红标笔趣阁
31.0MB · 2026-03-24

前端开发中常见这些问题:
这篇文章讲讲我们怎么用 Obsidian + Claude Code 来解决这些问题。
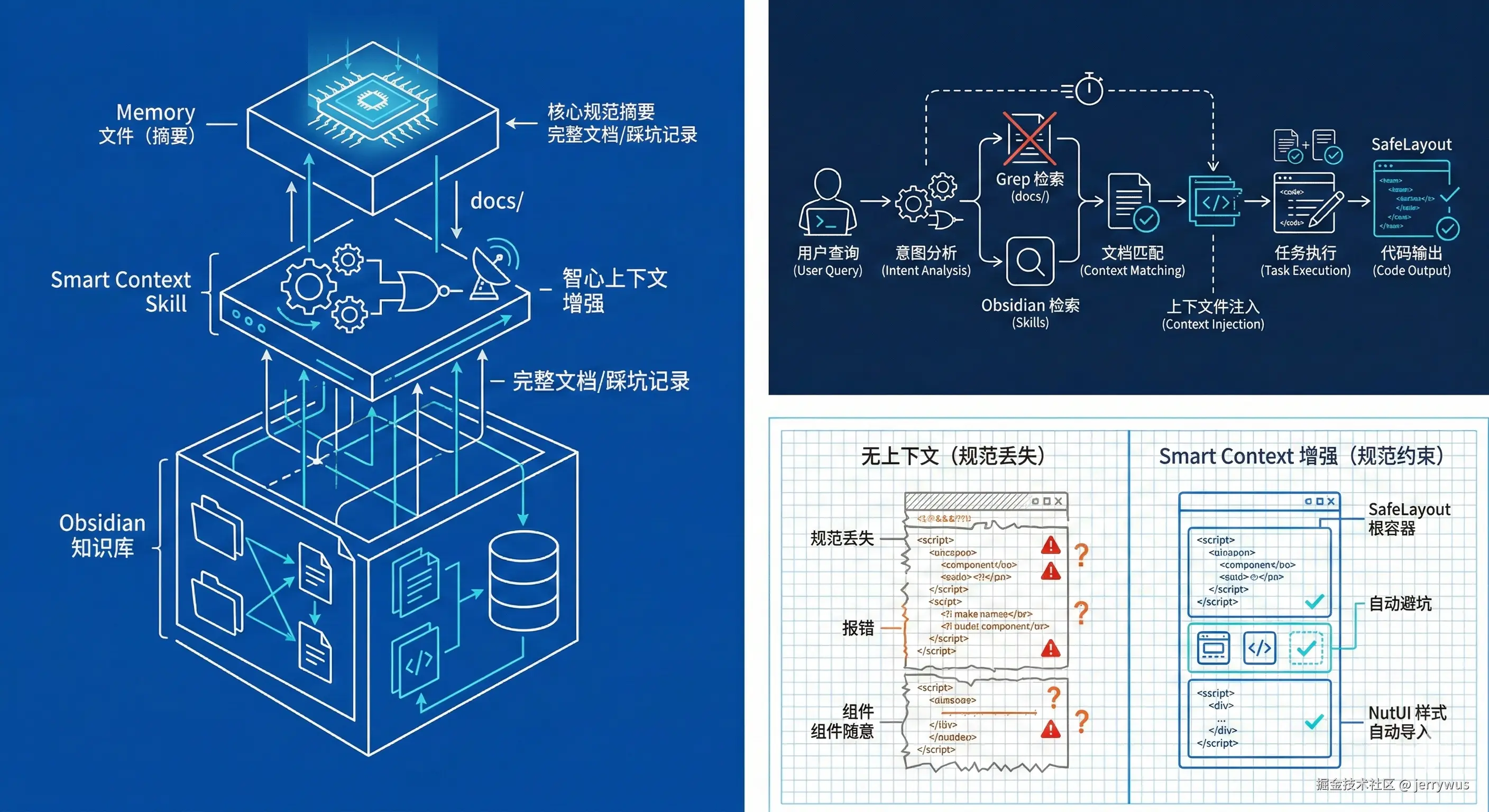
三层结构:
Memory 文件(200行左右)→ Smart Context Skill → Obsidian docs/
工作流程很简单:
在项目根目录建 docs/ 文件夹:
docs/
├── 00-索引.md
├── 01-快速开始.md
├── 02-开发规范/
│ ├── index.md
│ ├── API规范.md
│ ├── 组件使用.md
│ ├── 命名约定.md
│ └── 页面开发.md
├── 03-架构设计/
│ ├── index.md
│ ├── 目录结构.md
│ └── 分包策略.md
├── 04-开发笔记/
│ ├── index.md
│ └── 踩坑记录.md
└── 05-Claude相关/
├── index.md
└── 规则文件说明.md
docs/04-开发笔记/踩坑记录.md:
# 踩坑记录
## Taro 相关
### scroll-view 下拉加载不触发
**问题**: @scrolltolower 事件不触发
**原因**: scroll-view 高度未设置
**解决**: 设置 scroll-y 和 height: 100vh
### 内联 SVG 不支持
**问题**: svg 标签不渲染
**解决**: 使用图片 URL 或 IconFont
docs/02-开发规范/API规范.md:
# API 开发规范
## 函数命名
- query: 查询/获取
- add: 新增
- edit: 编辑
- delete: 删除
- toggle: 切换状态
- do: 执行操作
## 标准模式
1. try/catch 包裹
2. 检查 code === EResponseCode.Succeed
3. 从 context 提取数据
4. catch 中使用 getHttpErrorMessage
这个是claudecode自带的,/memory去开启即可
文件位置:
~/.claude/projects/-项目名-/memory/MEMORY.md
内容首次微调到精简到 50 行以内 (因为后续cc会自动往里面加记忆):
# Project Memory
## 知识库架构
> Memory(200行核心)→ Obsidian docs/(完整知识)
| 层级 | 存储 | 用途 |
|------|------|------|
| Memory | 核心规范摘要 | 始终加载 |
| Obsidian | 完整文档/踩坑记录 | 检索使用 |
## 核心规范
- **页面**: SafeLayout 根容器,列表 graybg/详情 whitebg
- **API**: query/add/edit/delete/toggle/do + try/catch
- **组件**: 优先 src/components/,禁 SVG 用 IconFont
## 常见避坑
1. scroll-view: 设 scroll-y + height
2. 小程序禁 SVG: 用图片 URL
3. NutUI 样式: 查 auto-import
4. ref template 不需 .value
## Obsidian 检索
```bash
obsidian search query=页面开发 # 搜索
grep -r "xxx" docs/ # 失败时才用 Grep
| 知识 | 文件 |
|---|---|
| 踩坑 | docs/04-开发笔记/踩坑记录.md |
| API | docs/02-开发规范/API规范.md |
| 页面 | docs/02-开发规范/页面开发.md |
编程任务自动检索:新增/修复/重构/询问"怎么做"/业务模块
## 步骤三:创建 Smart Context Skill
在项目 `.claude/skills/` 目录下创建:
.claude/skills/smart-context/
└── skill.md
内容:
---
name: smart-context
description: |
智能上下文增强技能。自动检索本项目 Obsidian 知识库(docs/)中的项目规范、踩坑记录。
触发条件:(1) 实现新功能/创建页面/添加API (2) 修复bug/解决报错 (3) 重构代码
(4) 询问"怎么做" (5) 提到业务模块(提货/结算/销售/会员等)。
优先使用 obsidian-cli 搜索 Obsidian 文档,失败才使用 Grep。
---
# Smart Context - 智能上下文增强
## 核心原则
1. 以 Obsidian 为知识库,obsidian-cli 为检索工具
