
意项
39.91M · 2026-03-23

ClaudeCode 结合 智谱 GLM Coding 完美使用教程: juejin.cn/post/759204…
本文档详细分析了 ClaudeCode/KiloCode 项目中文件处理的核心机制,包括大文件读取策略、多层保护机制、流式读取实现、Token 预算控制和配置化管理。
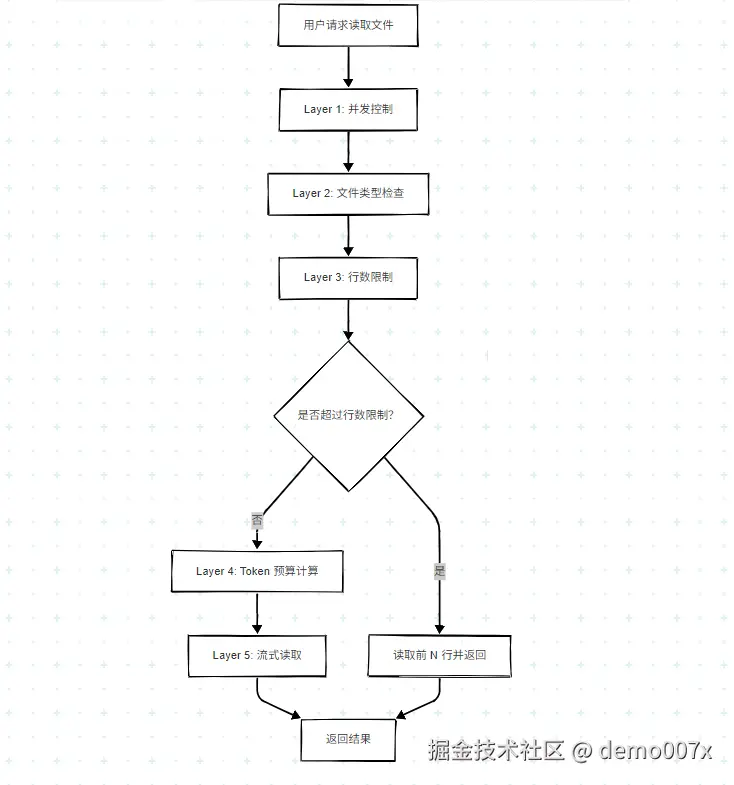
maxReadFileLine)默认值: 500 行
当文件总行数超过此阈值时,自动截断只读取前 N 行。设置为 -1 或 0 时禁用行数限制;设置为 0 时仅显示代码定义,不读取文件内容。
重要说明: 当 maxReadFileLine = -1 时:
read_file 工具:仍受 Token 预算(60%)限制,文件会被截断maxConcurrentFileReads)默认值: 5 个文件
限制 read_file 工具单次请求中最多可以读取的文件数量。
场景示例:
@file1 @file2 ... @file6)read_file 请求,包含 6 个文件路径目的: 防止单次请求读取过多文件导致内存溢出或 Token 超出限制。
FILE_READ_BUDGET_PERCENT)默认值: 60%(硬编码常量,无用户配置项)
可用上下文窗口的 60% 用于文件读取,剩余 40% 用于模型响应生成。
注意: 这是一个硬编码的常量,定义在 src/core/tools/helpers/fileTokenBudget.ts 中,没有对应的用户配置项。
allowVeryLargeReads)默认值: false
预留功能,当前在代码中无实际调用点。
常量: SIZE_LIMIT_AS_CONTEXT_WINDOW_FRACTION = 0.8(80% 上下文窗口)
重要说明: 这个 80% 限制是通过 blockFileReadWhenTooLarge() 函数实现的,但该函数当前未被调用,属于预留功能。
实际生效的限制:
maxReadFileLine(默认 500 行)FILE_READ_BUDGET_PERCENT(60%)默认值: false
作用: 当启用时(allowVeryLargeReads = true),跳过 80% Token 限制检查。
