



职业杀手
26.53M · 2026-03-25

Python 的切片表示法
python中访问列表的方式超乎想象的方便. 基于它的 slice 我们可以很容易的获取我们需要的列表元素
对于一个包含六个元素的列表, Python 的索引用于枚举元素, 切片用于枚举元素之间的间隔
# @description: list slice notation
def slice_test():
a = ["a", "b", "c", "d", "e", "f"]
print(
f"Index from front(): [{a[0]}, {a[1]}, {a[2]}, {a[3]}, {a[4]}, {a[5]}]")
print(
f"Index from rear(): [{a[-6]}, {a[-5]}, {a[-4]}, {a[-3]}, {a[-2]}, {a[-1]}]")
print(f"{"-" * 10} slice from front {"-" * 10}")
print(f"a[1:] = {a[1:]}") # [b, c, d, e, f]
print(f"a[:1] = {a[:1]}") # [a]
print(f"a[::] = {a[::]}") # [a, b, c, d, e, f]
print(f"a[1:4] = {a[1:4]}") # [b, c, d]
print(f"{"-" * 10} slice from rear {"-" * 10}")
print(f"a[-1:] = {a[-1:]}") # [f]
print(f"a[:-1] = {a[:-1]}") # [a, b, c, d, e]
print(f"a[::] = {a[::]}") # [a, b, c, d, e, f]
print(f"a[-5:-1] = {a[-5:-1]}") # [b, c, d, e]
if __name__ == "__main__":
slice_test()
我们可能会发现有些对象居然可以直接使用 for 语句
for element in [1, 2, 3]:
print(element)
for element in (1, 2, 3):
print(element)
for key in {'one':1, 'two':2}:
print(key)
for char in "123":
print(char)
for line in open("myfile.txt"):
print(line, end='')
这种访问风格清晰、简洁又方便.
迭代器的使用非常普遍并使得 Python 成为一个统一的整体, 所以想要学好python, iterator 是我们必须要掌握的一个知识
for循环的幕后, 会对in的对象调用其iter()方法, 他要求该方法返回一个 定义了 __next__方法的迭代器对象. 然后for loop会基于该对象, 调用__next__方法来逐一的访问容器的元素.
当元素用尽时, __next__() 将引发 StopIteration 异常来通知终止 for 循环
例如
class A:
"""test class"""
def __init__(self, lst):
self.lst = lst
self._index = 0
def __iter__(self):
return self
def __next__(self):
if self._index >= len(self.lst):
raise StopIteration
tmp = self._index
self._index = self._index + 1
return self.lst[tmp]
if __name__ == "__main__":
a = A([1, 2, 3])
for i in a:
print(i)
该如何理解 iterator & iterable?
__next__方法, 来获取数据iterator对象, 所以他需要提供__iter__方法, 该方法用于获取iterator对象docs.python.org/3/reference…
对于构造 list, set 或者 dictionary, python提供了一种名为"displays"的特殊语法. 他们有如下的2种形式
推导式的语法规则如下
comprehension ::= assignment_expression comp_for
comp_for ::= ["async"] "for" target_list "in" or_test [comp_iter]
comp_iter ::= comp_for | comp_if
comp_if ::= "if" or_test [comp_iter]
推导式表示一个表达式后面跟上一个for 语句即可, 并可以包含零个或多个 for 或 if 子句. 在这种情况下, 新容器中的元素是通过将每个 for 或 if 子句视为一个嵌套的代码块, 从左到右依次嵌套执行, 并在每次到达最内层的代码块时计算该表达式来生成的
最左侧 for 中的可迭代表达式是在外部作用域中直接求值的, 然后作为参数传递给后续的for / if语句.
注意构造的是list, set, dic 取决于我们使用的是什么类型的推导式
列表显示是一个用方括号括起来的可能为空的表达式系列
list_display ::= "[" comprehension"]"
[]显示会产生一个新的列表对象, 其内容通过一系列表达式或一个推导式来指定. 当提供一个推导式时, 列表会根据推导式所产生的结果元素进行构建, 相当于把推导式生成的结果, 一个一个的放入列表对象中
例如
def list_comprehension():
"""列表推导式的测试"""
lst = [1, 2, 3, 4]
squares = [i ** 2 for i in lst]
print(squares)
列表推导式中的初始表达式可以是任何表达式, 甚至可以是另一个列表推导式
内部的列表推导式是在它之后的 for 的上下文中被求值的
初始表达式作为一个整体在后续的for子句中进行处理
def example03():
matrix = [
[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12],
]
# 我们尝试进行行列转换
res = []
tmp = []
for i in range(4):
for it in matrix:
tmp.append(it[i])
res.append(tuple(tmp))
tmp.clear()
print(res)
res.clear()
# 通过列表推导式进行处理
# 内部的列表推导式是在它之后的 for 的上下文中被求值的
res = [[item[i] for item in matrix] for i in range(4)]
print(res)
res = list(zip(*matrix))
集合显示是用花括号标明的, 与字典显示的区别在于没有冒号分隔的键和值
def set_comprehension():
"""集合推导式的测试"""
# set会去重
s = {1, 2, 3, 4, 4, 5, 6}
squares = [i ** 2 for i in s]
print(squares)
字典显示是一个用花括号括起来的可能为空的字典条目(键/值对)
def dict_comprehension():
"""字典推导式"""
d = {"name": "alice", "age": 28}
name_info = {k: v for k, v in d.items() if k == "name"}
print(name_info)
# 将两个列表合并为字典
keys = ['孙燕姿', '周杰伦', '方大同']
values = ["我怀念的", "回到过去", "Love Song"]
songs = {name: song for name, song in zip(keys, values)}
for item in songs.items():
print(item)
# 二维字典推导式
matrix = {
row: {col: row * col for col in range( 1, 6)}
for row in range(3)
}
for item in matrix.items():
print(item)
"""
输出
(0, {1: 0, 2: 0, 3: 0, 4: 0, 5: 0})
(1, {1: 1, 2: 2, 3: 3, 4: 4, 5: 5})
(2, {1: 2, 2: 4, 3: 6, 4: 8, 5: 10})
"""
初识求值的表达式总是会放在后续表达式中进行执行.
也常用这些处理
类别标签编码
def print_dict(src: dict[str, str]):
"""key对齐的方式打印字典数据"""
max_len = max(len(k) for k in src.keys())
print(max_len)
for k, v in src.items():
print(f"{k.rjust(max_len, ' ')}: {v}")
def dict_comperhension_demo():
"""类别标签编码小案例"""
labels = ['cat', 'dog', 'bird', 'cat', 'bird']
unique_labels = sorted(set(labels))
# 获取label对应的编码, 这里以索引为例
label_to_id = {
label: id for id, label in enumerate(unique_labels)
}
print_dict(label_to_id)
# 对labels 进行encode
encoded = [label_to_id[item] for item in labels]
print(encoded)
"""
输出
bird: 0
cat: 1
dog: 2
[1, 2, 0, 1, 0]
"""
在 python 的世界装饰器本质上是一个函数,它接收一个函数作为参数,并返回一个新的函数。
而装饰器的核心作用:在不修改原函数代码的情况下,为函数添加额外的功能。
我们可以认为它是一种函数调用的语法糖,就像这样
@decorator
def func():
pass
# 等价于
func = decorator(func)
我们有时也可能看见这样的写法
@decorator() # 注意,在装饰器后面加上了 ()
def func():
pass
# 等价于
res = decorator()
func = res(func)
因为在Python中,函数可以像普通变量一样被传递和使用。这也是我们有时说函数是“一等公民”
def my_decorator(func):
def wrapper(*args, **kwargs): # 接收任意参数
print(f"调用函数: {func.__name__}")
print(f"参数: args={args}, kwargs={kwargs}")
result = func(*args, **kwargs) # 调用原函数并获取返回值
print(f"返回值: {result}")
return result
return wrapper
@my_decorator # 等同于 add = my_decorator(add)
def add(x, y):
return x + y
result = add(3, 5)
print(add.__name__) # 输出:wrapper
我们这里定义了一个装饰器,这个装饰器的功能就是在函数调用的时候,进行一些日志的输出,如果我们愿意,也可以将这里的日志输出改为对应的一些资源初始化或者清理的操作
但这里有个问题,我们被装饰函数的元数据发生了改变,也就是这行程序的输出有些不如预期,当然我们明白为何这样 print(add.__name__) # 输出:wrapper
而为了避免这个问题,我们可以使用一些 python 官方提供的函数工具
关于 functools 的更多说明,可以参考:docs.python.org/3/library/f…
装饰器的 PEP 的提出:peps.python.org/pep-0318/
functools.wraps装饰器的使用
from functools import wraps
def my_decorator(func):
@wraps(func) # 这是涉及函数的多次嵌套:首先是 wraps(func) 进行调用,然后返回了一个函数对象,然后该函数对象对我们这里定义的 wrapper 函数进行装饰,所以wrapper最后变成了被装饰后的函数。
def wrapper(*args, **kwargs):
print(f"调用函数: {func.__name__}")
print(f"参数: args={args}, kwargs={kwargs}")
result = func(*args, **kwargs) # 调用原函数并获取返回值
print(f"返回值: {result}")
return result
return wrapper
@my_decorator
def add(x, y):
return x + y
add(2, 3)
print(add.__name__) # 输出 add
为何需要该工具?
