




创源素材
67.15M · 2026-02-04

上篇文章《大模型训练全流程实战指南基础篇(四)——本地部署大模型API调用实战:Python对接OpenAI格式全解析》介绍了如何通过代码调用本地部署的大模型,实现自动化任务处理。至此,大家已经掌握了模型文件结构、模型本地部署与API代码调用的基本技能。
从本期内容开始,本系列将进入工具篇。在工具篇笔者首先会系统梳理大模型训练的整体流程,并针对训练流程的每个阶段推荐相应的实用工具;随后,笔者将挑选其中具有代表性的工具进行详细讲解与实战演示。工具篇之后将进入实战篇,笔者会带领大家运用所学工具,完整走通从数据准备、模型训练到最终部署上线的全流程。可以说,工具篇是承上启下的关键环节,希望大家认真学习,为后续实战打下坚实基础。
本期内容笔者会帮助大家建立对大模型训练全流程的结构化认知,同时为每个环节提供可操作的工具推荐。大家可以借助推荐工具动手实践,逐步构建属于自己的大模型训练工作流。
需要注意的是,大模型训练对计算资源尤其是GPU显存有较高要求。为降低学习与实践门槛,笔者已与国内主流云平台合作,为大家争取到了H100 GPU 6.5小时的免费算力体验机会。只需点击链接 Lab4AI 即可领取。本系列所有实战环节均将基于该平台完成,助力大家以更低成本上手大模型训练。
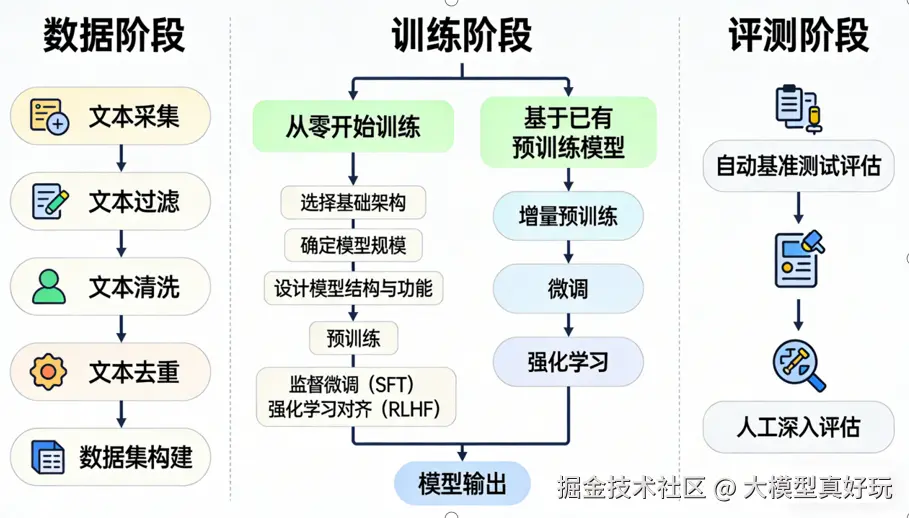
大模型训练的整体流程通常可分为三大核心阶段:数据阶段、训练阶段与评测阶段。每个阶段又可进一步细分为若干关键步骤。
了解整体流程后,大家可能仍对每个子环节的具体作用,以及应选用哪些工具进行处理感到困惑。别担心,接下来笔者将逐一详解各环节,并推荐相应的常用工具。
数据工程阶段的核心任务,是将原始数据转化、处理为可用于大模型训练的高质量数据集。大模型本质上可以视作一个庞大的“知识库”,其能力直接源自于训练数据中所蕴含信息的广度与质量。尤其对于大语言模型(LLM)而言,如何获取并有效处理高价值的文本语料,是整个训练流程中最为关键的基石。该阶段主要包含以下四个核心环节。
文本采集旨在从各类来源收集原始文本材料,为后续处理提供基础原料。
数据来源分类:
Common Crawl(PB级网络爬虫数据仓库)等大规模语料库。相关处理与工具推荐:
自行采集数据:可使用专业爬虫工具(如八爪鱼、亮数据)或自行编写脚本(推荐使用 Python 的 Scrapy 等框架)。若目标为训练通用大模型,建议参考百度百科或学科门类(我国共13类:哲、经、法、教、文、史、理、工、农、医、军、管、艺)进行针对性爬取,以保证数据多样性及质量。若爬取得到的数据源为图片或扫描件,需通过 OCR 技术(推荐 MinerU工具、DeepSeek-OCR 模型)转为文本,更多OCR工具可参考笔者文章OCR技术简史: 从深度学习到大模型,最强OCR大模型花落谁家。
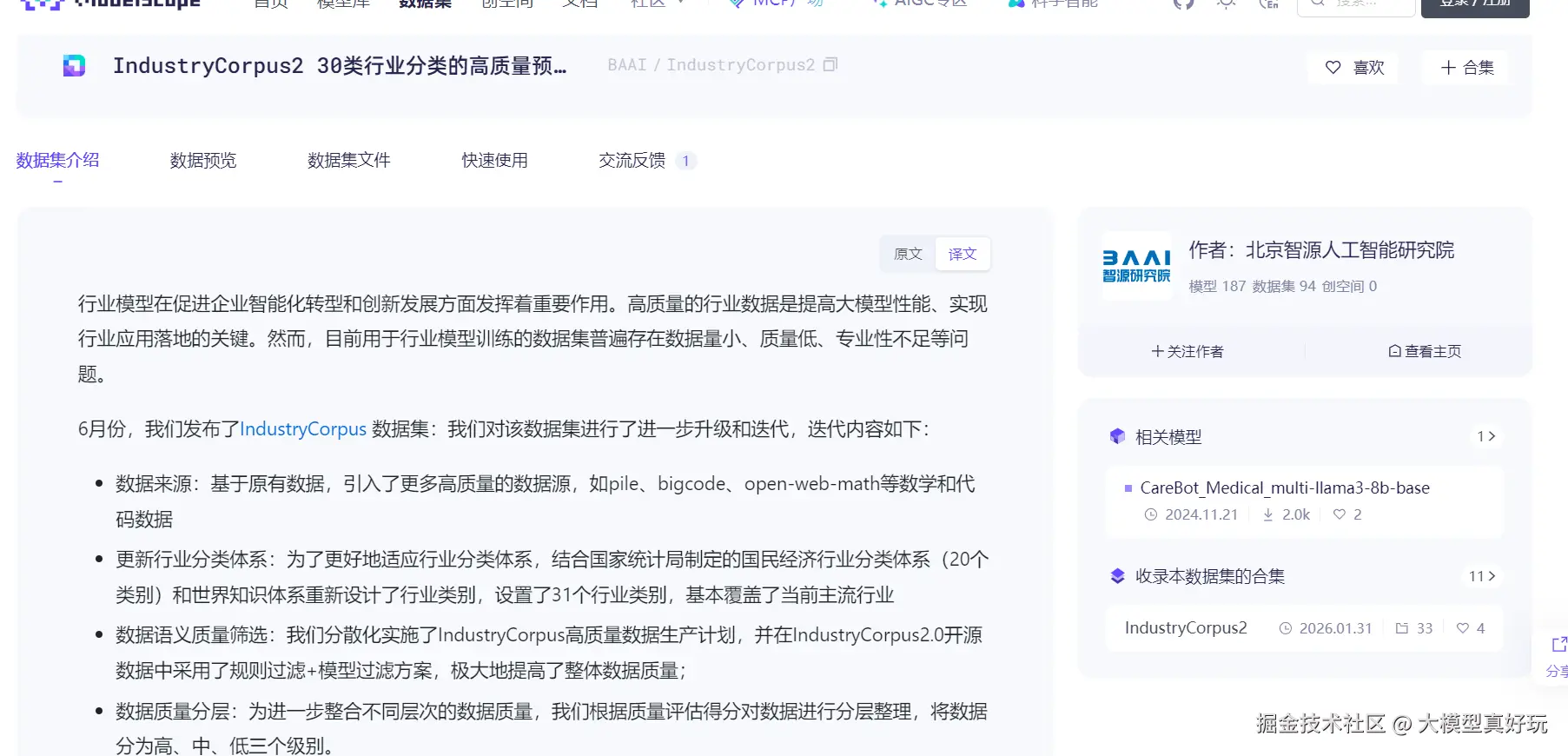
使用公开数据集:Hugging Face、ModelScope 等平台汇聚了大量开源数据集。例如,下图展示了智源研究院在 ModelScope 上开源的 IndustryCorpus2 分类预训练数据集,可直接下载使用。
大模型知识蒸馏:核心是编写 Python 脚本调用大模型 API 进行问答生成。工具方面,EasyDataset 提供了便捷的界面,可指定主题(如“中国历史”)后自动构造问题并从大模型中蒸馏数据。
采集到的原始数据(尤其是网络爬虫数据)通常质量参差不齐,必须过滤掉低价值或有害内容,以保证训练数据的纯净度。
处理流程:
此步骤旨在识别并剔除广告、仇恨言论、大量无意义重复文本等低质量内容。公开数据集与蒸馏数据通常质量较高,可适度简化此步骤。
相关处理与工具推荐:
文本过滤通常需自行编写处理脚本,主要有以下三类方法:
过滤后的文本需进一步规范化,并去除冗余信息,以确保数据的一致性和高效性。
处理流程:
相关处理与工具推荐:
codecs 或 chardet 库进行自动检测与转换。此环节将清洗后的高质量原始文本,转换为大模型训练可直接使用的标准化数据格式。
处理流程与数据格式:
预训练数据集:格式通常为连续的纯文本块(json或jsonl 格式,每个对象包含一个 "text" 字段)。关键在于文本块的切分策略,需尽量保证知识单元的完整性(如按段落、章节切分)。可借鉴 RAG(检索增强生成)中知识库的文档切分算法。
监督微调(SFT)数据集:格式为对话或指令-回答对(多轮对话)。若需训练模型具备思维链(Chain-of-Thought)能力,数据中需包含推理过程(常置于 <think>...</think> 标签内,并将其和输出合并置于ouput字段)。
