


扇贝听力
126.68M · 2026-02-26

文本大模型评测是通过设计合理的评价维度、数据集与指标,对模型的语言理解、生成、安全等能力进行系统、全面、科学的评估,以此驱动模型迭代优化,满足实际业务需求。
为什么它那么重要
技术闭环保障: 构建“数据准备--->模型设计与训练---->能力评测--->上线及运营”的完整技术闭环
能力说明书: 明确模型的功能边界与适用场景,解答"能做什么/不能做什么"的核心问题
大模型炼丹应用的生命周期,及评测扮演的角色
我们调研近3年国内外文本评测方向的成果。
调研目的:提炼核心焦点,构建货拉拉大模型评测的理论框架。最终结合公司场景知识和数据,形成了我们自己的评测实践,并抽象出货运行业特色的评测能力、评测框架,加速AI应用在公司的落地。
调研成果:学术与工业界的研究核心均围绕两个根本性问题展开: “评测什么”与“怎么评测” 。
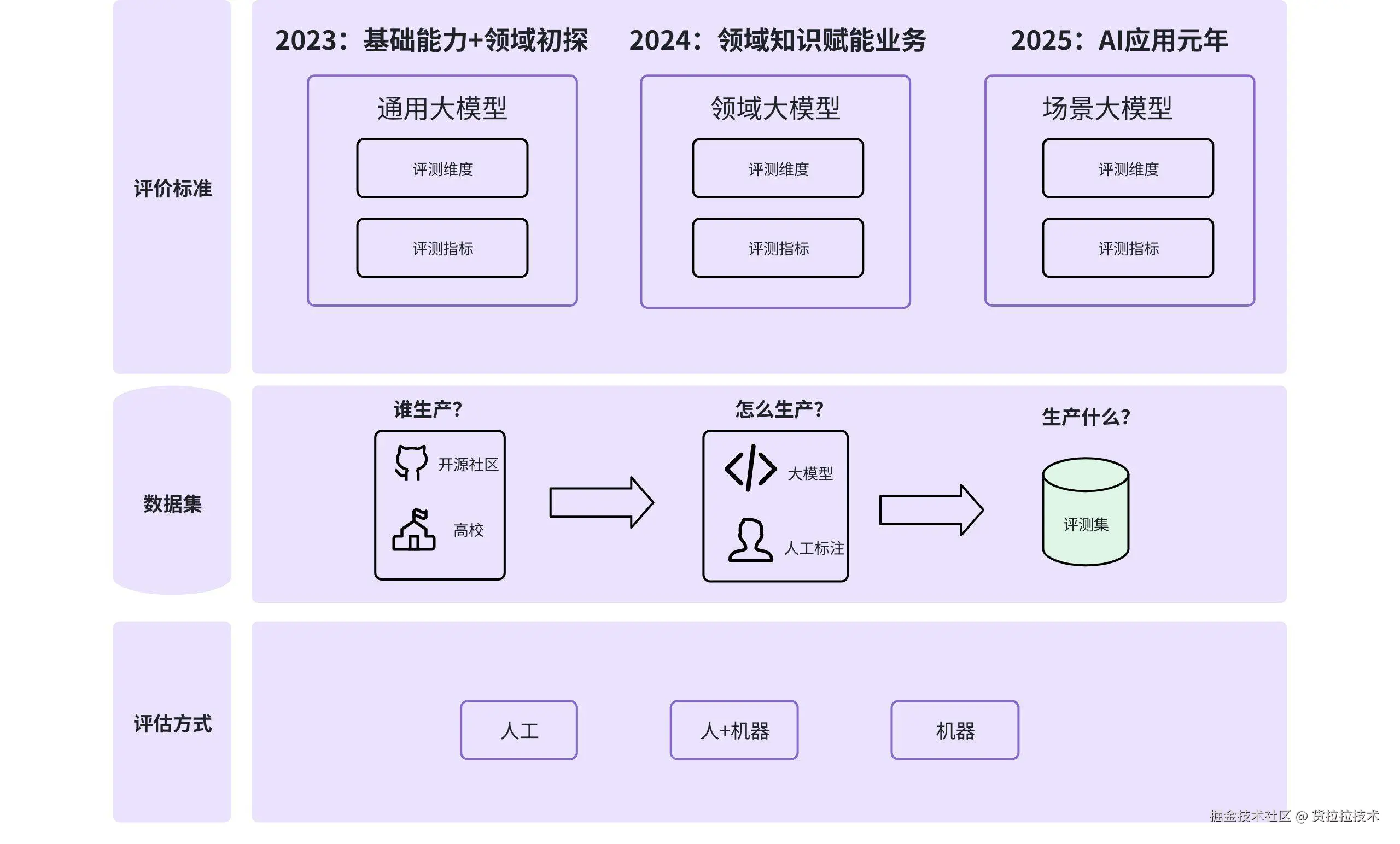
