

闪电疯狂赛车
91.44M · 2026-03-23

在分布式系统中,定时任务调度是一个常见但又极具挑战性的技术问题。传统的单机定时任务框架如Spring Task、Quartz等,在分布式环境下存在明显的局限性:
ElasticJob正是为解决这些问题而诞生的分布式调度解决方案。本文将带你从零开始,全面掌握ElasticJob的使用方法,并通过实际案例展示其在生产环境中的应用价值。
ElasticJob是当当网开源的分布式调度解决方案,于2015年开源,2020年成为Apache ShardingSphere的子项目。它由两个相互独立的子项目组成:
本文聚焦于ElasticJob-Lite,因为它更易于部署和使用,适合大多数企业场景。
ElasticJob最核心的特性是弹性扩容能力。当业务量增加时,只需增加应用实例,ElasticJob会自动重新分配任务分片,无需人工干预。这种特性使得系统能够从容应对业务峰值。
采用无中心化设计,不存在单点故障。任意节点宕机,其他节点会自动接管该节点负责的任务分片,保证任务继续执行。
支持Simple Job(简单作业)、Dataflow Job(流式作业)、Script Job(脚本作业)、HTTP Job(HTTP作业)等多种作业类型,满足不同场景需求。
提供独立的运维控制台,支持作业配置、坚控、启停等操作,降低运维成本。
ElasticJob适用于以下典型场景:
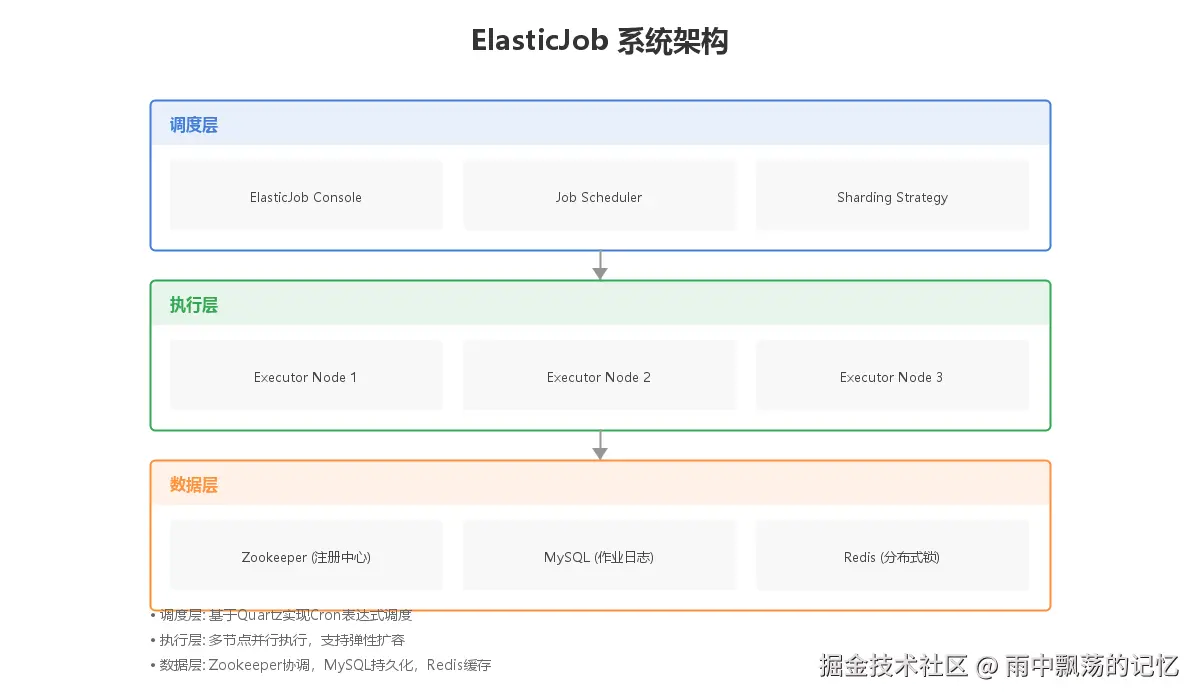
ElasticJob采用分层架构设计,从上到下分为调度层、执行层和数据层。
调度层是ElasticJob的核心,负责任务的调度触发和分片计算:
执行层由多个应用实例组成,每个实例都是一个执行节点:
数据层提供分布式协调和数据持久化能力:
分片是ElasticJob中最核心的概念。一个任务可以被拆分为多个分片,每个分片是任务执行的最小单位。例如,一个处理100万用户数据的任务,可以拆分为10个分片,每个分片处理10万用户数据。
分片项是分片的唯一标识,从0开始编号。例如3个分片,分片项分别是0、1、2。
每个分片可以配置不同的参数,用于传递业务相关的信息。例如分片0处理北京地区用户,分片1处理上海地区用户。
ElasticJob使用Quartz的Cron表达式定义任务执行时间,支持秒级精度的复杂调度规则。
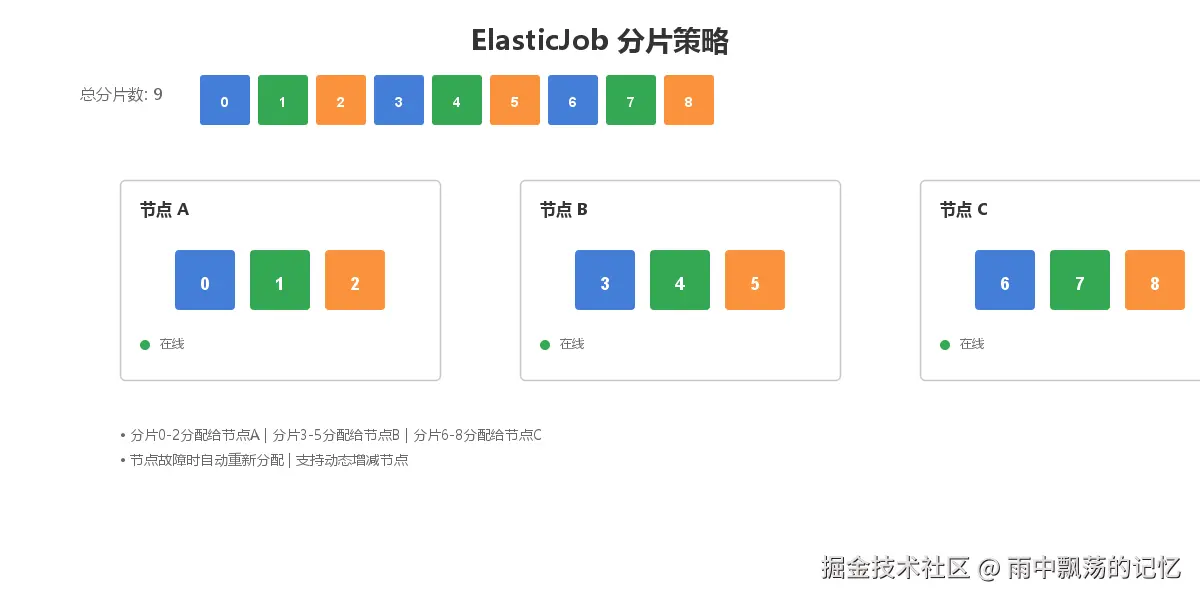
ElasticJob通过分片实现任务的分布式执行。核心思想是:将任务数据按照某种规则(如ID取模)分配到不同分片,每个分片由一个节点负责执行。
假设有一个处理订单数据的任务,总分片数为3:
// 订单ID为1,4,7,...的订单会被分配到分片0
// 订单ID为2,5,8,...的订单会被分配到分片1
// 订单ID为3,6,9,...的订单会被分配到分片2
int shardingItem = orderId % 3;
ElasticJob提供了多种内置分片策略:
最常用的分片策略,将分片平均分配到各个节点。例如9个分片、3个节点,每个节点分配3个分片。
按照分片项的奇偶数分配到不同节点,适合两节点场景。
所有分片都分配给第一个在线节点,适合单节点场景。
根据配置文件的配置进行分配,适合复杂的分配场景。
当节点发生上下线时,ElasticJob会自动触发重新分片:
这个过程对业务完全透明,无需人工干预。
分片参数是ElasticJob非常实用的功能,可以为每个分片配置不同的业务参数。例如:
elasticjob:
jobs:
dataSyncJob:
shardingTotalCount: 3
shardingItemParameters: 0=Beijing,1=Shanghai,2=Guangzhou
在代码中可以通过ShardingContext获取分片参数:
@Override
public void execute(ShardingContext context) {
String region = context.getShardingParameter("region");
// 根据地区参数处理该地区的业务数据
}
一个完整的任务执行包含以下10个步骤:
Job Scheduler根据配置的Cron表达式判断是否到达执行时间。ElasticJob支持Quartz的所有Cron表达式语法,可以实现复杂的调度规则。
从Zookeeper读取当前作业的分片配置,包括总分片数、分片项参数等。如果配置发生变化,使用最新的配置。
根据当前在线的节点数量,使用配置的分片策略计算每个节点应该负责的分片。这个计算过程在Zookeeper中完成,保证各节点计算结果一致。
各节点从Zookeeper获取自己负责的分片项。如果分片正在被其他节点执行(故障转移场景),会等待或跳过。
如果配置了器,在任务执行前调用beforeJobExecuted()方法。可以在此处做一些初始化工作,如建立数据库连接、加载配置等。
对每个获取到的分片项调用execute()方法。可以通过线程池配置并行执行多个分片,提高执行效率。
@Override
