意项
39.91M · 2026-03-23

在上一章中,我们介绍了 deepset 的 Haystack——一个用于管理 LLM 相关项目端到端生命周期的健壮框架。这其中涵盖了 OpenAI 的 GPT、Hugging Face 的 Transformers,以及托管在 Amazon Bedrock、Google Vertex AI 等云服务平台上的模型。我们深入探讨了 Haystack 如何支持基于 LLM 的数据 Pipeline 的创建与管理,而这些 Pipeline 对于数据预处理、存储、与 LLM 组件交互等任务都至关重要,并最终通过应用将处理后的信息提供出去。
本章的重点是:如何通过 Pipeline 将 Haystack 的组件连接起来。我们将提供一份全面指南,说明如何围绕常见与特定场景构建 Pipeline,从而充分发挥 Haystack 生态系统的潜力。到本章结束时,你将清楚理解如何构建高效的数据 Pipeline、如何优化它们的性能,以及如何将其应用到真实场景中,从而提升你开发复杂 LLM 应用的能力。
本章将涵盖以下主题:
我们将沿用第 2 章中介绍的同一套技术环境。本章的 Jupyter Notebook 可在以下仓库的 ch4/ 目录下找到:
本章配有一个专用的 pyproject.toml 文件。建议你在一个独立的 VS Code 窗口中打开 ch4 文件夹,并安装依赖:
$ cd ch4/
$ uv sync
$ source .venv/bin/activate
要将该虚拟环境激活为 Jupyter Notebook 的内核,请点击 Select Kernel,然后选择 Python Environments,再选择指向该文件夹虚拟环境的路径,即名为 rag-with-haystack-ch4 的环境,或者虚拟环境的相对路径 .venv/bin/python。
我们会逐步引入这些 Notebook,因此你可以根据所提供的 URL,通过相对路径选择当前讨论到的 Notebook。
当你基于 Haystack 的架构来设计 Pipeline 时,目标是利用该框架的组件以及灵活的连接方式,构建现代化的、结合 LLM 的搜索 Pipeline。本节将概述创建 Haystack Pipeline 所涉及的步骤与考虑因素,并说明如何利用其能力高效编排一个项目的生命周期。
接下来的部分,我们会先从理解 Haystack 的一个核心关注点开始:灵活性。
Haystack 2.0 引入了一种超越传统查询与索引 Pipeline 的灵活性。它的架构建立在有向多重图(directed multigraphs) 之上,因此支持多种多样的组件连接方式,包括并发流、循环和分支。
这意味着,在 Haystack 中,一个 Pipeline 可以被设计为同时处理多种数据处理任务——从预处理、索引到查询——而不再受限于线性数据流。借助这种能力,我们可以让 Pipeline 适配多种不同的使用场景,从数据清洗、处理和索引,到 RAG、Pipeline 分支与序列化。
下面我们来看看:为了设计一个 Pipeline,我们需要经历哪些关键步骤,以及有哪些类和对象使得多重图的创建成为可能。
在本章中,我们将通过多种用例,动手实践如何通过 Pipeline 连接组件。在本节中,我们会概述初始化 Haystack Pipeline 以及连接组件所涉及的关键步骤。主要的顺序步骤如下:
选择并初始化组件:
识别适用于该 Pipeline 的组件。例如,一个索引 Pipeline 通常需要预处理器、切分组件、embedding 组件以及写入组件。而一个带增强生成能力的检索 Pipeline,则通常需要查询 embedder、retriever 以及 Prompt 生成组件。
创建 Pipeline 对象:
首先使用 Pipeline() 类初始化 Pipeline。这个步骤会创建数据流的骨架,为后续填充组件做好准备。
添加组件:
使用 .add_component(name, component) 将单个组件添加到 Pipeline 中。此时尚未定义组件之间的数据流,但已经为后续集成各种能力做好准备——从数据抽取与清洗,到与 LLM 的交互。
连接组件:
使用 .connect("producer_component.output_name", "consumer_component.input_name") 在组件之间建立连接。这是至关重要的一步,它定义了数据流向,并确保一个组件的输出能够被正确地作为下一个组件的输入。Haystack 的设计支持复杂的数据流,包括分支与循环,以满足复杂数据处理需求。
运行 Pipeline:
通过 .run({"component_1": {"mandatory_inputs": value}}) 执行 Pipeline,并指定初始输入。这个动作会激活已经连接好的组件之间的数据流,使数据按照定义好的 Pipeline 结构被处理。
可视化 Pipeline:
你可以使用 pipeline.draw(path="path/to/image.png") 方法为 Pipeline 生成 Mermaid 图。
上述工作流可以应用到多种不同的用例中。Pipeline 的具体功能,取决于所选组件以及它们被连接的顺序。如果你的工作流需要重复执行某些步骤,或需要根据某种条件走向特定路径,那么 Haystack 的 Pipeline 还支持分支机制。
分支使得你的 Pipeline 可以同时处理不同的数据类型或不同的处理需求。通过创建分支,你可以将特定数据导向专门的组件,进行针对性处理。Pipeline 中的循环则支持迭代式处理,例如错误纠正或数据精炼,从而提升输出的准确性与可靠性。
在创建分支时,关键组件是 router。分支的典型应用场景包括:对不同语言的文档采用不同处理方式,或者对不同格式的文档采用不同处理路径。
用于探索不同类型 router 的 Jupyter Notebook 可在以下位置找到:
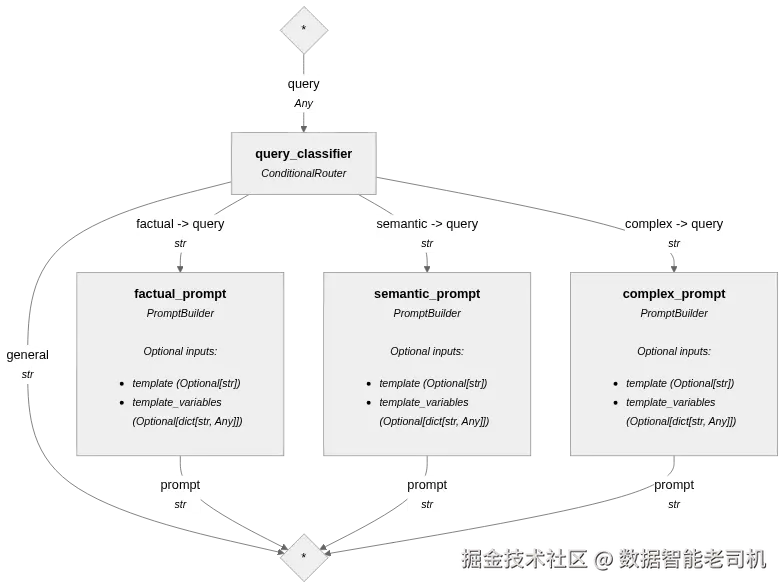
我们可以在图 4.1 中看到条件路由器是如何将流程分叉的。
图 4.1 —— 条件路由器将 Prompt 分类为 factual、semantic 或 complex