当前状态: 该配置项在 read_file 工具的执行流程中不被直接使用。kilocode.ts 中定义的两个函数 summarizeSuccessfulMcpOutputWhenTooLong() 和 blockFileReadWhenTooLarge() 均未被调用。
重要说明:
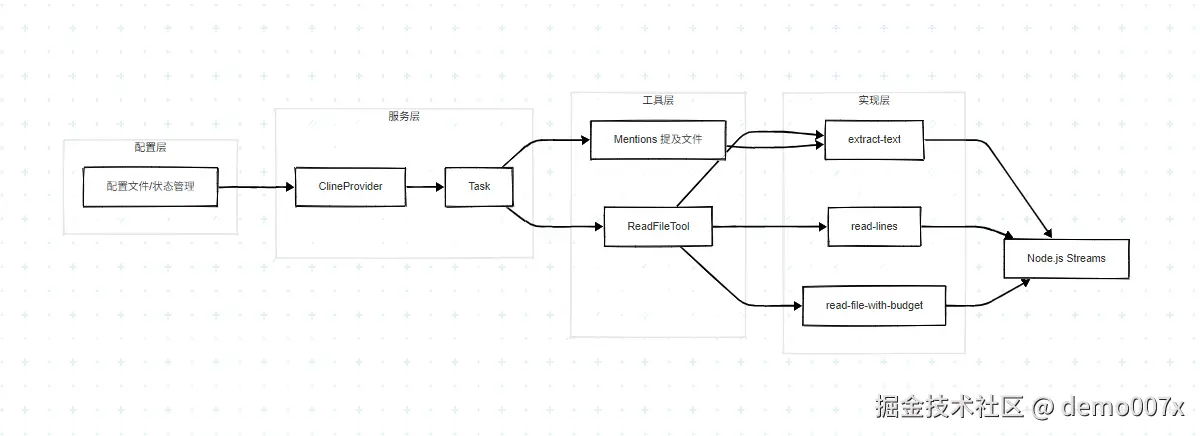
SIZE_LIMIT_AS_CONTEXT_WINDOW_FRACTION)和 60% Token 预算(FILE_READ_BUDGET_PERCENT)是独立的两层限制allowVeryLargeReads,跳过 80% 限制检查,read_file 工具仍然使用 60% Token 预算限制allowVeryLargeReads 后,文件读取仍然受 60% Token 预算限制当用户使用 @file 提及文件时,文件内容通过 getFileOrFolderContent 函数读取,该函数调用 extractTextFromFile 提取文本。
执行流程:
@file 提及 → getFileOrFolderContent() → extractTextFromFile()
maxReadFileLine = -1 时的问题:
| 场景 | read_file 工具 | @file 提及文件 |
|---|---|---|
| maxReadFileLine = -1 | 受 Token 预算(60%)限制,文件会被截断 | 不受 Token 预算限制,读取完整文件 |
| 结果 | 安全,不会超出 token | 可能导致"超出 token"错误 |
原因分析:
read_file 工具:有 Token 预算计算建议:
maxReadFileLine = -1 配置line_range 参数或使用 read_file 工具问题根源:extractTextFromFile 函数在 src/integrations/misc/extract-text.ts 第 96-109 行的逻辑:
// 第 96-107 行:行数限制检查
if (maxReadFileLine !== undefined && maxReadFileLine !== -1 && maxReadFileLine !== 0) {
const totalLines = await countFileLines(filePath)
if (totalLines > maxReadFileLine) {
// 读取指定行数并返回截断提示
...