public void execute(ShardingContext context) {
int shardingItem = context.getShardingItem();
// 只处理属于当前分片的数据
List<Data> dataList = queryData(shardingItem);
for (Data data : dataList) {
processData(data);
}
}
任务执行完成后调用afterJobExecuted()方法,可以进行资源清理、记录执行结果等操作。
将执行结果持久化到数据库,包括成功数量、失败数量、执行时间等信息,方便后续查询和问题排查。
elasticjob:
jobs:
myJob:
cron: 0 */5 * * * ? # 每5分钟执行一次
shardingTotalCount: 3 # 总分片数为3
shardingItemParameters: 0=A,1=B # 分片参数
monitorExecution: true # 坚控执行状态
failover: true # 启用故障转移
misfire: true # 错过重跑
maxTimeDiffSeconds: 3600 # 最大时间差1小时
reconcileIntervalMinutes: 10 # 自诊断修复间隔10分钟
jobExecutorServiceHandlerType: SINGLE_THREAD # 单线程执行
ElasticJob支持4种作业类型,每种类型适用于不同的业务场景。
Simple Job是最基础的作业类型,实现SimpleJob接口,适合一次性执行的任务。
适用场景:数据清理、定时报表、数据统计等
代码示例:
@Component
public class DataCleanupJob implements SimpleJob {
@Autowired
private DataMapper dataMapper;
@Override
public void execute(ShardingContext context) {
int shardingItem = context.getShardingItem();
int shardingTotalCount = context.getShardingTotalCount();
// 只处理当前分片的数据
Date expireDate = DateUtils.addDays(new Date(), -90);
List<Data> expireData = dataMapper.selectExpireData(
expireDate, shardingItem, shardingTotalCount
);
for (Data data : expireData) {
dataMapper.delete(data.getId());
}
log.info("分片{}清理了{}条过期数据", shardingItem, expireData.size());
}
}
配置示例:
elasticjob:
jobs:
dataCleanupJob:
elasticJobClass: com.example.job.DataCleanupJob
cron: 0 0 2 * * ? # 每天凌晨2点执行
shardingTotalCount: 3
description: 数据清理作业
Dataflow Job适合持续处理数据流的场景,实现DataflowJob<T>接口,需要实现fetchData()和processData()两个方法。
适用场景:日志分析、数据同步、实时计算等
代码示例:
@Component
public class LogAnalysisJob implements DataflowJob<String> {
@Override
public List<String> fetchData(ShardingContext context) {
int shardingItem = context.getShardingItem();
// 从数据源抓取待处理的日志
List<String> logs = logService.fetchUnprocessedLogs(shardingItem, 1000);
// 返回null表示没有更多数据
return logs.isEmpty() ? null : logs;
}
@Override
public void processData(ShardingContext context, List<String> logs) {
for (String log : logs) {
try {
// 解析日志内容
LogEntry entry = parseLog(log);
// 统计分析
statisticsService.save(entry);
// 标记为已处理
logService.markProcessed(entry.getId());
} catch (Exception e) {