图 4.1 所展示的 Pipeline 使用了 Haystack 的 ConditionalRouter 组件,对每一个输入查询进行检查,并动态选择最佳处理路径。该 router 会评估一组 Jinja2 条件,这些条件会在查询文本中查找特定模式,例如:
when / who / what is the 这类模式how does / compare / difference between 这类模式and 等连接结构如果你想更深入了解 Jinja2 及其模板中的条件判断,建议先熟悉相关教程中的关键概念。
根据第一个匹配成功的条件,查询会被路由到若干输出之一(factual、semantic 或 complex),每个输出都连接到一个专门的 PromptBuilder 组件,用于生成不同风格的 Prompt(如直接回答、全面解释或详细分析)。最后还有一个默认路由(条件:{{ True }}),以确保每个查询都能被处理。当我们运行这个 Pipeline 时,就能看到每个查询被选中了哪条路由,以及最终生成了哪一种 Prompt。
Haystack 的 Pipeline 强调一种受控的数据流:只有彼此连接的组件之间才会交换数据。这样的设计不仅优化了处理速度,也通过隔离数据路径简化了调试过程。
因此,准确梳理每个组件的输入和输出至关重要,以确保它们能够在 Pipeline 中无缝集成并顺利交换数据。
Haystack 已经预先规划好了多种合理的数据流方式,确保组件之间能够以符合逻辑的方式连接起来,从而使我们能够把文档逐步转换成合适的数据结构与向量表示,并最终让 LLM 检索并返回恰当的信息。其核心假设是:随着数据通过组件在 Pipeline 中流动,每个组件都会接收某种特定数据结构作为输入,并输出另一种数据结构。因此,组件的连接顺序非常重要。
例如,负责将 PDF、网站内容和 Markdown 文件转换为文本的组件,会分别接收对应类型的文件(例如文档路径)作为输入,并返回 Haystack 的 Document 对象。这些 Document 对象随后又可以作为输入,交给负责将文档内容向量化并存入文档存储的组件。
而当我们构建一个 retriever Pipeline 时,Haystack 假定 Pipeline 的输入将是一个问题(字符串)和/或一个由浮点数组成的列表(表示该问题的向量形式),其输出则是相关文档。在本章“使用 Haystack 构建 Pipeline”这一节中,我们会详细列出不同 Pipeline 用例所要求的输入与输出。
为了帮助理解数据在 Pipeline 中的流动方式,Haystack 提供了 .draw() 方法,用于创建一张数据流在各组件之间流动的可视化图。接下来我们就来看这一点。
图 4.2 —— 一个将音频转换为向量的 Haystack Pipeline 的 Mermaid 图
对 Pipeline 进行可视化——例如通过 Mermaid 图——能够帮助你更清晰地理解其结构与数据流,并识别潜在问题或低效之处。
Mermaid 图是一类使用 Mermaid 语法来对系统、过程和流程进行可视化与文档化的图表。它常被用来创建流程图、时序图、类图、状态图和甘特图。Mermaid 允许使用一种简单的文本语法来创建这些图表,并可集成到各种 Markdown 文件与文档之中。
在 Haystack 中,当组件被连接时,系统会自动进行验证,检查兼容性与配置是否正确,这有助于问题排查和 Pipeline 设计优化。通过 .draw() 方法,我们可以轻松创建数据流的 Mermaid 图。
例如,在图 4.2 中,我们看到的是一个音频文件索引 Pipeline 的数据流。这个 Pipeline 的目标,是接收音频文件,并将其中内容的向量表示存储到 DocumentStore 中。
这个 Pipeline 中涉及的关键组件如下:
RemoteWhisperTranscriber
该组件使用 OpenAI Whisper 接口将音频转换为文本。
DocumentCleaner
该组件会从转写后的文本中移除异常字符。在文本处理场景中,所谓异常字符,通常指那些非标准、特殊或意外出现的字符,它们可能会在编码、显示或数据处理过程中引发问题。
DocumentSplitter
该组件将文本切分成若干 chunk,为后续向量化做准备。
SentenceTransformerDocumentEmbedder
该组件将文本 chunk 转换为数值表示,同时保留其语义含义。
DocumentWriter
该组件将 embedding 写入 DocumentStore。
这种 Pipeline 流可以执行一次,也可以反复执行,例如当 DocumentStore 需要更新,或者有新的 embedding 文档需要加入时。通过这一特定流程,我们可以自动完成“将音频转换为向量格式”的过程,并使 LLM 能够从中检索信息。除了现有组件之外,Haystack 还通过 integrations 对外部能力进行了补充。
为了确保 Pipeline 能够连接多种包、LLM 与 embedding 提供商,以及评测与可观测性框架,Haystack 开发了一套框架,用于支持 Haystack Pipeline 与外部系统的连接,甚至支持开发新的 Haystack integrations。
可集成到 Haystack Pipeline 中的技术列表,可以在其 integrations 页面中找到。你还可以在那里查到关于每一项集成的具体实现方式、优势,以及如何为你的项目选择合适集成的指导。
这种协作式生态推动了 Haystack 生态内的创新与持续改进,使用户得以不断拓展信息检索及更广泛 AI 应用的边界。
在本节中,我们概览了 Haystack 在设计和构建 LLM 驱动 Pipeline 时的几个支柱,包括:
至此,我们已经准备好去研究那些按复杂度划分的、常见的 LLM 驱动 Pipeline 用例。在下一节中,我们将概述 LLM 在不同领域中的应用,并重点讨论 Haystack Pipeline 的特性是如何支撑这些工作流构建的。