}
}
// 第 109 行:无限制时直接读取整个文件
return addLineNumbers(await fs.readFile(filePath, "utf8"))
执行流程对比:
| 组件 | 调用位置 | maxReadFileLine = -1 时的行为 | Token 检测 |
|---|---|---|---|
read_file 工具 | src/core/tools/ReadFileTool.ts:507-604 | 跳过行数限制 → 进入 Token 预算计算 → 调用 readFileWithTokenBudget | 有 |
extractTextFromFile | src/integrations/misc/extract-text.ts:109 | 跳过行数限制 → 直接 fs.readFile() 读取完整文件 | 无 |
影响范围:
@file 提及文件 (src/core/mentions/index.ts:303):
const content = await extractTextFromFile(absPath, maxReadFileLine)
当 maxReadFileLine = -1 时,会读取完整文件内容,可能导致 Token 超出。
@folder 提及文件夹 (src/core/mentions/index.ts:335-357):
// absoluteFilePath 是具体文件的路径(文件夹路径 + 文件名)
const absoluteFilePath = path.resolve(absPath, entry.name)
// 使用 Promise.all 并行读取所有文件
const fileContents = (await Promise.all(fileContentPromises)).filter((content) => content)
文件夹内的文件并行读取,每个文件都受 maxReadFileLine = -1 影响,会读取完整内容。
二进制文件提取 (src/core/tools/ReadFileTool.ts:420):
const content = await extractTextFromFile(fullPath) // 不传 maxReadFileLine
PDF、DOCX 等文件不传 maxReadFileLine 参数,会读取完整内容。
使用 Node.js createReadStream 流式读取文件,达到目标行号后立即终止流,不读取剩余内容。内存占用仅与 chunk 大小相关,与文件大小无关。
使用流式读取逐行统计文件总行数。
流式读取过程中逐步计算 Token 数,可在达到 Token 预算时提前退出。
说明: 这是在 Node.js 进程中读取文件到内存的过程,不是在 LLM 会话中。
缓冲区(lineBuffer) : 内存中的字符串数组,用于临时存储从文件读取的行。
核心算法:
逐行读取文件:使用 Node.js createReadStream 流式读取
累积行缓冲:每读一行放入 lineBuffer,默认累积 256 行
暂停读取:达到 256 行时暂停,计算这 256 行的 Token 数
检查预算:
返回结果:实际读取的内容、Token 数和完成状态
示例(预算 1000 Token,文件 10000 行):
第 1 批 256 行 → 300 Token → 累计 300 Token → 继续
第 2 批 256 行 → 300 Token → 累计 600 Token → 继续
第 3 批 256 行 → 300 Token → 累计 900 Token → 继续
第 4 批 256 行 → 300 Token → 累计 1200 Token → 超出!
└─> 二分查找:只保留前 80 行(约 100 Token)
└─> 最终返回:672 行,998 Token
可用预算 = (上下文窗口 - 最大输出 Token - 已用 Token) × 60%
执行顺序:
关键点:
说明:
如果 LLM 返回了 line_range 参数(如 10-50),会优先使用行范围读取
代码定义结构:
line_range)重要: 如果 LLM 返回了 line_range 参数(如 10-50),会优先使用行范围读取,直接返回指定行内容,不再执行后续的 maxReadFileLine 检查和 Token 预算检查。
使用 fs.stat() 获取文件状态,通过 stats.isDirectory() 判断是否为目录。如果是目录,返回错误提示建议使用 list_files 工具。
错误提示: Cannot read 'xxx' because it is a directory. To view the contents of a directory, use the list_files tool instead.