log.error("处理日志失败: {}", log, e);
}
}
}
}
配置示例:
elasticjob:
jobs:
logAnalysisJob:
elasticJobClass: com.example.job.LogAnalysisJob
cron: 0 */10 * * * ? # 每10分钟执行
shardingTotalCount: 2
streamingProcess: true # 流式处理,持续获取数据
description: 日志分析作业
流式处理特点:
fetchData()返回数据后,立即调用processData()处理fetchData()获取下一批数据fetchData()返回nullstreamingProcess: true启用流式处理Script Job可以执行Shell、Python等脚本,适合跨语言场景。
适用场景:运维脚本、备份任务、Python数据处理脚本等
配置示例:
elasticjob:
jobs:
backupJob:
jobType: SCRIPT
cron: 0 0 3 * * ? # 每天凌晨3点执行
scriptCommandLine: "/opt/scripts/backup.sh"
description: 数据备份作业
脚本示例(backup.sh):
#!/bin/bash
# 数据库备份脚本
BACKUP_DIR="/data/backup"
DATE=$(date +%Y%m%d_%H%M%S)
BACKUP_FILE="$BACKUP_DIR/db_backup_$DATE.sql"
mkdir -p $BACKUP_DIR
# 执行备份
mysqldump -h localhost -u root -p${DB_PASSWORD}
mydb > $BACKUP_FILE
# 压缩备份文件
gzip $BACKUP_FILE
# 删除7天前的备份
find $BACKUP_DIR -name "*.sql.gz" -mtime +7 -delete
echo "备份完成: $BACKUP_FILE"
HTTP Job通过HTTP调用远程服务执行任务,适合微服务架构或异构系统集成。
适用场景:跨语言调用、微服务任务触发、第三方系统集成
配置示例:
elasticjob:
jobs:
reportJob:
jobType: HTTP
cron: 0 0 4 * * ? # 每天凌晨4点执行
jobExecutorServiceHandlerType: HTTP
restfulUrl: "http://report-service/api/job/dailyReport"
description: 日报生成作业
HTTP接口示例(report-service):
@RestController
@RequestMapping("/api/job")
public class JobController {
@PostMapping("/dailyReport")
public Map<String, Object> dailyReport(@RequestBody Map<String, Object> params) {
String jobName = (String) params.get("jobName");
Integer shardingItem = (Integer) params.get("shardingItem");
// 生成日报
DailyReport report = reportService.generate(shardingItem);
return Map.of("success", true, "reportId", report.getId());
}
}
生产环境建议采用以下架构:
使用Nginx作为反向代理和负载均衡器,分发请求到各个应用节点。
upstream elasticjob_backend {
server 192.168.1.10:8080;
server 192.168.1.11:8080;
server 192.168.1.12:8080;
server 192.168.1.13:8080;
}
server {
listen 80;
location / {
proxy_pass ;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
}
}
Zookeeper集群至少3个节点,保证高可用。
# zoo.cfg配置
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/data/zookeeper/data
clientPort=2181
# 集群配置
server.1=zk1:2888:3888
server.2=zk2:2888:3888
server.3=zk3:2888:3888
分片数建议设置为节点数的2-3倍:
分片数 = 节点数 × 2 到 节点数 × 3
这样配置的好处:
elasticjob:
jobs:
myJob:
failover: true # 启用故障转移