任何高效 RAG 系统的核心,都建立在两个彼此独立但又相互依赖的工作流之上:一个是负责准备知识库的离线索引 Pipeline,另一个是利用这些预处理数据、实时回答用户问题的在线查询 Pipeline。本节将给出构建这两个基础支柱的蓝图。我们会先构建一个通用的索引 Pipeline,使其能够摄取来自多种来源和格式的数据;然后再构建我们的第一个查询 Pipeline(即一个朴素 RAG 系统),它将作为后续一切扩展的功能基线(包括带排序能力的混合 RAG 系统)。
索引 Pipeline 是一个关键的离线过程。它的主要目标,是从各种来源获取 Web 地址、非结构化或半结构化数据,将其转换为标准化格式,并加载到 DocumentStore 中,以便后续高效检索。一个设计良好的索引 Pipeline,是高性能 RAG 系统的基石,因为摄取数据的质量会直接影响检索质量,并最终影响生成答案的质量。
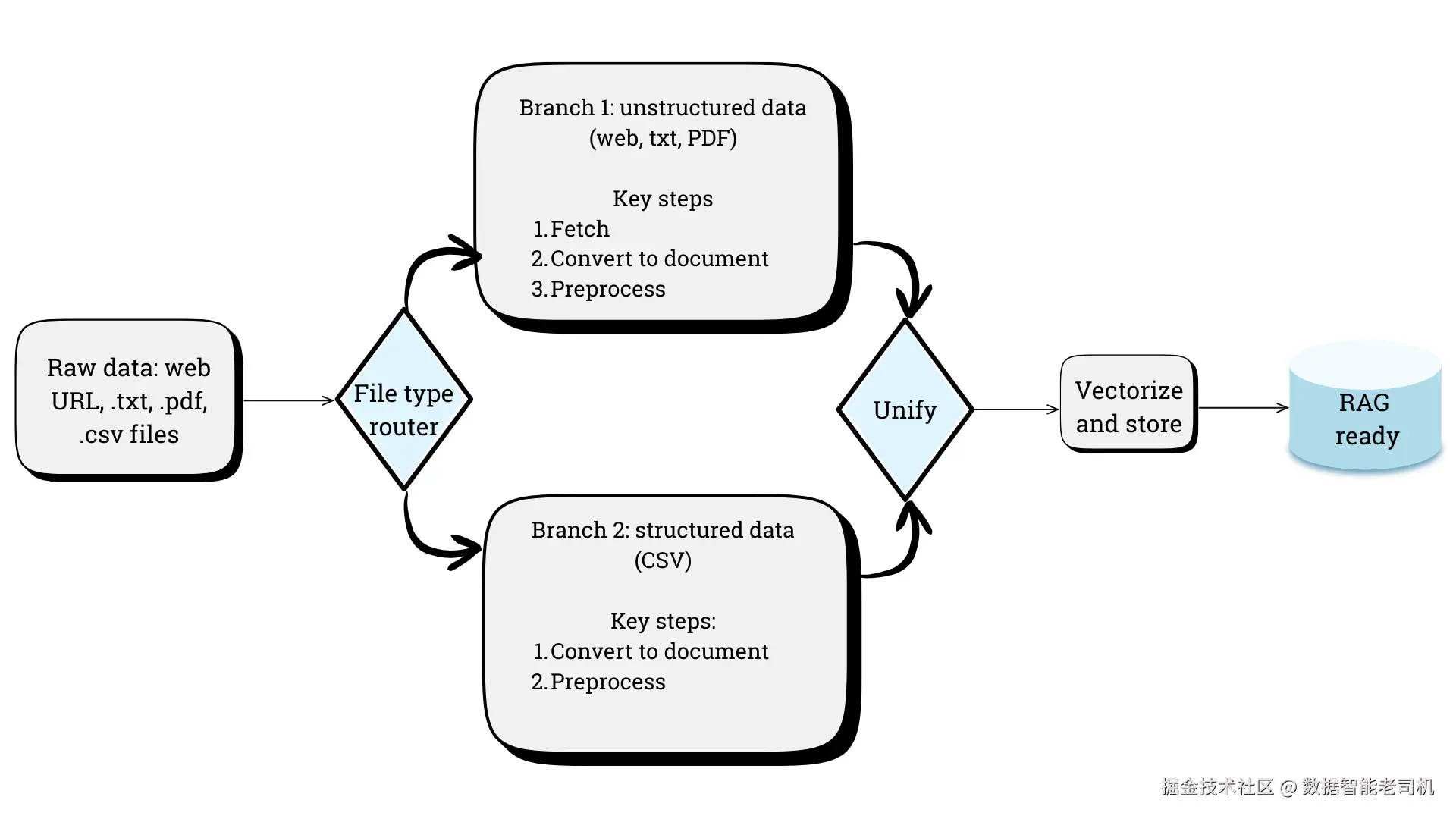
我们将构建一个能够同时处理多种数据源的索引 Pipeline:实时网页、本地文本文件和 PDF 文件,以及来自 CSV 文件的结构化表格数据。为此,我们会使用 FileTypeRouter——这是一个能够根据不同数据类型将其路由到相应转换器的组件,从而实现统一但又具备针对性的摄取工作流。其关键步骤如图 4.3 所示:
图 4.3 —— 同时处理结构化文本与非结构化文本的索引 Pipeline
我们的 Pipeline 将按以下顺序执行操作:
Document 对象。DocumentStore。一个用于探索带路由机制的索引 Pipeline 实现的 Jupyter Notebook 可在以下位置找到:
你可以把这个 Notebook 中的代码想象成:在为一个数字图书馆搭建一条复杂的装配线。其核心目标是:接收多种不同格式的“书籍”(实时网页、本地文本文件、PDF 和结构化 CSV 表格),以正确方式处理它们,并将它们归档到一个专门的数据库(InMemoryDocumentStore)中。一旦它们进入这个数据库,你就可以基于它构建搜索引擎或聊天机器人(即一个 RAG 系统),从而能够即时查找并理解来自这些不同来源的信息。
这段代码构建的是一条典型的索引 Pipeline。它是一个关键的离线过程,职责是为你的知识库做好准备。这个 Pipeline 的质量,会直接决定最终应用的表现。下面我们来拆解这条 Pipeline 的工作方式。
首先,我们收集所有原始材料(文件和网页)。然后,这些输入进入本工作流中最关键的组件:FileTypeRouter。这个组件会决定数据应该流向哪个输出 socket,并提供四条不同的数据流:text/plain、application/pdf、text/html(用于抓取到的网页内容)以及 text/csv。
当我们调用 indexing_pipeline.run(...) 时,所有本地文件(.txt、.pdf 和 .csv)都会被送入 router。它会逐个检查这些文件,并对其进行“分拣”,把它们送往正确的处理通道。这种针对不同数据类型创建不同处理路径的能力,称为分支(branching) ,也是 Haystack 灵活设计中的一个关键部分。借助这种机制,router 负责把每个文件送往合适的预处理 Pipeline:
haystack_intro.txt 只会被发送到 text/plain 输出sample.pdf 只会被发送到 application/pdf 输出llm_models.csv 只会被发送到 text/csv 输出接下来,就进入通过分支分别处理结构化数据与非结构化数据的阶段。
现在,我们的“原材料”会同时流经两条独立的、专门化的迷你装配线:
这一分支用于处理各种文本块:
获取并转换(Fetch and convert) :
LinkContentFetcher 负责抓取网页内容,而 HTMLConverter、TextConverter 和 PDFConverter 则分别将各自输入转换为标准的 Haystack Document 对象。
合并(Join) :
unstructured_doc_joiner 将来自这些不同转换器的文档收集到同一个列表中。
预处理(Preprocess) :
text_cleaner 对文本进行清理,text_splitter 则把较长文档切分为长度为 150 个单词的小 chunk。这一步对后续流程至关重要。
这一分支专门用于处理表格数据:
转换(Convert) :
csv_converter 会把整个 CSV 文件的内容读取进来,并作为一个单独的文档。
预处理(Preprocess) :
csv_cleaner:这个组件对表格很“聪明”。它会移除空行和空列(例如示例里的连续逗号形成的空字段)。csv_splitter:这是关键所在。我们将其设置为 split_mode="row-wise"。它会把清洗后的表格按行拆分,使每一行都变成一个独立的文档(例如“Company: OpenAI, Model: GPT-4...”)。现实世界中的数据很少是完美的,因此我们的 Pipeline 需要具备应对异常情况的稳健防线。第一道防线是 FileTypeRouter,它会对未知文件格式(例如 .png 图片)起到安全阀的作用。它会把无法匹配的文件导向一个未连接的 unclassified 路由,从而有效忽略这些文件,避免它们堵塞整条处理链路。
然而,LinkContentFetcher 默认会更加严格:对于失效链接,它会抛出异常,而这可能会让整个 Pipeline 崩溃。为避免这种情况,我们将其配置为 raise_on_failure=False,使其在遇到坏链接时直接跳过。
最后,即便文件本身是可访问的,也可能存在另一个问题:文件内容为空,而这会导致 DocumentSplitter 崩溃。为了解决这个问题,我们引入了一个 DocumentSanitizer 组件——它是一个自定义的质量闸门(quality gate),会检查每一个文档,并丢弃内容为空的文档。
这三层保护机制——类型安全的路由、访问异常的跳过,以及内容质量的清洗——共同确保了我们的 Pipeline 具备生产可用性。下一章中,我们将更详细地学习如何定义自定义组件。现在,我们已经可以把来自两条分支的数据送入最终阶段了。
