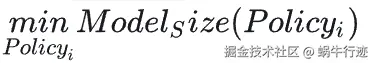
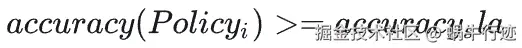
以观书法
108.85M · 2026-02-05

因为嵌入式设备的算力和内存有限,因此深度学习模型需要经过模型压缩后,方才能部署到嵌入式设备上。
模型压缩问题的定义可以从 3 角度出发:
FLOPs),降低[延迟](Latency)GPU/NPU 计算利用率我们知道,一定程度上,网络越深,参数越多,模型也会越复杂,但其最终效果也越好,而模型压缩算法是旨在将一个庞大而复杂的预训练模型转化为一个精简的小模型。
按照压缩过程对网络结构的破坏程度,《解析卷积神经网络》一书中将模型压缩技术分为“前端压缩”和“后端压缩”两部分:
知识蒸馏、轻量级网络(紧凑的模型结构设计)以及滤波器(filter)层面的剪枝(结构化剪枝)等;低秩近似、未加限制的剪枝(非结构化剪枝/稀疏)、参数量化以及二值网络等,目标在于尽可能减少模型大小,会对原始网络结构造成极大程度的改造。总结:前端压缩几乎不改变原有网络结构(仅仅只是在原模型基础上减少了网络的层数或者滤波器个数),后端压缩对网络结构有不可逆的大幅度改变,造成原有深度学习库、甚至硬件设备不兼容改变之后的网络。其维护成本很高。
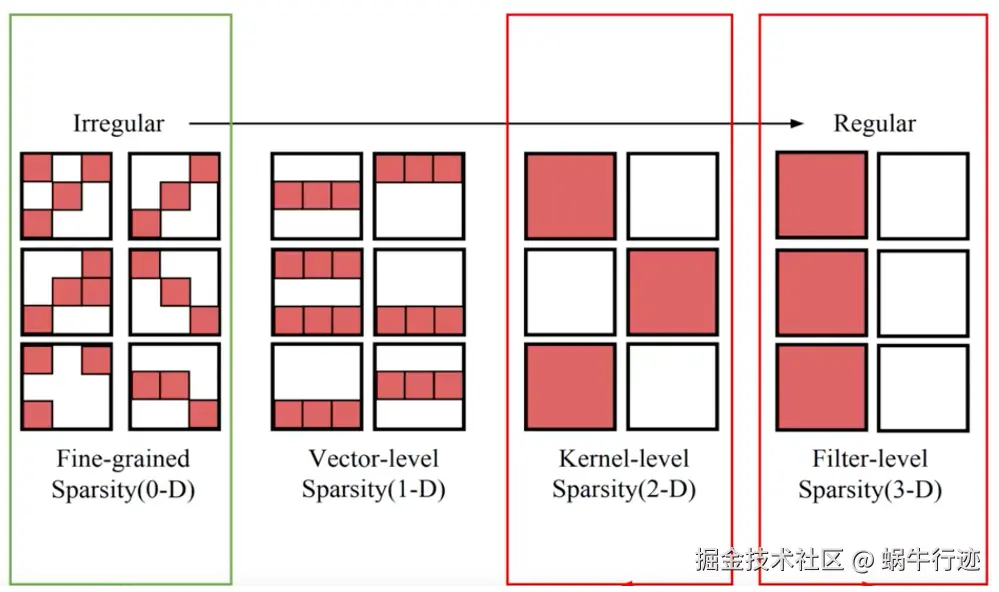
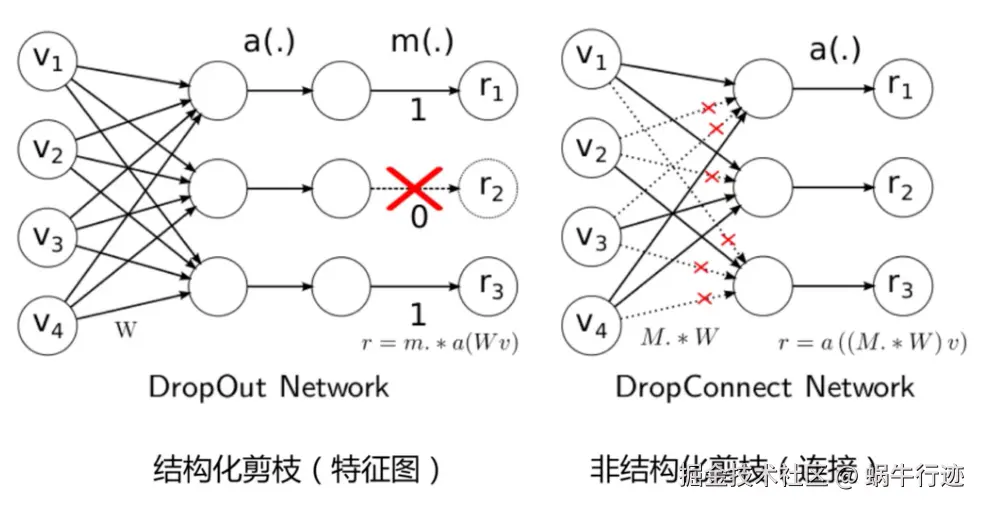
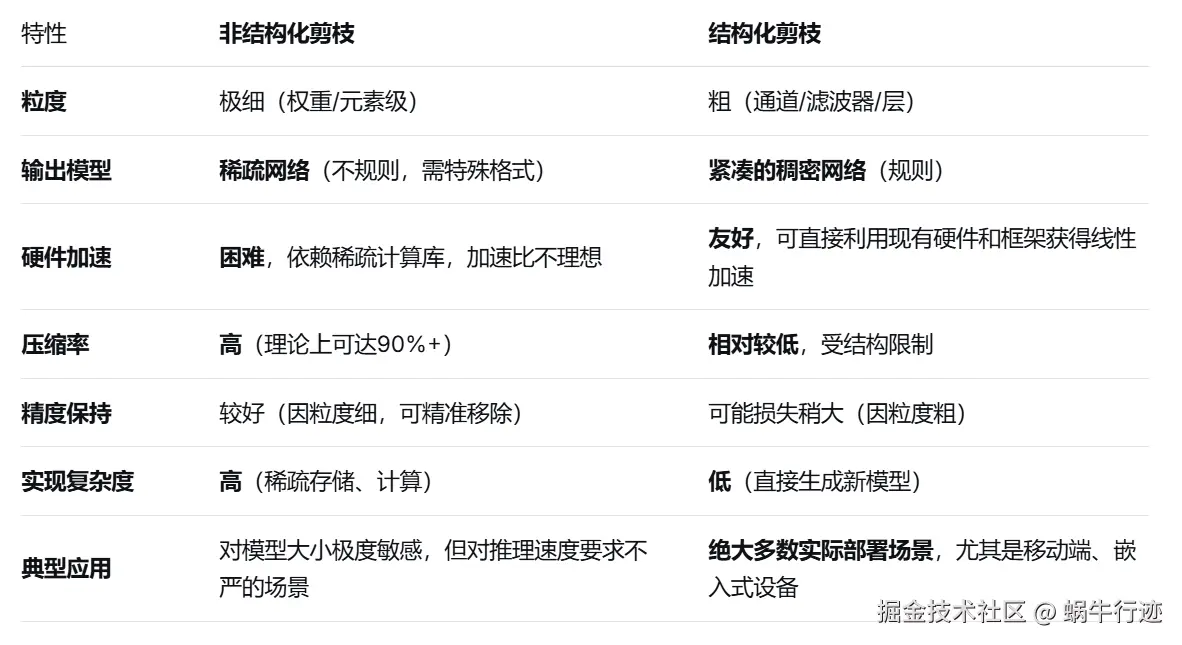
“四个级别”是理解剪枝技术的关键维度,从最精细到最粗粒度排列。
剪枝的核心思想是:移除神经网络中冗余或不重要的参数(权重)或结构,在保持模型性能基本不变的前提下,减小模型大小、降低计算复杂度和内存占用,从而提升推理速度。
删除权重小于一定阈值的连接或者神经元节点得到更加稀疏的网络
核心思想:移除网络中个别不重要的权重(即将其置为零),形成稀疏的权重矩阵。
特点:
典型方法:
(1)权重剪枝((Fine-gained) sparsity 0-D):直接根据权重的绝对值(L1范数)或梯度信息,剪掉值接近零的权重。
(2)神经元剪枝:可以被视为一种特殊的非结构化剪枝,通过移除某个神经元的所有输入和输出连接来实现,但其效果等同于移除整个神经元。
核心思想:移除整个结构化的组件(如通道、滤波器、层),从而直接改变网络的宏观架构,产生一个更小、更紧凑的稠密模型。
特点:
典型方法(从细到粗):
主要针对卷积神经网络。移除特征图中的整个通道。例如,一个形状为 [C_out, C_in, K, K] 的卷积核,若移除其输入通道 C_in 中的第 i 个,则对应所有滤波器的第 i 个通道都被移除;若移除输出通道 C_out 中的第 j 个,则整个第 j 个滤波器被移除。
可以看作是通道剪枝的特例,直接移除整个滤波器(即输出通道)。这会减少下一层输入通道的数量,因此需要同步剪掉下一层卷积核的对应输入通道。
粒度最粗。直接移除网络中的整个层(例如,残差网络中的某些残差块)。这需要模型本身有一定冗余深度,并且对网络拓扑结构影响较大,需谨慎设计。
无论哪种剪枝粒度,一个完整的剪枝流程通常包含以下核心步骤:
预训练:首先在目标任务上训练一个大型的、过参数化的模型,直至收敛。
重要性评估:这是剪枝的核心决策环节。定义一个标准来判断哪些参数或结构是“不重要”的。
常用准则:
剪枝:根据评估准则和预设的剪枝比例(全局或逐层),移除不重要的部分。
微调/再训练:对剪枝后的模型进行重新训练,以恢复损失的精度。这是一个“剪枝-微调”的迭代过程,可以重复多次。
部署:将剪枝后的小模型部署到目标设备上。
自动化与联合优化:
硬件协同设计: 设计支持高效稀疏计算的专用AI芯片(如某些NPU),以释放非结构化剪枝的潜力。
更优的重要性评估准则: 超越简单的范数判断,采用基于Hessian矩阵的二阶信息、基于影响力的分析等更精确的评估方法。
大语言模型的剪枝: LLMs参数量巨大,对其进行的结构化剪枝(如注意力头、FFN中间维度的剪枝)是当前研究热点。