想象一些场景:
所以比较 pythonic 的做法是始终在装饰器中使用 @wraps(func)
functools.wraps 的源码分析
def wraps(wrapped,
assigned = WRAPPER_ASSIGNMENTS,
updated = WRAPPER_UPDATES):
"""Decorator factory to apply update_wrapper() to a wrapper function
Returns a decorator that invokes update_wrapper() with the decorated
function as the wrapper argument and the arguments to wraps() as the
remaining arguments. Default arguments are as for update_wrapper().
This is a convenience function to simplify applying partial() to
update_wrapper().
wraps 本质上是一个 装饰器工厂
"""
return partial(update_wrapper, wrapped=wrapped,
assigned=assigned, updated=updated)
参数 说明
# 需要从原函数直接复制的属性
WRAPPER_ASSIGNMENTS = ('__module__', '__name__', '__qualname__', '__doc__',
'__annotations__', '__type_params__')
# 需要更新 / 合并 的属性
WRAPPER_UPDATES = ('__dict__',)
更新函数 update_wrapper
def update_wrapper(wrapper,
wrapped,
assigned = WRAPPER_ASSIGNMENTS,
updated = WRAPPER_UPDATES):
"""Update a wrapper function to look like the wrapped function
wrapper is the function to be updated
wrapped is the original function
assigned is a tuple naming the attributes assigned directly
from the wrapped function to the wrapper function (defaults to
functools.WRAPPER_ASSIGNMENTS)
updated is a tuple naming the attributes of the wrapper that
are updated with the corresponding attribute from the wrapped
function (defaults to functools.WRAPPER_UPDATES)
"""
# 遍历需要复制属性
for attr in assigned:
try:
value = getattr(wrapped, attr) # 从原函数获取属性
except AttributeError:
pass # 如果原函数该属性不存在,跳过
else:
setattr(wrapper, attr, value) # 设置到包装器函数
for attr in updated: # 更新 __dict__
getattr(wrapper, attr).update(getattr(wrapped, attr, {}))
# 设置 __wrapped__ 属性(指向原函数),这样我们可以通过 func.__wrapped__ 访问原函数
wrapper.__wrapped__ = wrapped
return wrapper
到这里,我们大致可以分析 functools.wraps第一步的操作了
@wraps(func)
def wrapper(*args, **kwargs):
...
# 获取wraps函数的返回值
tmp = partial(update_wrapper, wrapped=func, assigned=assigned, updated=updated)
# 通过该对象对我们自定义的wrapper进行装饰
wrapper = tmp(wrapper) # 相当于调用 partial 类的 __call__ 方法
# partial 类的 __call__ 方法 会返回 update_wrapper 执行结果
wrapper = update_wrapper(wrapper, func, WRAPPER_ASSIGNMENTS, WRAPPER_UPDATES)
# 于是我们的wrapper的元数据就被指向到了 func(wrapped) 的内容中了
partial 是什么?它是一个类,但是实现了 __call__所以可以当成函数,这里可以当成是一个 纯函数
# Purely functional, no descriptor behaviour
class partial:
"""New function with partial application of the given arguments
and keywords.
"""
# 限制实例只能拥有这些属性,不使用默认的 __dict__
# 如果不使用 __slots__,则每个实例都有一个 __dict__ 字典,占用更多内存
__slots__ = "func", "args", "keywords", "__dict__", "__weakref__"
# func一定要注意,它是我们之前看到的update_wrapper函数对象,该对象负责对原有的add这样的函数的元数据进行维护
def __new__(cls, func, /, *args, **keywords):
if not callable(func):
raise TypeError("the first argument must be callable")
if hasattr(func, "func"): # 如果 func 本身就是一个 partial 对象,合并它的参数
args = func.args + args
keywords = {**func.keywords, **keywords}
func = func.func
self = super(partial, cls).__new__(cls)
self.func = func # 维护的原始函数
self.args = args # 维护的函数参数
self.keywords = keywords
return self
def __call__(self, /, *args, **keywords):
keywords = {**self.keywords, **keywords}
return self.func(*self.args, *args, **keywords) # 调用的时候,展开参数
...
__class_getitem__ = classmethod(GenericAlias)
关于 __slots__的功能
# 不使用 __slots__ 的普通类
class NormalClass:
pass
# 每个实例都有一个 __dict__ 字典,占用更多内存
obj = NormalClass()
obj.a = 1
obj.b = 2 # 可以随意添加属性
# 使用 __slots__ 的类
class OptimizedClass:
__slots__ = ('a', 'b')
obj = OptimizedClass()
obj.a = 1
obj.b = 2
# obj.c = 3 # 报错!无法添加未声明的属性
关于__new__的功能
from functools import partial
def add(a, b, c, d):
return a + b + c + d
# 链式 partial
step1 = partial(add, 1) # 绑定 a=1
step2 = partial(step1, 2) # 绑定 b=2
step3 = partial(step2, 3) # 绑定 c=3
# 不做优化的话,会形成嵌套调用:
# step3(4) -> step2(3, 4) -> step1(2, 3, 4) -> add(1, 2, 3, 4)
# 但通过 __new__ 的优化,直接展平为:
# step3.func = add (原始函数)
# step3.args = (1, 2, 3) (所有绑定的参数) 因为会判断当前的partial的参数是不是具有func属性,有了的话,直接参数合并,避免把原先的func进行赋值传递
# step3(4) -> add(1, 2, 3, 4) 只调用一次!
这里 python 的官方使用 partial 作为返回值类型,事实上我们可以不用返回该类型也可以实现
def my_wraps(func): # 接受 wrapped
def decorator(wrapper): # 接受wrapper
"""篡改wrapper的元数据只想"""
wrapper.__name__ = func.__name__
wrapper.__doc__ = func.__doc__
wrapper.__module__ = func.__module__
wrapper.__wrapped__ = func
return wrapper
return decorator
def my_decorator(func):
@my_wraps(func)
def wrapper(*args, **kwargs):
print(f"调用函数: {func.__name__}")
print(f"参数: args={args}, kwargs={kwargs}")
result = func(*args, **kwargs) # 调用原函数并获取返回值
print(f"返回值: {result}")
return result
return wrapper
@my_decorator
def add(x, y):
return x + y
add(1, 2)
print(add.__name__) # add
我们这里 my_wraps 方法内部的 decorator就可以等同于之前functools.wraps的返回的 partial
可以发现我们自定义的程序可能比官方源码更加容易理解一下,但是这个程序却不如官方的程序那么通用,存在如下的一些缺陷
# 自定义的实现
@my_wraps(func) # 固定复制 __name__, __doc__, __module__, __wrapped__
# 官方实现:根据需求设置
@wraps(func, assigned=('__name__',), updated=()) # 只复制 __name__
不过这里也可以看出,其实 wraps 中的核心在于 update_wrapper 的功能,而不是 partial,但 partial 的好处在于它维护了 wrapped 的引用。
我们知道functools.wraps的底层通过参数控制要拷贝的初始化参数,那我们其实可以自己对它进行封装,改造出我们需要的装饰器,例如API路由装饰器
# 自定义wraps:只复制必要的元数据,忽略其他
minimal_wraps = lambda f: wraps(f, assigned=('__name__',), updated=())
def api_route(path):
"""API路由装饰器 - 只需要保留函数名用于日志"""
def decorator(func):
@minimal_wraps(func)
def wrapper(*args, **kwargs):
return func(*args, **kwargs)
wrapper.route_path = path # 添加路由信息
return wrapper
return decorator
@api_route('/users')
def get_users():
"""获取用户列表"""
return ["Alice", "Bob"]
实际开发中,除了 wraps 之外,我们还经常会使用 lru_cache 这个装饰器
什么是 LRU Cache?
