
FitCloud
136M · 2026-04-15

作为一线程序员高强度使用各种AI大模型和工具近1年,我深刻感受到了AI大模型的强大和便捷,但是一直在应用层不知道底层原理,很多概念理解的似是而非,没有体系化的知识体系,所以开始了这个自学人工智能之路。
1.我会结合视频教程、文档、大模型等学习资源,将自己学习人工智能的过程做个整理和记录。
2.后续会结合实际使用的案例和项目(有实际工作中的项目,也有自己兴趣使然的作品),逐步讲解一些经验和教训,希望能给大家带来一些帮助。
3.其中的一些错误和共鸣点欢迎大家指正和交流。
在上一讲中,我们学习了全连接神经网络 (DNN/MLP)。虽然理论上它可以拟合任何函数,但在处理复杂数据(如图像和文本)时,它面临两个巨大挑战:
为了解决这些问题,AI 进化出了三种专门的架构:CNN(处理空间数据) 、RNN(处理时间数据) 和 Transformer(处理序列数据的终极形态) 。
CNN (Convolutional Neural Network) 是计算机视觉领域的绝对霸主。它的核心思想是:与其盯着每一个像素,不如寻找局部的特征。
想象你在黑暗中用手电筒看一幅巨大的壁画。你无法一眼看清全貌,只能拿着手电筒(卷积核/Filter)在壁画上(输入图像)从左到右、从上到下地扫描。 每次手电筒照亮的一小块区域,就是感受野 (Receptive Field)。你在这个区域里寻找特定的图案(比如“竖线”或“圆弧”),如果找到了,就记录下来。
卷积核本质上是一个小的权重矩阵(比如 )。 它在图像上滑动,每次覆盖 的像素区域,将像素值与卷积核的权重做点积(对应位置相乘再求和)。
这个操作的结果反映了该区域与卷积核特征的匹配程度。
当你在看一张高清大图时,为了看清轮廓,你可能会眯起眼睛,或者把图片缩小。这就是池化。 池化层的作用是降维和保留主要特征。
经典的 CNN 架构(如 LeNet, AlexNet, ResNet)通常是这样的“三明治”结构:
输入层 (Input Layer):
卷积层 (Convolution Layer) - “特征提取器” :
激活层 (ReLU Layer) - “非线性开关” :
f(x) = max(0, x)。把负数变成0,正数保持不变。池化层 (Pooling Layer) - “信息压缩机” :
全连接层 (Fully Connected Layer) - “分类器” :
如果说 CNN 是“看”图片的专家,那么 RNN (Recurrent Neural Network) 就是“读”文章的高手。
人类阅读文章时,对当前词语的理解是依赖于上下文的。 比如:“我到达了苹果...”,这里的“苹果”是指水果还是手机? 如果后面接“...园,摘了一个吃”,那就是水果;如果接“...总部,购买了新手机”,那就是科技公司。 传统的全连接网络无法处理这种变长的、有前后依赖关系的序列数据。
