

爱回收
75.46M · 2026-04-05

Anthropic发布了Claude Opus 4.6新版本,官方定位为"最智能的模型",主打复杂智能体任务和长时程工作。相比此前的Claude Opus 4.5版本,新版本在架构上进行了多项升级,包括首次在Opus级别支持100万token上下文窗口、引入自适应思考(adaptive thinking)机制等。
我们对这两个版本进行了全面的对比评测,测试其在准确率、响应时间、token消耗和成本等关键指标上的表现差异。需要特别说明的是,本次评测主要聚焦于中文语境下的场景,官方所强调的复杂智能体任务、长时程编程工作、跨百万token上下文处理等核心优势,在当前评测框架下尚未得到充分体现。
Claude Opus 4.6版本表现:
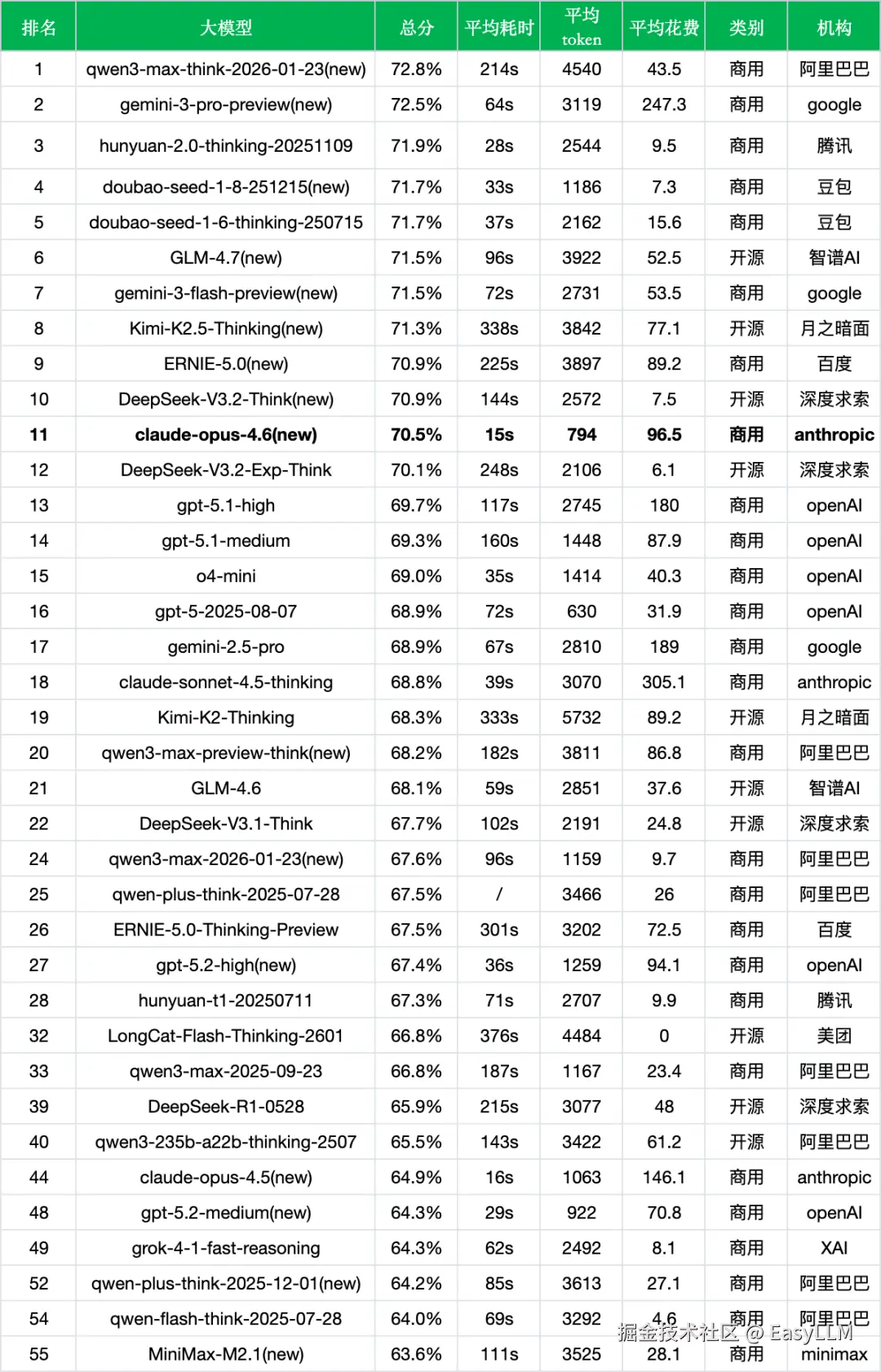
1、新旧版本对比
首先对比上个版本(Claude Opus 4.5),数据如下:
*数据来源:ReLE评测github.com/jeinlee1991…
*输出价格单位: 元/百万token
2、对比其他模型
在当前主流大模型竞争格局中,Claude Opus 4.6表现如何?我们从三个维度进行横向对比分析(本评测侧重中文场景,模型在其他语言和专业领域的表现可能有所不同):