misfire: true # 错过重跑
maxTimeDiffSeconds: 3600 # 最大时间差
failover: true:节点故障时,其分片自动转移到其他健康节点misfire: true:如果任务错过执行,系统会补执行maxTimeDiffSeconds:服务器时间差异阈值,超过此值记录错过management:
endpoints:
web:
exposure:
include: health,info,metrics,prometheus
metrics:
tags:
application: ${spring.application.name}
使用Docker Compose一键部署:
version: '3.8'
services:
zookeeper1:
image: zookeeper:3.8
container_name: zk1
ports:
- "2181:2181"
environment:
ZOO_MY_ID: 1
ZOO_SERVERS: zk1:2888:3888;zk2:2888:3888;zk3:2888:3888
volumes:
- zk1-data:/data
zookeeper2:
image: zookeeper:3.8
container_name: zk2
ports:
- "2182:2181"
environment:
ZOO_MY_ID: 2
ZOO_SERVERS: zk1:2888:3888;zk2:2888:3888;zk3:2888:3888
volumes:
- zk2-data:/data
zookeeper3:
image: zookeeper:3.8
container_name: zk3
ports:
- "2183:2181"
environment:
ZOO_MY_ID: 3
ZOO_SERVERS: zk1:2888:3888;zk2:2888:3888;zk3:2888:3888
volumes:
- zk3-data:/data
elasticjob1:
image: elasticjob-demo:1.0
ports:
- "8080:8080"
environment:
SPRING_DATASOURCE_URL: jdbc:mysql://mysql:3306/elasticjob_demo
SPRING_DATASOURCE_USERNAME: root
SPRING_DATASOURCE_PASSWORD: root123
depends_on:
- zookeeper1
- zookeeper2
- zookeeper3
- mysql
elasticjob2:
image: elasticjob-demo:1.0
ports:
- "8081:8080"
environment:
SPRING_DATASOURCE_URL: jdbc:mysql://mysql:3306/elasticjob_demo
SPRING_DATASOURCE_USERNAME: root
SPRING_DATASOURCE_PASSWORD: root123
depends_on:
- zookeeper1
- zookeeper2
- zookeeper3
- mysql
mysql:
image: mysql:8.0
ports:
- "3306:3306"
environment:
MYSQL_ROOT_PASSWORD: root123
MYSQL_DATABASE: elasticjob_demo
volumes:
- mysql-data:/var/lib/mysql
redis:
image: redis:7
ports:
- "6379:6379"
volumes:
- redis-data:/data
volumes:
zk1-data:
zk2-data:
zk3-data:
mysql-data:
redis-data:
启动命令:
docker-compose up -d
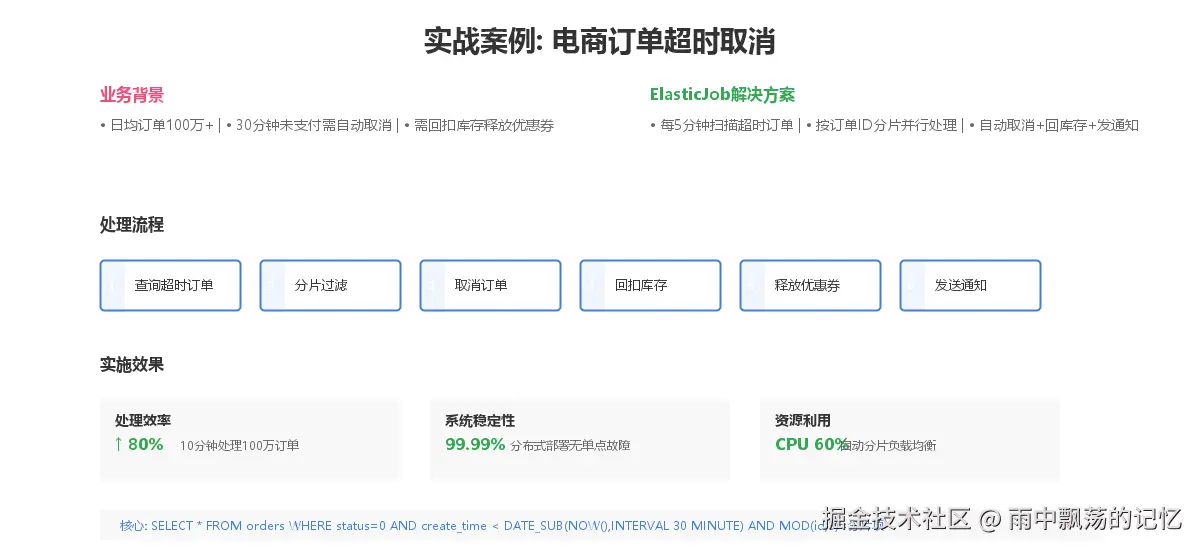
某电商平台,日均订单量100万+,业务规则要求订单创建后30分钟未支付需要自动取消。取消订单时需要:
在单机环境下,这个问题比较容易解决,使用一个定时任务扫描所有超时订单即可。但在分布式环境下,存在以下挑战:
按订单ID取模分片,订单ID % 分片数 = 分片项。例如3个分片,订单ID为1,4,7,...的订单属于分片0。
elasticjob:
regCenter:
serverLists: localhost:2181
namespace: elasticjob-demo
jobs:
orderCancelJob:
elasticJobClass: com.elasticjob.job.OrderCancelJob
cron: 0 */5 * * * ? # 每5分钟执行
shardingTotalCount: 3 # 3个分片
shardingItemParameters: 0=Beijing,1=Shanghai,2=Guangzhou