2. 当用户说"把这个加入知识库"时,优先使用 obsidian-cli 增加
obsidian search query=文档关键词 grep -r "scroll-view" docs/
## 工作流程
### 第一步:分析任务意图
- 任务类型:新增/修改/修复/查询
- 业务模块:提货/结算/销售/会员
- 技术领域:API/页面/组件
### 第二步:检索 Obsidian
```bash
obsidian search query="{关键词}"
obsidian read path=docs/04-开发笔记/踩坑记录.md
| 任务 | 搜索词 |
|---|---|
| 创建页面 | 页面开发、SafeLayout、列表页 |
| 添加 API | API规范、query、try catch |
| 修复报错 | 踩坑、{报错关键词} |
| 提货相关 | 提货、pickup |
用户输入:帮我创建一个退款订单列表页面
自动执行:
obsidian search query=页面开发obsidian search query=列表页配置完成后,实际效果长这样:
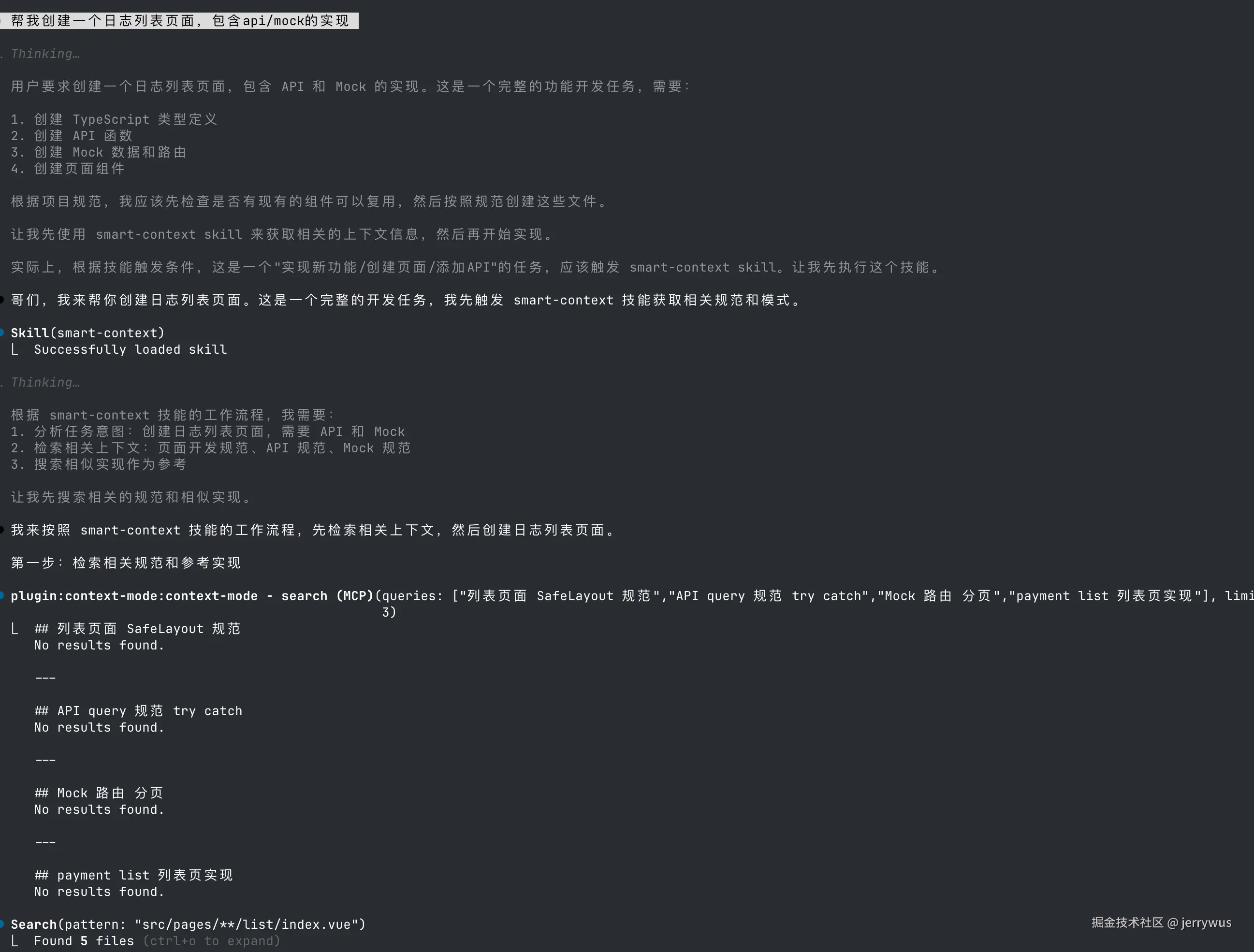
左边 Claude Code 正在工作,右边 Obsidian 里的搜索结果同步显示。它自动检索到了相关规范,比如页面开发、SafeLayout 这些关键信息。
再看另一个角度:
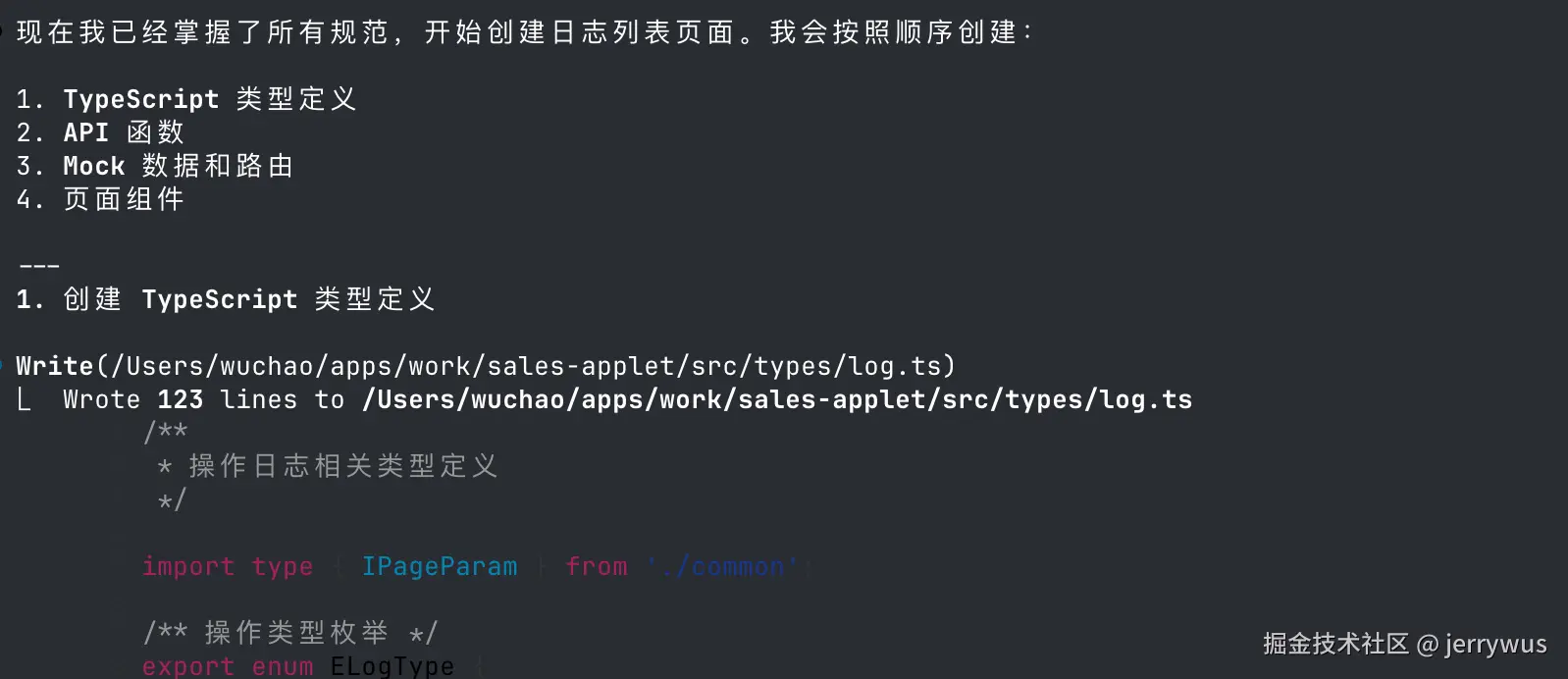
左边继续从 Obsidian 拉取踩坑记录,右边代码已经写上了。Smart Context 把规范和避坑信息注入上下文,Claude 直接沿着正确方向写,不需要你中途打断去纠正。
