女生做蛋糕甜品屋宝宝
105.50M · 2026-04-17

我将会通过 Java 源码,看在 Java 的底层是怎么实现多线程的,以及 Java 中实现多线程与操作系统中的多线程的异同点
在 OS 的学习中我们能够知道,绝大部分重要的功能不会让用户进程使用
JVM 是一个运行在 OS 上的进程,当 JVM 中需要进行多线程操作时,自己又没有这个权限,所以只能通过请求 OS 来创建线程
根本原因是因为 JVM 运行的环境处于用户态,而创建线程需要内核态进行创建
在 Java 中创建多线程只需要 new 一个线程,然后让该线程启动起来。
public class Main {
public static void main(String[] args) {
Thread thread1 = new Thread(() -> {
System.out.println("这里是线程 --- 1");
});
thread1.start();
}
}
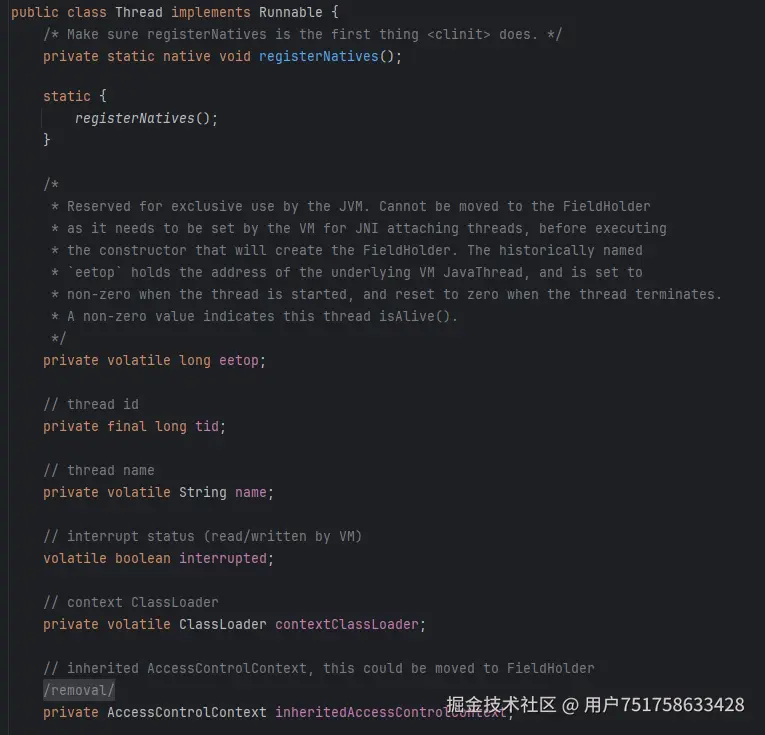
这里是 Java 中线程对应的源码,如果你学习过操作系统那么你会对此感到熟悉,这不就是 OS 中线程(TCB)对应的“属性”吗?
操作系统创建线程需要设置的部分字段在 Java 中也能看见,
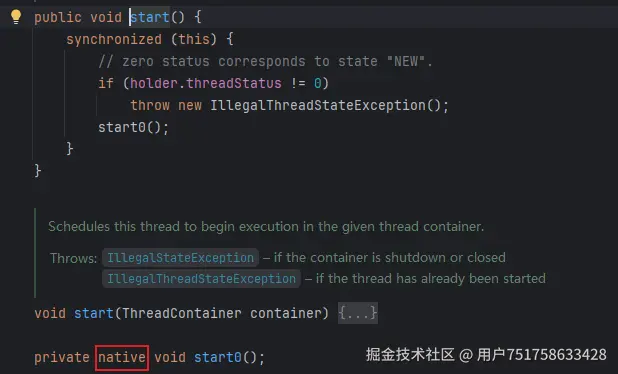
我们能看到 Java 底层的 start 是使用了系统调用
我们知道 JVM 的底层是调用了 C 和 C++ 的代码,所以我们需要再深入一点