LRU (Least Recently Used) 是一种缓存淘汰策略:
其次通过它我们还可以保证我们使用的是单例对象,例如
import logging
from functools import lru_cache
from core.config import get_settings
from redis.asyncio import Redis
logger = logging.getLogger(__name__)
class RedisClient:
def __init__(self):
self._settings = get_settings()
self._client: Redis | None = None
async def init(self) -> None:
if self._client:
logger.warning("Redis client already initialized")
return
try:
self._client = Redis(
host=self._settings.redis_host,
port=self._settings.redis_port,
db=self._settings.redis_db,
password=self._settings.redis_password)
await self._client.ping()
logger.debug("Redis client initialized")
except Exception as e:
logger.error("Redis client initialization failed", e)
raise e
async def shutdown(self):
if self._client:
await self._client.close()
self._client = None
logger.debug("Redis client closed")
# clean cache
get_redis_client.cache_clear()
@property
def client(self) -> Redis:
if self._client is None:
raise AttributeError("Redis client not initialized")
return self._client
@lru_cache
def get_redis_client() -> RedisClient:
return RedisClient()
这里每次调用 get_redis_client 都会从缓存中提供。
空说有点抽象,我们看点实际的代码,看看 lru_cache 具体是怎么完成的
在看具体代码之前,我们先尝试自己定义一个 lru_cache
import functools
import inspect
def make_key(args, func):
# 如果函数是空参,可以使用函数名作为key
if len(args) == 0:
module_obj = inspect.getmodule(func)
module_file_path = module_obj.__file__
module_func_key = module_file_path + "." + func.__name__
return hash(module_func_key)
return hash(args)
def simple_lru_cache(maxsize=128): # 定义该装饰器接收的参数,表示当前这个内存中允许使用的最大缓存数量
# 如果第一个参数是函数,说明是不带括号的用法
if callable(maxsize): # 这个行为是为了避免用户使用 @simple_lru_cache 方式进行调用
func = maxsize
maxsize = 128
# 直接返回装饰后的函数
return simple_lru_cache()(func)
def decorator(func):
"""简化版 LRU 缓存(仅支持位置参数)"""
cache = {} # 缓存的字典
order = [] # 访问的顺序列表
@functools.wraps(func)
def wrapper(*args):
# 判断传递的这个参数之前有没有调用过
if make_key(args, func) in cache:
order.remove(args)
order.insert(0, args) # 在头部插入该参数,来实现缓存更新,表示最新使用过了这个数据
return cache[make_key(args, func)] # 缓存命中
# 之前没有缓存过数据
result = func(*args)
cache[make_key(args, func)] = result
order.insert(0, args)
# 缓存满了,删除最旧的
if len(order) > maxsize:
oldest = order.pop(len(order) - 1)
del cache[oldest]
return result
return wrapper
return decorator
@simple_lru_cache
def foo():
print("foo")
return 1
@simple_lru_cache
def bar():
print("bar")
return 2
foo()
foo()
bar()
bar()
foo
bar
functools.lru_cache 的具体实现。
def lru_cache(maxsize=128, typed=False):
"""LRU 缓存装饰器
参数:
maxsize: 最大缓存大小,None 表示无限制
typed: True 时,不同类型的参数会分别缓存(如 3 和 3.0)
"""
if isinstance(maxsize, int):
if maxsize < 0:
maxsize = 0
# @lru_cache (不带括号,直接装饰函数,此时maxsize本质上是我们被装饰的函数对象)
elif callable(maxsize) and isinstance(typed, bool):
user_function = maxsize
maxsize = 128
# 获取装饰器函数,后续真正执行的是该函数
wrapper = _lru_cache_wrapper(user_function, maxsize, typed, _CacheInfo)
wrapper.cache_parameters = lambda : {'maxsize': maxsize, 'typed': typed}
# 更新user_function的元信息,避免因为装饰丢失元信息
return update_wrapper(wrapper, user_function)
# maxsize 参数错误
elif maxsize is not None:
raise TypeError('Expected first argument to be an integer, a callable, or None')
# 装饰器工厂,常规使用 即 @lru_cache() 的方式
def decorating_function(user_function):
wrapper = _lru_cache_wrapper(user_function, maxsize, typed, _CacheInfo)
wrapper.cache_parameters = lambda : {'maxsize': maxsize, 'typed': typed}
return update_wrapper(wrapper, user_function)
return decorating_function
我们可以重点关注一下 情况2 @lru_cache这种调用,基本覆盖所有的 lru_cache 的场景。
当这样装饰函数之后,被装饰的函数 wrapped / user_function就变成了 update_wrapper()返回结果,后续的调用,基本都是在调用 wrapper该函数
lru_cache 的重点也就是该wrapper函数,即 _lru_cache_wrapper
我们这里只关注 maxsize > 0 的状态
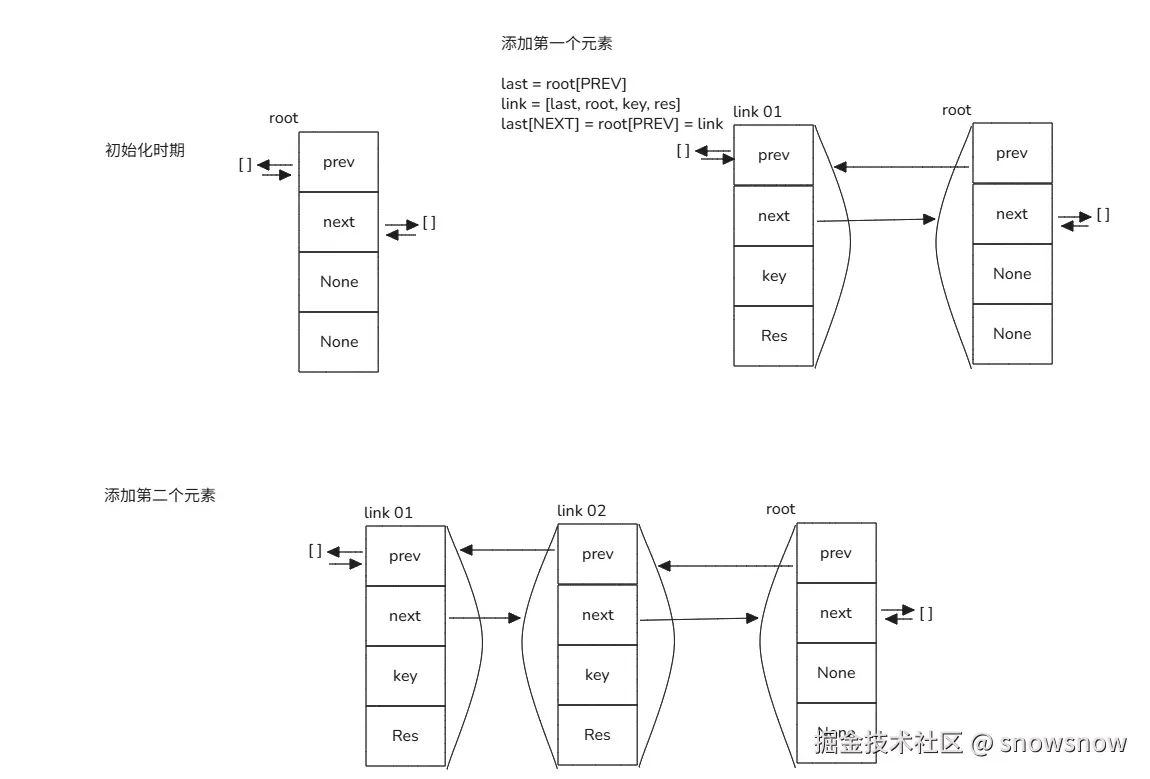
def _lru_cache_wrapper(user_function, maxsize, typed, _CacheInfo):
sentinel = object() # unique object used to signal cache misses
make_key = _make_key # build a key from the function arguments
PREV, NEXT, KEY, RESULT = 0, 1, 2, 3 # 通过数组的形式完成链表,这里四个元素将构建链表的一个节点的所有属性
cache = {} # 该函数维护的所有缓存字典, 类型为 dict[str, (PREV, NEXT, KEY, RESULT)]
hits = misses = 0
full = False
cache_get = cache.get # 从字典中获取数据的方法
cache_len = cache.__len__ # get cache size without calling len()
lock = RLock() # 通过加锁来避免多线程情况下的数据竞争问题
root = [] # root of the circular doubly linked list
root[:] = [root, root, None, None] # 初始化链表,
...
else:
def wrapper(*args, **kwds):
# Size limited caching that tracks accesses by recency
nonlocal root, hits, misses, full
key = make_key(args, kwds, typed) # 生成缓存键
with lock: # 加锁,来保证线程安全
link = cache_get(key) # 从缓存中尝试获取数据,如果key不存在,返回None
if link is not None: # 缓存命中
# 接下来的操作将命中的缓存从最后位置移动到最先的位置
link_prev, link_next, _key, result = link
link_prev[NEXT] = link_next
link_next[PREV] = link_prev
last = root[PREV]
last[NEXT] = root[PREV] = link
link[PREV] = last
link[NEXT] = root
hits += 1
return result
misses += 1
result = user_function(*args, **kwds)
with lock:
if key in cache:
pass
elif full:
oldroot = root
oldroot[KEY] = key
oldroot[RESULT] = result
root = oldroot[NEXT]
oldkey = root[KEY]
oldresult = root[RESULT]
root[KEY] = root[RESULT] = None
del cache[oldkey]
cache[key] = oldroot
else:
last = root[PREV]
link = [last, root, key, result]
last[NEXT] = root[PREV] = cache[key] = link
full = (cache_len() >= maxsize)
return result
这里的切换流程
这个类还提供了 2 个辅助方法
def cache_info():
"""报告缓存统计信息"""
with lock:
return _CacheInfo(hits, misses, maxsize, cache_len())
def cache_clear():
"""清空缓存和统计"""
nonlocal hits, misses, full
with lock:
cache.clear()
root[:] = [root, root, None, None]
hits = misses = 0
full = False
所以再开始我们对单例进行 shutdown 的时候,总会调用 lru_cache 装饰的函数的 cache_clear来清空内存信息
其实这里说的类装饰器,本质上还是函数,只不过 python 的语法灵活,可以把类看成函数,其次借用 @这个语法糖
class CountCalls:
"""统计函数调用次数的类装饰器"""
def __init__(self, func):
functools.update_wrapper(self, func)
self.func = func
self.count = 0
def __call__(self, *args, **kwargs):
self.count += 1
print(f"调用次数: {self.count}")
return self.func(*args, **kwargs)
@CountCalls
def greet(name):
print(f"Hello, {name}!")
greet("Alice") # 调用次数: 1
greet("Bob") # 调用次数: 2
他这里就相当于初始化一个类对象,然后调用类的 __call__方法,但是要注意 func 在 __init__中传递的。
和模块一样, 类也支持 Python 动态特性: 在运行时创建, 创建后还可以修改
Python 的类也是对象, 这为导入和重命名提供了语义支持, 以及类型编程提供了可行
对象之间相互独立, 多个名称(甚至是多个作用域内的多个名称)可以绑定到同一对象
一定要注意 name 和 具体的数据对象他们是存在不同的. name使我们给这个数据对象起的一个标识而已
namespace: 是从名称到对象的映射.