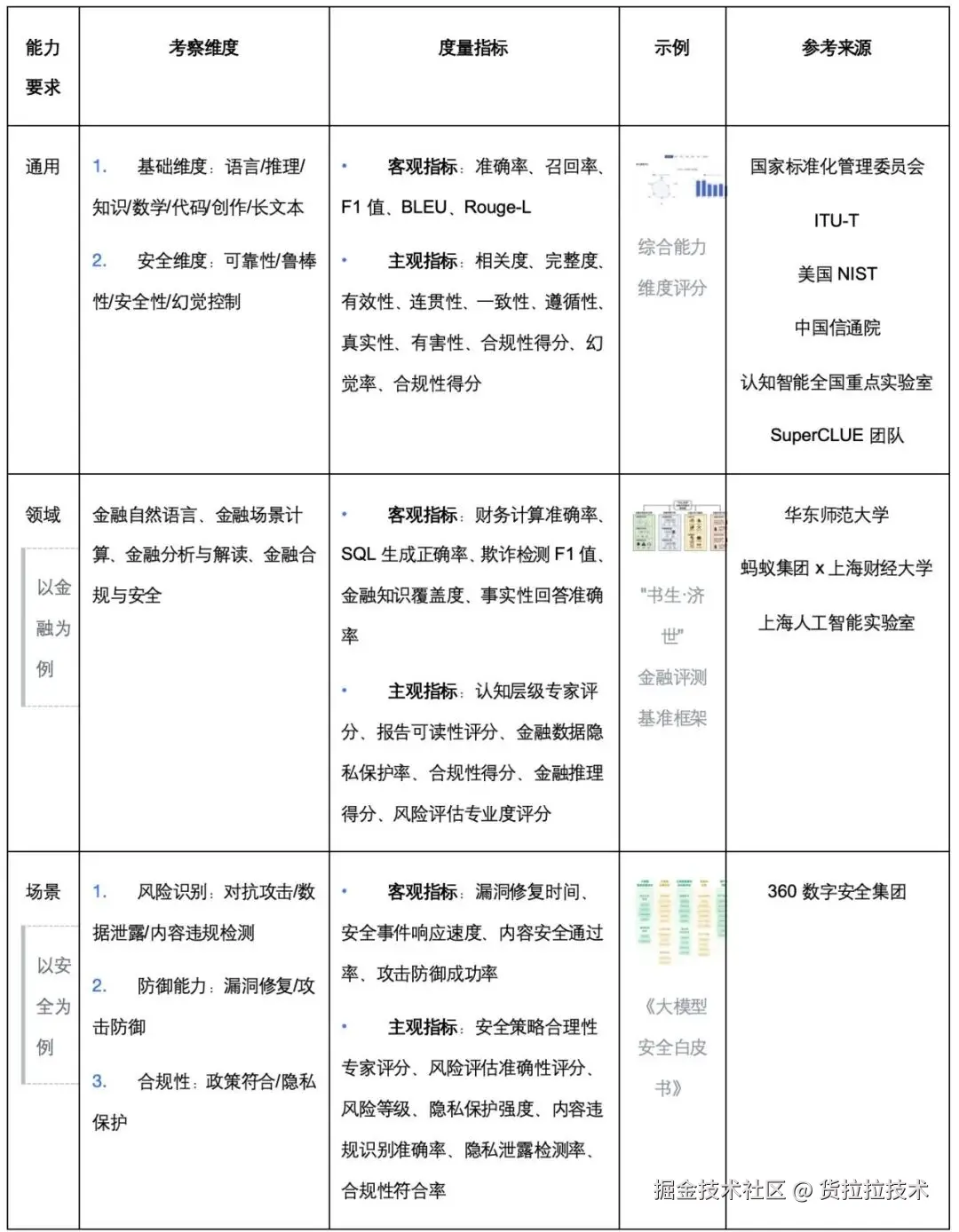
根据评测目标的差异化和覆盖完整性,我们参考国标、顶尖高校和头部公司(详见附录),把评测分成通用、领域、业务三大场景能力
模型的入门门槛,重点考察大模型的基础能力
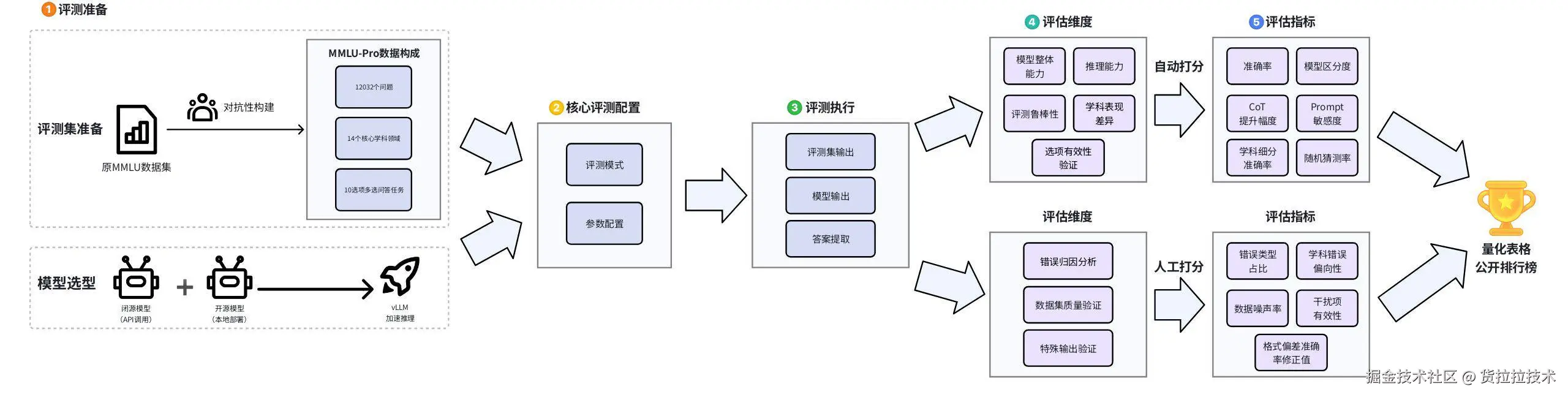
MMLU Pro的评估流程是通过自动打分和人工打分的多指标评估,最终输出量化表格与公开排行榜的完整闭环流程
定义与特点定位
评估流程
与通用的方式基本一致,差异点主要在于数据集构造、评测维度、指标会有些不同。
定义与特点定位
定义:大模型落地验证,重点关注大模型落地实用性和安全性如何,涉及到客服、营销、数据分析、办公等企业经营的方方面面。
特点定位: 面临的具体使用情境,需结合用户交互流程与业务目标,核心特征是 “任务闭环化、交互真实化”,更关注 “端到端解决问题的能力”,该场景是连接 “模型能力” 与 “用户价值” 的关键纽带。
