女生做蛋糕甜品屋宝宝
105.50M · 2026-04-17

Redis 的 Zset 同时具备两个核心特性:
为了实现这种高效的、兼具“集合”和“有序”特性的数据结构,Redis 采用了两种底层数据结构相结合的方案:
这种根据条件动态切换底层结构的设计,体现了 Redis 在性能与内存之间做出的精妙权衡。
在 Redis 内部,Zset 有两种编码方式,通过配置项 zset-max-ziplist-entries 和 zset-max-ziplist-value 来控制。
在 Redis 早期版本使用 ziplist,新版本(7.0+)逐渐用 listpack 替代 ziplist。我们以 listpack 为例讲解。
适用条件(同时满足):
zset-max-ziplist-entries (默认 128)。zset-max-ziplist-value (默认 64 字节)。内存布局:
listpack 是一个紧凑的、连续内存块,它按 [member1, score1, member2, score2, ...] 的顺序,成对存储成员和分值。
目的:在元素少且小的场景下,这种结构避免了额外的指针开销,极大地节约了内存。
当不满足上述任一条件时,Zset 会自动转换为 skiplist 编码。这才是 Zset 的“完全体”和核心实现。
它实际上是一个 复合结构,包含一个 跳跃表(skiplist) 和一个 字典(dict) 。
typedef struct zset {
dict *dict; // 哈希字典
zskiplist *zsl; // 跳跃表
} zset;
如果只用跳跃表,查询成员分值需要 O(logN)。
如果只用字典,无法进行高效的范围操作。
因此,这种 “空间换时间” 的设计,让 Zset 既能快速进行单点查询,又能高效进行范围操作,是工程上的经典取舍。
跳跃表是一种多层级的有序链表,是平衡树的一种概率替代方案,实现更简单,在并发环境下也更有优势。
结构:
typedef struct zskiplist {
struct zskiplistNode *header, *tail; // 头尾指针
unsigned long length; // 节点总数
int level; // 当前最大层数
} zskiplist;
typedef struct zskiplistNode {
sds ele; // 成员(SDS字符串)
double score; // 分值
struct zskiplistNode *backward; // 后向指针(L0层,用于逆序)
struct zskiplistLevel {
struct zskiplistNode *forward; // 该层的前进指针
unsigned long span; // 该层到下一个节点的跨度(用于排名)
} level[]; // 柔性数组,表示节点的层级
} zskiplistNode;
关键特性:
level 数组长度即为层高。score 排序,score 相同时,按 ele 的字典序排序。score 小于目标(或 score 相等但 ele 小于目标)的节点,然后下降一层继续。如此反复,直到第0层。这个过程时间复杂度平均 O(logN)。level[i].span 记录了从当前节点到 level[i].forward 节点之间,跨越了第0层的多少个节点。这是 ZRANK 命令(获取排名)能够 O(logN) 完成的关键。计算排名时,只需将搜索路径上所有符合方向的跨度累加即可。ZREVRANGE 等逆序操作。就是一个标准的 Redis 哈希表,其作用是:
假设我们执行 ZADD myzset 10 “alice” 20 “bob” 30 “charlie”。
在 skiplist 编码下,内存结构示意图如下:
zset
/