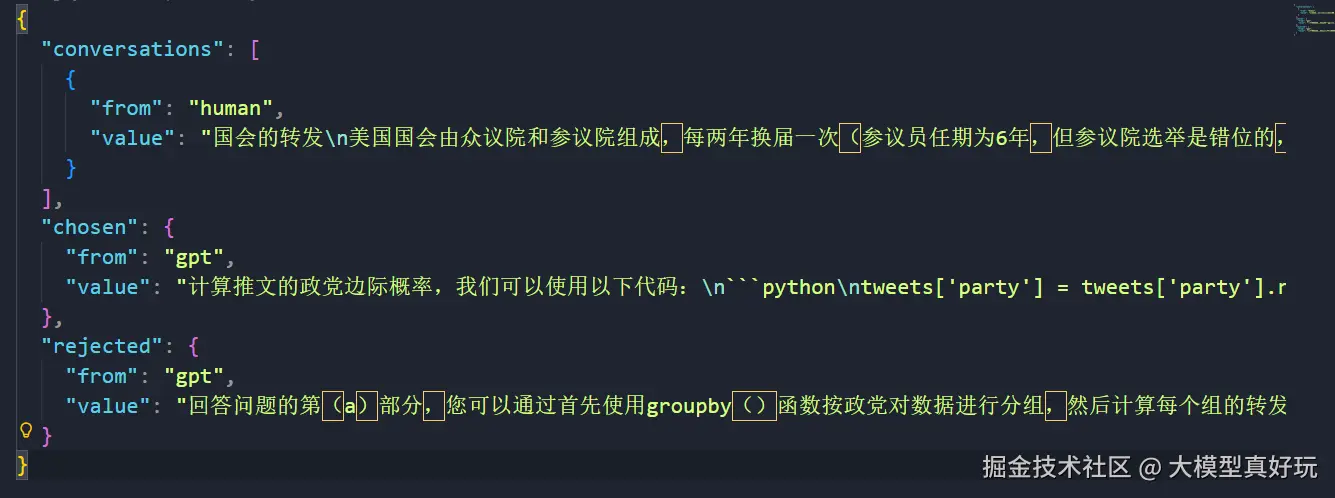
偏好对齐数据集:用于训练PPO算法中的关键奖励模型(RM)或进行 DPO/ORPO 训练。每条数据包含一个指令(或问题),以及一个被选中的(chosen)优质回答和一个被拒绝的(rejected)劣质回答。
相关处理与工具推荐:
EasyDataset 等工具辅助生成,或编写脚本调用大模型 API 批量合成。chosen, 实际生成的较差的回答作为rejected。数据质量是决定大模型性能上限的关键因素。在实际工作中,数据工程往往占据整个训练流程80%以上的精力。
对于领域适配或指令微调:推荐组合使用以下工具:
对于追求极致性能的精细优化:通常需要深入代码层面,进行数据合成增强、难度分级、负样本挖掘等更复杂的操作。相关高阶技巧与代码实践,将在本系列的扩展篇中详细展开。
与数据工程相比,训练工程阶段的工具链和标准化流程更为成熟。整个训练过程通常划分为三个核心且环环相扣的阶段:预训练、监督微调(SFT) 和 强化学习对齐(如RLHF) 。关于这三阶段的作用,笔者在 大模型训练全流程实战指南(一)——为什么要学习大模型训练?也基本提及过,笔者将其形象地比喻为 “培养一位超级学霸” 的过程:先海量阅读构建知识体系,再接受专业指导掌握方法,最后通过实践反馈优化言行。
预训练的核心目标,是将经过处理的海量文本数据中的语言规律和世界知识,“压缩”存储到大模型的参数中。在 大模型训练全流程实战指南基础篇(二)——大模型文件结构解读与原理解析中笔者提过大模型预测的本质是学习语言的概率分布:模型通过数十亿乃至数万亿的token,学会根据给定的上文预测下一个最可能的词,从而掌握语法、事实和基础推理能力。这相当于让模型“读完整个图书馆的书”,建立起对世界的通用认知框架。
对于希望获得领域专家的模型(如法律、医疗),直接从头预训练成本过高。更可行的路径是 增量预训练(Continued Pre-training) :在一个通用基座模型(如LLaMA、Qwen)基础上,使用领域专有数据(如法律条文、医学文献)继续训练。这能显著提升模型在特定领域的知识深度,但需注意可能伴随的 灾难性遗忘 问题——即模型在新领域变强的同时,可能损失部分原有通用能力。