description: 订单超时自动取消
monitorExecution: true
failover: true
misfire: true
jobErrorHandlerType: LOG
@Component
@Slf4j
public class OrderCancelJob implements SimpleJob {
@Autowired
private OrderMapper orderMapper;
@Autowired
private InventoryService inventoryService;
@Autowired
private CouponService couponService;
@Autowired
private NotificationService notificationService;
@Override
public void execute(ShardingContext context) {
long startTime = System.currentTimeMillis();
int shardingItem = context.getShardingItem();
int shardingTotalCount = context.getShardingTotalCount();
log.info("订单取消作业开始 - 分片{}/{}", shardingItem, shardingTotalCount);
int successCount = 0;
int failCount = 0;
try {
// 查询超时订单(只查询当前分片的订单)
List<Order> timeoutOrders = orderMapper.selectTimeoutOrders(
30, // 超时30分钟
shardingItem, // 当前分片
shardingTotalCount // 分片总数
);
log.info("分片{}查询到{}条超时订单", shardingItem, timeoutOrders.size());
// 逐个取消订单
for (Order order : timeoutOrders) {
try {
// 开启事务
TransactionStatus transaction = transactionManager.getTransaction(
new DefaultTransactionDefinition()
);
// 1. 取消订单
int rows = orderMapper.cancelOrder(
order.getId(),
LocalDateTime.now()
);
if (rows > 0) {
// 2. 回扣库存
inventoryService.returnInventory(
order.getProductId(),
order.getQuantity()
);
// 3. 释放优惠券
if (order.getCouponId() != null) {
couponService.returnCoupon(
order.getCouponId(),
order.getUserId()
);
}
// 4. 发送通知
notificationService.sendCancelNotification(
order.getUserId(),
order.getOrderNo()
);
// 提交事务
transactionManager.commit(transaction);
successCount++;
log.info("订单{}取消成功", order.getOrderNo());
} else {
failCount++;
log.warn("订单{}取消失败,可能已被处理", order.getOrderNo());
}
} catch (Exception e) {
// 回滚事务
if (transactionManager.isActualTransactionActive()) {
transactionManager.rollback(transaction);
}
failCount++;
log.error("订单{}取消异常", order.getOrderNo(), e);
}
}
} catch (Exception e) {
log.error("订单取消作业执行异常", e);
} finally {
long costTime = System.currentTimeMillis() - startTime;
log.info("订单取消作业完成 - 分片{} 成功:{} 失败:{} 耗时:{}ms",
shardingItem, successCount, failCount, costTime);
// 记录执行日志
saveExecutionLog(context, successCount, failCount, costTime);
}
}