dict zskiplist (header)
| (level=5)
"alice" -> 10 |
"bob" -> 20 |
"charlie"-> 30 V
+-------+-------+-------+
| Span | ... | Span | (高层,稀疏指针,快速跳跃)
+-------+-------+-------+
| |
V V
+-------+-------+-------+
| score | ele | level | -> Node(10, "alice")
| 10 |"alice"| 2 |
+-------+-------+-------+
| |
V (L0) V (L1)
+-------+-------+-------+-------+-------+-------+
| score | ele | level | score | ele | level | -> Node(20, "bob")
| 20 |"bob" | 3 | 20 |"bob" | 3 |
+-------+-------+-------+-------+-------+-------+
| |
V (L0) V (L1)
+-------+-------+-------+-------+-------+-------+
| score | ele | level | score | ele | level | -> Node(30, "charlie")
| 30 |"char" | 1 | 30 |"char" | 1 |
+-------+-------+-------+-------+-------+-------+
|
V (L0)
NULL
关键操作如何工作:
dict 中查找键 "bob",立即返回其值 20。O(1) 。zskiplist 的 header 出发,利用高层指针快速定位到起始节点("bob"),然后沿低层指针遍历输出。O(logN + M) ,M为返回元素个数。zskiplist 的 header 出发,搜索 "charlie" 的路径,同时累加沿途的 span 值。最终得到的累加和就是其排名(从0开始)。O(logN) 。dict 中检查 "david" 是否存在(保证唯一性)。zskiplist 中执行标准的跳表插入操作(O(logN)),找到插入位置。dict 中插入 "david" -> 15 的键值对。下面这个序列图展示了当执行 ZRANGE myzset 1 3 命令时,Redis 内部不同组件之间的交互流程:
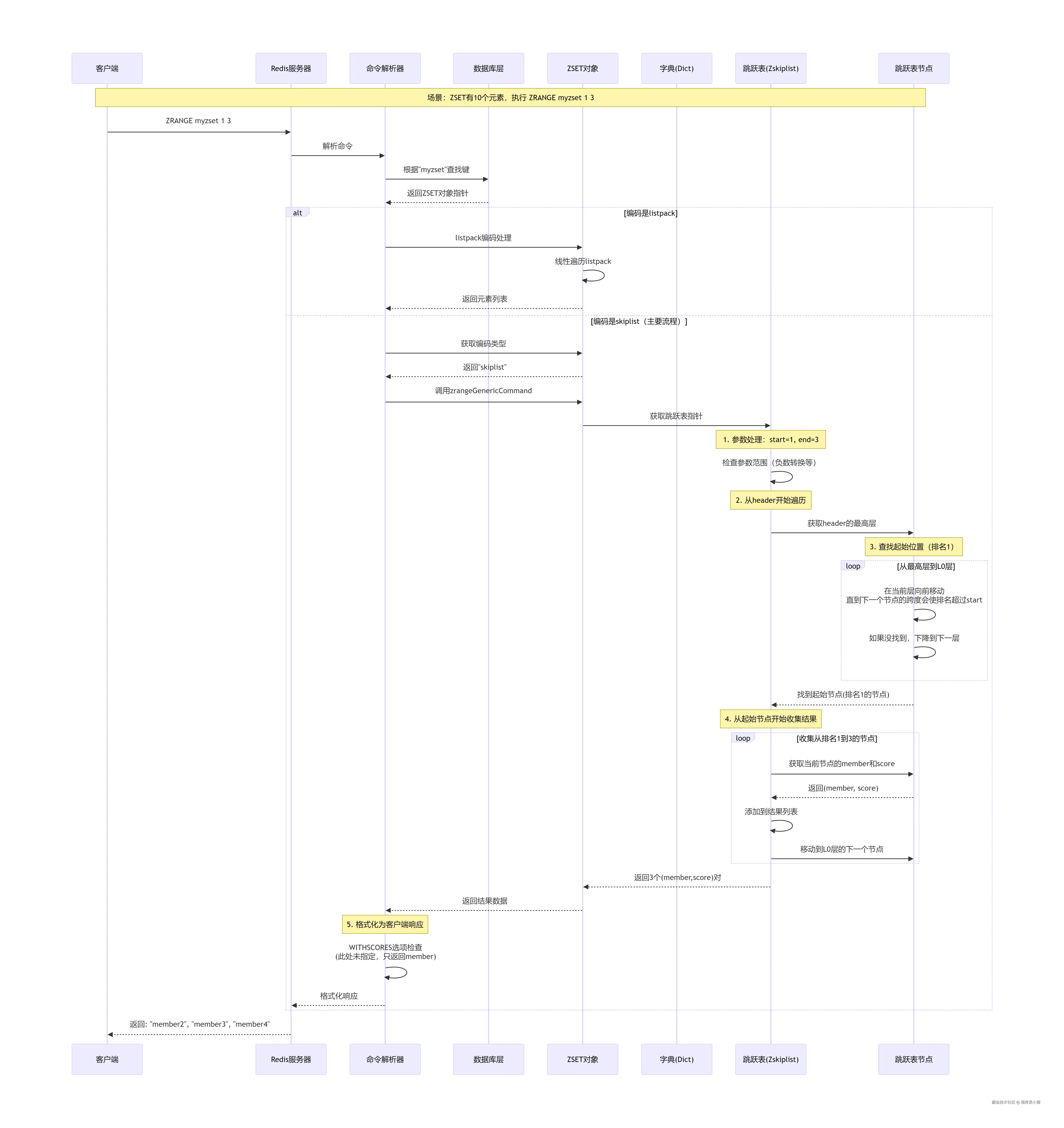
skiplist + dict 是 Zset 的灵魂。skiplist 负责排序和范围操作,dict 负责快速单点访问。二者通过共享成员和分值的指针来保证数据一致性,没有冗余存储。它的底层实现其实采用了两种数据结构相结合的 ‘混合’策略,目的是在内存使用和性能之间取得一个平衡。具体来说,它同时使用了:
这两种结构会共享集合中元素(成员)和分数(分值)的数据,但通过指针引用,所以不会造成双倍的内存开销。
为什么需要两种结构呢?
这主要是为了应对 Zset 不同的操作场景,让它们都能非常高效:
所以,简单来讲,可以把 Zset 想象成 一个用哈希表做‘索引’,用跳跃表做‘排序清单’的组合体。哈希表保证了点查的极致速度,跳跃表保证了范围操作的效率。
不过,在 Redis 的后续版本中(我记得是 7.0 之后),为了进一步节省内存,还有另一种编码方式,叫 Ziplist(紧凑列表)。
ziplist 来存储。在这个链表里,成员和分数是挨个交替存放的,它因为少了跳跃表和哈希表的结构开销,所以非常节省内存。总结一下,我的理解是:
Zset 的底层会根据数据规模灵活选择:
ziplist。