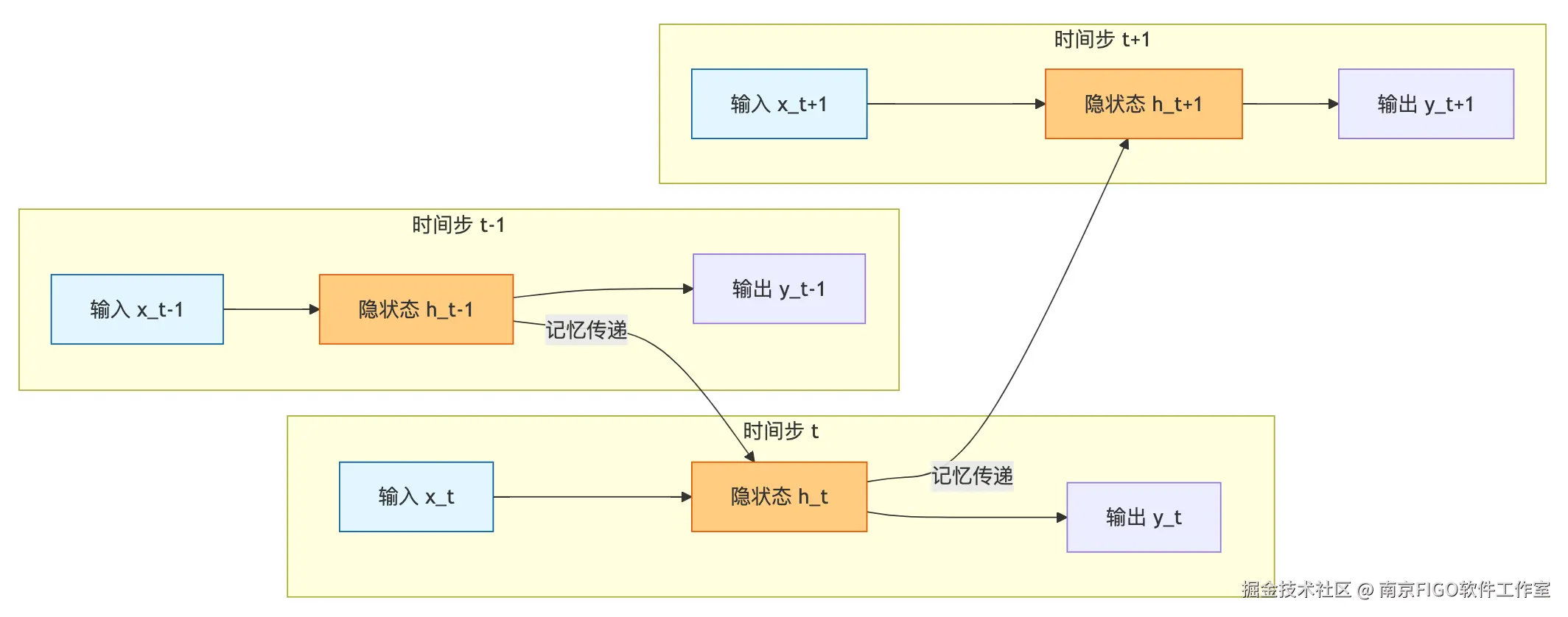
RNN 的天才之处在于引入了隐状态 (Hidden State) ,你可以把它理解为记忆。
时间步 (Time Step):
输入层 (Input Layer ):
隐状态层 (Hidden Layer ) - “大脑/记忆” :
输出层 (Output Layer ):
RNN 处理序列数据(如一句话)是按时间步 (Time Step) 进行的:
每一个时刻的输出,都不仅取决于当前的输入,还取决于之前的记忆。这就好比你读书时,脑海里始终保留着对前文的印象。
虽然 RNN 理论上能记忆无限长的序列,但在实际训练中,它面临梯度消失 (Gradient Vanishing) 和 梯度爆炸 的问题。 简单说,就是记不住太久以前的事情。就像读一本很长的小说,读到最后几章时,已经忘了第一章的主角叫什么名字了。
为了解决这个问题,后来诞生了 LSTM (长短期记忆网络) 和 GRU。它们通过引入精妙的门控机制 (Gating Mechanism)(遗忘门、输入门、输出门),主动选择该记住什么、该忘掉什么,大大延长了记忆的持续时间。
尽管 LSTM 改进了 RNN,但它依然有一个致命弱点:无法并行计算。 RNN 必须读完第一个词才能读第二个词,这导致训练速度极慢,无法利用大规模 GPU 集群。而且,对于特别长的序列,LSTM 的记忆能力依然有限。
2017 年,Google 团队发表了划时代的论文 《Attention Is All You Need》 ,提出了 Transformer 架构,彻底改变了 NLP 乃至整个 AI 领域的格局。
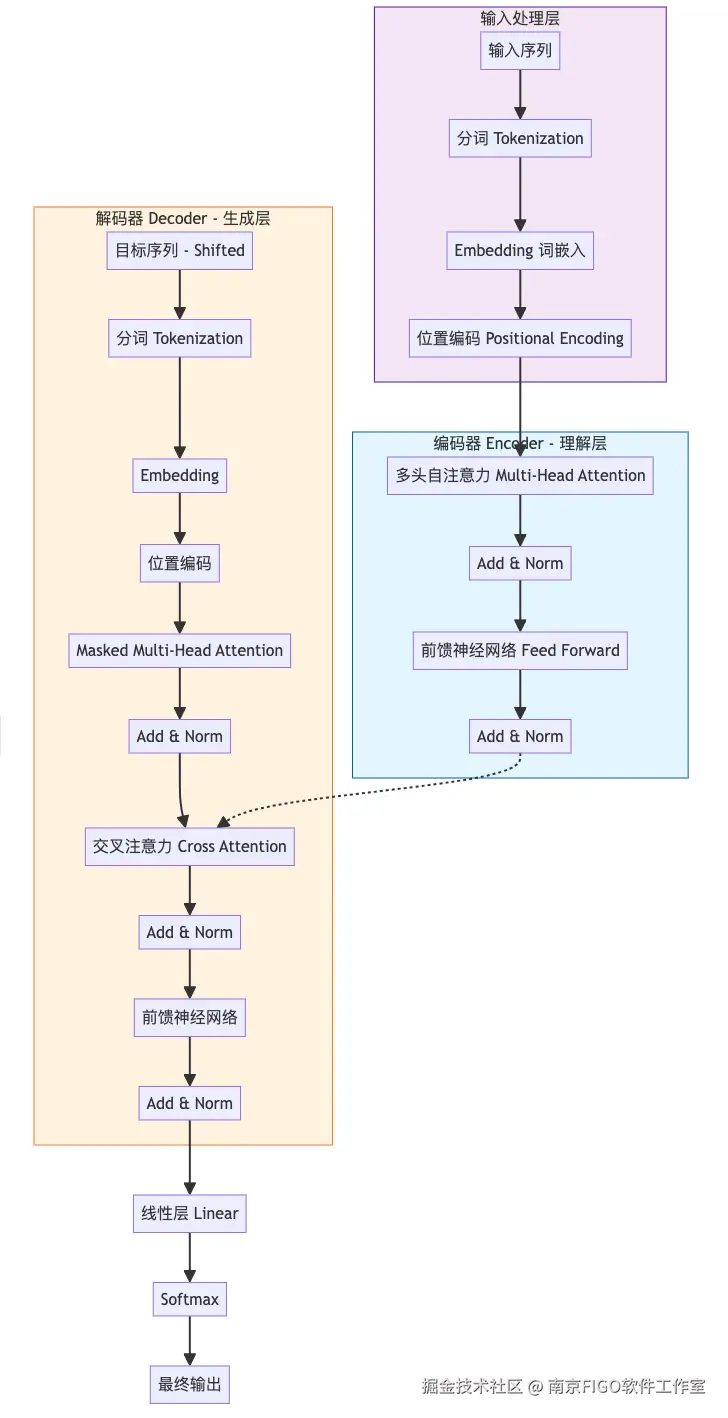
虽然自注意力机制是核心,但要让它真正工作起来,还需要一个完整的身体架构。下图展示了 Transformer 的经典架构(Encoder-Decoder 结构)。
为了让你彻底看懂这张“神图”,我们将按照数据流动的方向,把每个方块拆碎了讲。
这里是数据进入模型的第一个关卡。在进入模型之前,其实还有一个隐含的步骤:分词 (Tokenization)。
Tokenization (分词):
[102, 520, 305]。Embedding (词嵌入):
[0.1, 0.5, ...],让计算机能进行数学运算。Positional Encoding (位置编码):
左边的蓝色方块是 Encoder,它的任务是深刻理解输入的内容。
Multi-Head Attention (多头自注意力):
Add & Norm (残差连接与层归一化):