*数据来源:ReLE评测github.com/jeinlee1991…
2.1 同成本档位对比
2.2 新旧模型对比
2.3 开源VS闭源对比
3、官方评测
根据Anthropic官方发布的信息,Claude Opus 4.6在多个专业评测基准上取得了领先成绩:
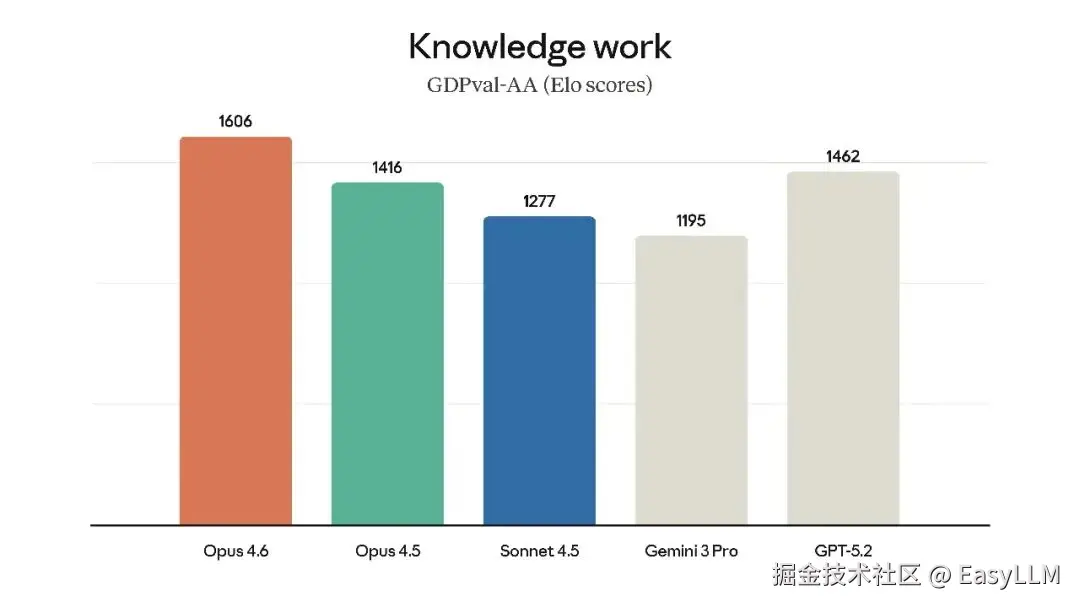
3.1 知识工作能力
在GDPval-AA评测(由Artificial Analysis独立运行,评估金融、法律等领域的高价值知识工作任务)中,Opus 4.6超越了业界第二名OpenAI的GPT-5.2约144 