逃离森林
37.60M · 2026-02-26

@[toc]
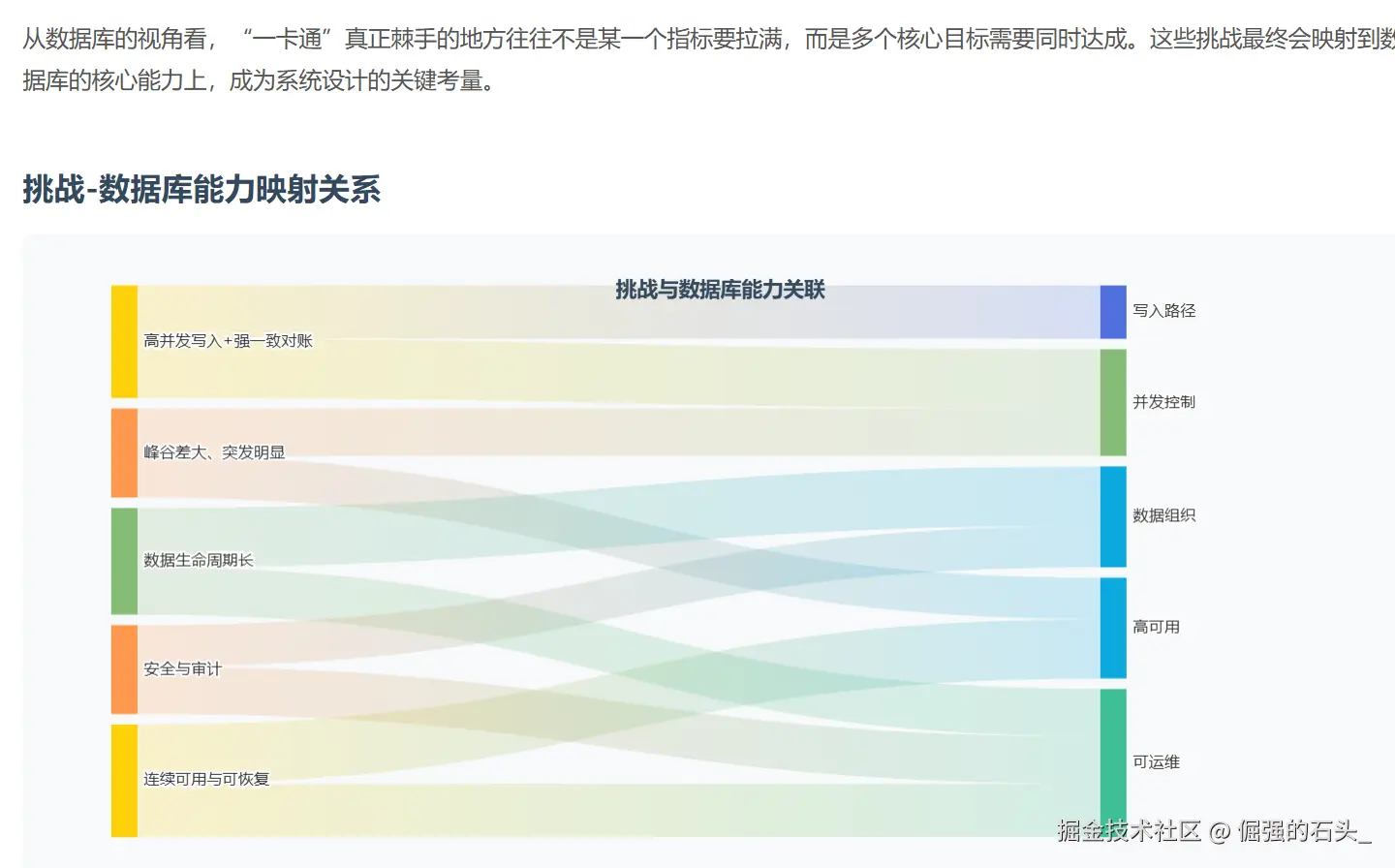
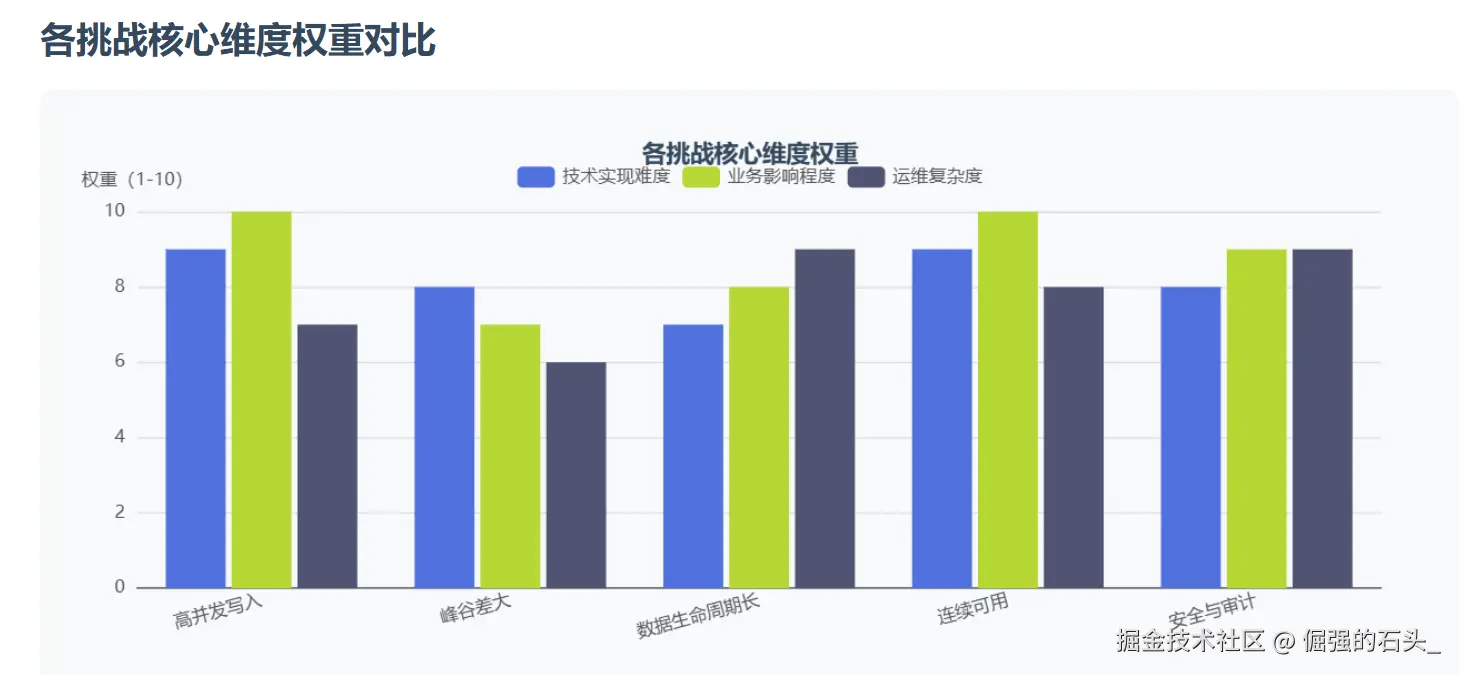
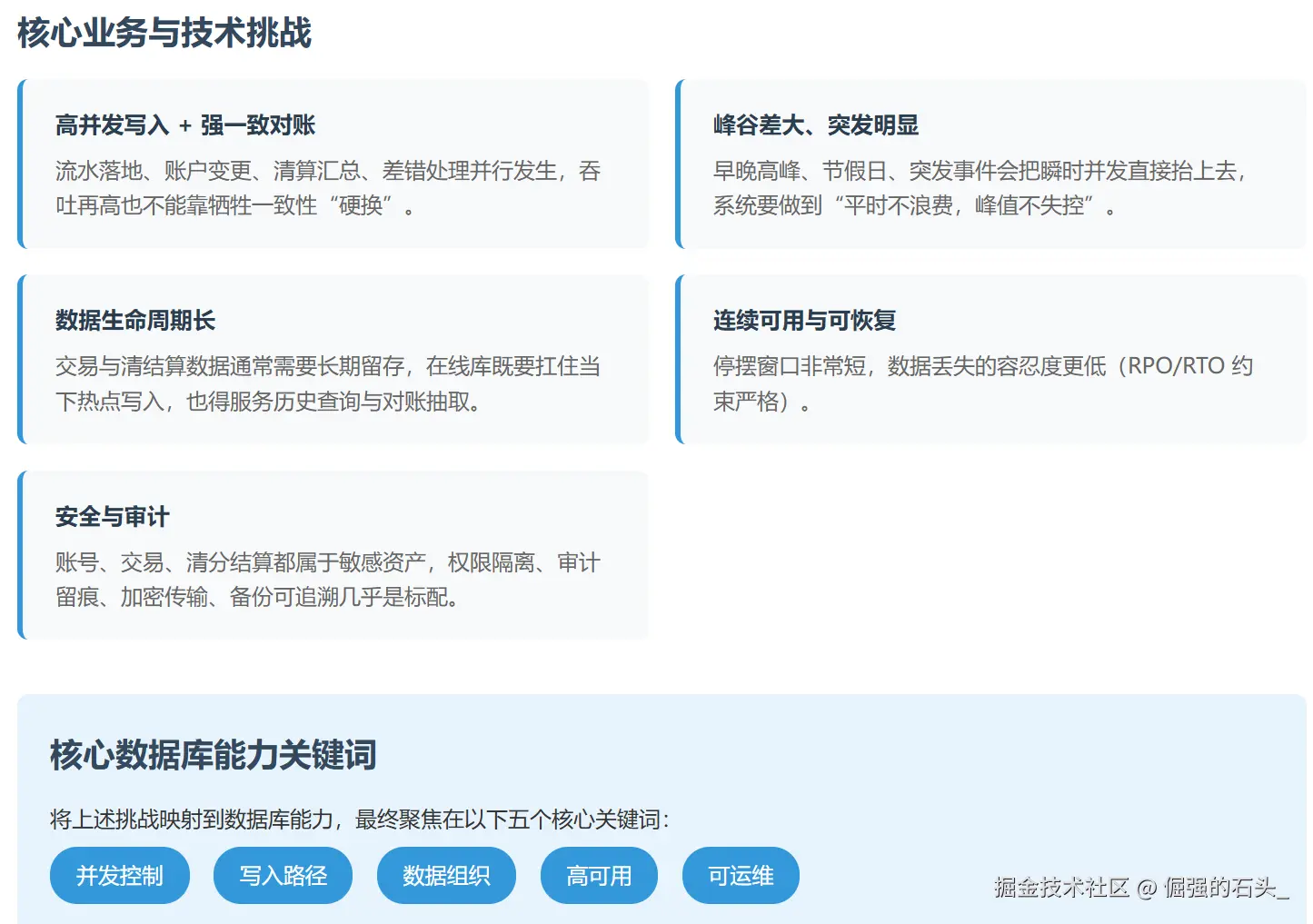
接触过城市级“一卡通”的同学多半知道,这种卡把“金融级一致性,交通级高并发,每天24小时运行”这几件事集于一身,其交易链路比较短,高峰期又特别集中;对账清算时使用的口径较多,链路就变得很长;数据保存的时间常常较长,而且还要符合监管审查以及安全合规的要求,文章联系这个平台选用金仓产品作为核心关系型数据库之后的实际操作情况,针对其架构的选择,数据模型的重点之处,高可用性和容灾能力,性能及稳定性的提升措施,还有迁移上线时的组织形式展开技术回顾,试图把“为什么要这样做,具体应该如何去做,实际效果怎样”阐述清楚,并附上一份可重复利用的列表和实例。
这类平台常见的形态是“交易域在线处理 + 清结算批处理 + 对外渠道接入”三段式组合。站在数据库一侧,关键动作有两个:把写热点和读热点分开,以及把强一致的边界收紧到最小闭环。
flowchart LR
subgraph Channel[渠道与终端]
A1[闸机/读卡器] --> G
A2[APP/小程序] --> G
A3[第三方支付渠道] --> G
end
G[接入网关/鉴权限流] --> T[交易服务]
G --> Q[查询服务]
T --> MQ[消息队列]
MQ --> C[清分清算/对账服务]
T --> DB[(核心关系型数据库)]
Q --> RO[(只读副本/读库)]
DB -.复制/同步.-> RO
C --> DW[(分析/报表/数仓)]
数据库在这里承担三类负载:
工程落地时,一般会把“核心交易库”当作强一致主库来运营,把查询与报表尽可能引到只读副本或分析系统上;对账清算这类波动明显、资源消耗大的任务,则用消息队列与批处理做削峰填谷,尽量别让主库背上不可控的大查询压力。