Feed Forward (前馈神经网络):
右边的橙色方块是 Decoder,它的任务是根据 Encoder 的理解,生成新的内容(比如翻译结果)。
Inputs (Shifted Right):
Masked Multi-Head Attention (掩码多头注意力):
Cross Attention (交叉注意力):
Transformer 抛弃了循环(RNN)和卷积(CNN),完全依赖注意力机制。
在嘈杂的鸡尾酒会上,你的耳朵能接收到所有人的声音,但你的大脑会自动聚焦 (Attention) 在和你聊天的那个人身上,通过上下文理解他的话,同时忽略背景噪音。
Transformer 将注意力机制形式化为 Query (查询) , Key (键) , Value (值) 的操作。 这很像在图书馆找书或数据库查询:
计算过程:
通过这种方式,Transformer 可以一次性看到整句话的所有词,并计算出每个词与其他所有词的关联程度。比如在“银行里的钱”这句话中,“银行”会特别关注“钱”这个词,从而确定自己是“金融机构”而不是“河岸”。
这就是为什么 Transformer 能理解上下文:它把上下文的信息“加”到了当前词的向量里。
这里我们可以跳过通俗的比喻,直接看数据流和矩阵变换。这才是 Transformer 的灵魂所在。
假设我们有一个输入序列 (比如 "Thinking Machines" 两个词),每个词已经 Embedding 为一个 4 维向量。 输入矩阵 的维度是 [2, 4] (sequence_length=2, embedding_dim=4)。
Transformer 内部维护了三个可训练的权重矩阵:。 我们将输入 分别乘以这三个矩阵,得到查询(Query)、键(Key)、值(Value)三个新矩阵。
[2, 4] * [4, 3] -> [2, 3] (假设 projected_dim=3)计算 Q 和 K 的转置矩阵的乘积。
公式:
维度变化:[2, 3] * [3, 2] -> [2, 2]
物理意义:得到一个 seq_len * seq_len 的方阵。矩阵中第 行第 列的值,代表第 个词和第 个词的相关性分数。
Scores[0][0] 是 "Thinking" 对 "Thinking" 的关注度。Scores[0][1] 是 "Thinking" 对 "Machines" 的关注度。将分数除以 (key 向量维度的平方根,这里是 )。
对每一行进行 Softmax 操作。
用算出的概率去加权 Value 矩阵。
公式:
维度变化:[2, 2] * [2, 3] -> [2, 3]
最终结果:生成的 矩阵维度与 一致。
为了彻底理解,我们用最基础的 NumPy 来还原这个过程:
import numpy as np