现在,我们把所有内容重新汇总起来:
汇合(Unifying) :
final_doc_joiner 是重新汇流的节点。它会等待并收集所有已经处理好的文档(分支 1 中的文本 chunk,以及分支 2 中拆分出的 CSV 行文档),并将它们合并成一个大的统一列表。
索引(Indexing) :
doc_embedder 接收这个统一后的列表。它会读取其中每一个 chunk(无论是文本还是 CSV 行),并把它转换为向量,也就是一组能够表达其语义含义的数字。
入库(Shelving) :
最后,writer 会把这些完成全部处理、已经“建好索引”的文档(此时它们已经携带强大的向量 embedding)“上架”到 InMemoryDocumentStore 中。
至此,大功告成。你的数字图书馆已经完成索引。无论是博客文章里的文本、PDF 文件中的内容,还是 CSV 文件中的单独行数据,都已经并列存储好,随时可以基于其语义被理解与检索。
这些如今存放在 DocumentStore 中的处理后数据,正是我们后续构建问答能力的基础。下一步,就是构建能够与这个知识库交互、生成智能回答的 RAG Pipeline。
生成后的 Pipeline 可以通过内置的 draw 能力进行可视化,得到 Mermaid 图,见以下链接:
朴素 RAG(naive RAG)架构,是 RAG 的最直接实现方式。它遵循一个简单、线性的两步过程:首先,检索与用户查询相关的一组文档;其次,基于这些文档中的信息生成回答。虽然它是最简单的 RAG 形式,但它既是一个必要的基线系统,本身也具有相当的实用价值。
即便是在这样一个基础配置下,Haystack 的设计哲学依然带来了明显优势。框架对显式连接(pipe.connect())的坚持,构建出了一种“玻璃盒(glass box)”式架构。Haystack Pipeline 中的每一步都是透明且可追踪的。从最初的查询 embedding,到 retriever,再到 prompt builder,最后到 generator,整条数据流都由开发者显式定义。这种透明性对于调试和理解系统行为极其宝贵,也为构建更复杂、更易维护的应用奠定了坚实基础。
下面我们来实现这一工作流。
我们的 Pipeline 将按以下顺序执行:
DocumentStore 中检索相关信息。一个用于探索语义搜索 Pipeline 实现的 Jupyter Notebook 可在以下位置找到:
如果说前一个 Pipeline 是我们离线构建“智能图书馆”的装配线,那么语义搜索 Pipeline 就是在线使用这座图书馆的系统。语义搜索 Pipeline 就像一位“图书管理员”:它接收用户问题,在已经完成索引的“书架”中查找答案,并实时生成带上下文依据的回答。下面我们来拆解这条用于回答问题的装配线。
用户的问题是起点。但我们无法直接把一个文本问题与 DocumentStore 中的向量 embedding 进行比较,因此必须先把问题转换为同样的表示形式。
动作(Action) :
用户的问题(例如“Haystack 2.0 是什么?”)会被发送到 SentenceTransformersTextEmbedder。
组件(Component) :
text_embedder 使用与索引阶段完全相同的 embedding 模型。
输出(Output) :
输出结果是一个“查询向量(query vector)”,也就是一组能够表达该问题语义含义的数字。
正是这个初始阶段,使得后续基于向量搜索的语义相关检索成为可能。接下来我们看检索阶段。
现在我们已经有了问题对应的向量,就可以从图书馆中找到最相关的文档了。
动作(Action) :
阶段 1 中得到的查询向量会被送入 InMemoryEmbeddingRetriever。
组件(Component) :
retriever 会拿这个向量,与 DocumentStore 中存储的所有文档向量进行比较,并找出 top_k=3 个与该问题语义最相近的文档。
输出(Output) :
输出是一组文档对象列表。它们可能来自网页内容,也可能来自文本文件,或者是 CSV 的某一行,只要它们与问题最相关即可。
这些文档对象接下来会与原始查询一起,被“注入”到一个 Prompt 模板中,用来指导 LLM 如何生成回答。
现在,我们把检索到的事实拿来构造答案。
动作(增强,augment) :
PromptBuilder 组件会接收两个输入:原始问题,以及来自 retriever 的文档列表。随后,它会遵循模板,将检索到的文档内容巧妙嵌入到一个更大的 Prompt 中,交给 LLM 使用。模板大致如下:
动作(生成,generate) :
这个最终增强过的 Prompt 会被发送给 LLM(OpenAIGenerator)。LLM 会读取刚刚提供给它的上下文,并仅基于这些信息,用自然语言回答问题。
至此,一切就完成了。系统随后会输出 LLM 的回答。我们已经成功构建出一条 Pipeline:它不再是“猜测”答案,而是先从自定义知识库(其中包括文本、网页和 CSV 数据)中检索事实,再利用这些事实生成准确、具有上下文依据的回答。
该 Pipeline 的可视化结果可在以下 URL 找到:
这个朴素 RAG Pipeline 提供了一个功能完备且相当有力的基线方案。然而,它完全依赖语义相似性,这也正是它的主要弱点。它可能会在处理依赖特定关键词、缩略语或产品代码的查询时表现不佳,因为这些内容在 embedding 空间中未必能被很好表达。
例如,搜索某个特定错误代码时,如果包含该精确字符串的那份文档在整体语义上下文上并不够接近,那么系统可能就无法检索到它。为了构建一个更稳健、更接近生产可用的系统,我们必须解决这一局限性——也就是引入**词法检索(lexical search)**能力,这便自然引出了更高级的模式:混合检索(hybrid retrieval) 。
混合检索是一种高级技术,旨在通过结合两种不同的搜索范式——稀疏(词法)检索与稠密(语义)检索——来构建一个更稳健、更通用的搜索系统。
稀疏检索(Sparse retrieval) ,通常使用 BM25 这类算法实现,非常擅长关键词匹配。对于包含特定名称、术语或代码,并且这些精确词项实际出现在源文档中的查询,它特别有效。它的弱点是词汇不匹配问题:它无法理解同义词,也无法把握概念之间的关系。