现在, 大多数命名空间都使用 Python 的dict实现, 所以他可以简单的理解为就是一个通过dict实现的name和对象之间的关系对象.
但除非涉及到性能优化, 我们一般不会关注这方面的事情, 而且将来也可能会改变这种方式
关于namespace的具体示例有:
为何要强调 namespace 的说明, 因为 不同命名空间中的名称之间绝对没有关系
例如, 两个不同的模块(.py文件)都可以定义 maximize 函数, 且不会造成混淆. 用户使用函数时必须要在函数名前面加上模块名
内置名称的命名空间是在 Python 解释器启动时创建的, 永远不会被删除.
模块的全局命名空间(也就是模块中全局name与对象之间的关系)在读取模块定义时创建; 通常, 模块的命名空间也会持续到解释器退出
一个命名空间的 作用域 是 Python 代码中的一段文本区域, 从这个区域可直接访问该命名空间.
通俗理解就是, 我们在这个区域可以直接访问变量 / 函数 等这些name, 找到他们对应的对象(值 / 调用函数)
作用域虽然是被静态确定的, 但会被动态使用
而内置名称的namespace在builtins模块下, 例如在该namespace下, 我们有 False, True, None
"""
Module: quickstart.py
Description: 类的初识
Author: Falling Snow
Date: 2025-06-06
"""
# -*- coding: utf-8 -*-
def scopes_global_nonlocal_test():
"""global nonlocal 变量测试"""
def do_local():
spam = "local spam"
def do_nonlocal():
# 使用 nonlocal 需要在当前def的scope外部创建一个spam
nonlocal spam
spam = "nonlocal spam"
def do_global():
global spam
spam = "global spam"
spam = "test spam"
do_local()
print("After local assignment:", spam)
do_nonlocal()
print("After nonlocal assignment:", spam)
do_global()
print("After global assignment:", spam)
if __name__ == "__main__":
scopes_global_nonlocal_test()
print("In global scope: ", spam)

:::info nonlocal的赋值会改变我们的对于变量的绑定, 而global会修改模块层级的绑定
nonlocal会想当前作用域的外部进行寻找, 而global会在全局作用域中处理
:::
当进入类定义时, 将创建一个新的命名空间, 并将其用作局部作用域 --- 因此, 所有对局部变量的赋值都是在这个新命名空间之内
如果不支持继承, 语言特性就不值得称为"类". 派生类定义的语法如下所示
class DerivedClassName(BaseClassName):
<语句-1>
.
.
.
<语句-N>
类它也是一个对象, 他们有这样的关系
Python有两个内置函数可被用于继承机制:
isinstance()来检查一个实例的类型: isinstance(obj, int)仅会在obj.__class__ 为 int 或派生于 int 的类时为Trueissubclass() 来检查类的继承关系: issubclass(bool, int)为True, 因为bool是int的子类, 但是issubclass(float, int) 为 False, 因为 float 不是 int 的子类补充一下obj.__class__的概念:
python中每一个值都是一个对象, 而对于实例而言, 他们会保存其类型信息, 通过obj.__class__ 进行存储
class A():
pass
if __name__ == "__main__":
i = 233
print(i.__class__) # <class 'int'>
print(A().__class__) # <class '__main__.A'>
如果多继承了, 我们访问同名属性, 他会调用谁的呢?
class DerivedClassName(Base1, Base2, Base3):
pass
从父类所继承属性的操作是深度优先、从左到右的, 当层次结构存在重叠时不会在同一个类中搜索两次. 因此, 如果某个属性在 DerivedClassName 中找不到, 就会在 Base1 中搜索它, 然后(递归地)在 Base1 的基类中搜索, 如果在那里也找不到, 就将在 Base2 中搜索, 依此类推
那种仅限从一个对象内部访问的"私有"实例变量在 Python 中并不存在
但是, 大多数 Python 代码都遵循这样一个约定: 带有一个下划线的名称 (例如 _spam) 应该被当作是 API 的非公有部分 (无论它是函数、方法或是数据成员)
但这种行为终究只是约定, 如果我们真的希望使用一些私有的成员, python提供了一种较为脆弱的机制: name mangling 对的, 就像是c++中函数重载的机制一样, python会对双下划线的成员进行name mangling, 例如__spam 会被改为 _classname__spam
class Mapping:
def __init__(self, iterable):
self.items_list = []
self.__update(iterable)
def update(self, iterable):
for item in iterable:
self.items_list.append(item)
def __next__(self, index):
if index >= len(self.items_list):
raise StopIteration
return self.items_list[index]
def __iter__(self):
return iter(self.items_list)
__update = update # update 的副本, 但是该方法是私有的
class MappingSubclass(Mapping):
def update(self, keys, values): # 不会破坏Mapping的__init__中self.__update(iterable)这个逻辑, 还提供了update新的签名
for item in zip(keys, values):
self.items_list.append(item) # item is a Tuple(key, value)
if __name__ == "__main__":
ms = MappingSubclass([1, 2, 3])
print(', '.join(str(i) for i in ms))
ms.update([1, 2, 3], ['alice', 'bob', 'jude'])
print(', '.join(str(i) for i in ms))
ms.__update([1, 2, 3]) # AttributeError: 'MappingSubclass' object has no attribute '__update'. Did you mean: 'update'?
print(', '.join(str(i) for i in ms))
快速使用
from dataclasses import dataclass
@dataclass
class Employee:
name: str
dept: str
salary: int
当我们给类添加了@dataclass装饰器, 它用于自动为我们自定义的类添加生成一些 特殊方法 例如 __init__() 和 __repr__()。 它的初始描述见 PEP 557
他们具有如下的转换关系
from dataclasses import dataclass
@dataclass
class InventoryItem:
'''Class for keeping track of an item in inventory.'''
name: str
unit_price: float
quantity_on_hand: int = 0
def total_cost(self) -> float:
return self.unit_price * self.quantity_on_hand
@dataclass装饰器将向类添加这些内容
def __init__(self, name: str, unit_price: float, quantity_on_hand: int = 0) -> None:
self.name = name
self.unit_price = unit_price
self.quantity_on_hand = quantity_on_hand
def __repr__(self):
# <expression>!r 等同于 repr(<expression>)
return f'InventoryItem(name={self.name!r}, unit_price={self.unit_price!r}, quantity_on_hand={self.quantity_on_hand!r})'
def __eq__(self, other):
if other.__class__ is self.__class__:
return (self.name, self.unit_price, self.quantity_on_hand) == (other.name, other.unit_price, other.quantity_on_hand)
return NotImplemented
def __ne__(self, other):
if other.__class__ is self.__class__:
return (self.name, self.unit_price, self.quantity_on_hand) != (other.name, other.unit_price, other.quantity_on_hand)
return NotImplemented
def __lt__(self, other):
if other.__class__ is self.__class__:
return (self.name, self.unit_price, self.quantity_on_hand) < (other.name, other.unit_price, other.quantity_on_hand)
return NotImplemented
def __le__(self, other):
if other.__class__ is self.__class__:
return (self.name, self.unit_price, self.quantity_on_hand) <= (other.name, other.unit_price, other.quantity_on_hand)
return NotImplemented
def __gt__(self, other):
if other.__class__ is self.__class__:
return (self.name, self.unit_price, self.quantity_on_hand) > (other.name, other.unit_price, other.quantity_on_hand)
return NotImplemented
def __ge__(self, other):
if other.__class__ is self.__class__:
return (self.name, self.unit_price, self.quantity_on_hand) >= (other.name, other.unit_price, other.quantity_on_hand)
return NotImplemented
也就是我们基础的 __init__, __repr__, Rich_Comparsion method, 当然, 它允许我们重写一些方法
从这里, 我们也可以看出, 一般__repr__用于展示我们的这个实例的结构
概述: docs.python.org/zh-cn/3.13/…
具体: docs.python.org/zh-cn/3.13/…
def: 生成器 是一个用于创建迭代器的简单而强大的工具.
而Generator expression返回的对象的类型是一个 generator iterator. 注意这是一个iterator, 意味着它实现了.
生成器和迭代器总是一起讨论
我们所说的生成器(Generator)通常是指一个生成器的函数, 该函数会返回一个对象, 该对象通常称之为 Generator Iterator(生成器迭代器)
名词:
Generator很像是一个普通函数, 但是关键的地方在于, 他会在函数中使用yield表达式, 从而返回一个 Generator Iterator.