def self_attention(X, W_Q, W_K, W_V):
"""
X: [seq_len, d_model] - 输入矩阵
W_Q, W_K, W_V: [d_model, d_k] - 权重矩阵
"""
# 1. 线性投影 (Linear Projections)
# 这一步通常由 nn.Linear 完成
Q = np.dot(X, W_Q) # shape: [seq_len, d_k]
K = np.dot(X, W_K)
V = np.dot(X, W_V)
# 2. 矩阵点积 (Dot Product)
# Q 乘以 K 的转置
scores = np.dot(Q, K.T) # shape: [seq_len, seq_len]
# 3. 缩放 (Scaling)
d_k = Q.shape[1]
scores = scores / np.sqrt(d_k)
# 4. 归一化 (Softmax)
# 对每一行做 softmax
exp_scores = np.exp(scores)
attention_weights = exp_scores / np.sum(exp_scores, axis=1, keepdims=True)
# shape: [seq_len, seq_len]
# 5. 加权求和 (Weighted Sum)
# 权重矩阵乘以 V
output = np.dot(attention_weights, V) # shape: [seq_len, d_k]
return output, attention_weights
# --- 测试数据 ---
X = np.array([
[1, 0, 1, 0], # Input 1
[0, 2, 0, 2], # Input 2
[1, 1, 1, 1] # Input 3
])
# 随机初始化权重
W_Q = np.random.rand(4, 3)
W_K = np.random.rand(4, 3)
W_V = np.random.rand(4, 3)
output, weights = self_attention(X, W_Q, W_K, W_V)
print("Attention Weights Matrix:n", np.round(weights, 2))
print("nContextualized Output:n", np.round(output, 2))
一句话总结:自注意力机制本质上就是一个“基于内容的动态加权求和”算法。它通过矩阵运算,让序列中的每个元素都能聚合全局信息。
很多开发者第一次看 Transformer 代码时,最困惑的就是 Multi-Head 到底是怎么“切”出来的。是把输入复制多份吗?还是有什么黑魔法?
