



三星云服务
27.14M · 2026-04-12

在水环境生态监测与藻类研究中,藻类细胞的种类与数量变化往往是评估水体富营养化、污染程度及生态健康状态的重要依据。然而,传统依赖人工显微观察与手动统计的方法,不仅效率低下,而且对操作者的专业经验依赖较强,难以满足大规模、连续化监测的实际需求。
随着深度学习技术在计算机视觉领域的快速成熟,基于卷积神经网络的目标检测算法逐渐成为生物显微图像分析的重要技术手段。其中,YOLO 系列模型凭借端到端结构和优秀的实时性能,在实时检测场景中展现出显著优势。
基于此,本文介绍一套面向藻类细胞检测的智能识别系统,该系统以 YOLOv8 为核心检测模型,并结合 PyQt5 构建可视化操作界面,实现从模型训练到实际应用部署的完整闭环。
哔哩哔哩视频下方观看: www.bilibili.com/video/BV11i…
完整项目源码
预训练模型权重
️ 数据集地址(含标注脚本
本系统遵循“算法与应用解耦”的设计原则,整体可划分为四个功能层级:
这种分层结构既保证了算法模块的独立性,也为后续功能扩展(如更换模型、增加类别)提供了良好的工程基础。
系统当前支持 6 种常见藻类细胞的检测识别,覆盖多种典型水环境监测对象,包括:
每一类藻类在形态结构、尺寸分布和纹理特征上均存在差异,这对检测模型的特征提取能力提出了较高要求。
数据集采用标准 YOLO 格式进行组织,图像与标签一一对应。标签文件中使用归一化后的中心点坐标与宽高信息,确保模型在不同分辨率下具备良好的泛化能力。
在模型选型上,系统采用 YOLOv8 Detection 分支作为基础网络。该模型具备 Anchor-Free 架构,减少了锚框设计对检测效果的影响,尤其适合尺度变化较大的藻类细胞目标。
完整训练流程包括:
训练完成后,系统会自动保存最优权重文件,供后续推理与部署使用。
模型性能主要通过以下指标进行评估:
在实验数据集上,模型在主要类别上均取得较高的检测准确率,能够满足实际应用对稳定性与可靠性的要求。
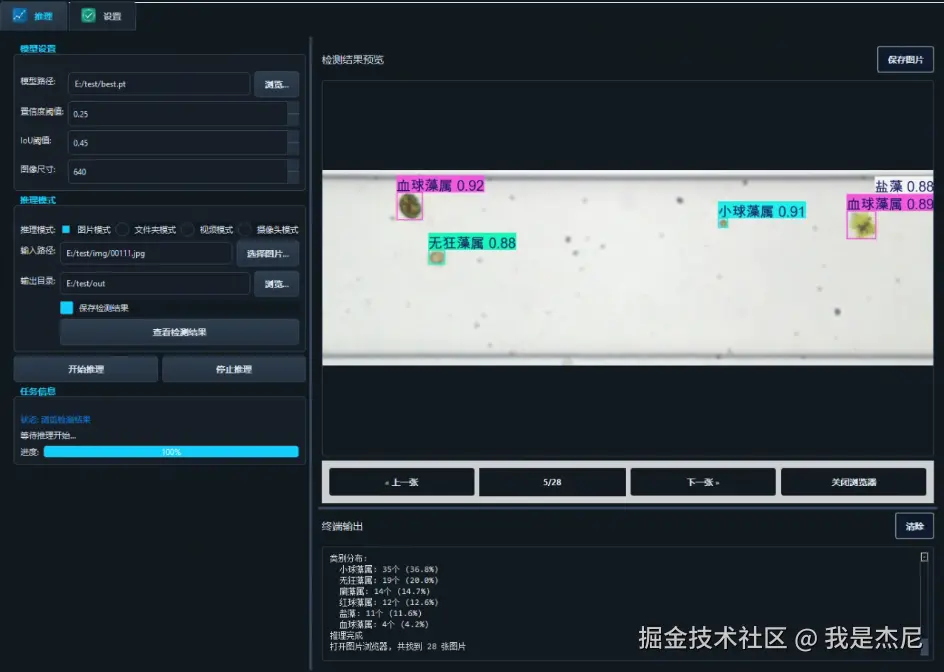
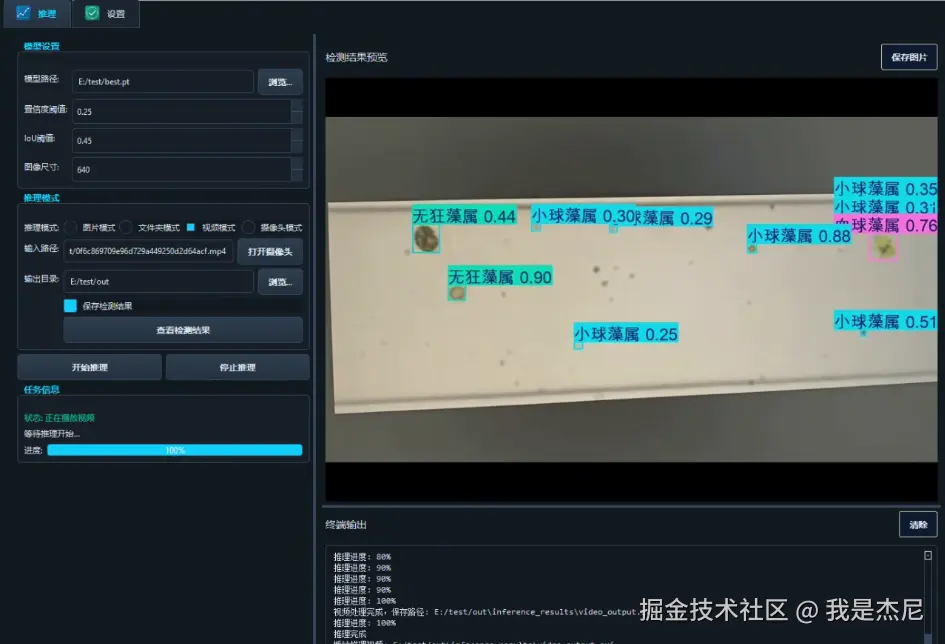
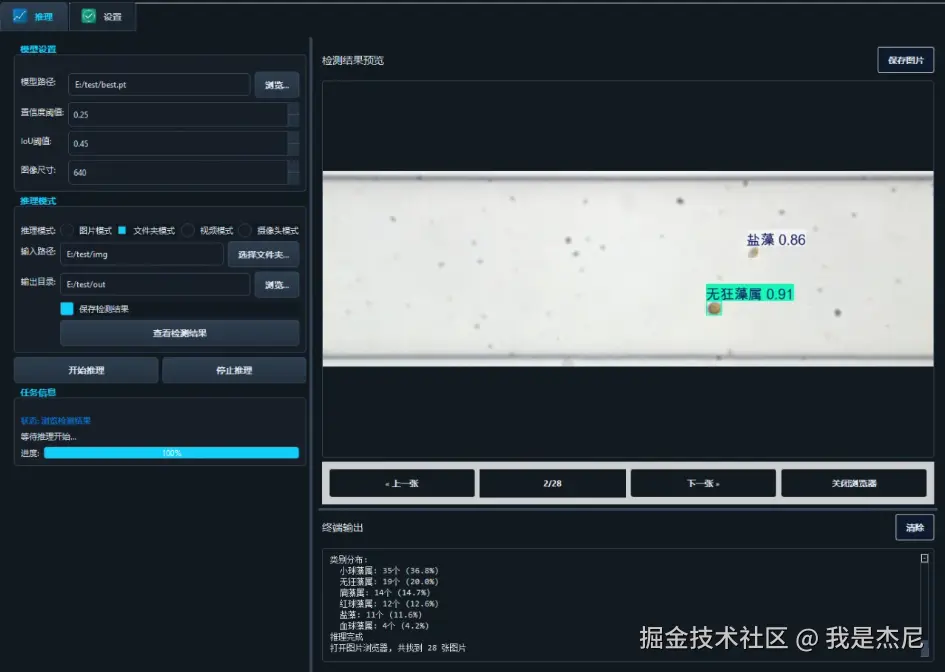
训练完成的模型可通过 Python 接口快速完成推理任务。推理结果不仅包含目标的类别与置信度,还提供精确的边界框坐标信息,可用于后续统计分析或二次处理。
在系统实现中,推理模块与界面模块解耦,既支持 GUI 调用,也可作为独立脚本运行,方便在服务器或边缘设备上部署。
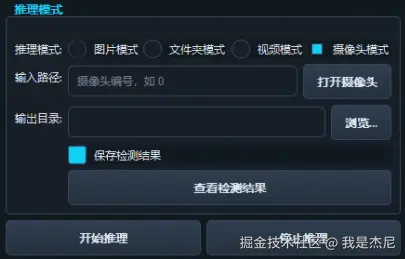
为提升系统易用性,项目基于 PyQt5 构建了完整的桌面端应用,主要功能包括:
所有操作均通过按钮触发,无需任何命令行操作,适合科研教学与现场演示使用。
相比纯脚本形式,图形化系统在实际使用中具有明显优势:
这使得深度学习模型真正从“算法原型”转化为“可用工具”。
在现有系统基础上,还可进一步开展以下工作:
本文介绍了一套基于 YOLOv8 与 PyQt5 的藻类细胞智能检测系统,从数据集构建、模型训练到图形化部署,完整展示了深度学习技术在生物图像识别领域的工程化落地过程。实践表明,该系统在检测精度、实时性能与易用性方面均具备良好表现,能够有效提升藻类识别的自动化水平。
对于从事环境监测、生物信息分析或计算机视觉应用开发的研究者与工程人员而言,该项目提供了一个具有参考价值的技术范例,也为后续更复杂的智能水环境分析系统奠定了基础。