使用 isbinaryfile 库检测文件是否为二进制文件。
分类处理:
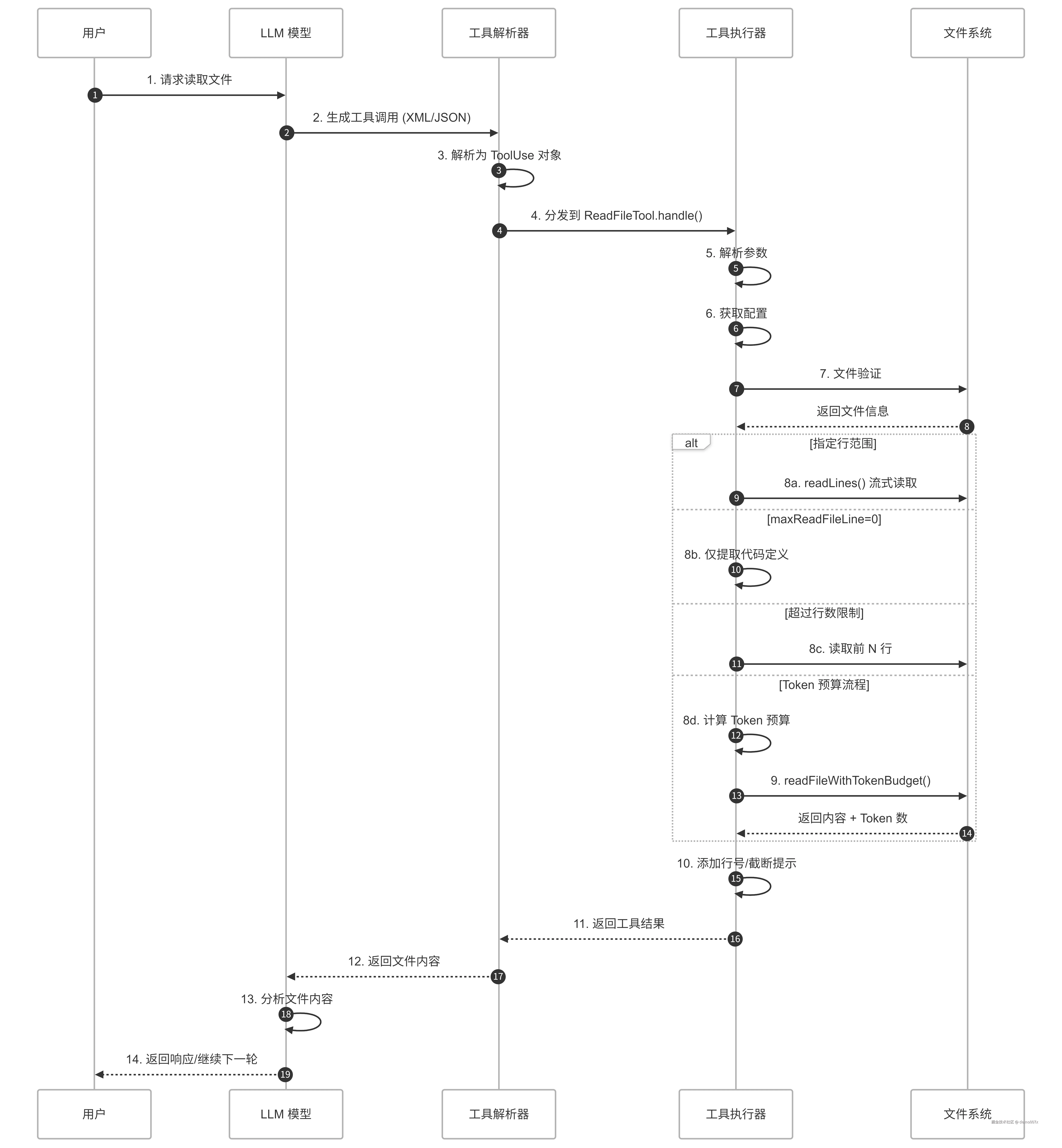
.png, .jpg, .jpeg, .gif, .webp, .svg, .bmp, .ico, .tiff, .tif, .avif): 验证大小和内存限制后返回 Data URL.pdf): 使用 pdf-parse 提取文本.docx): 使用 mammoth 提取文本.ipynb): JSON 解析提取 cell 内容.xlsx): 使用 extractTextFromXLSX 提取文本大文件读取的工具调用流程涉及 LLM 的 Function Call 机制和框架内部工具执行。
系统 Prompt 是 LLM 行为的决定性因素。在 Kilo Code 中,read_file 工具的描述通过系统 Prompt 传递给 LLM,明确说明了以下关键指令:
实现位置: src/core/prompts/tools/read-file.ts
// 工具描述
Description: Request to read the contents of one or more files.
The tool outputs line-numbered content (e.g. "1 | const x = 1")
for easy reference when creating diffs or discussing code.
// 并发限制指令
**IMPORTANT: You can read a maximum of ${maxConcurrentReads} files in a single request.**
If you need to read more files, use multiple sequential read_file requests.
// 行范围(line_range)使用指令
By specifying line ranges, you can efficiently read specific portions of large files
without loading the entire file into memory.