Elo分,超越其前代产品Claude Opus 4.5达190 Elo分。官方表示,这意味着Claude Opus 4.6在该评测中击败GPT-5.2的概率约为70%。
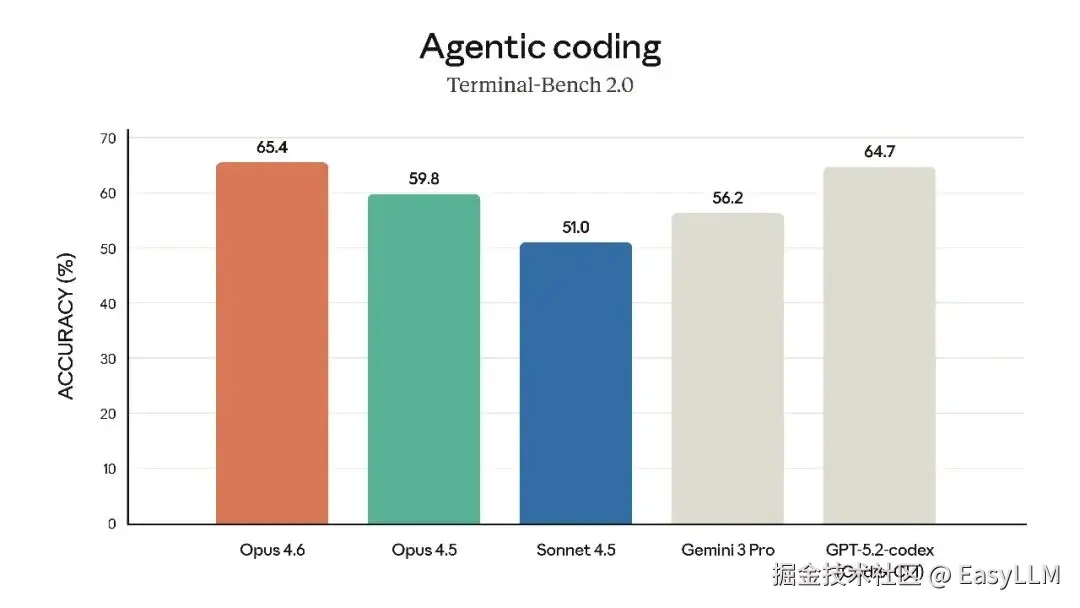
3.2 智能体编程能力
在智能体编程评测Terminal-Bench 2.0上,Opus 4.6取得了业界最高分,展现了在真实世界智能体编程和系统任务上的卓越表现。官方强调,新版本"规划更周密,能够更长时间地持续执行智能体任务,在大型代码库中运行更可靠,并具有更好的代码审查和调试能力来发现自身错误"。
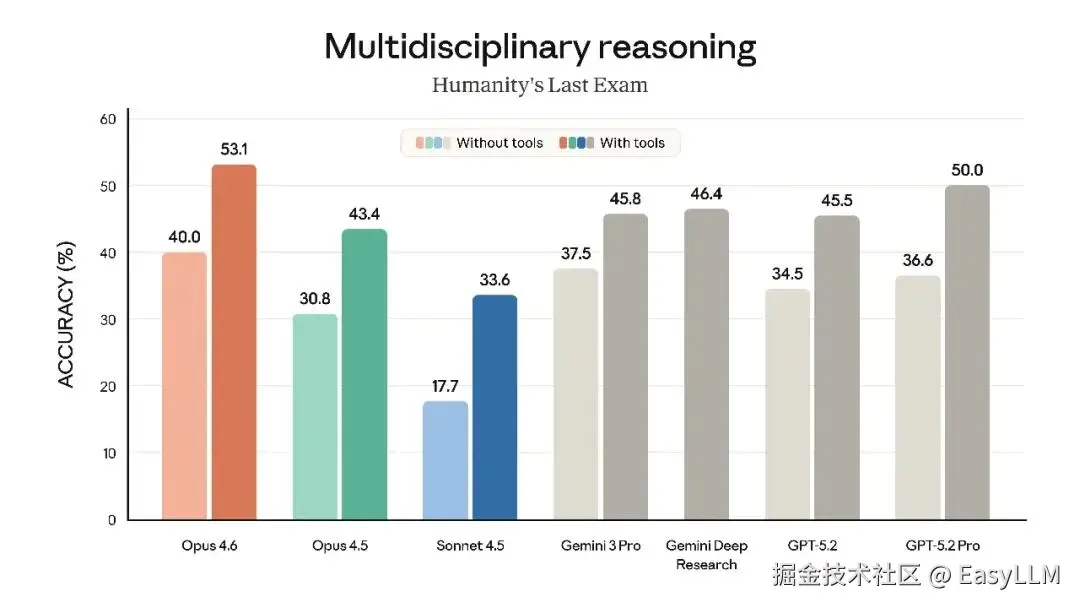
3.3 深度推理能力
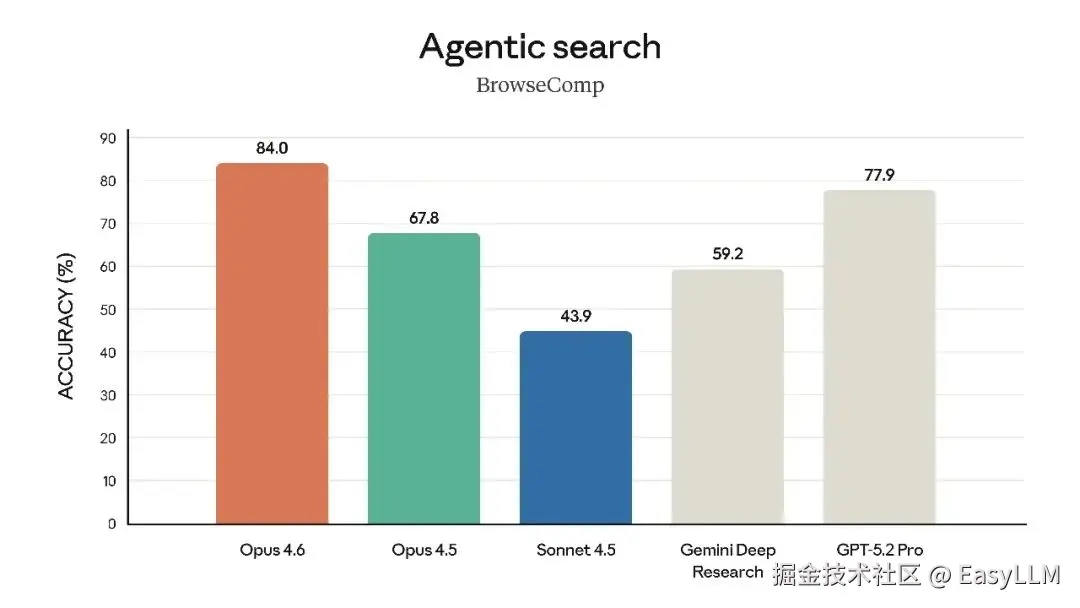
在Humanity's Last Exam(复杂多学科推理测试)中,Opus 4.6领先所有其他前沿模型。在BrowseComp(评估模型定位网络难查信息的能力)上也取得了最佳表现。
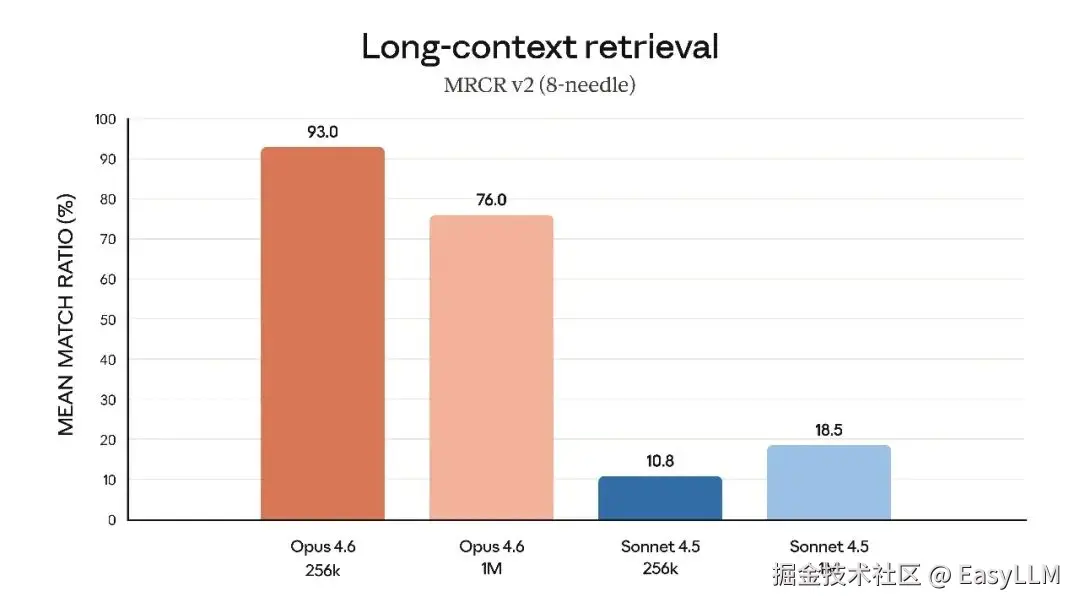
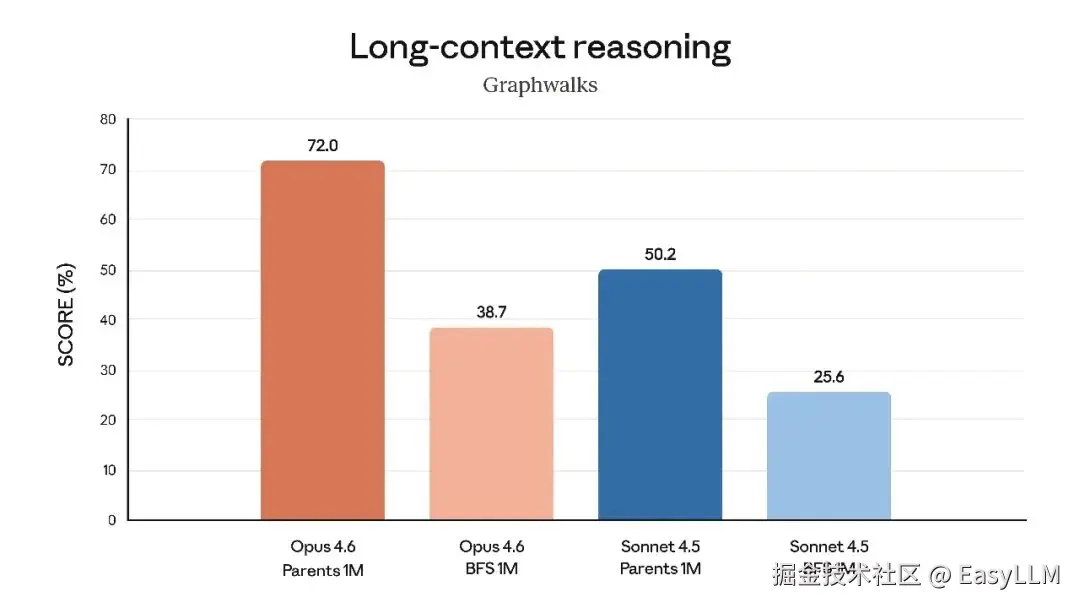
3.4 长上下文处理
官方特别强调了Opus 4.6在长上下文任务上的突破:在MRCR v2的100万token、8针变体测试中,Opus 4.6得分76%,而Sonnet 4.5仅为18.5%。这代表了"模型在保持峰值性能的同时能实际利用多少上下文的质的飞跃"。
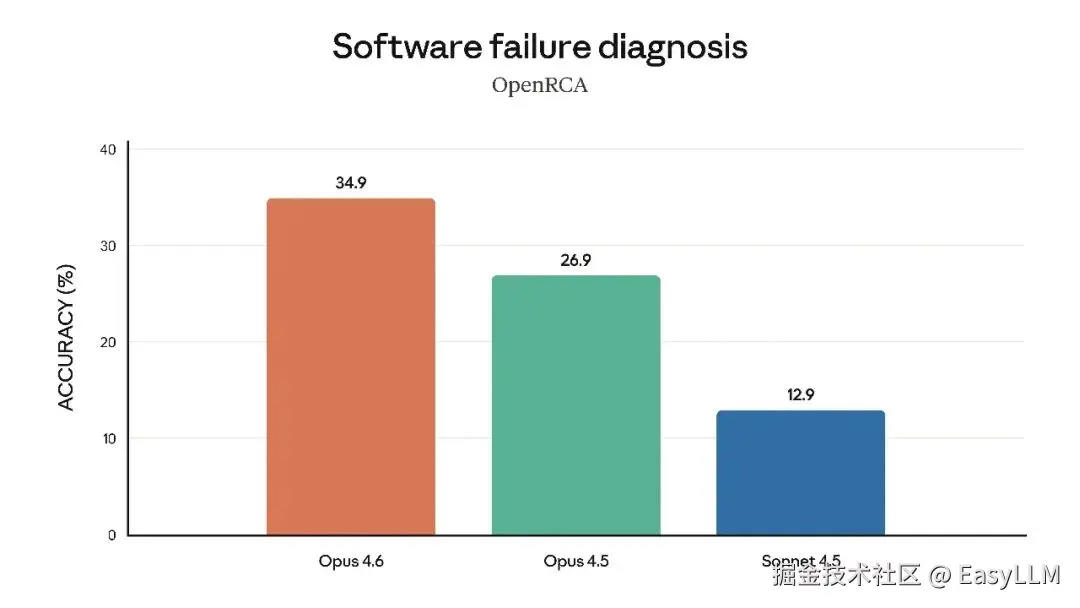
3.5 软件工程与专业领域能力
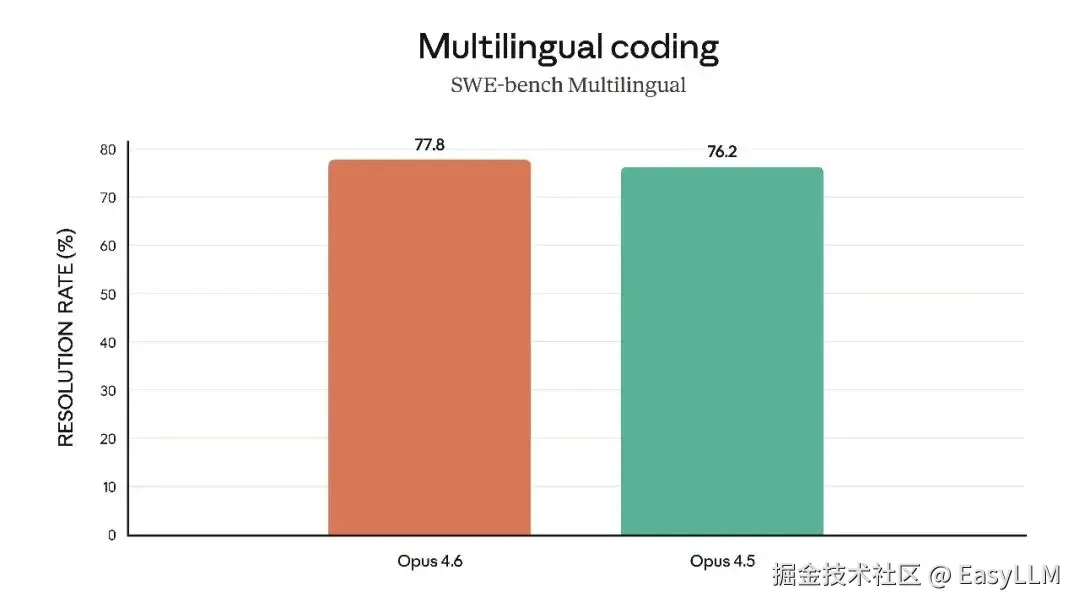
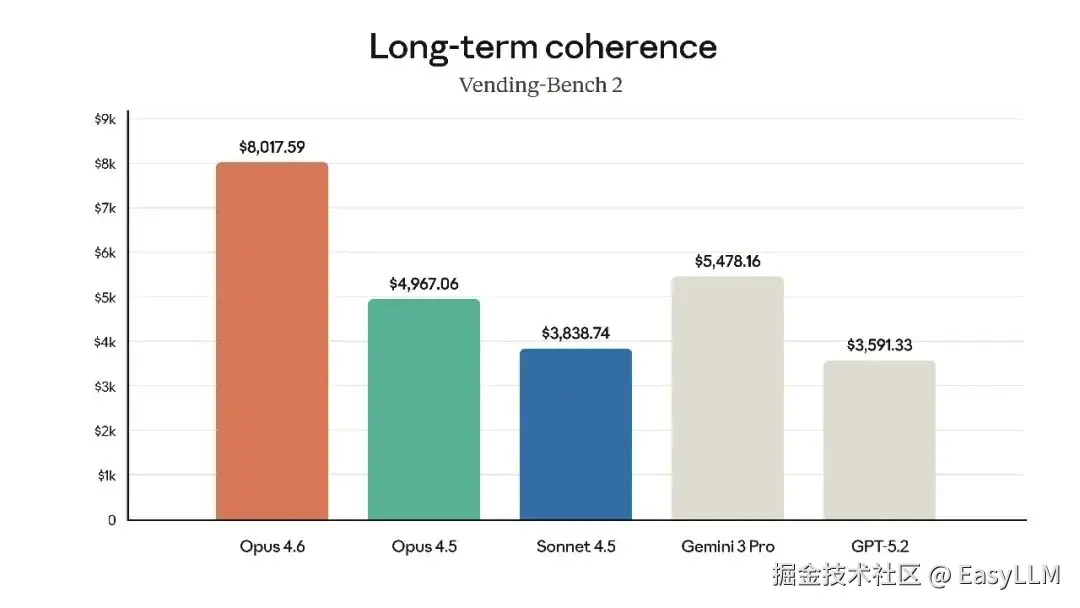
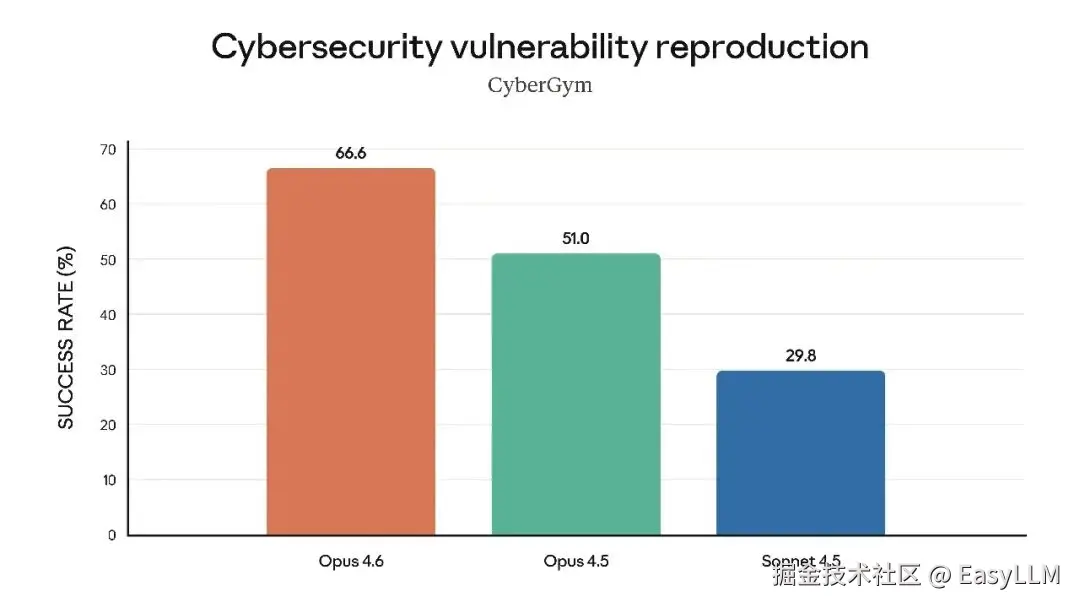
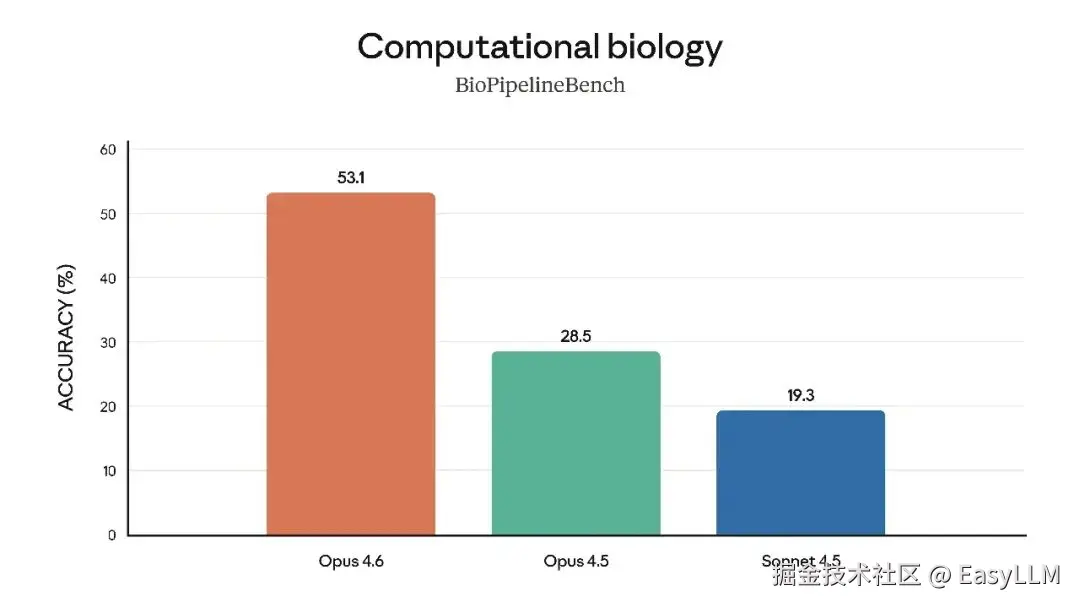
官方还展示了Claude Opus 4.6在多项专业基准上的表现,涵盖软件工程技能、多语言编程能力、长期连贯性、网络安全能力以及生命科学知识等维度:
官方表示,在根因分析方面,Opus 4.6擅长诊断复杂软件故障;在多语言编程方面,能够跨编程语言解决软件工程问题;在长期连贯性测试Vending-Bench 2中,Opus 4.6比Opus 4.5多赚取3,050.53美元,展现了长时间保持专注的能力;在网络安全方面,Opus 4.6在代码库中发现真实漏洞的能力优于其他所有模型;在生命科学领域,Opus 4.6在计算生物学、结构生物学、有机化学和系统发育学测试中的表现几乎是Opus 4.5的2倍。
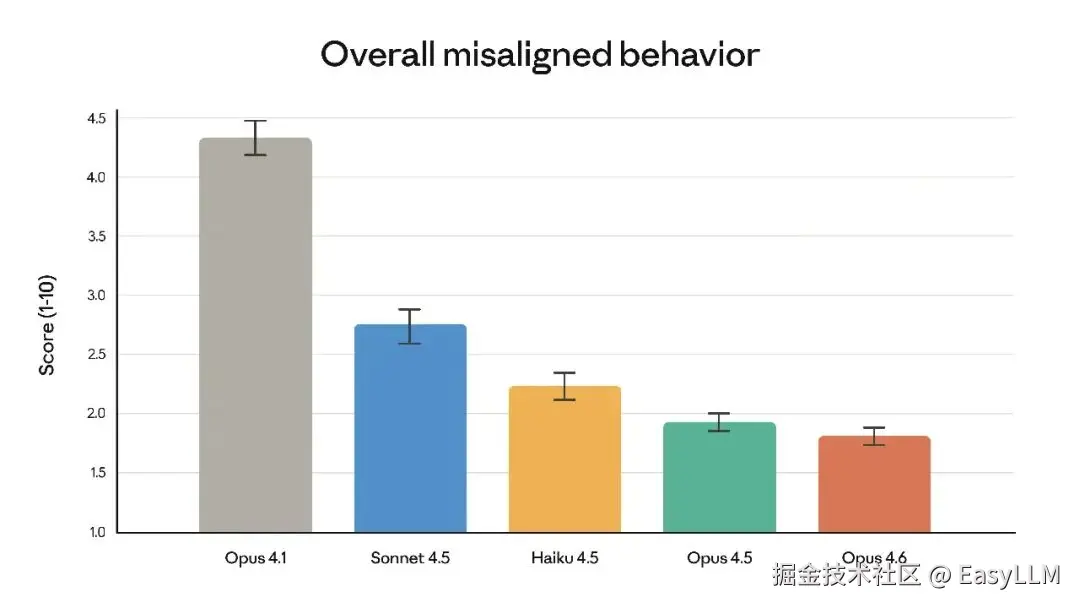
3.6 安全性评估
官方系统卡显示,Opus 4.6的整体安全性与此前最对齐的前沿模型Claude Opus 4.5持平或更优,在欺骗、谄媚、助长用户妄想、配合滥用等方面的错误行为率较低。同时,Opus 4.6的过度拒绝率是近期Claude模型中最低的。
目前所有大模型评测文章在公众号:大模型评测及优化NoneLinear