预训练模型虽“学识渊博”,却不懂如何与人类交流。例如,当被问及“长江”时,它可能仅基于统计关联回答“黄河”,而非给出有用信息。监督微调(SFT) 正是为了解决“如何与人对话”的问题。此阶段使用 高质量的指令-回答对数据集,以有监督的方式训练模型,目标是:
这个过程好比让那位“学霸”进入实习期,由导师(高质量数据)手把手地教导其沟通礼仪、回答技巧与行为边界。在实际应用中,许多垂直领域模型会直接对通用基座模型进行SFT,以快速“激活”其在该领域的潜在能力,而跳过增量预训练阶段。
掌握了知识与方法后,还需要通过反馈机制来优化行为,使其更符合人类的主观偏好和价值判断。这便是强化学习对齐阶段的任务。
以主流的 基于人类反馈的强化学习(RLHF)为例,该阶段通常分为两步:
这如同为“实习生”配备了一位严格的实战教练,通过持续的练习与即时反馈,不断打磨其表现,直至其产出结果既专业又令人满意。
在工程实现上,模型训练主要分为两种路径,对应不同的开发深度与效率需求:
1. 底层研发式训练
适用于需要全新架构探索或深度定制的研究团队,通常是从0开发大模型的团队
2. 高效微调与一体化训练(推荐)
对于绝大多数基于现有模型进行适配的专用模型训练场景,使用高层框架可以极大提升效率。
单卡高效微调:Unsloth 是当前的性能标杆,专注于极致优化LoRA等参数高效微调技术。
一体化训练框架:
强化学习专用库:
最佳实践建议:
对于希望快速上手的开发者,推荐使用 LLaMA Factory 完成从数据准备到模型微调的全流程。本系列合作的实训平台 Lab4AI 已提供预置环境,可一键开启实践。对于有定制化强化学习需求的场景,可在VeRL或Easy-R1的基础上进行二次开发。
模型训练完成并非终点,科学、系统的评估是衡量模型能力、发现潜在缺陷并指导后续迭代的关键环节。评测工程的目标是全面回答一个问题: “训练的模型效果究竟如何?” 通常从两个层次分析模型的实际效果:自动化的基准测试与深入的人工评估,这就好像一个学生既要参加标准化的期末考试,也需要老师在期末的时候写评语。
自动评估通过一系列精心设计的标准化测试集和量化指标,对模型的各项能力进行快速、可重复的客观衡量。