通过该Generator Iterator 我们进行for-loop 或者基于该对象的next()方法逐步的获取所有数据
测试
from collections.abc import Iterator, Generator
from builtins import list
def reverse(data):
""" 翻转数据 """
for i in range(len(data) - 1, -1, -1):
yield data[i]
def example01():
gi = reverse([11, 22, 33, 44])
print(isinstance(gi, (Iterator))) # True
print(type(gi)) # generator
# 它是一个 Iterator, 所以可以进行 for
for i in gi:
print(i)
可以用生成器来完成的任何功能同样可以通过基于类的迭代器来完成. 但生成器的写法更为紧凑, 因为它会自动创建 __iter__() 和 __next__() 方法
现在我们基于生成器 和 迭代器的方式, 实现我们的 读取文本行的功能. 但是对这个功能, 我们需要做出一些拓展
例如 # 开始的文本行不读取, 空行不读取
class ClearFileIterator:
"""基于迭代器的方式读取干净的文本行"""
def __init__(self: 'ClearFileIterator', file_path: str):
self.file_path = file_path
self.file = open(file_path, 'r', encoding='utf-8')
def __iter__(self):
return self
def __next__(self):
line = self.file.readline()
while line:
if (len(line.strip()) == 0) or line.startswith('#'):
# 表示内容为空行或者以 # 开始, 是注释, 跳过
line = self.file.readline()
continue
return line
# 表示内容读取完毕
self.file.close()
raise StopIteration
def clear_file_generator(file_path: str):
"""基于生成器的方式, 读取干净的文本行"""
with open(file_path, 'r', encoding='utf-8') as file:
line = file.readline()
while line:
if (len(line.strip()) == 0) or line.startswith('#'):
# 表示内容为空行或者以 # 开始, 是注释, 跳过
line = file.readline()
continue
yield line
line = file.readline()
相较于迭代器, 重写**__iter__**, **__next__**, 直接使用 yield 毫无疑问代码要简化很多.
为何要是用生成器 / 迭代器?
Generator expressions: 我们有时也会称为生成式
生成式语法规则如下
generator_expression ::= "(" expression comp_for ")"
生成器表达式会生成一个新的生成器对象(Generator Object). 它的语法与推导式相同, 只不过它被包含在圆括号中
生成器对象(Generator Object): 生成器对象是Python用来实现生成器迭代器的对象. 它们通常通过迭代产生值的函数来创建, 而不是显式调用
The parentheses can be omitted on calls with only one argument. 如果调用的函数只有一个参数, 可以忽略生成式的括号
例如
nums = [1, 2, 3, 4, 5]
res = ', '.join(str(i) for i in nums)
print(res)
"""
输出
1, 2, 3, 4, 5
"""
为何使用生成式? 惰性求值.
因为生成器表达式中使用的变量会在生成器对象调用 __next__() 方法时惰性求值(与普通生成器的工作方式相同). 然而, 最左侧 for 子句中的可迭代表达式会立即求值. 这意味着如果这个可迭代表达式产生了错误, 那么错误将在定义生成器表达式的位置就被抛出, 而不是等到第一次取值的时候.
至于后续的 for 子句, 以及最左侧 for 子句中的任何过滤条件, 它们不能在外部作用域中提前求值,因为它们可能依赖于从最左侧的可迭代对象中获得的值。
例如:(x*y for x in range(10) for y in range(x, x+10))
for x in range(10) 立即求值, 后续的for y in range(...) 会在每次取值的时候在求值(evaluate)
使用相对导入时,对于单独的 python 文件在运行时,应该将其视为一个 package, 而不是 module, 避免出现问题。
方法很简单,运行时加上 -m 即可,这样运行
文件结构如下
└─python
├─demo01.py
└─demo02.py
我们在 python 目录之外,使用如下的运行
python -m python.demo01
demo01 的内容如下
from .demo02 import demo02
if __name__ == "__main__":
demo02()
official: docs.python.org/zh-cn/3.13/…
__new__ 使用较少. 如果我们需要使用单例这种, 就需要使用该方法, 也就是客制化建立的过程, 或者metaclass的时候
__new__建立obj, 所以他必须要返回一个obj, 这是和__init__ 不同
# @author: falling snow
# @date: 2025-05-20
class A:
name = 'falling snow'
def __new__(cls, name):
# class > object
print("create a object")
print("__new__: name: " + name)
# 这里的写法需要注意.
return super().__new__(cls)
def __init__(self, name):
# have a object, init some properties
print("object initialize")
print(f'__init__: name: {name}')
self.name = name
if __name__ == '__main__':
# a = A() # error, A.__new__() missing 1 required positional argument: 'name'
# if using arguments
a1 = A('alice')
# equals
# a1 = __new__(A,'alice')
# __init__(a1, 'alice')
print('name = ' + a1.name)
__del__del可以当成Cpp的析构, 但是它不是. 他的会在对象释放后, 进行调用, 做一些处理.
但是Python中对象的释放. 较为复杂, 例如:
释放的时机是任意时期. 这个过程无法控制, 所以用的不多
__del__ 和 del 关键字不同.
del obj 只是让obj少一个引用, 但是并不会触发__del__
例如
class A:
def __del__(self):
print('__del__')
if __name__ == '__main__':
a = A()
x = a
del a # A()创建的对象减少一次引用. 但是依旧不会释放
print('main finish')
output
main finish
__del__
__str__ & __repr__二者主要是语义上不同, 都是返回一个字符串表示.
__str__ 返回人类理解的, 注重可读性
__repr__返回更详细的信息, 此方法通常被用于调试, 因此确保其表示的内容包含丰富信息且无歧义是很重要的
如果一个类定义了 __repr__() 但未定义 __str__(), 则在需要该类的实例的 "非正式" 字符串表示时也会使用 __repr__()
print(repr(A()))
print(str(A()))
print(A()) # 存在__str__, 调用它, 没有的话调用__repr__
__bytes__如果不客制化这个对象的二进制表示. 很少使用:D
class A:
def __bytes__(self):
# using bytes(obj), will call the method
print("__bytes__called")
return bytes([0, 1]) # return need bytes
if __name__ == '__main__':
print(bytes(A()))
python将比较大小的行为称为 Rich Comparison
Rich Comparison一共有6个操作符
object.__lt__(self, other) # <
object.__le__(self, other) # <=
object.__eq__(self, other) # ==
object.__ne__(self, other) # !=
object.__gt__(self, other) # >
object.__ge__(self, other) # >=
我们一般用于自定义的对象比较
因为在python中我们在没有实现一个类的比较运算符时, 他默认调用的是is
而is 的运算:
所以
class Date:
def __init__(self, year, month, day):
self.year = year
self.month = month
self.day = day
if __name__ == '__main__':
d1 = Date(2025, 5, 20)
d2 = Date(2025, 5, 20)
print(d1 == d2) # False
# equals
print(d1 is d2) # False
__eq__class Date:
def __init__(self, year, month, day):
self.year = year
self.month = month
self.day = day
def __eq__(self, other):
# override = operator
return (self.year == other.year and
self.month == other.month and
self.day == other.day)
if __name__ == '__main__':
d1 = Date(2025, 5, 20)
d2 = Date(2025, 5, 20)
print(d1 == d2) # True
# if obj not override __eq__(equals), python will call is
print(d1 is d2) # False
__ne__默认情况下, 如果没有实现该方法时, 对于 __ne__() , 默认会委托给 __eq__() 并对结果取反
print(d1 != d2) # equal !d1.__eq__(d2)
class Date:
def __init__(self, year, month, day):
self.year = year
self.month = month
self.day = day
def __ne__(self, other):
# override != operator
return (self.year != other.year or
self.month != other.month or
self.day != other.day)
__gt__ & __lt__class Date:
def __init__(self, year, month, day):
self.year = year
self.month = month
self.day = day
def __eq__(self, other):
# override == operator
return (self.year == other.year and
self.month == other.month and
self.day == other.day)
def __ne__(self, other):
# override != operator
return (self.year != other.year or
self.month != other.month or
self.day != other.day)
def __gt__(self, other):
print("__gt__")
if self.year > other.year:
return True
if self.year == other.year:
if self.month > other.month:
return True
if self.month == other.month:
return self.day > other.day
return False
def __lt__(self, other):
print("__lt__")
if self.year < other.year:
return True
if self.year == other.year:
if self.month < other.month:
return True
if self.month == other.month:
return self.day < other.day
return False
if __name__ == "__main__":
d1 = Date(2025, 4, 20)
d2 = Date(2025, 5, 20)
print(d1 > d2) # False
print(d1 < d2) # True
d1 < d2 对于d1而言是小于号, 但是对于d2是大于号. 那python如何确定使用什么符号呢?