private void saveExecutionLog(ShardingContext context, int successCount,
int failCount, long costTime) {
JobExecutionLog log = new JobExecutionLog();
log.setJobName(context.getJobName());
log.setShardingItem(context.getShardingItem());
log.setSuccessCount(successCount);
log.setFailCount(failCount);
log.setStartTime(LocalDateTime.now());
log.setCostTime(costTime);
log.setStatus("COMPLETED");
jobExecutionLogMapper.insert(log);
}
}
通过器可以在任务执行前后做一些自定义操作:
@Component
public class JobListener implements ElasticJobListener {
@Override
public void beforeJobExecuted(ShardingContexts shardingContexts) {
for (ShardingContext context : shardingContexts) {
log.info("作业{}分片{}即将开始执行",
context.getJobName(), context.getShardingItem());
// 可以在这里做一些初始化工作
// 如:检查前置条件、清理临时数据等
}
}
@Override
public void afterJobExecuted(ShardingContexts shardingContexts) {
for (ShardingContext context : shardingContexts) {
log.info("作业{}分片{}执行完成",
context.getJobName(), context.getShardingItem());
// 可以在这里做一些清理工作
// 如:记录执行日志、发送通知等
}
}
}
配置器:
elasticjob:
jobs:
myJob:
jobListenerType: com.example.listener.JobListener
如果内置的分片策略不满足需求,可以自定义分片策略:
public class CustomJobShardingStrategy implements JobShardingStrategy {
@Override
public Map<JobInstance, List<Integer>> sharding(
List<JobInstance> jobInstances,
String jobName,
int shardingTotalCount) {
Map<JobInstance, List<Integer>> result = new LinkedHashMap<>();
// 自定义分片算法
// 例如:根据节点的IP地址的哈希值分配分片
int instanceCount = jobInstances.size();
for (int i = 0; i < jobInstances.size(); i++) {
JobInstance instance = jobInstances.get(i);
List<Integer> shardingItems = new ArrayList<>();
for (int j = 0; j < shardingTotalCount; j++) {
if (j % instanceCount == i) {
shardingItems.add(j);
}
}
result.put(instance, shardingItems);
}
return result;
}
}
配置自定义策略:
elasticjob:
jobs:
myJob:
jobShardingStrategyType: com.example.strategy.CustomJobShardingStrategy
通过线程池配置,可以提高单节点的并发处理能力:
elasticjob:
jobs:
myJob:
jobExecutorServiceHandlerType: EXECUTOR_SERVICE
executorServiceHandlerClass: com.example.CustomExecutorServiceHandler
自定义线程池处理器:
public class CustomExecutorServiceHandler implements ExecutorServiceHandler {
@Override
public ExecutorService createExecutorService(final String jobName) {