稠密检索(Dense retrieval) ,则基于向量 embedding,擅长理解语义含义、用户意图以及概念关系。即便文档与查询之间没有共享任何关键词,它也能找到相关文档。但它的弱点在于:有时它会偏向广义语义相似性,从而忽略那些字面上非常精确、但整体语义不够接近的词项。
我们可以在 Pipeline 中为这两种检索方式分别加入一个 retriever 组件,让查询同时发往两边,然后使用 DocumentJoiner 组件来合并它们的输出。
为了进一步提升精度,我们还会在 Pipeline 中加入一个 reranker。Reranker 通常是一个 cross-encoder 模型,它虽然计算成本高于初始检索中使用的 bi-encoder 模型,但精度也更高。它的工作方式是:把查询与每个候选文档作为一对输入,从而对二者相关性做更深入、更具上下文感知的分析。
通过把 reranker 放在融合步骤之后,我们就可以对合并后的文档列表重新排序,确保只有最相关的候选文档会被传递给 LLM,从而显著提升最终生成答案的质量。
通过并行运行这两种检索方式并融合其结果,混合系统就能同时利用二者互补的优势。在第 5 章和第 6 章中,我们将学习如何借助知识图谱、合成数据生成以及 Ragas,对朴素方法和混合方法进行评估,以判断哪一种表现更优。
现在我们来看看,如何实现一个带排序的混合 RAG。
我们将探索一个混合 RAG + 排序的实现,它会利用分支、合并,以及一个 Transformer 模型来执行排序。
我们的高级 Pipeline 将具备以下结构:
InMemoryEmbeddingRetriever(稠密检索)和 InMemoryBM25Retriever(稀疏检索)。DocumentJoiner。TransformersSimilarityRanker,由它根据查询相关性重新评分并重新排序。PromptBuilder 和 OpenAIChatGenerator 用于生成最终答案。一个用于探索带重排能力的混合搜索 Pipeline 实现的 Jupyter Notebook 可在以下位置找到:
为了构建一个更稳健的问答系统,我们采用了一种名为**混合检索(hybrid retrieval)**的高级技术。这个 Pipeline 通过并行结合两种不同的搜索方式,构建出一个更通用的搜索系统:
混合检索 Pipeline 的 Mermaid 图可在以下 URL 找到:
你可以把这种混合方式想象成:让原来的“语义图书管理员”和一个新的“关键词专家”(BM25)一起协作,去找出尽可能最好的文档。Haystack 灵活的设计,使这种并行分支成为一种原生能力。但我们还会再加一位专家:一位“总馆长”(reranker),由它对两者合并后的结果做最后一次深度分析,从而挑出绝对最佳的文档。
下面我们来拆解这条高级装配线。
和前面一样,用户的问题仍然是起点。但不同于语义搜索 Pipeline,在混合搜索 Pipeline 中,用户问题会在同一时刻被送入两条路径——稠密 / 语义搜索与稀疏 / 关键词搜索。
这一路径会使用语义检索组件,遵循以下模式:
动作(Action) :
hybrid_question 被发送到 SentenceTransformersTextEmbedder。
组件(Component) :
text_embedder 把问题转换为查询向量。
组件(Component) :
embedding_retriever 使用该向量,从 document_store 中找出 top_k=3 个在语义上最相似的文档。
这一路径使用基于关键词的 retriever,遵循以下模式:
动作(Action) :
用户原始问题文本会直接发送给 InMemoryBM25Retriever。
组件(Component) :
bm25_retriever(我们的关键词专家)会忽略语义含义,而是通过匹配精确词项(如 Haystack 或 2.0)来找出 top_k=3 个文档。
当两条路径都完成检索后,就进入合并阶段。
现在,我们手头已经有了两份不同的文档列表,它们可能有重叠,也可能完全不同。我们需要把它们“融合”为一个候选文档列表。
动作(Action) :
两份文档列表(最多共 6 份文档)都会送入 DocumentJoiner。
组件(Component) :
document_joiner 会把这两份列表合并为一个统一的候选文档列表。
输出(Output) :
输出是一份合并后的文档列表。
接下来,我们就可以在这个基础上引入排序机制,从中挑选最相关的内容。
这份合并后的列表已经不错了,但它还没有按照“真实相关性”进行排序。于是我们加入最强的一道质量控制步骤:reranker。
动作(Action) :
合并后的文档列表与原始用户问题文本一起被发送到 TransformersSimilarityRanker。
组件(Component) :
ranker 是一个计算成本更高、但精度也高得多的模型。它会对查询与每个候选文档组成的配对进行“更深层、更具上下文意识的分析”,然后基于这种分析对整个列表重新打分、重新排序。
输出(Output) :
输出结果是最终的、经过精确排序的 top_k=3 个最相关文档,它们是从两种检索方式的最佳候选中筛选出来的。
当前三份最优文档被 ranker 选出之后,我们就可以把它们交给 LLM 了。
这一阶段与朴素 RAG Pipeline 相同,只不过这次它被“增强”了,因为提供给它的是质量更高、经过重排的文档。
动作(增强,augment) :
PromptBuilder 会接收原始用户问题,以及来自 ranker 的高排名文档,并把这些高相关上下文巧妙地填入 Prompt 模板中。
动作(生成,generate) :
这个最终增强后的 Prompt 会被发送给 LLM(OpenAIGenerator)。LLM 会读取这些质量更高的上下文,并仅基于这些信息生成最终答案——一个更准确、上下文依据更充分的回答。