对于这样的表达式
x < y
如果x, y不是同一个类的对象, 如果y是x的衍生类, 那优先使用y的Rich Comparison
例如, 我们定义如下的类
class Date:
def __init__(self, year, month, day):
self.year = year
self.month = month
self.day = day
def __gt__(self, other):
print("__gt__")
print(
f'self info: year: {self.year}, month: {self.month}, day: {self.day}')
print(
f'other info: year: {other.year}, month: {other.month}, day: {other.day}')
if self.year > other.year:
return True
if self.year == other.year:
if self.month > other.month:
return True
if self.month == other.month:
return self.day > other.day
return False
def __lt__(self, other):
print("__lt__")
print(
f'self info: year: {self.year}, month: {self.month}, day: {self.day}')
print(
f'other info: year: {other.year}, month: {other.month}, day: {other.day}')
if self.year < other.year:
return True
if self.year == other.year:
if self.month < other.month:
return True
if self.month == other.month:
return self.day < other.day
return False
# define a subclass of Date
class SubDate(Date):
pass
if __name__ == "__main__":
d1 = Date(2025, 4, 20)
nd = SubDate(2025, 1, 20)
print(d1 < nd)
输出
__gt__
self info: year: 2025, month: 1, day: 20
other info: year: 2025, month: 4, day: 20
False
所以, 因为nd是d1的子类, 从结果可以看见, 调用的是子类的方法.
我们最长使用hash的场景就是将一个对象的hash作为字典的key
python对于每个自定义的类都默认生成了一个hash 以及 eq函数, 但如果我们重写了eq, 那默认生成的hash就不会生成了.
因为hash的定义是. 如果2个对象相等, 那他的hash应该一致. 而如果我们自定义了eq, 那python并不知道我们是否会使用hash, 所以丢弃了默认生成的hash.
但如果我们希望将obj作为dict的key, 除了定义eq外, 还要定义hash
hash的要求:
python官方的建议是, 使用内置的hash方法. 将我们对象的核心属性组成一个tuple, 进行计算, 然后返回.
class Date:
def __init__(self, year, month, day):
self.year = year
self.month = month
self.day = day
def __repr__(self):
return f"Date[year: {self.year}, month: {self.month}, day: {self.day}]"
def __hash__(self):
return hash((self.year, self.month, self.day))
def __bool__(self):
# using the method of if segement
print("__bool__")
return False
if __name__ == "__main__":
d1 = Date(2025, 5, 21)
d2 = Date(2025, 5, 21)
# a dict
income = {}
income[d1] = 100
income[d2] = 100
print(income)
if (d1):
# equal bool(d1) === d1.__bool__()
pass
__getattr__访问一个不存在的属性时, 我们该做什么
class A:
def __init__(self, desc):
self.desc = desc
self.counter = 0
def __getattr__(self, name):
print("the name properties not exist")
raise AttributeError()
if __name__ == "__main__":
a = A("alice")
print(a.name)
__getattribute__注意不要使用getattr(self, name)函数, 因为它会调用__getattribute__, 从而产生一个无限递归
如果需要获取当前属性, 需要通过super的方式调用super().__getattribute__(name). 当然使用object.__getattribute__(name) 也是允许的
下面这种也是一种递归调用!
class A:
def __init__(self, desc):
self.desc = desc
self.counter = 0
def __getattr__(self, name):
pass
def __getattribute__(self, name):
print("__getattribute__")
# 有时我们希望统计属性的访问次数. 可能会写出如下的代码
self.counter += 1
return super().__getattribute__(name)
if __name__ == "__main__":
a = A("alice")
print(a.desc)
因为self.counter += 1 这个操作会触发 __getattribute__ 调用.
__setattr__在社区的一些编写过程中, 我们通常可能使用super().__setattr__(name, value)这种方式替代我们的object...的形式, 因为我们的类可能是存在多层继承的关系嘛.
而该special method更多的是用于拦截我们的赋值行为, 从而实现一些委托代理的味道.
class A:
def __init__(self, desc):
self.desc = desc
self.counter = 0
def __getattr__(self, name):
pass
def __getattribute__(self, name):
pass
def __setattr__(self, name, value):
print("__setattr__")
# 完成赋值行为的默认定义. 实现具体的赋值功能
super().__setattr__(name, value)
if __name__ == "__main__":
a = A("alice")
a.desc = "hello, world!"
print(a.desc)
print(a.name) # error
因为__setattr__可以拦截赋值操作, 所以有时候我们可以做一些神奇的东西. 例如
class A:
_attr = {}
def __init__(self):
self.data = "alice"
def __getattr__(self, name):
if name not in self._attr:
raise AttributeError
# Note: call __getattribute__
return self._attr[name]
def __setattr__(self, name, value):
self._attr[name] = value
if __name__ == "__main__":
o1 = A()
o2 = A()
o1.data = "Bob"
print(o2.data) # Bob
我们的_attr属性是属于A这个class的. 他没有和self关联, 这意味着所有基于A Class创建的object都拥有这个_attr属性
而我们对每个object的属性赋值, 最终都会挂载到我们的_attr上. 是不是很神奇.
还有在__getattr__中调用的self._attr[name] 会调用系统提供的 __getattribute__ 从而不会出现递归调用
__delattr__在一个对象正常的产生和消亡, 并不会调用该方法
他是在我们尝试删除一个object属性, 它才会调用
getattr 这个 special method 会经常用于我们封装一些 wrapper 的方法,例如 Dify 在设计它们的 Redis 客户端的时候,考虑到 python 模块加载的特殊性,所以使用 Wrapper 包裹具体的 redis 客户端,具体实现为:
if TYPE_CHECKING:
from redis.lock import Lock
logger = logging.getLogger(__name__)
class RedisClientWrapper:
"""
A wrapper class for the Redis client that addresses the issue where the global
`redis_client` variable cannot be updated when a new Redis instance is returned
by Sentinel.
This class allows for deferred initialization of the Redis client, enabling the
client to be re-initialized with a new instance when necessary. This is particularly
useful in scenarios where the Redis instance may change dynamically, such as during
a failover in a Sentinel-managed Redis setup.
Attributes:
_client: The actual Redis client instance. It remains None until
initialized with the `initialize` method.
Methods:
initialize(client): Initializes the Redis client if it hasn't been initialized already.
__getattr__(item): Delegates attribute access to the Redis client, raising an error
if the client is not initialized.
"""
_client: Union[redis.Redis, RedisCluster, None]
def __init__(self) -> None:
self._client = None
def initialize(self, client: Union[redis.Redis, RedisCluster]) -> None:
if self._client is None:
self._client = client
if TYPE_CHECKING:
# Type hints for IDE support and static analysis
# These are not executed at runtime but provide type information
def get(self, name: str | bytes) -> Any: ...
...
def __getattr__(self, item: str) -> Any:
if self._client is None:
raise RuntimeError("Redis client is not initialized. Call init_app first.")
return getattr(self._client, item)
redis_client: RedisClientWrapper = RedisClientWrapper()
...
一个Web应用的本质就是:
而常规的web服务器会帮我实现好一些基础的操作,例如
接受HTTP请求、解析HTTP请求、发送HTTP响应
当然我们可以自己写,但是这些内容并不容易。我们需要对TCP, HTTP,HTTPS 等规范有着深刻的理解
大部分应用会将这些封装好,对我们上层开发者提供对应的接口,从而方便我们编写对应的web业务。
但不同的服务器可能会提供不同的接口,这里语言的设计团队一般会提供一套设计好的接口,从而使得每个
web服务提供的上层接口是一致的。
python中web接口有:
这样web服务器开发和web框架的开发就是分离,例如 FastAPI 是一个web框架,它基于ASGI实现,而ASGI对应的服务器有uvicorn, Daphne, Hypercorn
或许未来有更高效的ASGI服务器,那fastAPI也可以无缝衔接。
测试一下:
pip install fastapi
pip install hypercorn
pip install uvicorn
示例代码
from fastapi import FastAPI
# hypercorn的启动
from hypercorn.config import Config
from hypercorn.asyncio import serve
import asyncio
app = FastAPI()
@app.get("/hello")
async def hello():
return {
"desc": "hello, world"
}
# 方式 1:使用 asyncio + serve(推荐)
async def main():
config = Config()
config.bind = ["0.0.0.0:8000"]
config.workers = 1 # 注意:asyncio serve 本身是单进程,workers 在这里无效
# 这里可能会有警告,因为starlette和hypercorn的类型声明不完全一致,但符合ASGI要去
# ASGI
# receive: an awaitable callable that will yield a new event dictionary when one is available
# receive:调用一次 receive(),await 一次,得到一个事件字典
# 只要定义如下的 类型 声明就可以了
# from typing import Callable, Awaitable, Dict, Any
#
# Receive = Callable[[], Awaitable[Dict[str, Any]]]
await serve(app, config)
def application(environ, start_response):
"""
:param environ:一个包含所有HTTP请求信息的dict对象;
:param start_response:一个发送HTTP响应的函数。
:return: 有了WSGI,我们关心的就是如何从environ这个dict对象拿到HTTP请求信息,然后构造HTML,通过start_response()发送Header,最后返回Body
通过调用一些实现了WSGI的服务器,底层代码不需要我们自己编写,我们只负责在更高层次上考虑如何响应请求就可以了
"""
# 从请求中获取一些信息,动态返回内容
path = environ["PATH_INFO"][1:] or "world"
# 设置返回的响应头
start_response('200 OK', [('Content-Type', 'text/html')])
# 设置返回的响应body
resp_body = f"<h1>Hello, {path}</h1>"
return [resp_body.encode()]
def wsgiServer():
# 从wsgiref模块导入:
from wsgiref.simple_server import make_server
# 创建一个服务器,IP地址为空,端口是8000,处理函数是application:
httpd = make_server('', 8000, application)
print('Serving HTTP on port 8000...')