其实,它的实现非常优雅且高效,核心就在于矩阵维度的 Reshape 和 Transpose。
如果是单头(Single-Head),Q、K、V 的维度就是 d_model(比如 512)。这意味着我们只能在一个特征空间里寻找词与词的关系。 但语言是复杂的:
多头机制就是让模型拥有“分身术”,同时在多个不同的子空间(Subspace)里捕捉信息,最后再拼起来。
假设 d_model = 512,我们要分 h = 8 个头。 每个头的维度就是 d_k = 512 / 8 = 64。
关键点:我们并不是创建了 8 个独立的矩阵,而是把一个大矩阵“拆”成了 8 个小矩阵。
数据流向 (Data Flow):
线性投影 (Linear Projection): 输入 经过 投影后,维度依然是 [batch, seq_len, d_model] (例如 [32, 10, 512])。
切分 (Split / Reshape): 我们将最后一维 512 拆解为 8 * 64。
view(batch, seq_len, heads, d_k)[32, 10, 512] -> [32, 10, 8, 64]转置 (Transpose / Permute): 为了让每个头能独立计算 Attention,我们需要把 heads 维度移到前面。
transpose(1, 2)[32, 10, 8, 64] -> [32, 8, 10, 64]并行计算 Attention: 现在的维度是 [32, 8, 10, 64]。 当我们做矩阵乘法时,后两维 [10, 64] 参与运算,前两维 [32, 8] 被视为 Batch 处理。 这意味着 8 个头的注意力计算是完全并行发生的,GPU 极其擅长这种操作。
拼接 (Concat): 计算完 Attention 后,维度变回 [32, 8, 10, 64]。 我们需要把它还原回去:
[32, 10, 8, 64][32, 10, 512]最终线性层 (Final Linear): 最后经过一个 矩阵,融合 8 个头的信息。
# 假设 batch_size=32, seq_len=10, d_model=512, heads=8, d_k=64
def multi_head_attention_split(x):
# x: [batch, seq_len, d_model] -> [32, 10, 512]
# 1. 线性投影得到 Q (这里简化演示,实际会有 W_q)
# q = linear(x)
# q shape: [32, 10, 512]
# 2. Reshape: 把 512 拆成 8 * 64
# 此时维度: [32, 10, 8, 64]
q = q.view(32, 10, 8, 64)
# 3. Transpose: 把头(8) 换到 序列长度(10) 前面
# 这一步是核心!让每个头独立
# 此时维度: [32, 8, 10, 64]
q = q.transpose(1, 2)
# ... 对 K, V 做同样操作 ...
# 4. 计算 Attention
# 这里的矩阵乘法只发生在后两维 [10, 64] * [64, 10]
# 前面的 [32, 8] 就像是 32*8 = 256 个独立的任务在并行
scores = torch.matmul(q, k.transpose(-2, -1))
return scores
一句话总结:Multi-Head 不是物理上的“分身”,而是逻辑上的“多视角切片”。通过 Reshape 和 Transpose,我们在不增加计算量级的前提下,让模型拥有了“多重思维”。
Transformer 依然属于神经网络家族,它的底层同样由神经元(矩阵乘法、激活函数)组成,但它在架构设计上与前辈们有着本质的区别。为了让你从传统软件开发的视角理解它们的关系,我们可以用软件开发架构的演进史来类比:
简单说:Transformer 是神经网络家族中,目前最先进、最能打的一个“变种”。
Transformer 的出现催生了现在的 LLM(大语言模型)盛世:
最后,我们将这三位巨头做一个横向对比,帮助大家建立完整的知识图谱。
| 特性 | CNN (卷积神经网络) | RNN (循环神经网络) | Transformer |
|---|---|---|---|
| 核心操作 | 卷积核滑动窗口 | 循环递归 (隐状态) | 自注意力机制 (Self-Attention) |
| 擅长领域 | 计算机视觉 (CV) 图像分类、检测 | 自然语言处理 (NLP) 语音识别、时间序列 | 全能霸主 (NLP + CV) 大语言模型、多模态 |
| 数据特征 | 空间局部性 (Grid) | 时间顺序性 (Sequence) | 全局关联性 (Set/Graph) |