接下来,合乎逻辑的一步,就是比较朴素 RAG 与混合 RAG Pipeline 的表现。为了简化后续对这两条 Pipeline 的调用与评估,我们会将它们封装为 SuperComponents。正如第 3 章介绍的那样,SuperComponent 是一种抽象,它允许我们把整个 Pipeline 当作一个组件来使用。
除了能够把复杂工作流像组件一样连接起来之外,抽象还有一个额外好处:它可以简化复杂的输入 / 输出结构。在第 6 章中,我们将使用不同的 embedding 模型,对朴素 RAG SuperComponent 和混合 RAG SuperComponent 进行系统性评估。
本节中,我们将演示如何把前面构建的整个朴素 RAG 与混合 RAG Pipeline 重构为可复用的 SuperComponent。实现方式是:将 Pipeline 传入 SuperComponent 类中。同时,我们还会使用**输入类型映射(input type casting)与输出映射(output mapping)**来定义这个新组件的公共接口。
在保持我们原先定义的朴素与混合 Pipeline 不变的前提下,假设它们分别命名为 naive_rag_pipeline 和 hybrid_rag_pipeline,那么把它们重构为 SuperComponent 可以通过两种方式完成。
第一种方法,是对一个已经实例化完成的 Pipeline 进行包装。当你已经定义好了某个 Pipeline 对象,并希望在不修改其底层类结构的前提下,快速把它抽象出来时,这种方法最合适:
from haystack import SuperComponent
# Naive RAG
naive_rag_sc = SuperComponent(
pipeline=naive_rag_pipeline,
input_mapping={
"query": [
"text_embedder.text",
"prompt_builder.question"
]
},
output_mapping={
"llm.replies": "replies",
"retriever.documents": "documents"
}
)
# Hybrid RAG
hybrid_rag_sc = SuperComponent(
pipeline=hybrid_rag_pipeline,
input_mapping={
"query": [
"text_embedder.text",
"bm25_retriever.query",
"ranker.query",
"prompt_builder.question"
]
},
output_mapping={
"llm.replies": "replies",
"ranker.documents": "documents"
}
)
这样做的结果,是应用逻辑得到了显著简化。主 Pipeline 现在变得非常简单,只包含一个单独的组件,而这个组件本身就代表了我们整个复杂的 RAG 系统。重构,以及输入输出映射,也带来了一个更简洁的接口。
原先,运行 Pipeline 所需的输入输出映射是这样的:
naive_rag_pipeline.run({
"text_embedder": {"text": question},
"prompt_builder": {"question": question}
})
hybrid_rag_pipeline.run({
"text_embedder": {"text": question},
"bm25_retriever": {"query": question},
"ranker": {"query": question},
"prompt_builder": {"question": question}
})
而一旦封装成 SuperComponent,我们就可以这样执行查询:
naive_rag_sc.run(query=question)
hybrid_rag_sc.run(query=question)
这种方法提供了一种快速方式,可以把一个 Pipeline 包装成可复用组件。但它也存在局限:如果我们想更换 generator 组件,或者更换 document store,就必须手动去修改 Pipeline 本身。对于那些希望把变量作为输入传入的 SuperComponent,我们就需要看第二种方法。
虽然包装已有 Pipeline 的方式很快捷,但第二种方法——定义一个用 @super_component 装饰的类——在能力与模块化程度上要强大得多。通过定义类,我们可以把 Pipeline 生成器当成一个可定制的蓝图来使用。这种方法允许我们在 __init__ 方法中暴露初始化参数。
这对复用性尤其有帮助:它允许你实例化同一种 RAG 架构,但使用不同配置。比如,你可以使用同一个 NaiveRAGSuperComponent 类来创建两个不同的 Pipeline:一个连接到 Elasticsearch document store,另一个连接到 in-memory document store;或者你也可以很方便地切换 embedding 模型(例如,从 text-embedding-3-small 切换到本地托管模型),只需要在初始化时传入不同参数即可。
下面两个脚本给出了这种更稳健、基于类的方法的实现示例:
为了更好理解这种基于类的实现方式中的逻辑,我们来梳理一下代码执行流程。
我们首先定义类结构及其初始化参数。在 __init__ 方法中,我们为组件建立蓝图,使其能够在运行时动态配置。我们不再把具体值写死,而是接受诸如 embedding 模型、LLM 模型以及 top-k 检索参数等输入。这种设计确保了我们的 SuperComponent 不只是一个静态脚本,而是一个灵活的对象——它甚至会在尝试构建 Pipeline 之前,先检查必要的凭据是否存在,例如模型 API key。
当配置设定完成后,我们就进入 _build_pipeline 方法中定义的内部组装逻辑。在这里,我们初始化完成任务所需的具体组件:用于向量化查询的 text embedder、用于搜索 Elasticsearch 存储的 retriever、用于格式化上下文的 prompt builder,以及用于生成最终答案的 generator。需要注意的是,你也可以选择不同的 generator,例如 OllamaGenerator,从而使用 OpenAI 之外的开源模型。
