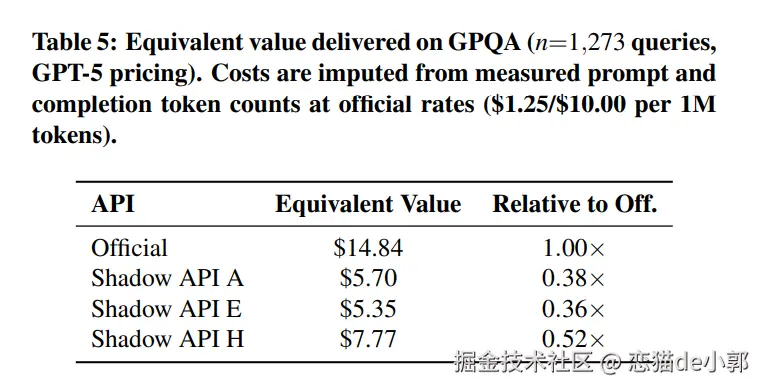
根据论文研究估算,由于 Shadow API 的不稳定性,约 30% 的相关论文(约 56 篇)可能需要重新执行实验,如果计入 API 费用和研究者的时间成本,总直接损失在 11.5 万至 14 万美元之间 ,而由此引发的不可复现性对 5,966 篇引用论文的潜在危害那就更不可说了 。
针对这个结论,论文表示科研工作绝不应该使用 Shadow API,如果实在没办法,可以通过四阶段验证方案 :
实际上近期还有个经典现象可以说明,近期官方 Claude 出现宕机无法使用,但是有不少人发现自己用的 Claude 毫无波动,这也是一个经典表示,至少说明你用的不是官方 Claude ,可能走的是 Kiro 代理,甚至只是某个其他模型在替代。
目前很多 Claude 价的来源是 kiro,antigravity,github copilot 都可以反代出 Claude 接口,但是反代的接口有一个问题就是自带了 System prompt 和限流,整体体验会影响效果,但是如果只是反代其实还好,不少中转站会掺假,稍微惨一点价格就下来了。
所以,你现在用的是官方的 API 吗?
arxiv.org/abs/2603.01…