落到数据模型上,我更愿意先把“三句话原则”摆出来:流水尽量不可变、状态可以派生、对账必须可复算。这么做的直接收益是:并发场景下锁冲突更少、一致性风险更可控,后期审计与追溯也更从容。
示例(仅演示结构与思路,字段需按实际口径调整):
CREATE TABLE txn_ledger (
txn_id VARCHAR(32) NOT NULL,
occur_time TIMESTAMP NOT NULL,
card_no VARCHAR(32) NOT NULL,
account_id VARCHAR(32) NOT NULL,
amount_cent BIGINT NOT NULL,
txn_type VARCHAR(16) NOT NULL,
channel_code VARCHAR(16) NOT NULL,
merchant_id VARCHAR(32) NOT NULL,
trace_no VARCHAR(64) NOT NULL,
status VARCHAR(16) NOT NULL,
create_time TIMESTAMP NOT NULL,
PRIMARY KEY (txn_id)
);
查询侧建议优先保障两条主路径:一条是按卡/账号查近期交易;另一条是按渠道/商户/时间窗做对账抽取。比如:
SELECT txn_id, occur_time, amount_cent, txn_type, status
FROM txn_ledger
WHERE card_no = :card_no
AND occur_time >= :t0
AND occur_time < :t1
ORDER BY occur_time DESC
FETCH FIRST 100 ROWS ONLY;
这类查询只要分区裁剪和索引命中,成本就会很稳定,对主库的影响也能压下来。
余额类数据最怕两件事:并发更新带来的冲突,以及重试/重复请求造成的重复记账。工程上通常会这么收敛:
账户表仅存储“当前态”(余额,状态等),每次变更均能在流水中有据可依,做到可追溯,可重新计算。