接着,我们创建一个标准的 Pipeline() 对象,并把这些组件加入其中。之后的过程和我们之前的做法一样:显式使用 pipeline.connect() 方法连接各组件,画出清晰的“线路”,让数据从 embedder 的输出流向 retriever,再从 retriever 找到的文档流向 prompt builder。
最后,我们通过输入与输出映射,把这种内部复杂性抽象掉。这一步才真正把 Pipeline 转换成一个单一、易用的组件。我们定义一个输入映射,使得外部只需传入一个 query,它就会在内部被同时路由给 embedder 和 prompt builder。同样地,我们也定义一个输出映射,只暴露用户真正关心的内容:LLM 最终回复,以及供参考使用的检索文档。
通过这种包装方式,我们把整条装配线内部复杂的“接线逻辑”都隐藏进组件内部,只向应用的其他部分暴露一个简单、干净的接口。
通过使用 @super_component 装饰器以及专门的类结构,我们已经把原本的 Pipeline 从一个静态脚本,转变为一个灵活的软件组件,使其能够无缝融入更大的应用系统中。接下来,我们来看多模态 Pipeline。
在前面的章节中,我们已经建立了稳健的文本处理与检索 Pipeline。然而,现实世界中的知识,往往被锁在非文本格式中,例如图像、图表和音频记录。本节将把我们的架构扩展到多模态 RAG。
与基于文本的 RAG 不同,文本 RAG 中查询与文档共享同一种模态(文本),也共享同质化的向量空间;而多模态 RAG 必须跨越这种模态鸿沟(modality gap) 。我们无法在数学上直接比较一个文本查询与一个二进制图像文件。
为了解决这个问题,我们采用两种主要策略:
我们将通过一系列 Notebook 来探索这些策略,并从基础图像处理逐步过渡到复杂的音视频推理。
第一种方法使用诸如 CLIP(Contrastive Language-Image Pretraining) 这样的模型。这类模型经过训练,能够把图像与文本投影到同一个潜在向量空间(latent vector space)中。这样一来,我们就可以使用自然语言来搜索图像,而不需要显式标签。
这个 Notebook 介绍了 Haystack 中的 sentence-transformers 文档图像 embedding 组件。通过使用例如 sentence-transformers/clip-ViT-L-14 这样的模型,我们可以把本地图像文件转换为向量表示,而这些向量会在几何空间上接近其文本描述对应的向量。
通过这个 Notebook,我们可以:
但如果想把这种方式推广到大规模场景,我们就必须构建一个能够处理混合数据流的索引 Pipeline。
这个 Pipeline 使用 FileTypeRouter 组件,根据 MIME type 将输入文件分流:
文本分支(Text branch):
PDF 会被路由到标准的 PyPDFToDocument 转换器以及文本 embedder。
图像分支(Image branch):
图像会被路由到专门的 ImageFileToDocument 转换器以及图像 embedder。
粘合层(The glue):
我们引入了一个自定义组件:ImagePathFixer。标准转换器可能只会存储文件名,但 embedding 组件通常需要绝对路径。这个组件会在向量化之前补全这些路径。
该 Pipeline 的 Mermaid 图可在以下 URL 中查看:
最终结果是一个统一的 InMemoryDocumentStore:图像与文本在其中共存,并且可以通过同一个查询 embedding 模型来进行检索。
接下来我们再看第二种策略。
虽然 CLIP 在视觉相似性方面非常出色,但它并不擅长读取图像中的细节文字,或者分析复杂图表。对此,我们需要借助视觉 LLM(vision LLM) ,例如 GPT-4o。
在这个工作流中,我们会用 LLMDocumentContentExtractor 组件替代图像 embedder。该组件会将图像发送给视觉 LLM,由其生成一段详细的文本描述。然后,我们再使用高性能文本模型(例如 mixedbread-ai/mxbai-embed-large-v1)对这段描述生成 embedding。
这种方式实际上是把图像“转化”为文本,从而使我们能够使用标准的、高精度的文本检索工具。
一个用于探索基于视觉 LLM 的完整索引流程的 Jupyter Notebook 可在以下位置找到:
和前面一样,我们仍然可以使用 router 组件对不同类型文档进行路由,从而对 PDF 文件使用文本 embedding 模型,对图像文件使用视觉模型。该 Pipeline 的 Mermaid 图可在以下 URL 中查看:
下面我们来拆解这个索引 Pipeline 的关键步骤:
文本分支(Text branch):
PDF 会被路由到标准的 PyPDFToDocument 转换器。这一分支上不直接应用 embedding。
图像分支(Image branch):
图像会被路由到视觉模型,由其提取图像信息。这一分支上同样不直接应用 embedding。
粘合层(The glue):
我们使用 Haystack 的 DocumentJoiner 组件,把处理后的文档合并起来,然后在这些 chunk 之上统一应用同一个文本 embedding 模型。
当索引过程完成后,我们就可以像构建朴素 RAG 与混合 RAG Pipeline 那样,继续构建对应的 RAG Pipeline。这样一来,我们就能通过自然语言,从文本和图像中共同检索信息。
一个用于探索基于视觉 LLM 的完整 RAG 流程的 Jupyter Notebook 可在以下位置找到:
这个 Pipeline 代表了当前多模态 RAG 的先进形态。它采用的是一种**“通过代理进行检索,通过源数据进行回答(search by proxy, answer by source)”**的逻辑:
检索(Retrieve):
我们使用索引阶段生成的文本描述,在 DocumentStore 中进行搜索。