# 开始HTTP请求:
httpd.serve_forever()
if __name__ == '__main__':
# import uvicorn
#
# uvicorn.run("WSGI_interface_learn:app")
# hypercorn的启动
# asyncio.run(main())
# 官方的wsgiref 的启动,该服务器是python官方基于WSGI接口实现的一个简易的服务器
wsgiServer()
这里因为 FastAPI 是基于 ASGI 接口进行的开发,所以只要任何实现了该接口的服务器,都可以运行 FastAPI 的程序,上面的示例中,我们通过 uvicorn,以及hypercorn 进行了测试
为了简化讲解,我们这里将忽略内核线程,用户线程等专业的概念
协程是在一个线程中执行
最大的优势就是协程极高的执行效率。因为子程序切换不是线程切换,而是由程序自身控制,
因此,没有线程切换的开销,和多线程比,线程数量越多,协程的性能优势就越明显
第二大优势就是不需要多线程的锁机制,因为只有一个线程,也不存在同时写变量冲突(竞态条件)
在协程中控制共享资源不加锁,只需要判断状态就好了,所以执行效率比多线程高很多
因为协程是一个线程执行,想要利用多核CPU。最简单的方法是多进程+协程,因为 python 存在 GIL 的存在,所以我们这里需要多进程。从而充分利用多核,又充分发挥协程的高效率,可获得极高的性能
Python对协程的支持是通过 generator 实现的。也就是生成器,而生成器的语法核心在yield, 所以我们需要先了解 yield, yield form是什么
所以我们先学习 Generator 的内容,不过 generator 依赖我们以前学习的 iterator
从 该 pep 开始 peps.python.org/pep-0342/
将 yield 重新定义为表达式(expression),而不是语句(statement),但每当生成器通过正常的 next() 调用恢复时,yield 表达式的值都是 None
表达式相较于语句的好处就是,可以有返回值
**这里要注意的是:调用 send(None) 完全等同于调用生成器的 next() 方法, 其次 由于生成器迭代器在生成器函数体的顶部开始执行, **
**因此当生成器刚刚创建时,没有 yield 表达式来接收值。因此,当生成器迭代器刚刚启动时,禁止使用非 None 参数调用 send(), **
**如果发生这种情况,则会引发 TypeError(可能是由于某种逻辑错误)。 **
因此,在与协程通信之前,必须先调用 next() 或 send(None) 将其执行推进到第一个 yield 表达式
async def my_coroutine() -> None:
print("Hello world!")
这个函数很简单, 仅仅是加上了一个 async 关键字.
async def coroutine_add_one(number: int) -> int:
return number + 1
def add_one(number: int) -> int:
return number + 1
if __name__ == '__main__':
function_result = add_one(1)
coroutine_result = coroutine_add_one(1)
print(f"普通函数结果为: {function_result} 返回值的类型为: {type(function_result)}")
print(f"coroutine结果为: {coroutine_result} 返回值的类型为: {type(coroutine_result)}")
普通函数结果为: 2 返回值的类型为: <class 'int'>
coroutine结果为: <coroutine object coroutine_add_one at 0x000002915BA9E570> 返回值的类型为: <class 'coroutine'>
当我们调用时coroutine函数时, 不会执行协程中的代码. 我们得到的是一个coroutine对象, 这个对象是可以稍后执行的, 如果希望运行一个 coroutine, 需要在事件循环上进行运行.
现在的问题是, 如何创建事件循环?
在python3.7之后, asyncio提供了几个方便的函数, 而其中有一个 asyncio.run 可以用来运行协程
关于 asyncio.run: docs.python.org/zh-cn/3.15/…
import asyncio
async def coroutine_add_one(number: int) -> int:
return number + 1
if __name__ == '__main__':
# 这里是传递coroutine, 而不是函数对象
result = asyncio.run(coroutine_add_one(1))
print(result)
asyncio.run它创造了一个事件循环. 一旦它成功, 它就会接受传递给它的协程并运行它, 直到协程执行完成, 返回结果
可能最重要的是, 它旨在成为我们创建的 asyncio 应用程序的主要入口点
它只执行一个协程, 并且该协程应该启动我们应用程序的所有其他方面.
在后面的内容中, 我们将渐渐使用此函数作为几乎所有应用程序的入口点. asyncio.run执行的协程将创建并运行其他协程, 这将使我们能够利用 asyncio 的并发性质
asyncio 的真正好处是能够暂停执行, 让事件循环在执行一个尝试操作的时候, 运行其他任务
如果希望暂停, 可以通过 await 关键字, 该关键字后面跟着coroutin的调用(更具体地说, 是一个称为 awaitable 的对象, 它并不总是coroutine, 我们将在后面了解有关 awaitables 的更多信息)
使用await将导致其后面的协程被运行, 这与直接调用协程不同.
注意: 该await awaitable表达式, 还将暂停包含它的协程, 直到这个等待的协程完成并返回结果, 然后程序往下执行.
import asyncio
async def coroutine_add_one(number: int) -> int:
return number + 1
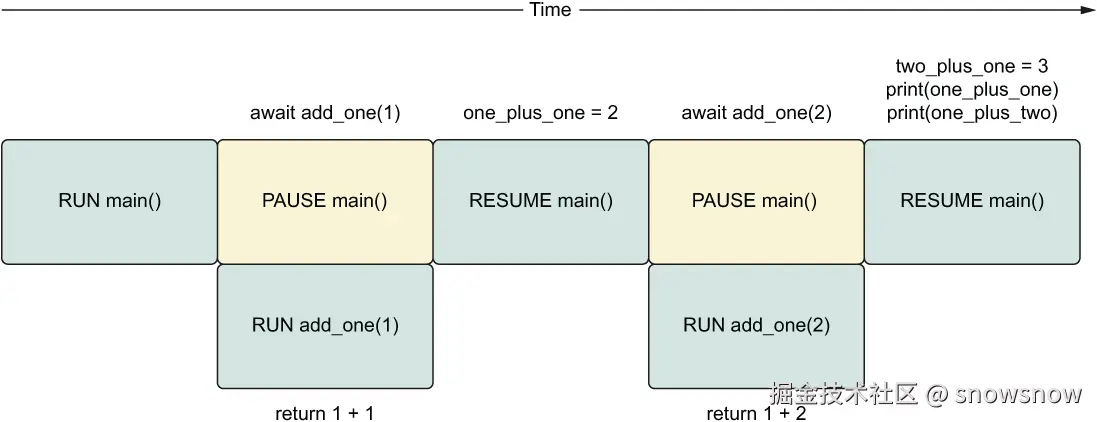
async def main() -> None:
one_plus_one = await coroutine_add_one(1)
two_plus_one = await coroutine_add_one(2)
print(one_plus_one)
print(two_plus_one)
if __name__ == '__main__':
asyncio.run(main())
这里main是父coroutine 函数, 而add_one这个是子coroutine 函数
我们暂停父协程并在 await 表达式中运行add_one协程, 完成后, 我们恢复父协程并获取返回值.
就目前而言, 此代码的作方式与普通顺序代码没有区别, await之后的程序也没有任何IO的行为.
用 viztracer(python一个可视化库) 可以看到这样的执行流程
不过在python3.14之后官方提供了查看异步任务的api了。
asyncio.sleep可以"睡眠"制定的秒数, 这个函数也是一个 coroutine, 所以应该配合await 使用, 而不能直接调用. 从而模拟使用 一些 耗时 的 I / O 行为
import asyncio
async def hello_world_message() -> str:
await asyncio.sleep(1)
return "Hello World!"
async def main() -> None:
message = await hello_world_message()
print(message)
if __name__ == '__main__':
asyncio.run(main())
因为后续会经常使用 sleep, 所以我们尝试设置一个可复用的 delay协程
该文件位于 util 模块下.
"""
@file_name: delay_functions.py
@desc: 可复用的 delay 函数
"""
import asyncio
async def delay(delay_second: int) -> int:
print(f"睡眠 {delay_second} 秒")
await asyncio.sleep(delay_second)
print(f"睡眠 {delay_second} 秒 已完成")
return delay_second
import asyncio
from util import delay
async def add_one(number: int) -> int:
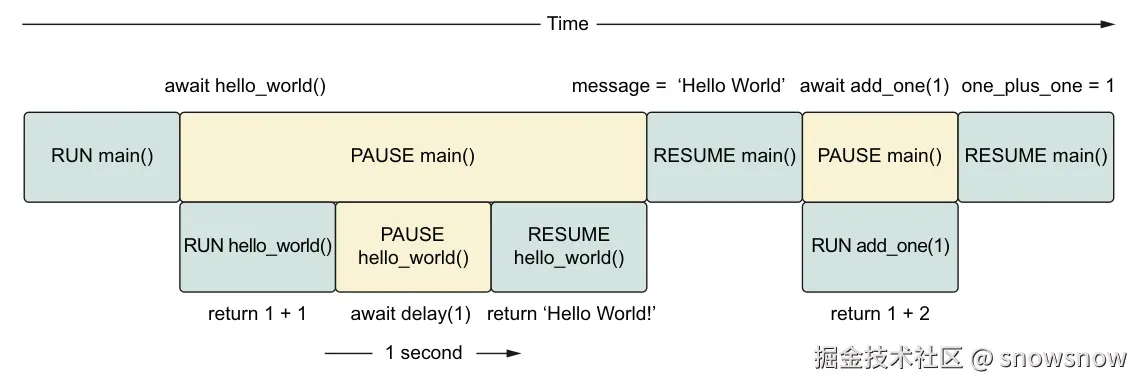
return number + 1
async def hello_world_message() -> str:
await delay(1)
return "Hello World!"
async def main() -> None:
message = await hello_world_message()
one_plus_one = await add_one(1)
print(one_plus_one)
print(message)
if __name__ == '__main__':
asyncio.run(main())
睡眠 1 秒
睡眠 1 秒 已完成
2
Hello World!