评估流程
流程可复用领域的评测流程,差异点在于业务目标与场景数字人的评价标准,数据更加个性化,以及有明确的业务指标。比如转化率、一解率等。
明确了“评测什么”的问题之后,接下来就是看如何做评测?
我们对国家标准化管理委员会、上海人工智能实验室、以及产业界的头部玩家进行了跟踪。总结归纳出两个核心方面:一、术的层面,保障全面性:需要哪些指标、哪些维度、什么样的数据。二、器的层面,保障科学性:用什么工具,什么资源进行评测。
评测方案的全景图,以及发展脉络
对比24年,25年国内外框架的指标体系,更精准贴合场景应用中模型能力评估的需求,且注重划分人/机指标。
25年整体向学术引领、应用驱动、协同创新发展:学术机构仍是评测集构建标杆,企业自建则紧贴应用场景,且联合构建与跨界合作成为主流。
相比24年,业内评测集构建仍由人工主导,但模型辅助以多种方式深度融入构建流程,发挥可靠提效作用。
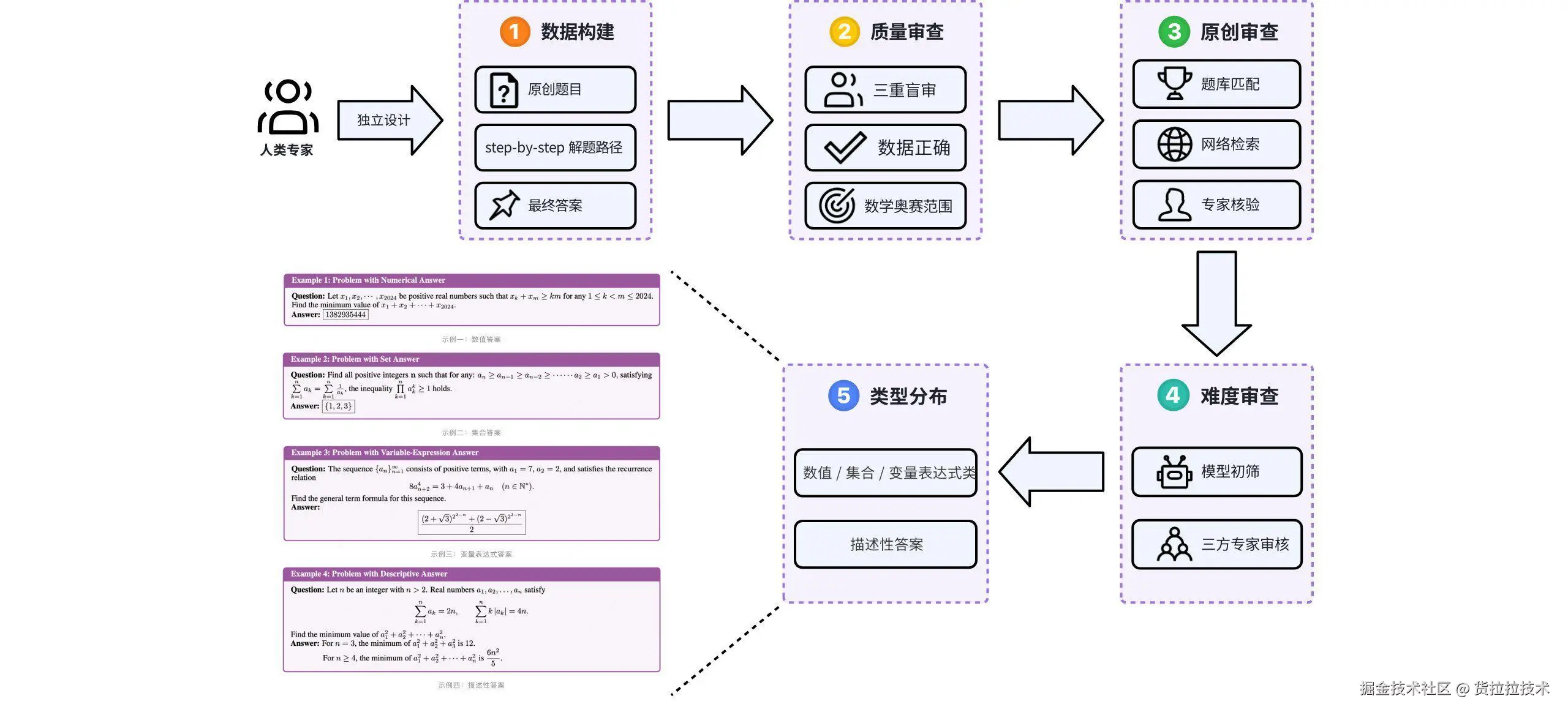
人工:领域专家仍是高质量和权威性数据构建的主力
美团LongCat团队的AMO-Bench人工数学推理评测集生产过程
机器:基于规则构建与半自动 标注是当前主流构建趋势,协同构建兼顾质量与效率,科学性强。
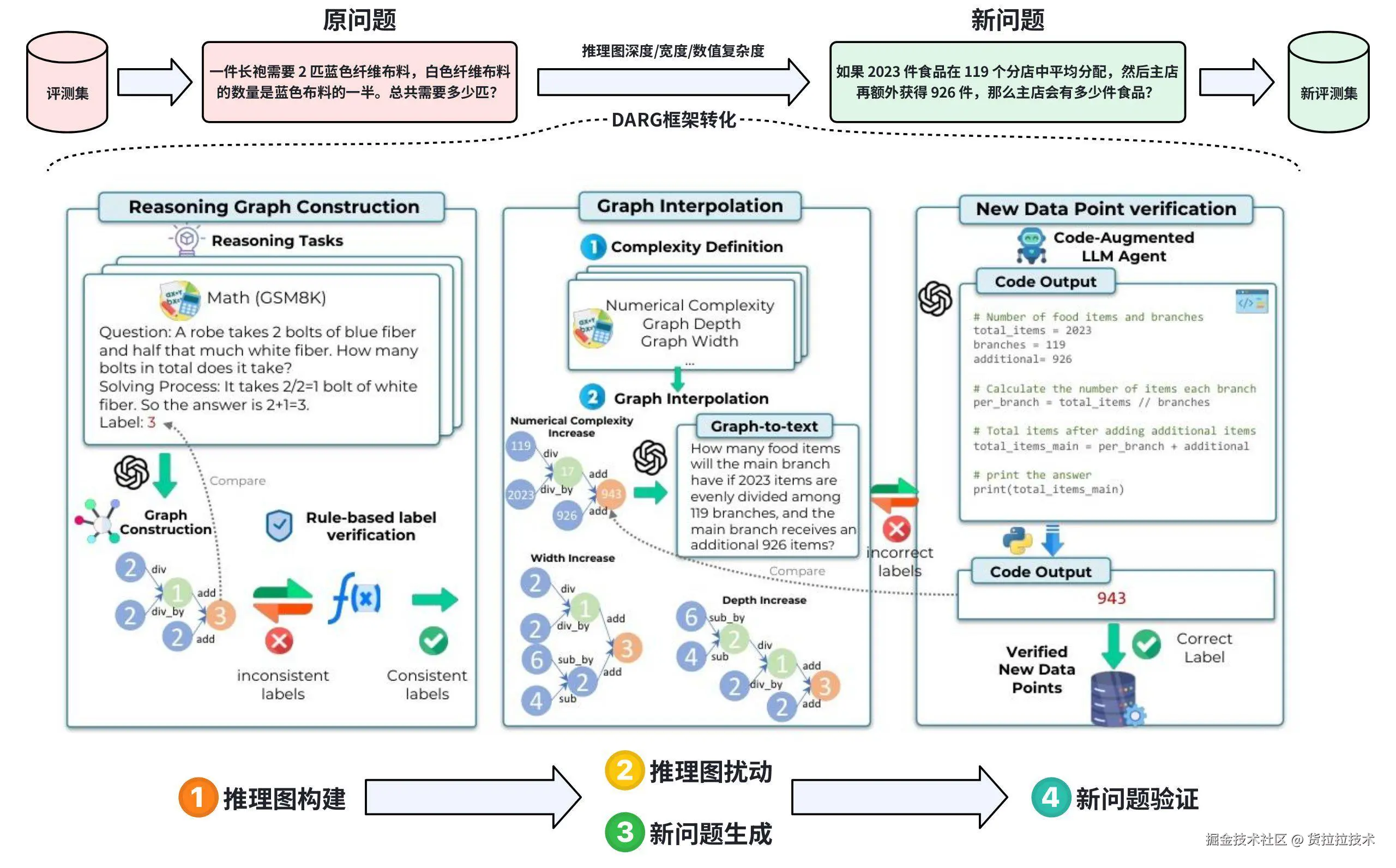
DARG框架:从原评测题出发,经推理图构建、复杂度扰动、新问题生成等动态生成高质量新评测题(图片来源:)
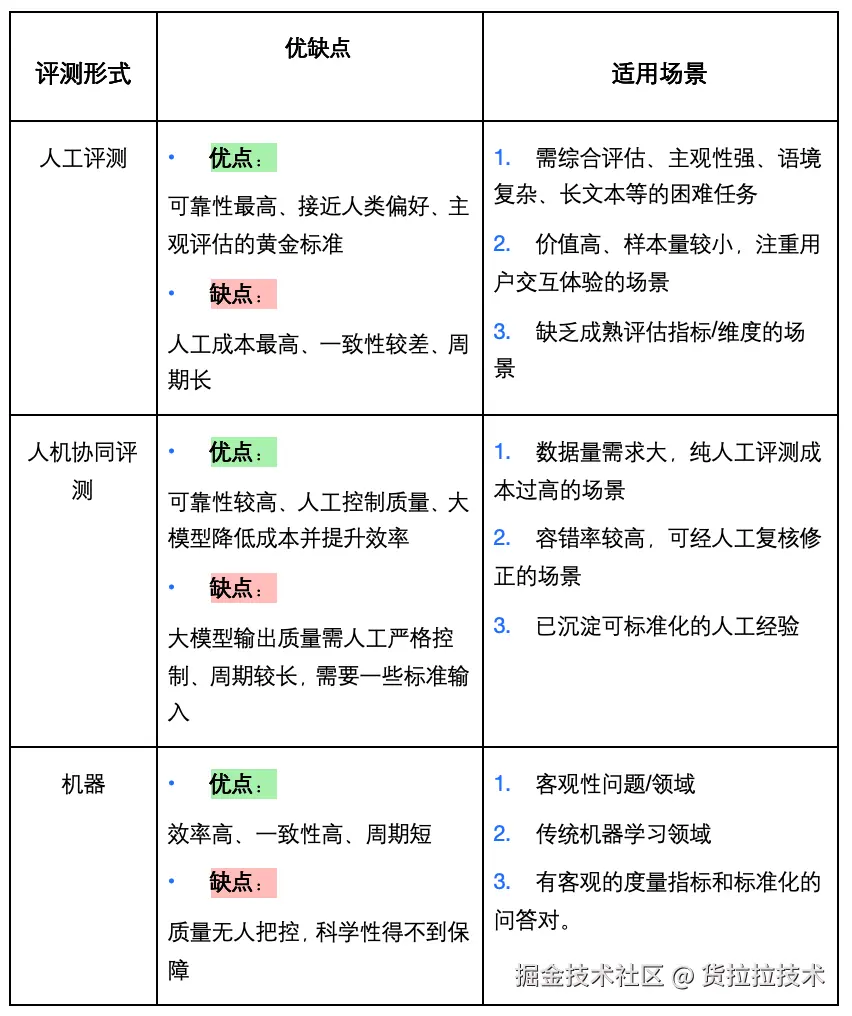
人工评测模式保持稳定,纯人工评测应用热度呈下降趋势;仍以学术机构主导建设,且仅少数机构厂商公布了实践落地情况 。
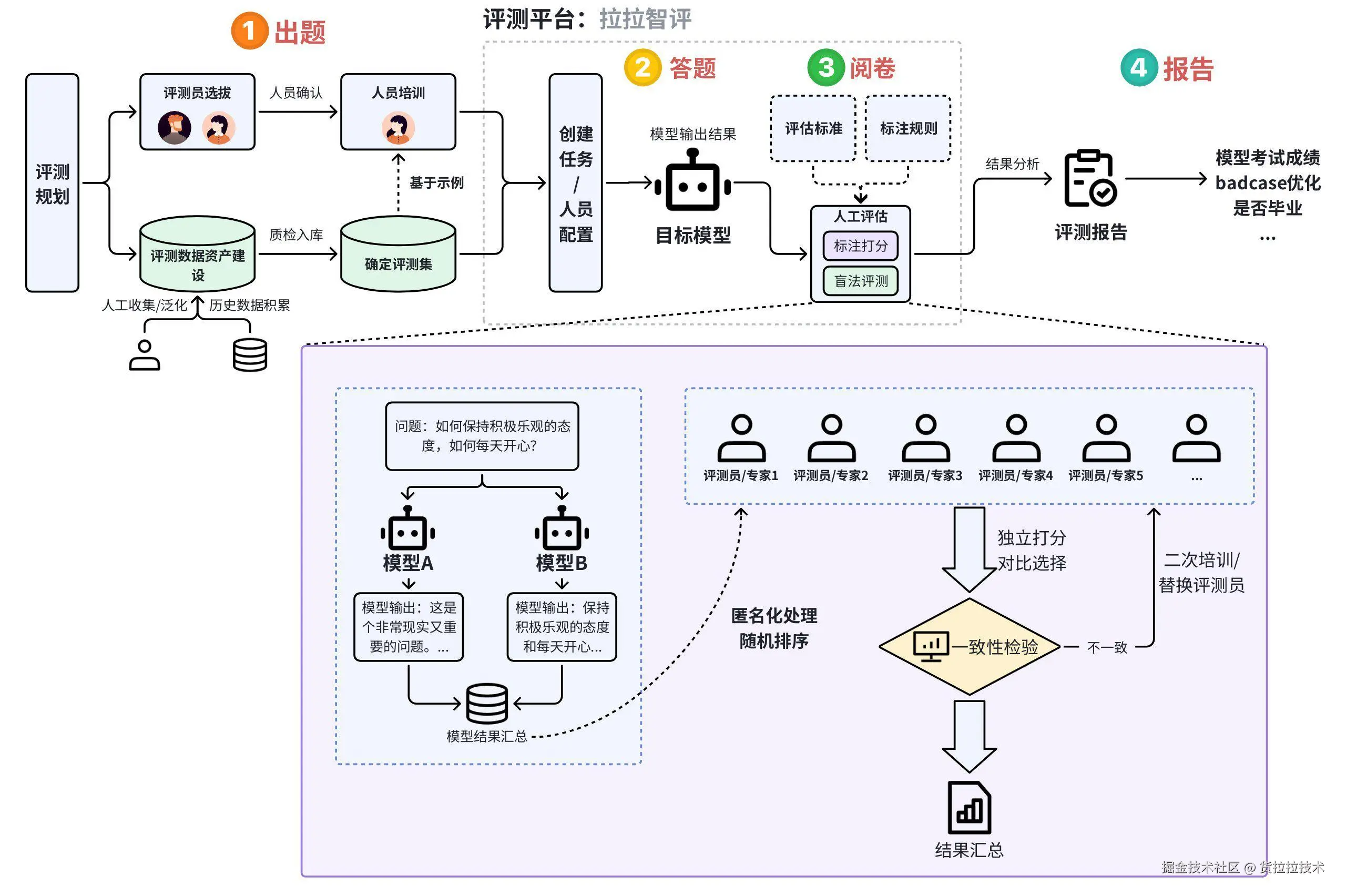
基于系统化的评测方案,确定评测人员及评测集,经过规范化的人工评估形成最终评测结果。
人工评测流程