| 并行计算 | 容易并行 | 难以并行 (串行) | 极易并行 |
| 长距离依赖 | 较弱 (受限于感受野) | ️ 一般 (受限于梯度消失) | 极强 (全局视野) |
| 代表模型 | ResNet, YOLO, VGG | LSTM, GRU | BERT, GPT, LLaMA |
总结:
Tokenization和大模型中常提到的“100k限制”之间是计量单位与容量上限的关系。简单来说,Tokenization(分词) 定义了模型认识和使用的“语言单元”——Token,而 “100k限制” 就是指模型一次性能处理的最大Token数量,也就是它的上下文窗口大小。
打个比方,可以把大模型想象成一个记忆力超群,但“工作记忆”有限的读者:
apple),也可以是一个词的一部分(如 ing),甚至是一个标点符号。对中文来说,一个汉字通常就是一个Token。Tokenization是让大模型理解文本的第一步,它有一套自己的拆解规则:
unhappiness 可能会被拆成 un、happi 和 ness 这样三个Token。这样做的好处是,即使遇到没见过的生僻词,模型也能通过拆解后的已知子词来“猜”出大概意思,有效避免了“词汇表里没有,我就不认识”的尴尬。上下文窗口的大小,直接决定了模型在生成回答时,能同时“回顾”多少前文信息。
所以,当你向一个拥有100k上下文窗口的模型提问时,你的输入文本会先经过分词器,被拆解成一个个Token,然后模型会在这个不超过 100k个Token 的范围内,理解你的意思并组织语言进行回复。
这个问题触及了大模型技术的核心瓶颈。之所以会有100k(即10万token左右)这个限制,根本原因在于计算成本、内存消耗和模型架构三者之间的复杂博弈。
简单来说,不是不想做得更大,而是做到100k级别已经是当前技术在“成本”和“性能”之间找到的一个艰难平衡点。
以下是导致这个限制的几个核心原因:
目前绝大多数大模型(如GPT系列)都基于Transformer架构。它的核心机制是自注意力机制,这个机制允许模型在处理一个词时,同时关注句子中所有其他词。
数学关系:如果输入文本的长度是 ( n )(即Token数量),那么模型需要计算两两之间的注意力。这种计算量和内存占用的增长速度大约是 ( n^2 )(即平方级增长)。
直观理解:
即便算力足够,内存也是一个巨大的制约因素。这里的“内存”指的是显卡的显存(VRAM)。
即使硬件的钱不是问题,模型本身的数学特性也会带来挑战。
除了技术原因,商业因素也决定了为什么主流产品目前普遍选择100k(如GPT-4 Turbo, Claude 3)作为标准。
你可能会问,那为什么现在有一些模型(如Google的Gemini 1.5 Pro,或者一些国产模型)开始支持1M(100万)甚至更大的窗口呢?
这是因为业界正在通过算法优化来“绕过”平方级的复杂度:
所以,100k的限制本质上是 “数学定律(平方级增长)”、“物理限制(内存墙)”和“经济规律(成本效益)”共同作用的结果。
100k是当前工程实践中的一个黄金分割点——它足够覆盖绝大多数人类知识载体(如书籍、报告),同时又能让普通用户的显卡和云端算力勉强承受得住。而突破100k向1M迈进,则意味着必须在算法或硬件上进行革命性的创新。
这个问题很有深度,触及了大模型计算复杂度的核心。要理解窗口大小(序列长度 ( n ))和计算量之间的关系,关键在于剖析 Transformer模型中自注意力机制的计算过程。
这个关系通常被称为 ( O(n^2) ) 复杂度。这里的 ( n ) 指的是输入序列的长度(Token数量),而 ( O ) 表示算法的复杂度。
我们可以把计算过程拆解为两个主要部分来理解这个 ( n^2 ) 是如何产生的:
假设我们有一个长度为 ( n ) 的句子(即 ( n ) 个Token)。在自注意力机制中,模型需要找出这 ( n ) 个词中,每一个词与其他所有词之间的关系强度。
步骤拆解:
准备数据:模型为每个单词生成三个向量:查询向量、键向量、值向量。
两两组合计算:
数学关系:
直观对比:
可以看到,当 ( n ) 扩大10倍(从100k到1M),计算量不是扩大10倍,而是扩大 ( 10^2 = 100 ) 倍。
这个 ( n times n ) 的注意力矩阵不仅需要计算,还需要临时存储在显卡(GPU)的显存中,以便进行后续的梯度计算。
存储关系:这个矩阵的大小同样是 ( n^2 )。
举例说明:
这就是为什么说大窗口会导致 “内存墙” ——显存的物理容量限制了我们能处理的最大 ( n )。
你可能会好奇,既然 ( n^2 ) 这么可怕,为什么现在有些模型号称支持 1M 甚至 10M 的上下文?它们是怎么绕过这个数学定律的?