// 行范围参数说明
- line_range: (optional) One or more line range elements in format "start-end" (1-based, inclusive)
// 高效读取策略
IMPORTANT: You MUST use this Efficient Reading Strategy:
- You MUST read all related files and implementations together in a single operation
- You MUST obtain all necessary context before proceeding with changes
- You MUST use line ranges to read specific portions of large files
- You MUST combine adjacent line ranges (<10 lines apart)
- You MUST use multiple ranges for content separated by >10 lines
- You MUST include sufficient line context for planned modifications while keeping ranges minimal
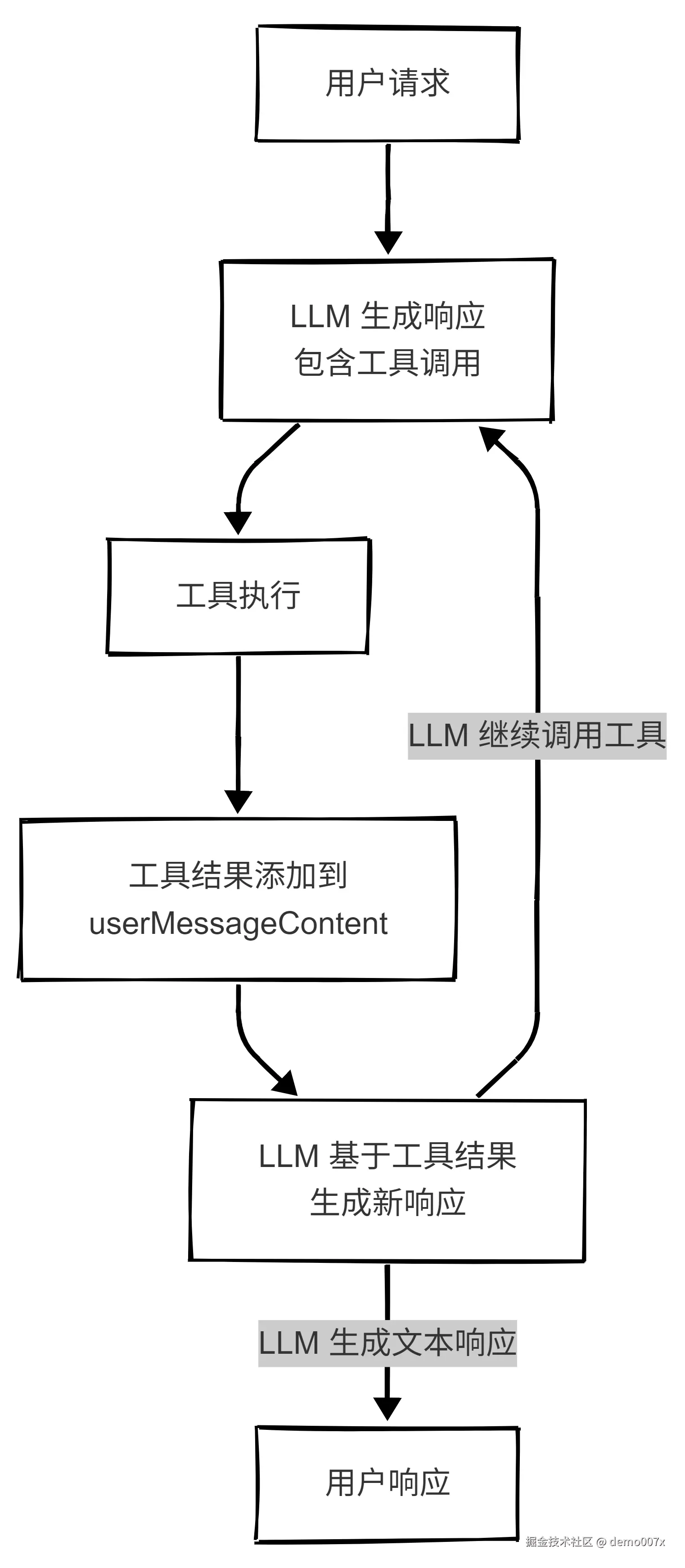
单对话内单工具调用说明:
根据 presentAssistantMessage.ts:535-686 的代码,每个 LLM 响应中只能使用一个工具:
// 关键代码:didAlreadyUseTool 标志控制
if (cline.didAlreadyUseTool) {
// 忽略后续工具调用
const errorMessage = `Tool was not executed because a tool has already been used in this message.`
break
}
// 工具执行完成后设置标志
if (toolProtocol === TOOL_PROTOCOL.XML) {
cline.didAlreadyUseTool = true // XML 协议:单工具
} else if (toolProtocol === TOOL_PROTOCOL.NATIVE && !isMultipleNativeToolCallsEnabled) {
cline.didAlreadyUseTool = true // 原生协议:单工具(默认)
}
关键特点:
didAlreadyUseTool 标志控制)userMessageContent 中为什么采用单工具调用设计:
read_file 等工具支持批量操作(通过 maxConcurrentFileReads 配置,默认单次读取 5 个文件),弥补了单工具调用的限制。在 Kilo Code 中,Ask 模式和Code 模式是两种不同的工作模式,它们在文件读取行为上有一些重要区别。
ask): 专注于回答问题、提供建议,通常不涉及文件修改code): 专注于代码编写、修改和文件操作| 特性 | Ask 模式 | Code 模式 |
|---|---|---|
| 文件读取权限 | 支持 | 支持 |
| 文件修改权限 | 不支持 | 支持 |
| 默认读取行数限制 | 500 行 | 500 行 |
