以观书法
108.85M · 2026-02-05

在这个 AI 技术狂飙的时代,从 ChatGPT 到 Gemini、Qwen、Deepseek,每隔几天就会有一个大新闻。人工智能正在重塑每一个行业。
对于 Android 开发者而言,自动化测试,一直是个很鸡肋的任务:写吧,嫌麻烦,而且经常要跟随迭代维护。不写吧?好像又显得不专业?容易心慌?
也许你听说过 Espresso 或 Appium 能做自动化测试,但仍然逃不了写测试脚本的命运。这样的问题有很多解法,比如,让 AI 来写测试。
而我想到了另一个思路,那就是:让 AI 帮我做测试!
有了这个想法,我就开始写代码了。实际操作下来,遇到了不少问题,我慢慢通过博客来记录。
首先,云端 AI API 肯定是不能用的,因为会特别烧钱。最好能让 AI 跑在我们自己的电脑上,这样一来自动化测试的成本就可以忽略不计了。幸运的是,随着 Gemma、Qwen 等开源模型的持续优化,端侧模型的智能程度已经足以胜任这些简单的逻辑任务。
解决了端侧 AI 运行的问题后,剩下的 OCR、OpenCV 相关的技术就不是问题了。
接下来,请大家看看我闲暇时间写的这个项目:基于端侧 AI 的 Android 自动化测试 Agent 项目——Monkey-AI。
作为 Android 程序员,Monkey 多多少少都应该听说过吧?Monkey-AI 顾名思义,就是一个运行在桌面电脑( MacOS/Windows)的 Android 自动化测试 Agent。它不依赖昂贵的云端 API,完全基于本地运行的开源大模型来驱动。
它就像一只聪明且不知疲倦的“猴子”,但这只猴子装上了“大脑”和“眼睛”:
本项目目前支持两大主流开源模型家族,它们各有所长:
Gemma 是 Google 基于 Gemini 技术构建的轻量级开放模型。
Qwen (通义千问) 家族的 Vision-Language (VL) 版本,拥有强大的视觉理解能力。
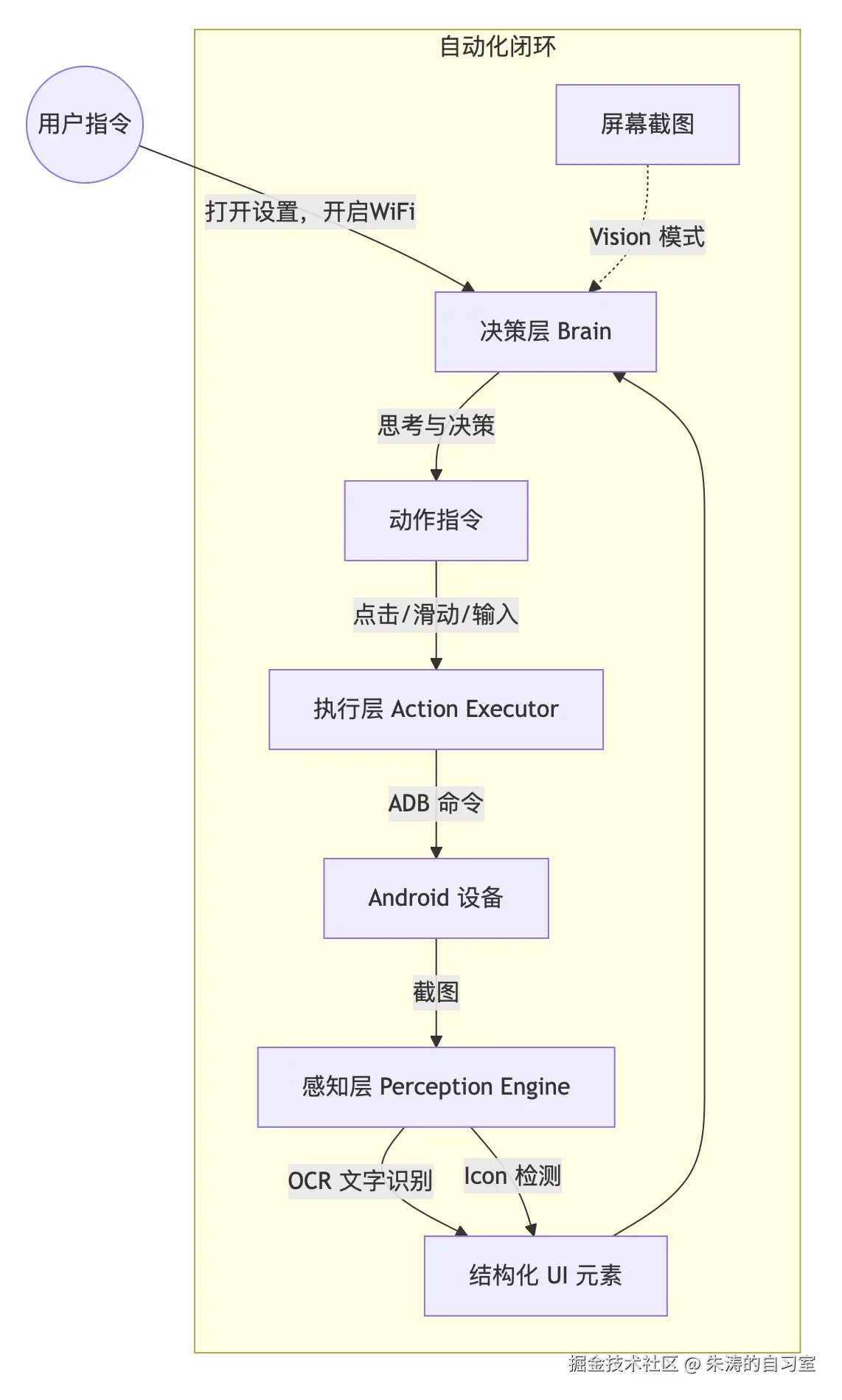
Monkey-AI 的实现逻辑并不复杂,核心是一个感知-决策-执行的闭环系统。下面是它的架构流程图:
这是 Agent 的“眼睛”。单纯的大模型虽然强大,但直接处理高分辨率截图速度较慢且精度有限。因此,我们引入了传统的计算机视觉技术作为辅助:
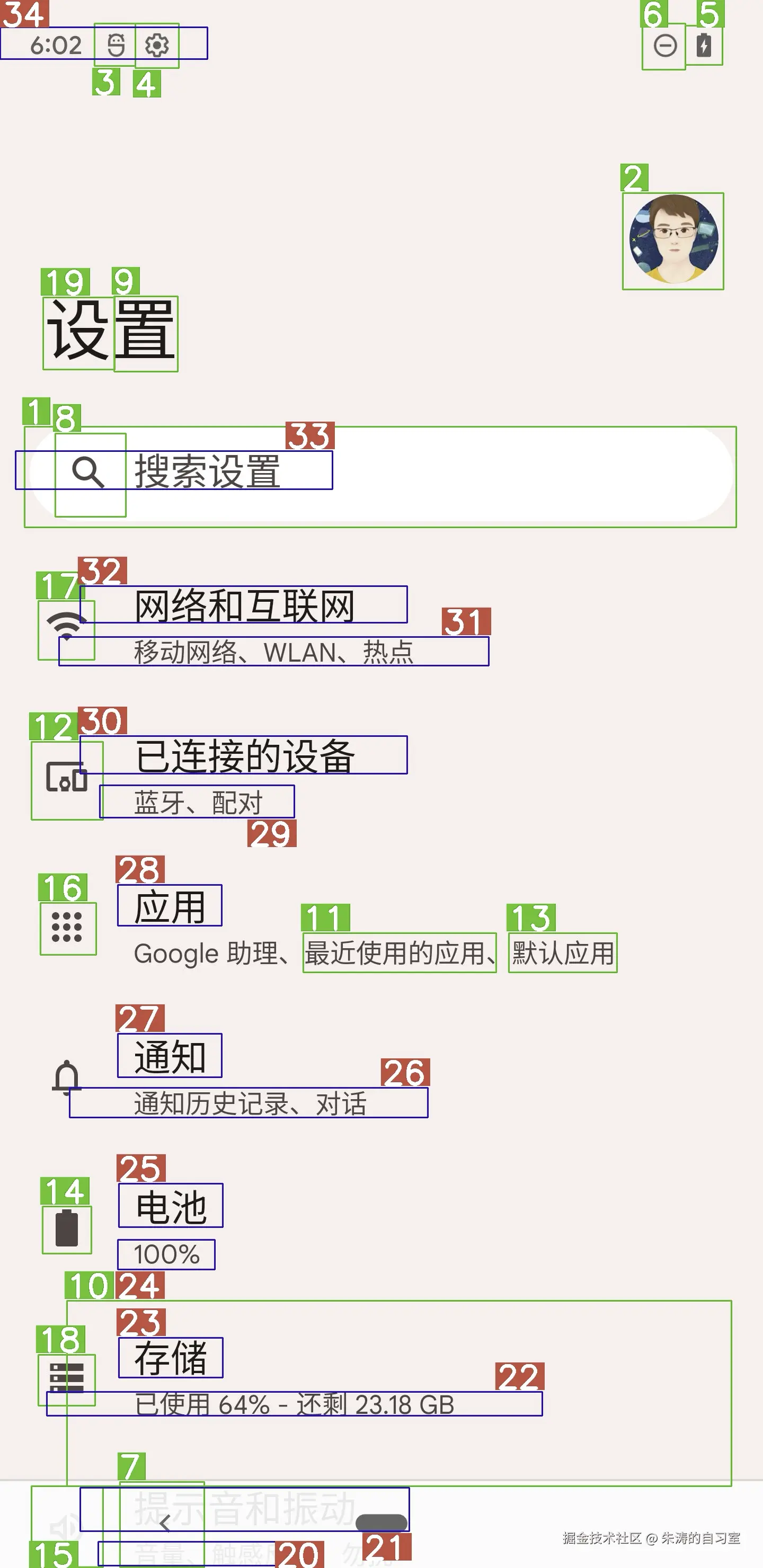
ClickableElement 列表。其实,OCR 和 YOLO 预处理这个步骤,对于顶尖的 LLM 是可以省略的,像 Gemini 3、GPT5,它们都能够直接通过截图给出具体行为的坐标。但我们这不是为了省钱,想用自己的电脑来跑嘛,所以,这个预处理步骤就显得很重要了。