幂等键需具备“硬约束”,trace_no,外部订单号等即属于此类情况,经由唯一约束或者幂等表,可以从机制层面阻止重复扣款/重复入账的发生。
更新语句尽量短,同一事务里别塞太多查询和复杂逻辑,把锁持有时间压到尽可能小。
示例(幂等控制 + 账户更新):
CREATE TABLE txn_idempotent (
idem_key VARCHAR(64) NOT NULL,
txn_id VARCHAR(32) NOT NULL,
create_time TIMESTAMP NOT NULL,
PRIMARY KEY (idem_key)
);
-- 伪代码式事务片段:
-- 1) 先插入幂等表(利用主键冲突实现“只处理一次”)
-- 2) 再落流水
-- 3) 最后更新账户表
想要长期跑在 7×24 的节奏里,高可用从来不是“搭个集群就完事”。更现实的做法是把三件事工程化:故障模型讲清楚、切换策略定下来、演练机制跑起来。
同城高可用里,一个更容易复用的思路是:核心库采用主备架构(同步或准同步复制取决于 RPO 要求),再配一套仲裁/探测机制,把切换做成自动或半自动的可控动作。
flowchart TB
APP[应用集群] --> VIP[数据库访问入口<br/>VIP/代理/连接串]
subgraph DC1[同城机房A]
P[(主库)]
end
subgraph DC2[同城机房B]
S[(备库)]
W[仲裁/见证]
end
VIP --> P
P <-.同步/准同步复制.-> S
W -.健康探测/仲裁.-> P
W -.健康探测/仲裁.-> S
落地细节上,更需要盯住这些“会在凌晨出问题”的点:
异地灾备的重点也不是“是不是多了一个点”,而是能不能真正恢复起来。通常要把下面几条跑通:
这类系统性能治理的经验存在三条主要脉络,即连接治理,SQL治理以及数据治理,把握住这三点,许多表面上颇具神秘色彩的线上波动就会回归到能够加以阐释和调控的范畴之内。
连接池需把控上限:把最大连接数及并发线程控制在可承受范围之内,防止高峰期遭遇“连接风暴”而崩溃。