| 可使用工具 | 有限(只读工具) | 完整(包括写操作工具) |
Ask 模式可用工具(只读):
read_file - 读取文件内容list_files - 列出目录内容search_files - 搜索文件内容codebase_search - 代码库语义搜索ask_followup_question - 询问用户attempt_completion - 完成任务Code 模式额外可用工具(包括写操作):
write_to_file - 写入文件apply_diff - 应用代码差异edit_file - 编辑文件(使用 search/replace)fast_edit_file - 快速编辑文件(Morph Fast Apply)execute_command - 执行命令delete_file - 删除文件search_and_replace - 使用搜索和替换应用更改search_replace - 应用单个搜索和替换apply_patch - 应用 codex 格式的补丁browser_action - 使用浏览器use_mcp_tool - 使用 MCP 工具access_mcp_resource - 访问 MCP 资源generate_image - 生成图像update_todo_list - 更新待办列表run_slash_command - 运行斜杠命令重要:无论在 Ask 模式还是 Code 模式下,read_file 工具的核心读取逻辑是完全一致的:
maxReadFileLine 配置限制| 错误类型 | 处理方式 |
|---|---|
| 目录 | 返回错误提示,建议使用 list_files 工具 |
| 二进制文件 | 支持的格式(PDF/DOCX/XLSX)提取文本,不支持的返回格式提示 |
| Token 预算不足 | 返回空内容并提示无可用预算 |
| 代码定义解析错误 | 不支持的语言静默处理,其他错误记录日志 |
| 状态 | 说明 |
|---|---|
| pending | 初始状态 |
| blocked | 行范围错误或文件访问限制 |
| approved | 用户确认 |
| denied | 用户拒绝 |
| error | 读取过程出错 |
| 配置项 | 默认值 | 说明 |
|---|---|---|
maxReadFileLine | 500 | 文件读取自动截断阈值(行数), 生效中 |
allowVeryLargeReads | false | 允许超大文件读取开关,️ 预留功能 |
maxConcurrentFileReads | 5 | 单次请求最多读取文件数, 生效中 |
| 场景 | 推荐配置 | 说明 |
|---|---|---|
| 常规开发 | maxReadFileLine: 500 | 默认配置,平衡性能和实用性 |
| 大文件分析 | maxReadFileLine: -1 | 禁用行数限制,仍受 Token 预算(60%)限制 |
| 代码审查 | maxReadFileLine: 0 | 仅查看代码定义,不读取内容 |
| 批量文件读取 | maxConcurrentFileReads: 10+ | 增加并发数以提高效率 |
line_range 参数精确读取需要的部分maxReadFileLine: 0 先查看代码定义,再定位具体位置| 文件 | 说明 |
|---|---|
src/core/tools/ReadFileTool.ts | 主要文件读取工具实现 |