自动化评测常用数据集:
以上测试集中既包含MMLU、C-Eval等一些专项知识的选择题,又包含GSM8K含标准答案的模型推理题以及Gaokao-Bench等主观求解题,全面评测模型的全部能力。
关键指标:
自动化测试虽高效,但难以完全捕捉模型在复杂、开放场景下的真实表现和细微缺陷。人工深入评估不可或缺,它侧重于:
此阶段通常由领域专家或标注团队,通过设计多样化的真实用户场景(如客服对话、创意写作、分析报告)进行系统性测试和主观评分。
目前主流的开源评测工具已经极大地提升了评估效率。
综合来看,虽然 OpenCompass 在基准评测的广度上排名No.1,但对于追求从研发到上线全链路质量管控的团队而言,更推荐将 EvalScope 作为评测阶段的工具,EvalScope不仅可以快速集成OpenCompass后台,还具备模型服务压力测试等额外功能,适合全面的分析评测。
本篇内容系统分享了大模型训练三大核心阶段(数据工程、训练工程、评测工程)的全流程,为每个环节推荐了如EasyDataset、LLaMA Factory、EvalScope等关键实用工具,旨在帮助读者构建清晰的训练路径。
从下期内容开始,笔者将分享这些工具的详细使用指南,首先分享OCR工具的相关知识,看看我们是如何把大家爬取的文档识别为统一的markdown格式,大家敬请期待!
大模型训练对计算资源有一定要求,尤其是GPU显存。为降低学习门槛,笔者与国内主流云平台合作,大家可以通过打开链接: Lab4AI ,体验H100 GPU 6.5小时的算力。本系列所有实战教程均将在该平台上完成,帮助大家低成本上手实践。
除大模型训练外,笔者也在同步更新《深入浅出LangChain&LangGraph AI Agent 智能体开发》免费专栏,要说明该专栏适合所有对 LangChain 感兴趣的学习者,无论之前是否接触过 LangChain。该专栏基于笔者在实际项目中的深度使用经验,系统讲解了使用LangChain/LangGraph如何开发智能体,目前已更新 37 讲,并持续补充实战与拓展内容。欢迎感兴趣的同学关注笔者的掘金账号与专栏,也可关注笔者的同名微信公众号大模型真好玩,每期分享涉及的代码均可在公众号私信: LangChain智能体开发免费获取。

