锦书在线
80.52M · 2026-03-21

随着座舱屏幕数量和算力趋近用户感知上限,智能座舱的竞争焦点正由硬件堆叠转向智能体验。真正的变革在于座舱系统能否成为贴心伙伴——不仅能听懂指令,更能理解意图;不仅能识别环境,更能洞察场景;不仅能执行操作,更具情感共鸣与主动服务能力。
纵观智能座舱的发展脉络,行业正经历从早期的功能集成 (将导航、音乐、车控等功能汇集一屏),到当前的场景服务 (如“会议”“小憩”“长途”等模式),再到综合情感交互的三阶段演进。未来的智能座舱将具备情景理解、全乘客意图判断与主动服务能力,真正成为有温度、有智慧、懂用户的舱内智能空间。而实现这一目标,需要在车端计算单元部署更强大的多模态、全模态 AI,并克服以下核心挑战:
同时,这些挑战会催生出下一代舱内 AI 智能体的关键场景:
面向 L2+/L3/L4 的高动态人机交互式共驾:系统根据驾驶员及乘客的乘车目的、路况复杂度、舱内场景状态、驾驶员专注度,动态调整交互策略和信息呈现方式,从而实现“不想回家,去看电影”“去一家我喜欢口味的餐厅”等丝滑驾舱体验。
一、框架概述
NVIDIA TensorRT Edge-LLM 是专为边缘端大模型部署打造的轻量级推理框架,面向智能汽车等实时端侧应用场景。框架针对边缘部署的核心诉求进行了深度优化:
二、核心特性
| 特性 | 核心价值 |
| 纯 C++ 运行时 | 开源代码,依赖极少,易于集成与生产部署 |
| 超轻量化设计 | 专注嵌入式场景,资源占用最小化 |
| 高性能计算 | 优化的 CUDA 内核与 TensorRT 集成,实现最大吞吐量 |
| 高级能力 | 支持投机解码、NVFP4 等量化、动态 LoRA 切换,先进的 KV 缓存管理等特性 |
| 统一工具链 | 同一推理工具链适用于 NVIDIA Drive AGX、Jetson 及 MediaTek Dimensity Auto 座舱平台 |
更多技术细节请参考:TensorRT Edge-LLM 技术文档
三、开源意义
NVIDIA 在 GPU 计算领域深耕多年,依托 CUDA、TensorRT 等核心技术构建了成熟的 AI 开发生态,已成为业界事实标准。此次开源 TensorRT Edge-LLM,正是将这一生态优势向边缘端延伸的重要举措。
开源将带来多重价值:一方面,统一的技术规范能够有效降低车企等端侧厂商的开发门槛与适配成本;另一方面,也为 AI 模型厂商提供了标准化的适配路径,使模型能够更便捷地部署至边缘设备,加速商业化落地。此外,代码透明有助于提升安全可审计性,更好地满足生产环境的合规要求;开放的社区模式也将汇聚全球开发者持续贡献,推动技术快速迭代演进。
通过 TensorRT Edge-LLM 的开源,NVIDIA 旨在进一步完善从云到端的全栈 AI 生态,让开发者从复杂的底层优化中解放出来,更专注于上层应用创新,助力智能汽车等端侧行业加速迈向智能化。 欢迎访问开源社区参与贡献:TensorRT Edge-LLM GitHub
TensorRT Edge-LLM 为车载边缘AI提供了高性能、轻量化、纯 C++ 的推理运行时,是构建车规级推理系统的重要基础。基于该运行时,中科创达进一步构建了面向座舱业务的多模态 AI 服务架构,将底层推理能力封装为可调度、可扩展的系统服务。
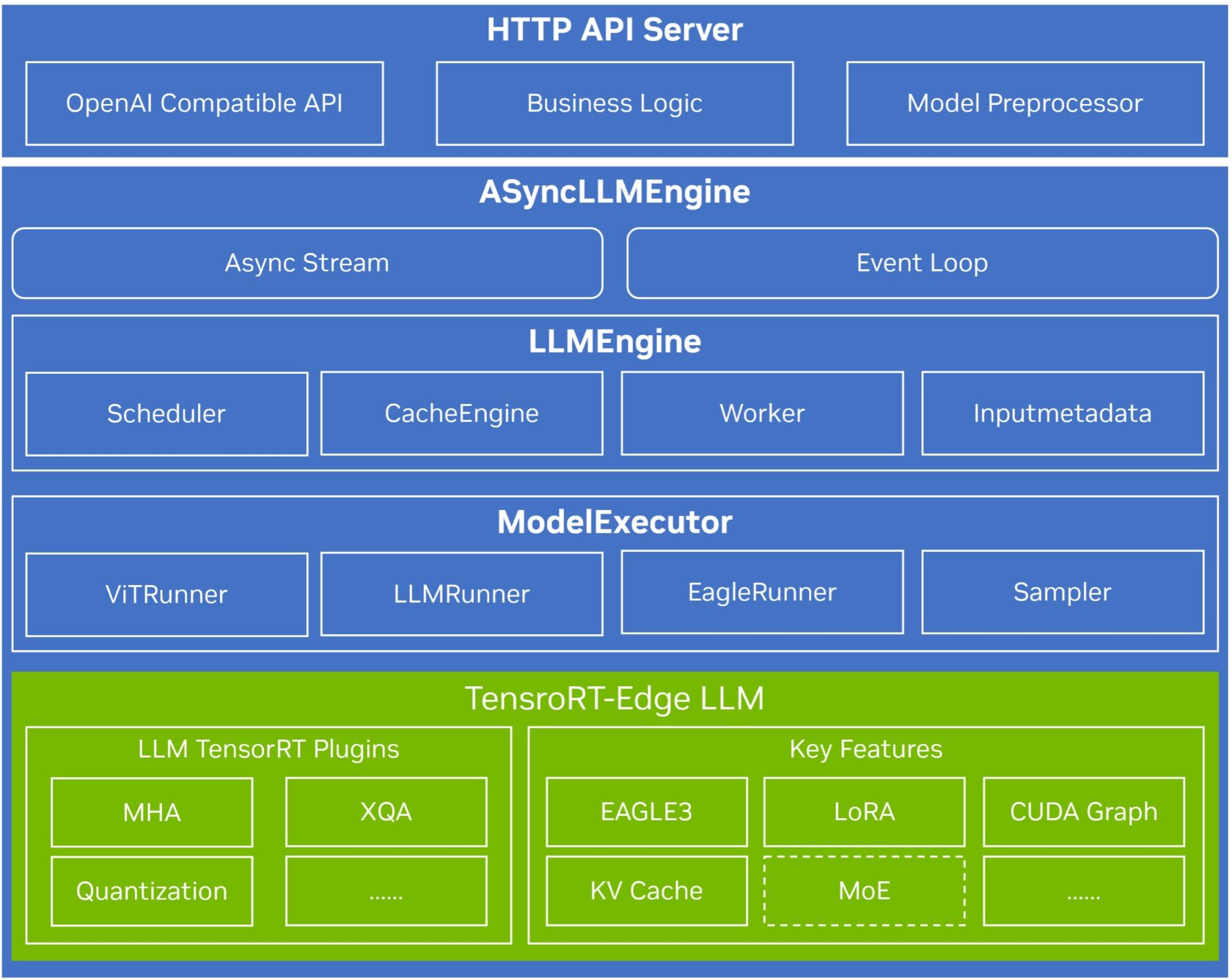
一、该架构特点