这主要归功于工程和算法上的近似优化,它们不再计算完整的 ( n^2 ) 矩阵:
稀疏注意力:
RNN(循环神经网络)式线性化:
检索增强生成:
窗口大小 ( n ) 与计算量的关系 ( O(n^2) ) ,来源于自注意力机制必须计算每个Token与其他所有Token之间关系的设计。
我们来完整地看一下图片、文档和视频这三种模态的Token计算方式。它们遵循完全不同的逻辑:图片和视频是按“视觉块”算的,文档则通常是先转成纯文本再计算。
模型通过视觉编码器处理图片,核心是将其切割成固定大小的方块。
有趣的是,这种方式信息压缩效率极高。研究发现,一篇约1000个文字Token的文档,如果换成“看图”的方式处理,可能只需要100个视觉Token就能以97%的精度还原,相当于压缩了10倍。
不同模型的具体参数可能略有差异,建议查阅官方文档获取精确值。
对于PDF、Word等文档,其计算方式非常直接:
视频的处理最为复杂,因为它增加了时间维度。视频被看作一系列图片(帧)的集合,计算方式是在图片的二维网格基础上,再增加一个时间轴,形成三维的立方块。
T x H x W 的网格。其中 T 代表时间维度的帧数,H 和 W 代表每帧图片的高度和宽度上的网格数。T * H * W。例如,一个包含10帧、每帧切分成14x14网格的视频,其Token总数大约为 10 * 14 * 14 = 1960 个。为了提升效率,一些技术会通过剪枝(Pruning)策略,智能地保留信息量大的Token,丢弃冗余的Token,从而减少计算量。
最后有一个非常重要的提醒:不同的模型服务商和模型版本,其具体的Token计算规则(特别是视觉部分的编码方式)可能不一样。最准确的方法是查阅你所使用模型的官方技术文档。
随着 AI 技术的指数级迭代,2026 年的大模型领域已进入“Agent(智能体)”与“原生多模态”的全新时代。为了让你在选择模型时不再迷茫,我们从开源属性、模型类型、擅长领域等多个维度,对目前(截至 2026 年)国内外的主流大模型进行一次盘点。
| 模型名称 | 厂商 (国家) | 核心类型 | 开源情况 | 核心优势 / 擅长领域 |
|---|---|---|---|---|
| GPT-5 (Orion) / o3 | OpenAI (美) | 原生多模态 / 强推理 | 闭源 | AGI雏形,o3 具备自主反思与长程规划能力,GPT-5 实现毫秒级全模态交互 |
| Claude 4 Opus | Anthropic (美) | 多模态 | 闭源 | 最强安全性与长窗口,支持 10M+ token 上下文,代码架构能力无可匹敌 |
| Gemini 2.0 Ultra | Google (美) | 原生多模态 | 闭源 | 生态整合之王,与 Android/Workspace 深度绑定,视频理解与生成能力业界第一 |
| Llama 4 (405B) | Meta (美) | 文本 / 多模态 | 开源 | 开源界定海神针,性能对标 GPT-5,全球开发者首选基座,私有化部署标准 |
| DeepSeek-V4 / R2 | 深度求索 (中) | 稀疏混合专家 / 推理 | 开源 | 极致性价比,R2 在数学/代码竞赛中超越 o3,推理成本仅为 GPT-5 的 1/10 |
| Qwen 3 (通义千问) | 阿里巴巴 (中) | 多模态 Agent | 开源 | 最强中文能力,视觉智能体 (Visual Agent) 能力突出,在手机端侧表现优异 |
| Grok 3 | xAI (美) | 实时多模态 | ️ 部分开源 | 实时信息流,直接接入 X (Twitter) 实时数据,具备独特的“叛逆/幽默”模式 |
| Kimi (Moonshot) | 月之暗面 (中) | 长文本 / 智能体 | 闭源 | 长文本鼻祖,支持 100M+ 级无损上下文,擅长财报分析与长篇小说创作 |
| MiniMax (海螺 AI) | 稀宇科技 (中) | 多模态 / 语音 | 闭源 | 拟人化最强,语音合成 (TTS) 极其逼真,角色扮演 (Roleplay) 体验业界第一 |
| Yi-Lightning 2 | 零一万物 (中) | 长文本 | 闭源 | 超长文档分析,在千万级 token 的大海捞针测试中保持 100% 召回率 |