提前标记好所有的文本、icon,给它们编号,LLM 在决策的时候能够跳过坐标计算,直接推理下一步具体的行为。这个步骤可以大幅提升小模型的行为准确度。
这是 Agent 的“大脑”。
// Brain 层抽象
@dataclass(frozen=True)
class ScreenState:
elements: list[ClickableElement]
screen_size: tuple[int, int]
package: str | None
image_bgr: "np.ndarray | None" = None
class Brain(ABC):
@abstractmethod
def next_action(self, screen: ScreenState) -> Action:
raise NotImplementedError
对于端侧的 AI 模型,是否开启 Think,效果差异会很大。
用户现在需要完成的任务是:打开设置页面,进入通知栏,去应用设置里,关闭Chrome的通知权限。首先看历史动作已经点击了设置图标,所以当前在设置主界面。
接下来要进入通知相关部分。根据元素列表,27对应的是“通知”,文本是“通知”,位置在屏幕中下部。所以需要点击“通知”选项来进入通知设置页面。
检查可点击元素列表,第27个元素是text 通知 (226, 1955, 414, 2029),对应的就是通知入口。因此下一步操作应该是点击这个“通知”选项。
</think>
这是 Agent 的“手”。
大脑输出的决策通常是抽象的(例如:“点击 ID 为 5 的元素”)。执行层负责将这些指令翻译成具体的 Android 坐标,通过 ADB 发送 input tap 或 input swipe 命令,甚至处理坐标映射(从截图坐标系到设备坐标系)。
这个部分反而是最简单的,作为 Android 程序员,谁还不会点 adb 命令了?
class AndroidDevice:
def __init__(self, device: u2.Device) -> None:
self._device = device
@classmethod
def connect(cls, serial: str | None = None) -> "AndroidDevice":
device = u2.connect(serial) if serial else u2.connect()
return cls(device)
def info(self) -> DeviceInfo:
info = self._device.info
width = int(info.get("displayWidth") or 0)
height = int(info.get("displayHeight") or 0)
serial = info.get("serial")