return new ThreadPoolExecutor(
10, // 核心线程数
20, // 最大线程数
60L, // 空闲线程存活时间
TimeUnit.SECONDS,
new LinkedBlockingQueue<>(1000), // 任务队列
new ThreadFactoryBuilder().setNameFormat(jobName + "-thread-%d").build()
);
}
}
ElasticJob提供了灵活的错误处理机制:
elasticjob:
jobs:
myJob:
jobErrorHandlerType: LOG # LOG/EMAIL/WECHAT/DINGTALK
自定义错误处理器:
public class CustomJobErrorHandler implements JobErrorHandler {
@Autowired
private AlertService alertService;
@Override
public void handleException(JobExceptionHandlerContext context) {
Throwable exception = context.getException();
ShardingContext shardingContext = context.getShardingContext();
log.error("作业执行异常 - 作业:{}, 分片:{}",
shardingContext.getJobName(),
shardingContext.getShardingItem(),
exception);
// 发送告警
alertService.sendAlert("作业执行失败", exception.getMessage());
}
}
软件要求:
安装Zookeeper:
# 下载
wget
# 解压
tar -xzf apache-zookeeper-3.8.0-bin.tar.gz
cd apache-zookeeper-3.8.0-bin
# 配置
cp conf/zoo_sample.cfg conf/zoo.cfg
配置zoo.cfg:
tickTime=2000
dataDir=/data/zookeeper
clientPort=2181
maxClientCnxns=60
启动Zookeeper:
bin/zkServer.sh start
添加依赖:
<dependency>
<groupId>org.apache.shardingsphere.elasticjob</groupId>
<artifactId>elasticjob-lite-spring-boot-starter</artifactId>
<version>3.0.4</version>
</dependency>
配置application.yml:
elasticjob:
regCenter:
serverLists: localhost:2181
namespace: elasticjob-demo
jobs:
myJob:
elasticJobClass: com.example.job.MyJob
cron: 0 */5 * * * ?
shardingTotalCount: 3
实现作业:
@Component
public class MyJob implements SimpleJob {
@Override
public void execute(ShardingContext context) {
int shardingItem = context.getShardingItem();
System.out.println("执行分片: " + shardingItem);
}
}
# 启动应用
java -jar elasticjob-demo.jar
# 访问应用
curl
# 查看Zookeeper节点
zkCli.sh -server localhost:2181
ls /elasticjob-demo
ElasticJob提供了独立的运维控制台:
下载控制台:
wget
tar -xzf elasticjob-lite-console-3.0.4-bin.tar.gz
cd elasticjob-lite-console-3.0.4
配置控制台:
# conf/application.properties
auth.root_username=root
auth.root_password=root
datasource.url=jdbc:mysql://localhost:3306/elasticjob_console
datasource.username=root
datasource.password=root123
启动控制台:
bin/start.sh
访问控制台:
ElasticJob作为Apache ShardingSphere的子项目,经过多年的发展,已经非常成熟和稳定。它在当当网、京东、国美等大型电商企业得到了广泛的应用,证明了其生产可用性。