重启 Claude Code,然后测试:
帮我创建一个订单列表页面
观察 Claude 的行为:
obsidian search 搜索相关文档遇到新踩坑时,直接告诉 Claude:
把这个加入知识库:Taro 项目上传图片时,如果使用本地路径不显示,
需要使用 require() 或者用 COS 托管的图片 URL
Claude 会自动:
在obsidian软件设置->关于-> 打开"允许命令行和obsidian交互“, 然后重启cc会话即可。
同时安装一下mcp服务:
mcp-obsidian.org/install/
再安装obsidian skills
请打开:obsidian skills
不需要。Claude Code 通过 obsidian-cli MCP 工具直接操作,Obsidian 可以关闭,只是一个存储软件,实际cc调用效果如下图:
比如我让他修改文档
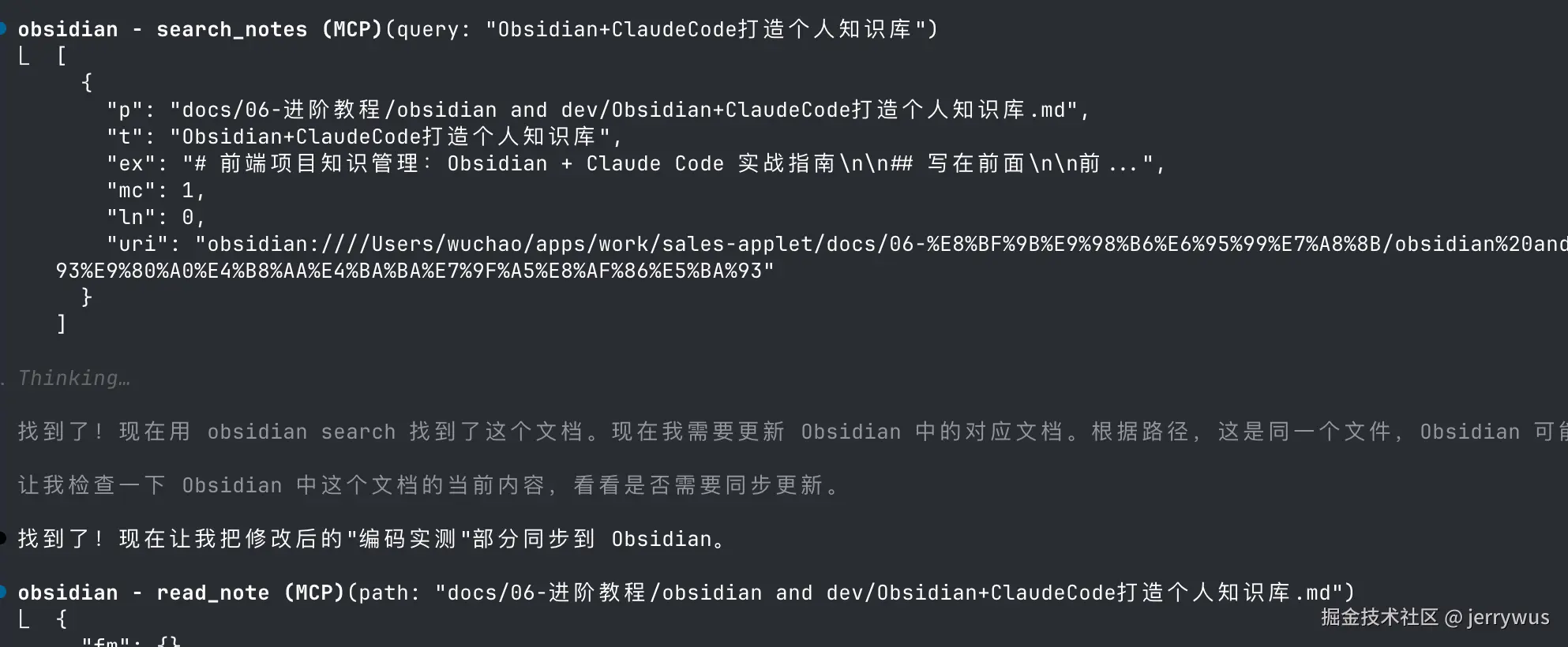
配置完成后,你得到一个自动化的知识增强系统:
| 功能 | 实现方式 |
|---|---|
| 记忆增强 | Obsidian 持久存储 + Memory 始终加载 |
| 规范约束 | Smart Context 自动检索 |
| 避坑提醒 | 踩坑记录 + 自动查询 |
| 知识更新 | 自然语言告诉 Claude "加入知识库" |
核心思路:让 Claude Code 在每次编程时自动检索相关规范,而不是靠人工记忆。
关于obsidian更多用法,请关注后续写新的文章~