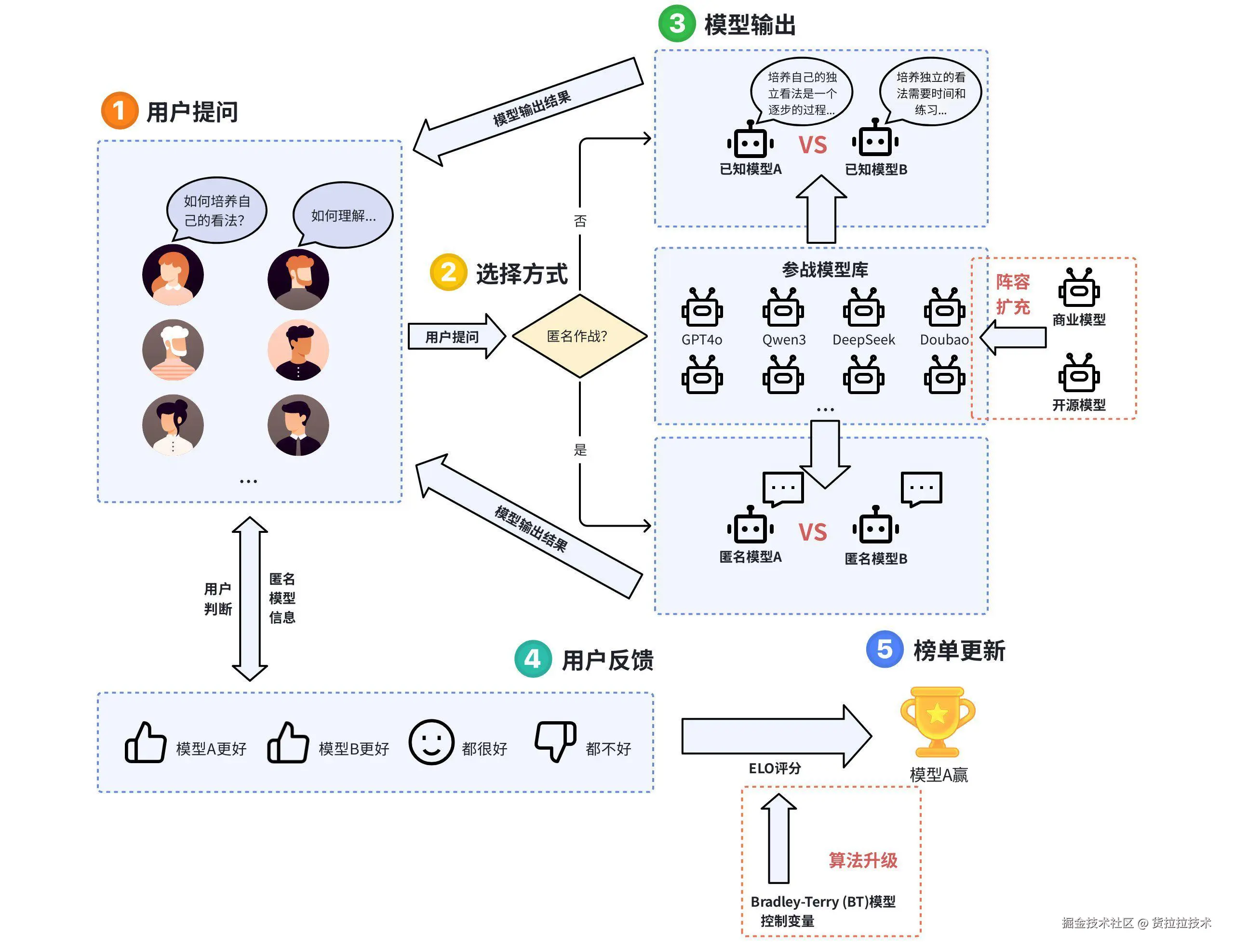
采用众包人工评估方式,对比同一问题多模型输出结果并进行实时投票,最终依据统计指标动态更新排名榜单。
竞技场式评测流程
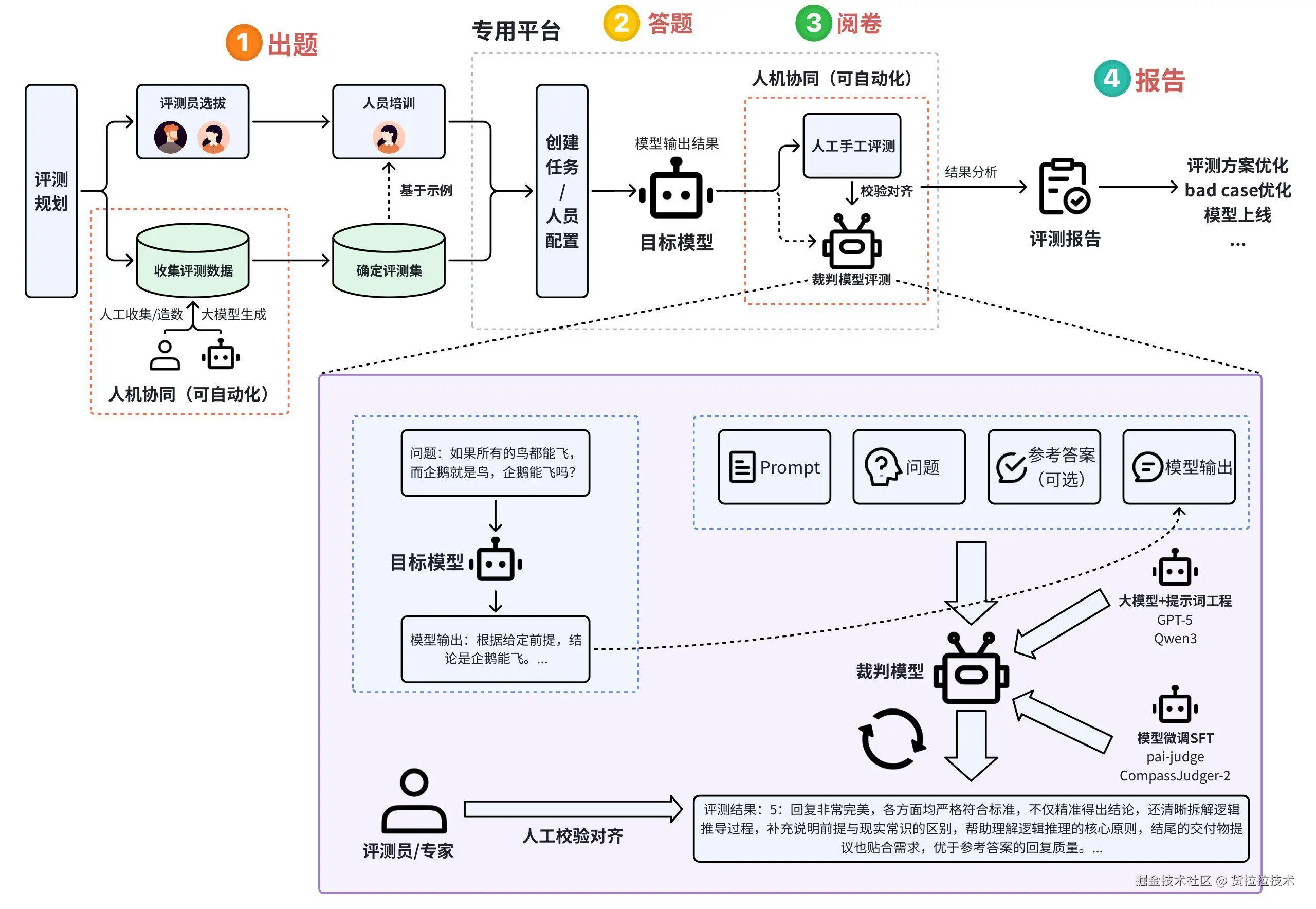
作为当前主流探索方向,人机协同评测通过"人工主导+模型辅助"的混合范式,在保证质量可控的前提下显著提升评测效率。该模式已在头部企业落地实践。
人机协同评测全流程图,模型参与“出题”与“阅卷”阶段,辅助提升评测质量与效率
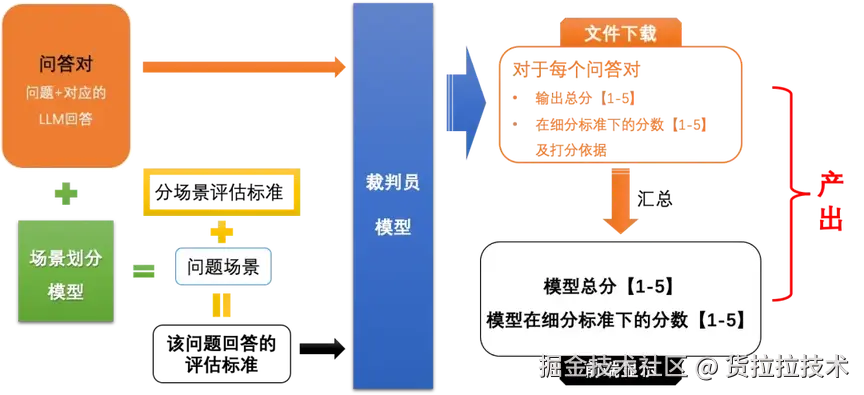
可根据不同的任务进行自动化指标选取 ,并且模型可以替代人工进行效果评价。
工作模式
阿里裁判员模型工作模式图(来源:)
根据核心主体,划分为基于基准测试和智能体的两种自动化评测 。
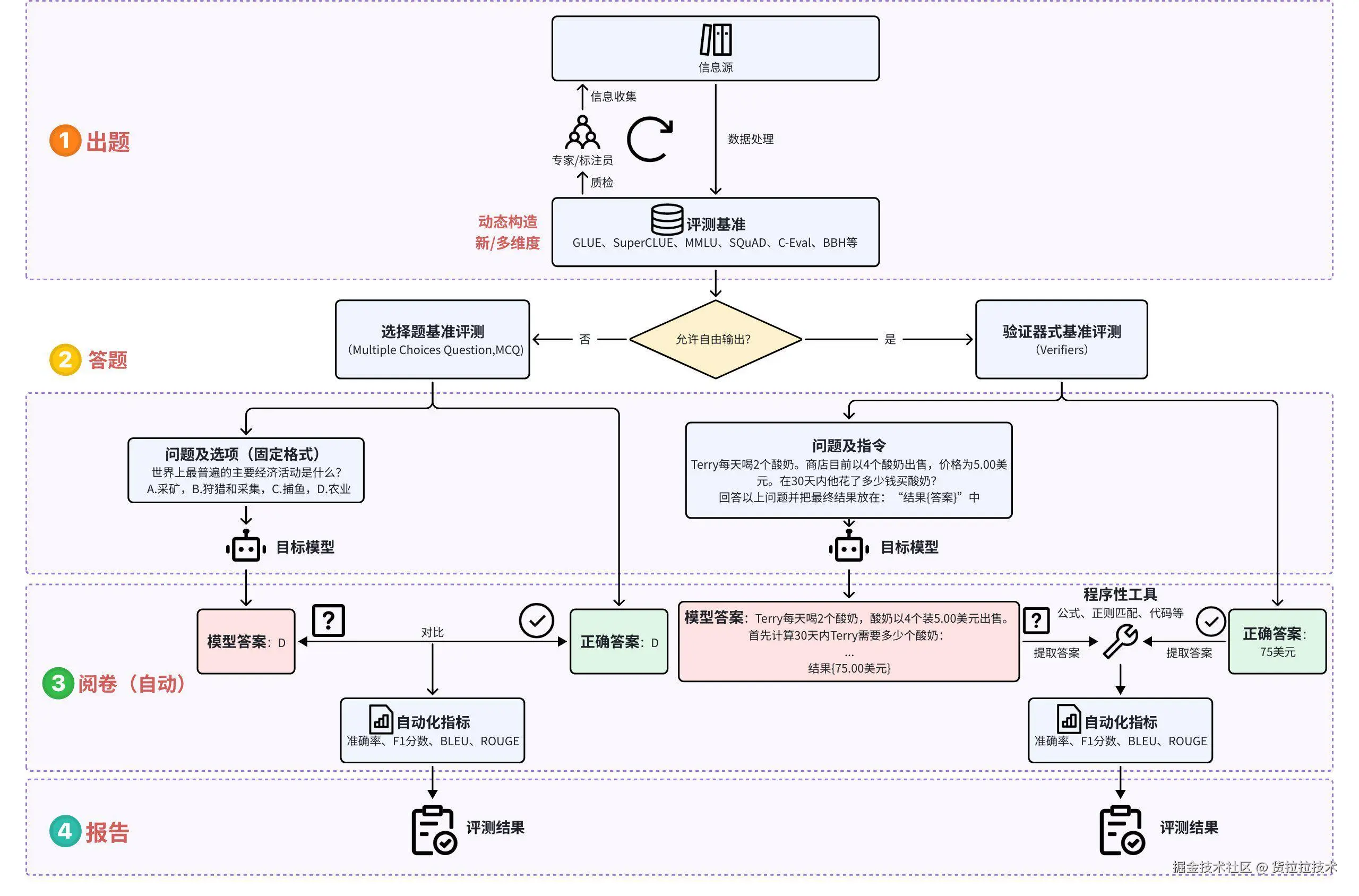