当我们运行它时, 在打印两个函数调用的结果之前经过 1 秒. 我们真正想要的是 add_one(1)的值和 hello_world_message() 并发运行时立即打印. 那么为什么这段代码没有发生这种情况呢? 答案是 await 暂停我们当前的协程, 并且在表达式给我们一个值之前不会在该协程中执行任何其他代码
这种情况下, 我们的代码表现得好像它是顺序的
为了实现 执行协程时, 不会阻碍后续程序的执行, 我们需要引入一个 Task 的概念.
Task是coroutine的包装器, 用于安排coroutine尽快在事件循环上运行. 这种调度和执行以非阻塞方式进行, 这意味着, 一旦我们创建了一个任务, 我们就可以在任务运行时立即执行其他代码
这与我们之前使用await 表达式存在显著的不同.
通过它, 我们可以同时执行多个任务. 也就是降低我们的I / O 的等待时间.
我们需要通过 asyncio.create_task 创建Task.
该函数接受的参数类型为: Generator[Any, None, _T] | Coroutine[Any, Any, _T]
import asyncio
from util import delay
async def main():
sleep_for_three = asyncio.create_task(delay(3))
print(type(sleep_for_three))
result = await sleep_for_three
print(result)
if __name__ == '__main__':
asyncio.run(main())
<class '_asyncio.Task'>
睡眠 3 秒
睡眠 3 秒 已完成
3
值的注意的是: 如果我们不使用 await 等待coroutine运行结束, 我们的Task将被安排运行, 但在关闭事件循环时, 它几乎会立即停止并“清理”
这个问题, 我们在后面会提供一些方式来处理.
import asyncio
from util import delay
async def main():
sleep_for_three = asyncio.create_task(delay(3))
print(type(sleep_for_three))
if __name__ == '__main__':
asyncio.run(main())
<class '_asyncio.Task'>
睡眠 3 秒
程序没有执行完毕.
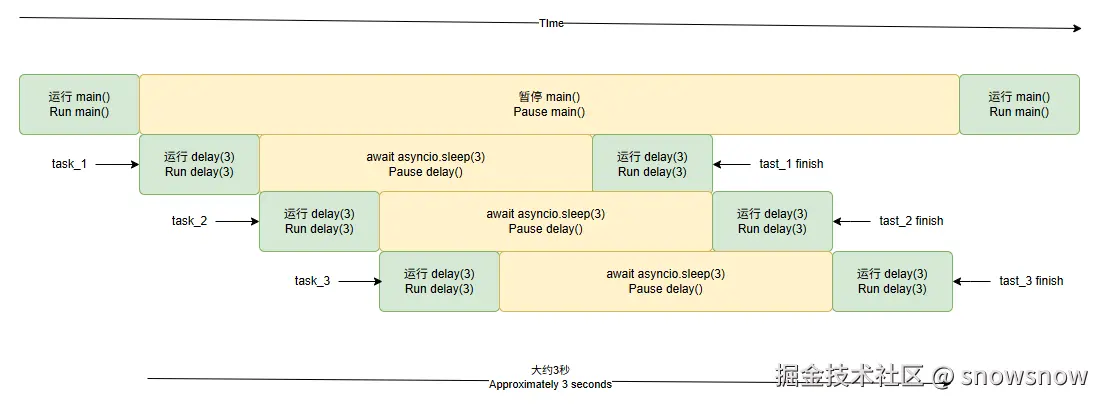
并发运行多任务
import asyncio
import time
from util import delay
async def main():
start = time.time()
sleep_for_three = asyncio.create_task(delay(3))
sleep_again = asyncio.create_task(delay(3))
sleep_one_more_time = asyncio.create_task(delay(3))
await sleep_for_three
await sleep_again
await sleep_one_more_time
end = time.time()
print(f"执行耗时: {end - start:.4f}")
if __name__ == '__main__':
asyncio.run(main())
睡眠 3 秒
睡眠 3 秒
睡眠 3 秒
睡眠 3 秒 已完成
睡眠 3 秒 已完成
睡眠 3 秒 已完成
执行耗时: 3.0056
注意: 标记为 RUN delay(3) 的任务中的代码(在上面代码中, 某些 print 语句)不会与其他任务同时运行; 只有进行 sleep 的时候同时运行
在没有 协程 的时候, 我们的这个程序可能需要9秒, 在拥有了 协程 之后 我们将此应用程序的总运行时间缩短了三倍
同时执行这些长时间运行的作是 asyncio 真正闪耀的地方, 它极大地提高了我们的应用程序性能, 不过也可以发现它减少的是 I / O 时间
在代码等待期间, 我们可以执行其他代码. 例如, 假设我们想在运行一些长时任务时每秒打印一条状态消息
import asyncio
from util import delay
async def hello_every_second() -> None:
for i in range(4):
await asyncio.sleep(1)
print("我在等待的时候正在运行其他代码!")
async def main() -> None:
first_delay = asyncio.create_task(delay(3))
second_delay = asyncio.create_task(delay(3))
asyncio.create_task(hello_every_second())
await first_delay
print("first_delay after")
await second_delay
print("second_delay after")
if __name__ == '__main__':
asyncio.run(main())
这个程序 print("我在等待的时候正在运行其他代码!")可能会输出2次, 也可能输出3次.
输出2次是在main执行完毕后, hello_every_second完成了2次等待.
输出3次是在main执行完毕后, hello_every_second完成了3次等待.
因为 sleep 的这个睡眠不能保证完全准确, 所以可能会有一定的误差. 如果希望等待 hello_every_second 执行完毕, 可以加上await
import asyncio
import threading
async def hello(name):
# 打印name和当前线程:
print(f"Hello {name}! {threading.current_thread()}")
await asyncio.sleep(1)
print(f"Hello {name} again! {threading.current_thread()}")
return name
async def wget(host: str):
print(f"wget {host} ...")
# 使用asyncio获取非阻塞的异步socket
reader, writer = await asyncio.open_connection(host, 80)
# 发送 HTTP 请求
header = f"GET / HTTP/1.0rnHost: {host}rnrn"
writer.write(header.encode("utf-8"))
await writer.drain()
# 获取响应数据
while True:
line: bytes = await reader.readline()
# 这里只读取header, 没有读取body
if line == b"rn":
break
print(f"{host} 返回数据 {line.decode('utf-8')}")
# 关闭socket
writer.close()
await writer.wait_closed()
print(f"{host} wget 完成")
async def main():
# 用asyncio.gather()同时调度多个async函数, 该函数会返回异步函数的执行结果。不过gather无法指定函数的执行顺序
# 从线程id可以看出都是在一个线程中 4832
# L = await asyncio.gather(hello("alice"), hello("bob"))
# print(L)
await asyncio.gather(wget("www.example.com"), wget("www.baidu.com"))
if __name__ == '__main__':
# asyncio.run(main())
print(asyncio.get_event_loop_policy())
注意 gather 的使用,他会同时调用所有的异步方法,其次会等到所有函数调用完成后返回结果,但是他无法让我们自定义函数的执行顺序。
Annotated它 是 Python 3.9+ 引入的类型注解,它的功能是在类型注解上附加额外的元数据,而不影响类型本身
from typing import Annotated
# Python 运行时可以提取这些元数据
from typing import get_args, get_origin
# Annotated[类型, 元数据1, 元数据2, ...]
hint = Annotated[str, "这是用户名", "最大长度100"]
print(get_origin(hint)) # <class 'typing.Annotated'>
print(get_args(hint)) # (str, '这是用户名', '最大长度100')
# ↑类型 ↑元数据1 ↑元数据2
使用该功能,给类型添加了元数据之后,可以获取更多的变量信息。
在 python 的现代化开发中这个类型经常使用,例如 FastAPI 就会使用它来做依赖注入的特殊处理,python 的一个特点之一 Free
from typing import get_args, get_origin, Annotated
def parse_parameter(annotation, default):
# 检查是否是 Annotated 类型
if get_origin(annotation) is Annotated:
args = get_args(annotation)
actual_type = args[0] # str | None
metadata = args[1:] # (Header(description="设备标识"),)
# 遍历元数据,找到 FastAPI 能够识别的对象
for meta in metadata:
if isinstance(meta, Header):
# 找到了!这是一个 Header 参数
return {
"type": actual_type,
"source": "header",
"convert_underscores": meta.convert_underscores,
"description": meta.description,
}
# 不是 Annotated,按普通参数处理
return {"type": annotation}
待续...