生成(Generate):
当找到相关文档后,Pipeline 会把原始二进制图像(通过元数据引用)传递给 generator。
在这种场景下,视觉 LLM 会直接查看桥梁的原始照片来回答问题。它并不是依赖前面生成的“代理描述”,而是在源材料上重新执行一次视觉推理。
这种架构可以提供尽可能高的保真度。文本描述仅仅作为一个稳健的索引键存在,而在生成阶段,则完整保留了原始模态的全部分辨率信息。
这个 Pipeline 的 Mermaid 图可在以下 URL 中查看:
如果不讨论第三种主要数据类型——音频——我们对多模态的探索就是不完整的。从季度财报电话会议到客服对话,大量企业智能都被锁在 .wav 与 .mp3 文件中。
与具有空间结构的图像不同,音频必须先被线性化,也就是转写为文本,才能兼容向量检索。
一个演示音频集成的 Jupyter Notebook 可在以下位置找到:
这个 Pipeline 使用 RemoteWhisperTranscriber 组件,将音频文件(如 .wav 或 .mp3)转换为文本文档。
这里有一个至关重要的步骤,就是使用 DocumentSplitter 组件进行分段,并将其配置为 split_by="sentence"。这一流程如图 4.2 所示。它会把长篇转写文本切分成语义连贯的 chunk(例如每 10 句话为一个 chunk),从而确保检索系统能够准确定位对话中的特定时刻,而不是每次都把整段一小时长的录音都取回来。
这个 Pipeline 当前被保留为一个简单的音频转写器,但它可以进一步扩展,以处理本章中见到的各种文件类型。
本章最后,我们将对 Pipeline 的并行化与异步使用方式做一个简要概述。
在前面的几节中,我们已经设计出了结构完整、功能丰富的 Pipeline。然而,仅有结构合理,并不自动意味着性能优秀。当我们从本地原型走向生产环境时,系统延迟就会成为一个关键约束。现实中的 RAG 应用,很少真正受限于 CPU 速度;它们更多是受制于输入 / 输出(I/O)操作。系统执行时间的绝大部分,实际上都花在“等待”上,例如等待 embedding API 返回向量、等待数据库完成检索,或者等待 LLM 生成 token。
在标准的同步 Pipeline 中,这些等待时间是会累加的。假设一次混合检索需要执行一次稠密检索(0.5 秒)和一次稀疏检索(0.5 秒),那么用户就需要等待 1.0 秒。为了解决这个问题,Haystack 引入了并行化与异步 Pipeline。这一高级能力使我们能够把彼此独立的操作解耦开来,并发执行,从而显著降低总延迟。
一个实现了这种异步架构的 Jupyter Notebook 可在以下位置找到:
异步 Pipeline 的构建方式,与标准版本几乎完全相同,只不过我们实例化的是 AsyncPipeline 类,而不是 Pipeline 类。
虽然它在添加和连接组件时,与标准 Pipeline 类共享相似的 API,但它内部的执行图在本质上是不同的。
AsyncPipeline 类会分析这个有向多重图,以识别其中彼此独立的分支。在一个线性 Pipeline 中(A -> B -> C),是没有并行空间的,因为 B 依赖于 A。而在一个带分支的 Pipeline 中(A -> B 且 A -> C),节点 B 和 C 虽然都依赖 A,但它们彼此之间是独立的。AsyncPipeline 会识别出这种拓扑结构,并把 B 和 C 调度为并发执行的 asyncio.Task 对象。
AsyncPipeline 还提供了专门的方法,以满足不同应用场景的需求,尤其适用于那些“感知延迟”非常关键的聊天类应用:
run_async():
这个方法以异步方式执行 Pipeline。它是非阻塞的,非常适合 Web 服务器(例如 Fatai)场景,或者在需要同时处理多个用户查询时使用。
run_async_generator():
这是流式执行方法。它会随着各组件的完成,逐步产出部分输出。
这种流式能力对于调试和用户反馈尤其有价值。我们不必等到整个流程全部结束,才能看到结果;相反,我们可以先看到 retriever 完成工作,甚至在 LLM 开始生成之前,就已经获得中间状态反馈。
通过掌握并行化,开发者可以确保自己的 Pipeline 不仅“聪明”,而且也足够“敏捷”,能够满足实时用户交互的严格要求。
至此,我们就完成了关于如何在 Haystack 2.0 中把组件组合起来的完整指南。我们已经从图结构的基础布局,一路走到异步执行的精细优化,为现代 NLP 架构提供了一份完整蓝图。
本章中,我们从 Haystack 2.0 的理论概念,进一步走向了具体实现。我们探讨了它的核心设计哲学——有向多重图(directed multigraphs) ,这种结构使得分支与灵活数据流成为可能。
我们构建了三类不同的 Pipeline:
索引 Pipeline:
我们构建了一个稳健的数据摄取系统,利用 FileTypeRouter 同时处理结构化数据(CSV)与非结构化数据(PDF、Web),并将它们规范化后写入统一的文档存储中。
RAG Pipeline:
我们从一个仅依赖语义 embedding 检索的朴素 RAG 系统出发,逐步发展到一个混合 RAG 系统。混合方法通过引入分支机制,把稀疏检索(BM25)的精确匹配能力与稠密检索的上下文理解能力结合起来,并通过 reranker 进一步优化精度。
多模态 Pipeline:
我们打通了文本、图像和音频之间的模态鸿沟。我们使用 CLIP 实现了联合 embedding,使得可以用文本搜索图像;同时也实现了视觉 RAG,使 LLM 能够直接“看见”图像并对其进行推理。
最后,我们又通过 SuperComponents 提升模块化能力,并通过 异步 Pipeline 实现并行执行,对这些工作流进行了优化。
在下一章中,我们将深入研究自定义组件的创建。尤其是,我们将开发一些自定义组件,用于从文档语料中生成知识图谱和合成数据。随后,在第 6 章中,我们会将这些自定义组件与朴素 RAG / 混合 RAG 的 SuperComponents 结合起来,对这两种方法进行系统性评估,并在更换 embedding 模型时测量性能表现。