通过设计合理的测试任务和评价数据集来客观、公正、量化的评估模型的性能,是目前产业界和学术界最为认可的模型能力评估方法。
传统自动化评测流程图:模型输出方式不同,问题也分为“固定”与“指令”两种形式
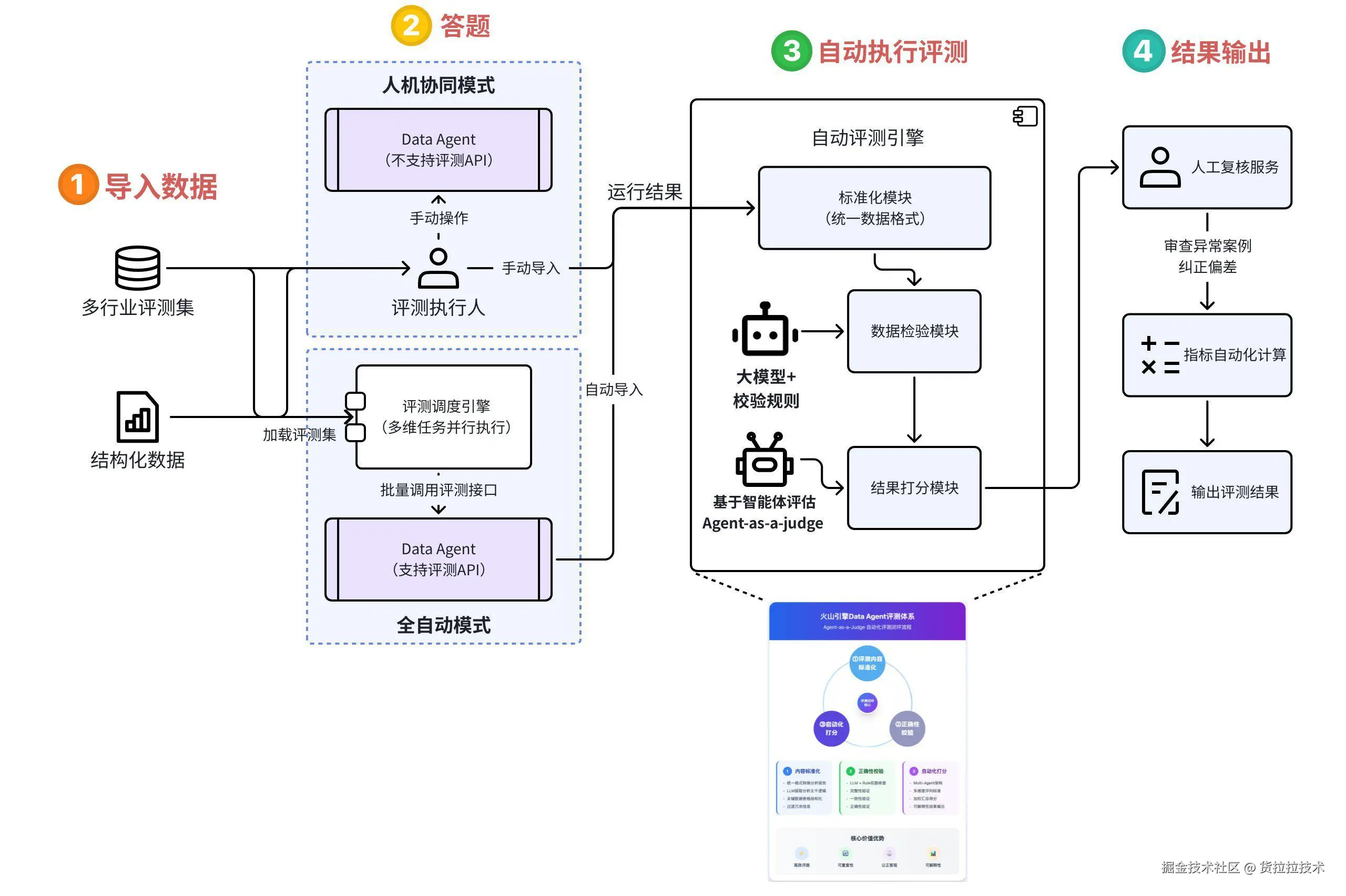
概念:暂无明确统一定义,以评测引擎为核心,对智能体输出效能进行标准化自动评估的方式。
通过多行业/结构化数据输入,经人机协同或全自动(批量调用接口)两种模式答题,再通过自动评测引擎的标准化模块、数据检验模块等模块执行评测,最后经人工复核异常案例、自动计算指标后输出评测结果(来源:)
小结
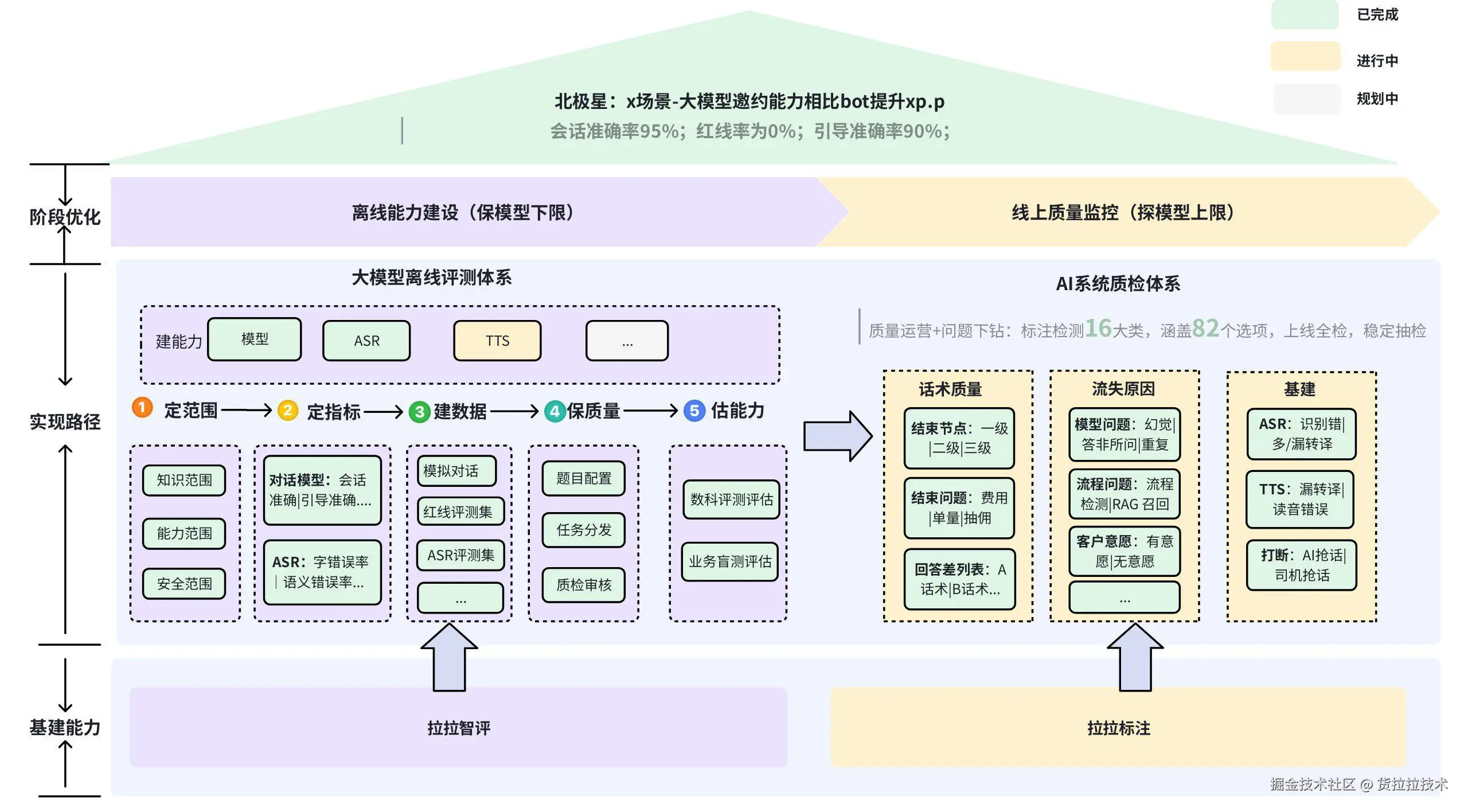
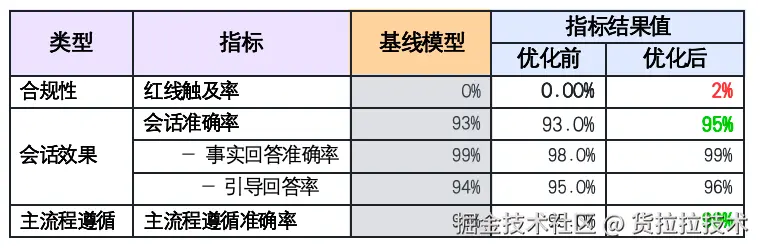
基于调研的评测行业信息,结合货拉拉实际业务场景特点,已沉淀一套半自动的评测体系,加速AI在邀约、客服、办公等场景的落地应用。