构建统一的推理后端抽象层,实现从特定平台推理框架到 TensorRT Edge-LLM 的平滑迁移,显著降低底层适配成本,提升整体开发效率。
在平台层提供标准化的模型定义与接入机制,使新模型能够快速完成适配、部署与调优,避免为每个模型重复进行工程开发,加速多模型在座舱场景中的规模化应用。
二、客户合作案例
案例 A:重构 AI 座舱交互——基于 NVIDIA DRIVE AGX Orin 的端侧算力与优化视觉大模型融合实践
基于 DRIVE AGX Orin 平台,中科创达与某头部车企携手,成功打造并全球首发了新一代 AI 座舱。其核心成果在于:充分利用 DRIVE AGX Orin 平台的极致AI算力,深度融合经中科创达深度优化的本地 Qwen2.5-VL-7B 视觉大模型,真正兑现了“AI 座舱”的感知与决策能力,并将关键 AI 场景的端到端推理延迟降至业界领先水平,为用户带来颠覆性的瞬时响应体验。
性能成果:将关键 AI 场景的端到端推理延迟降至秒级——AI增强哨兵场景 2.6s,AI迎宾场景 0.6s,下车安全场景 0.7s,停车记忆场景 0.8s。
行业突破:中科创达成功解锁了 AIBOX (DRIVE AGX Orin) A 样的量产能力,实现了全球首次交付。这一里程碑标志着 AI 座舱相关智能场景进入了新的发展阶段。
案例B:面向下一代车载自然交互的端侧大模型记忆实践
中科创达与某全球头部车企合作的 Innovation Project 中,在车规级高性能 AI 算力底座上,部署并深度优化了 Qwen3-VL-4B 视觉语言模型,使其满足车载环境的苛刻要求。基于此,成功实现了“长聆听” (Long-Context Listening) 与“端侧主动记忆” (On-Device Proactive Memory) 两大原型功能,为探索无界面的自然交互奠定了基础。
三、核心价值
基于 DRIVE AGX Orin 的强大算力以及 TensorRT Edge-LLM 优秀的推理任务调度管理方案,实现端侧人人对话、主动记忆、Non-workflow 的智能任务编排范式,与客户共同探索车载 AI 场景技术的创新能力边界。
智能座舱的竞争已经进入下半场,决胜的关键不再是单纯的配置堆叠,而是考验在严苛车规级环境下能否提供稳定、高效且确定性的用户体验输出。此外,智能座舱的演进从来不是单点技术的突破,而是完整生态系统的协同进化升级。在这一关键进程中,NVIDIA 和中科创达基于各自的核心能力,形成了深度互补的合作,共同为行业提供从底层算力到上层应用的全栈解决方案。NVIDIA 开源的 TensorRT Edge-LLM 框架将专业级边缘AI推理能力全面开放给开发者,而中科创达则凭借深厚的座舱软件全栈能力,将TensorRT Edge-LLM 深度集成至座舱AI系统,将AI能力封装为智能且可复用的场景服务模块,从而共同推动智能座舱进入“AI 定义”时代。
面向未来,双方将合作聚焦于三个维度:基于量产数据和用户反馈持续优化 DRIVE 平台上的性能表现;共同开发支持个性化服务与座舱 AI Agent 框架;为车企提供从模型选型、量化优化到 Agent 部署集成的完整工具链与参考框架,助力打造可持续进化的AI定义座舱。中科创达非常期待通过 NVIDIA 开放的底层能力与中科创达成熟的集成经验,与更多开发者共同创建创新可靠的智能汽车软件生态,真正实现从功能定义到AI定义的范式变革。
获取核心框架、工具链以及模型部署示例:

