为什么需要KVCache?
本blog主要介绍大模型推理中 KV Cache 的作用。先通过模拟自回归生成过程,说明模型是如何逐步生成文本的;随后进一步解释 KV Cache 为什么被提出。
1. 大模型生成内容的过程
KVCache一般只存在于含有Decoder的模型中,下面模拟会简化一些内容
1.1 规定符号
假定词表大小vocab_size=6,隐藏层维度d_model=5
词表W:
embedding矩阵E:
E∈R6×5=x00x10x20x30x40x50x01x11x21x31x41x51x02x12x22x32x42x52x03x13x23x33x43x53x04x14x24x34x44x54=[x0,x1,x2,x3,x4,x5]
1.2 生成过程
输入: 我爱学
模型预期输出: 习!
下面我们来具体分析模型是怎么生成习!
- 模型通过词表
W,将输入文字转换为token_ids=[[0, 1, 2]],token_ids.shape=(1,3)=(batch_size, seq_len)
- 模型通过词嵌入层embedding矩阵
E,将token_ids转换为词向量表示,e=begin{bmatrix}begin{bmatrix}x_0 & x_1 & x_2end{bmatrix}end{bmatrix},e.shape=(1,3,5)=(batch_size, seq_len, d_model)
- 接下来需要加上位置编码,但是我们省略这个过程
- 经过Casual Self-Attention(Masked Self-Attention)
- 最后经过Linear+SoftMax进行采样
1.2.1 Casual Self-Attention
在模拟的这个注意力机制中,我们当单头注意力进行模拟
输入: 矩阵e=begin{bmatrix}begin{bmatrix}x_0 & x_1 & x_2end{bmatrix}end{bmatrix},e.shape=(1,3,5)
约定符号:
| W_Q | W_K | W_V |
|---|
| 模拟中的形状 | (5,2) | (5,2) | (5,2) |
| 形式化的形状 | (d_{model},d_q) | (d_{model},d_q) | (d_{model},d_v) |
将矩阵e分别通过W_Q,W_K,W_V线性变换得到Q,K,V矩阵,Q.shape=(3,2),K.shape=(3,2),V.shape=(3,2)
再通过公式SoftMax(Masked(QK^T))V计算得分
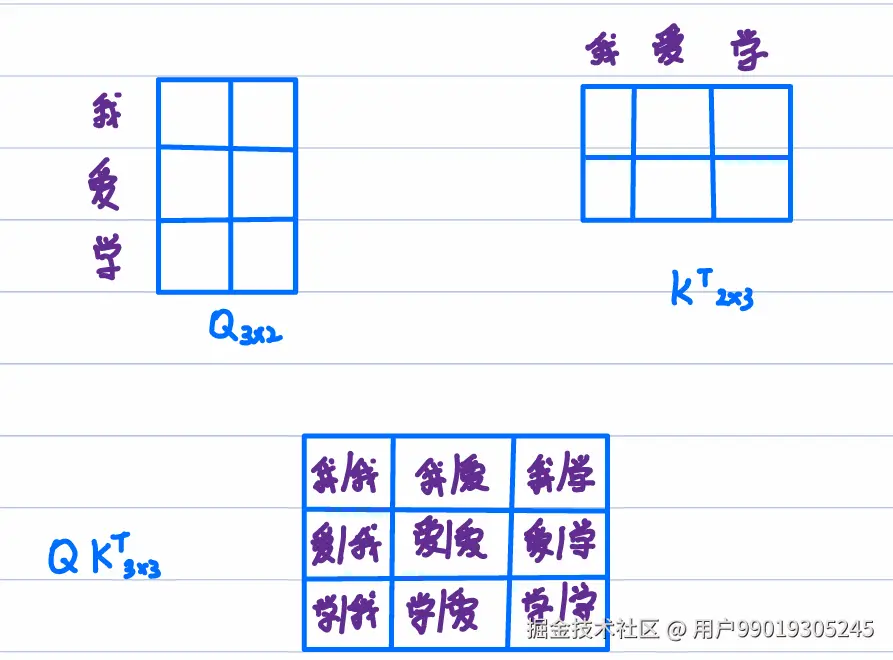
这里的我/我表示两个token的相关性Q[我]*K[我]
QKT=y00y10y20y01y11y21y02y12y22
Masked(QKT)=y00y10y20−∞y11y21−∞−∞y22
P=SoftMax(Masked(QKT))=p00p10p200p11p2100p22=p0p1p2
将V分块写为V=[v_0, v_1]
最终结果:
A=PV=SoftMax(Masked(QKT))V=p0v0p1v0p2v0p0v1p1v1p2v1
1.2.2 Final Linear + SoftMax采样
输入: 经过Casual Attention后矩阵A,A.shape=(3,2)
此时A无法与E.T进行相乘,所以需要先给A做一次线性变换W_O,W_O.shape=(2,5)
矩阵logitis=AW_OE^T,logits.shape=(6,6)
取logits最后一行进行采样,即SoftMax(logitis[-1]),假定结果为[0.1, 0.1, 0.1, 0.4, 0.1, 0.2],概率最高的为index=3,为习
自回归: 将习加入输入,得到我爱学习,将这个句子重新作为输入,重复上面的推理过程,再得到输出 !
2. KVCache
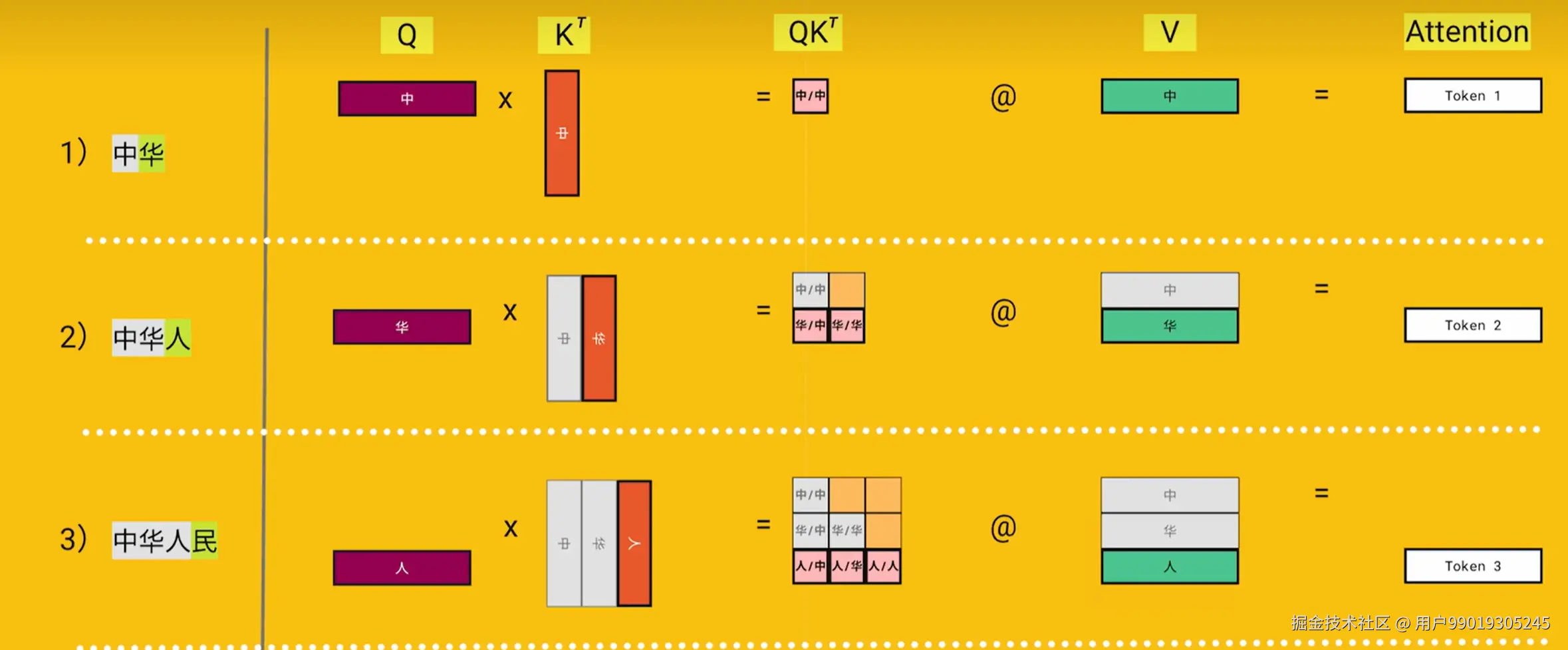
我们重新回顾上面推理过程:
输入1: 我爱学
通过一系列过程,最后采样得到习,将习加入输入
输入2: 我爱学习
通过一系列过程,最后采样得到 ! ,将!加入输入,直到最后采样到或者满足其它条件,才终止采样
显然两次输入存在相同的前缀我爱学,那么在我们进行第二次推理时,能否利用第一次推理过程中的部分内容呢,从上面的推理过程可以知道两次推理的相同前缀的K,V矩阵是完全相同的(甚至Q矩阵也是相同的,但是之前的Q矩阵并没有再利用的价值,所以不需要再进行缓存)
3. 参考资料
The Illustrated Transformer
【8】KV Cache 原理讲解