货拉拉x场景半自动评测体系图
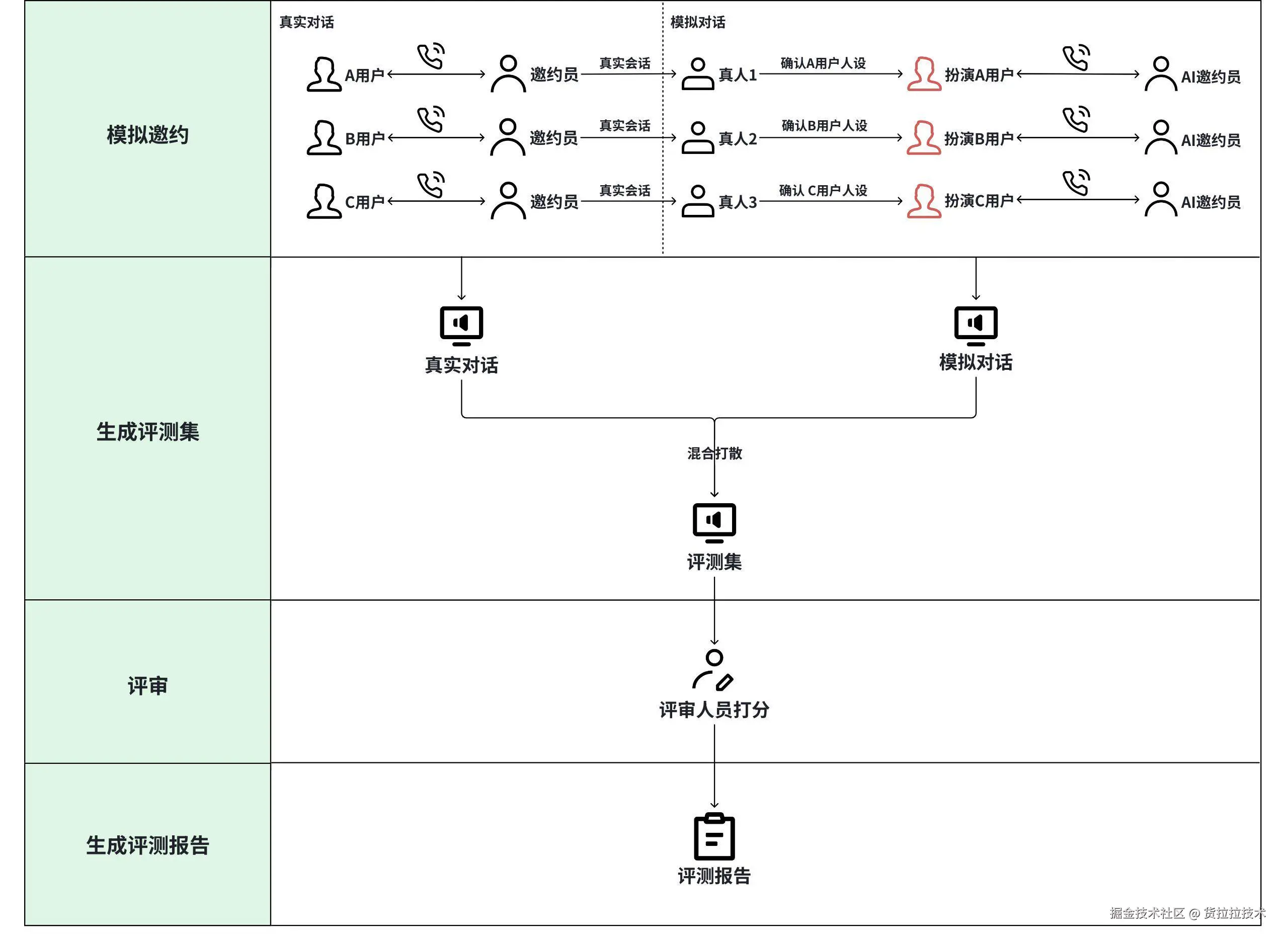
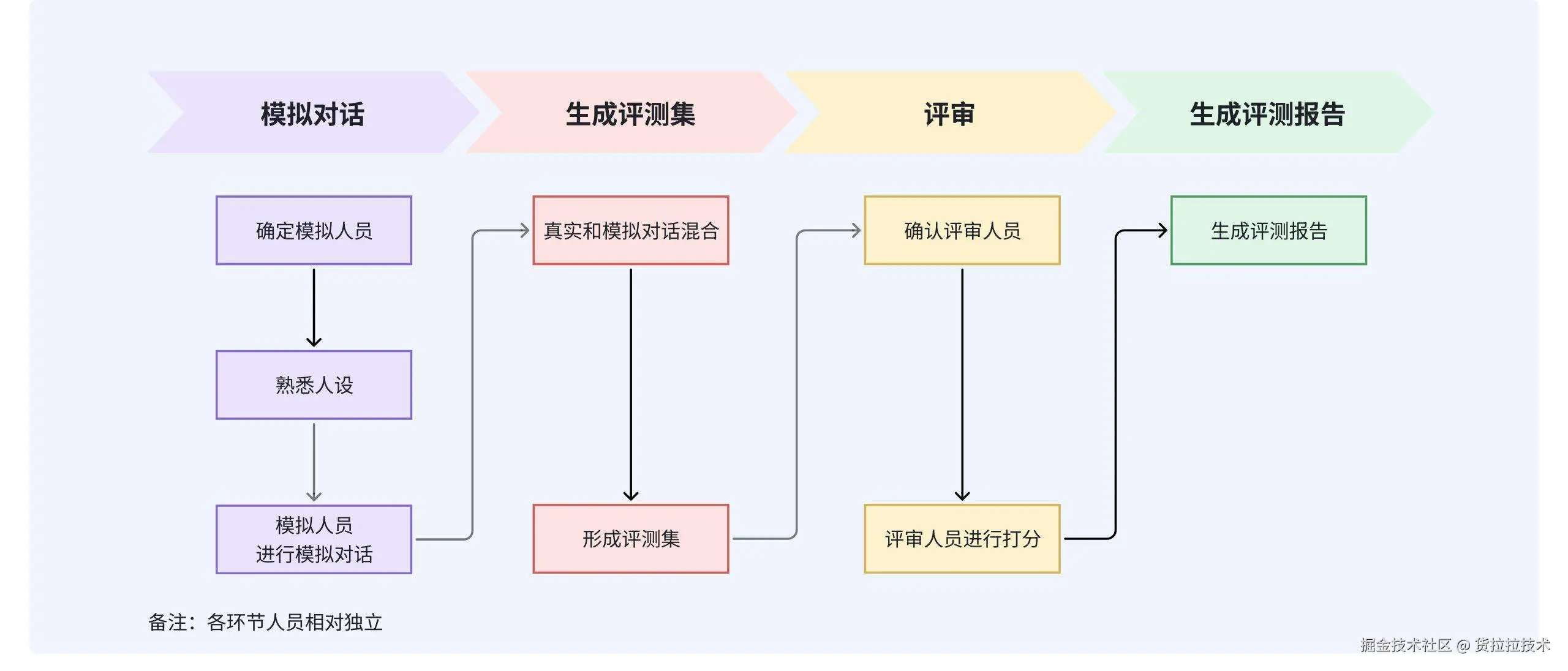
货拉拉x场景评测方案流程图,展示从模拟邀约数据提取数据到生成评测报告的整个对话评测流程
1.1 评测集生成
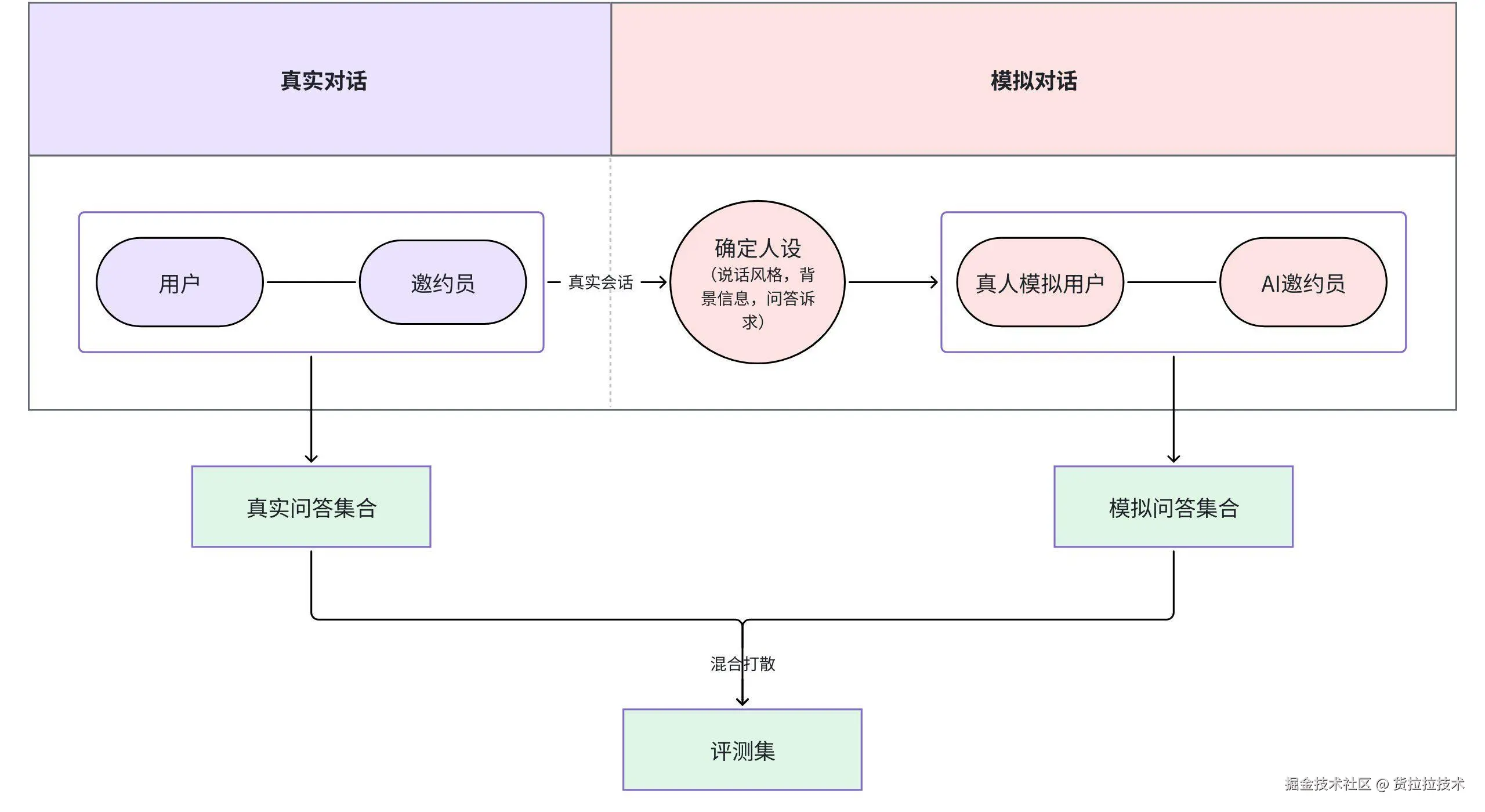
评测集构建流程:通过模拟真实用户,确定人设并与AI邀约员对话形成模拟问答集,通过与真实数据混合方式构建最终评测集
1.2 模拟人设策略
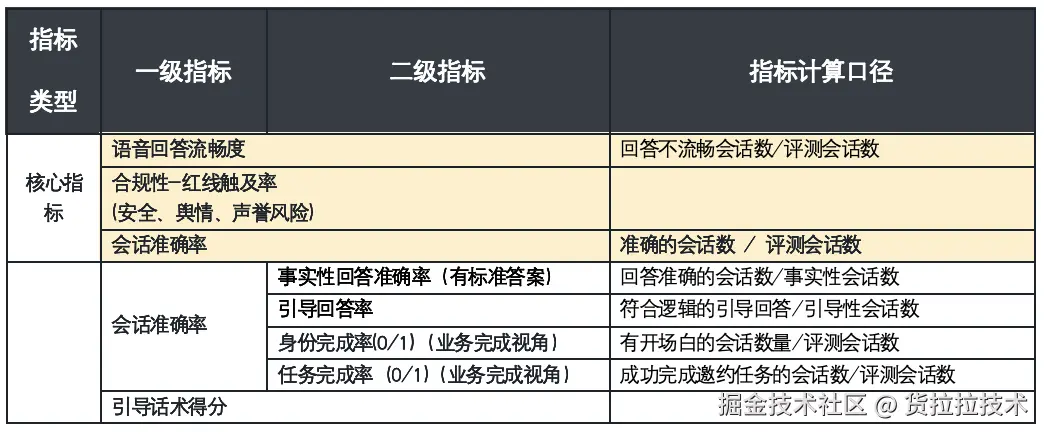
评测执行全流程
国家标准委:GB/T 45288.2-2025人工智能 大模型 第2部分:评测指标与方法-openstd.samr.gov.cn/bzgk/gb/new…
国际电信联盟电信标准分局(ITU-T):ITU-T F.748.44 基础模型的评估标准:基准测试-www.itu.int/rec/T-REC-F…
美国国家标准与技术研究院(NIST): 人工智能测试、评估、验证与确认(TEVV)标准零草案大纲-www.nist.gov/system/file…
中国信通院:
认知智能全国重点实验室:通用大模型评测体系 2.0-mp.weixin.qq.com/s/N4GjUef13…
SuperCLUE团队:SuperCLUE中文大模型基准测评框架-mp.weixin.qq.com/s/9-lVuQENO…
华东师范大学:金融数据分析领域框架/FinDABench基准-aclanthology.org/2025.coling…
蚂蚁集团x上海财经大学:金融大模型测评框架/FinEval-KR基准-aclanthology.org/2025.finnlp…
360数字安全集团:《大模型安全白皮书》-mp.weixin.qq.com/s/jBeJ4nBRv…