src/core/tools/helpers/fileTokenBudget.ts | Token 预算配置 |
src/core/tools/kilocode.ts | 超大文件读取开关逻辑 |
src/integrations/misc/read-file-with-budget.ts | 基于 Token 预算的流式读取 |
src/integrations/misc/read-lines.ts | 按行范围流式读取 |
src/integrations/misc/line-counter.ts | 行数和 Token 计数 |
src/integrations/misc/extract-text.ts | 文本提取(支持行数限制) |
src/core/webview/ClineProvider.ts | 状态管理和配置 |
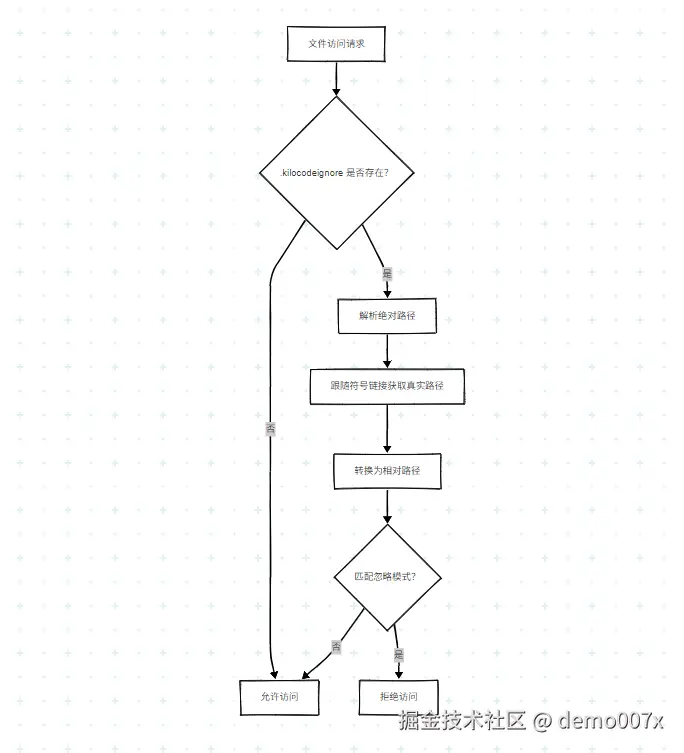
src/core/ignore/RooIgnoreController.ts | 文件访问控制 |
src/core/mentions/index.ts | @file 提及文件处理 |
allowVeryLargeReads 配置项(当前未使用)maxReadFileLine 配置项(默认 500 行)消息标签机制:
isSummary: 标记消息是否为摘要condenseId: 摘要的唯一 IDcondenseParent: 指向生成此摘要的原始消息组truncationParent: 指向截断操作的 IDisTruncationMarker: 标记是否为截断标记有效历史记录 (getEffectiveApiHistory()):
condenseParent 或 truncationParent 标签的消息truncateConversation())流程:
truncationParent 标签截断标记:
{
role: "user",
content: `[Sliding window truncation: ${messagesToRemove} messages hidden to reduce context]`,
ts: firstKeptTs - 1,
isTruncationMarker: true,
truncationId,
}
summarizeConversation())消息范围确定 (getMessagesSinceLastSummary()):
isSummary=true 的消息压缩流程:
isSummary 和 condenseId 标签)condenseParent 标签manageContext())触发条件:
const contextPercent = (100 * prevContextTokens) / contextWindow
if (contextPercent >= effectiveThreshold || prevContextTokens > allowedTokens) {
// 触发压缩
}
处理流程:
summarizeConversation())完整历史 (apiConversationHistory)
↓
getEffectiveApiHistory() - 过滤被压缩/截断的消息
↓
发送给 API 的有效消息
关键点:
本文档基于 ClaudeCode / KiloCode 项目源代码分析生成,最后更新时间:2026-03-05