return DeviceInfo(width=width, height=height, serial=serial)
def screenshot_bgr(self) -> np.ndarray:
image = self._device.screenshot(format="opencv")
if not isinstance(image, np.ndarray):
raise ValueError("screenshot not returned as ndarray")
return image
def click(self, x: int, y: int) -> None:
self._device.click(x, y)
def swipe(self, start: tuple[int, int], end: tuple[int, int], duration: float | None = None) -> None:
if duration is None:
self._device.swipe(start[0], start[1], end[0], end[1])
else:
self._device.swipe(start[0], start[1], end[0], end[1], duration)
def press(self, key: str) -> None:
self._device.press(key)
def input_text(self, text: str) -> None:
payload = text.replace(" ", "%s")
self._device.adb_shell("input", "text", payload)
def app_start(self, package: str) -> None:
self._device.app_start(package, wait=True)
def app_current(self) -> dict[str, Any]:
return self._device.app_current()
def window_size(self) -> tuple[int, int]:
size = self._device.window_size()
return int(size[0]), int(size[1])
Monkey-AI 目前还是一个 Lite 版本,但它展示了端侧 AI + 自动化测试的巨大潜力:
虽然现阶段跑在PC电脑上的 Monkey-AI 偶尔还会“犯傻”,操作速度也比不上手写脚本,但它代表了未来的方向。Android 开发者们,是时候拥抱 AI,让我们的测试工作变得更酷、更智能了!
目前 Monkey-AI 还在内部测试阶段,欢迎感兴趣的朋友关注我的公众号:朱涛的自习室,参与测试。