应用侧需统一事务隔离 :超时,字符集,时区等重要参数,不能让它们各自为政,线上存在诸多怪异问题,往往源于这些参数不一致。
把阻塞看见:对等待事件、锁等待、长事务建立可观测能力,能定位就别靠猜。
高峰期时,最常见的现象并非“某条SQL特别慢”,而是“数量众多且复杂度中等的SQL堆积在一起”,而且锁范围被扩大,于是整体就出现波动。在实际操作当中,我更建议从以下几个方面着手:
别让主库执行大范围扫描,账目对比或者生成报表的时候最好利用只读副本或者离线系统,这样就可以减轻OLTP主库所承受的“不可控查询”的压力。
批量写入并批量提交时,在可控窗口里缩减提交次数,不过事务不要做的过大,防止回滚或者锁持有成本失去控制。
更新尽量走主键或高选择性索引,让锁冲突范围可控,减少并发互相“卡脖子”的概率。
做迁移时,最怕“接口跑通就算完”。更稳的做法是把工作拆成四条并行流水线:兼容评估、数据迁移、联调压测、灰度切换,每条线都要能独立交付结果。
flowchart LR
A[现网盘点] --> B[SQL与对象兼容评估]
B --> C[改造与适配]
C --> D[全量迁移]
D --> E[增量同步/双写验证]
E --> F[联调与压测]
F --> G[灰度切换]
G --> H[回归验证与收尾]
几条落地要点,建议当作上线门槛来卡:
在此类平台当中,数据库运维实际上是由“产品能力 + 制度流程 + 自动化工具”这三部分共同形成的,缺少其中任何一个部分,想要稳健运行起来都会很困难。
回顾“一卡通”项目时,站在数据库专业角度来讲,其关键之处并不在于某项单点技术多么夺目,而是要看工程闭合是否执行到位。
数据模型围绕流水展开,把一致性从“全局复杂”压缩到“局部可控”。
高可用用故障模型驱动,切换、仲裁、演练做到制度化、可重复。
性能治理盯住写路径,连接、SQL、分区与归档协同推进,主库不背不该背的查询负载。
迁移所交付的是可经营的能力,灰度,回滚,验证口径以及压测场景一同予以交付,并非仅仅交付“能运行起来”的东西。