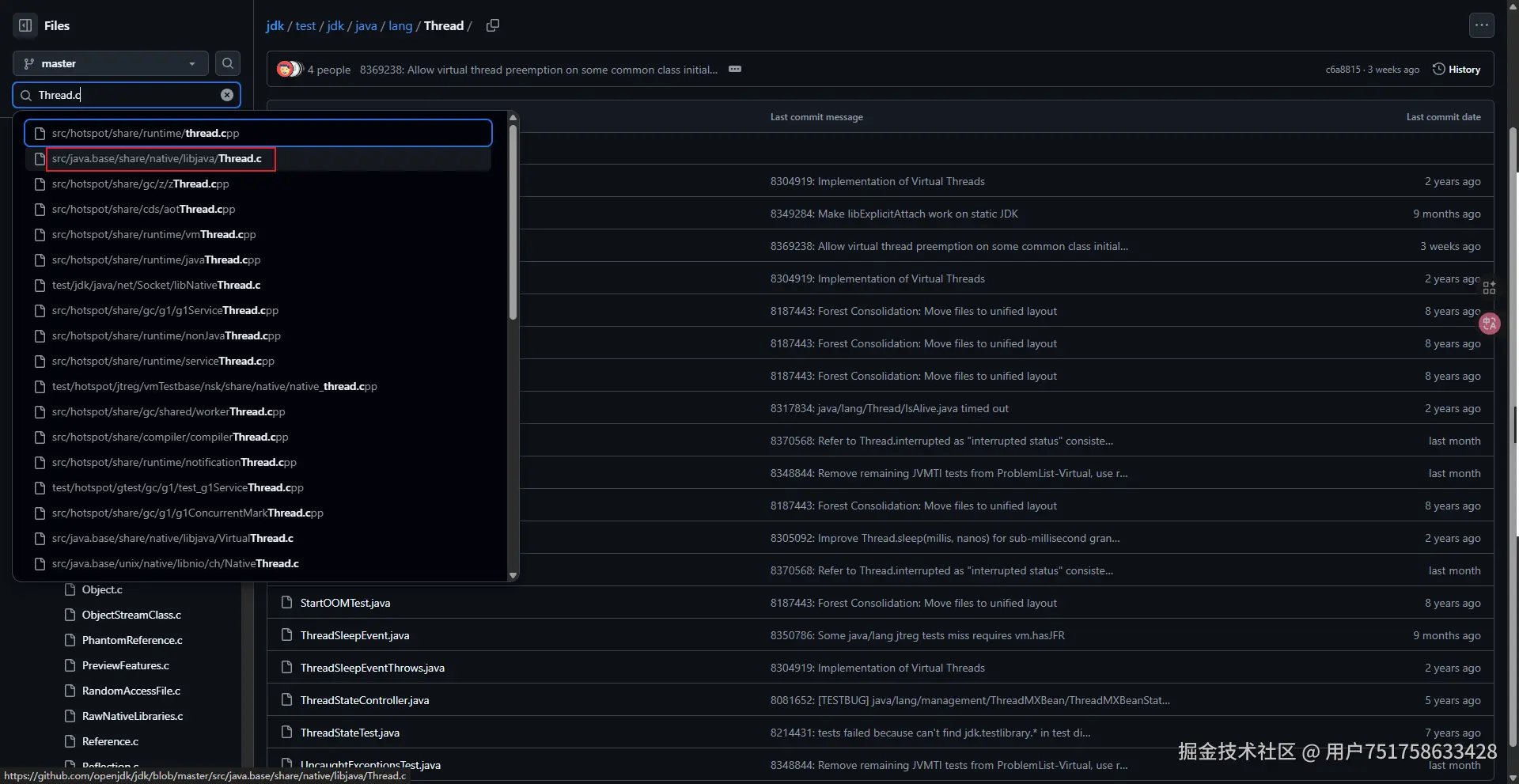
我进入了 Open JDK
我们需要找到 native 包下的 Thread 文件,后缀为 .c 或者 .cpp
第一部分中我们能发现这里有一张方法表, Java 调用的方法在这里对应着 C 或 C++ 的方法,在 Java 底层就是通过 C 或 C++ 去请求 OS 内核级对线程进行操控
这段代码的作用是“建立映射关系”。它告诉 JVM:“如果在 Java 里调用了 start0,请你去找 C 代码里的 JVM_StartThread 函数执行。” 这就是 JNI (Java Native Interface) 的桥梁作用。
static JNINativeMethod methods[] = {
{"start0", "()V", (void *)&JVM_StartThread},
{"setPriority0", "(I)V", (void *)&JVM_SetThreadPriority},
{"yield0", "()V", (void *)&JVM_Yield},
{"sleepNanos0", "(J)V", (void *)&JVM_SleepNanos},
{"currentCarrierThread", "()" THD, (void *)&JVM_CurrentCarrierThread},
{"currentThread", "()" THD, (void *)&JVM_CurrentThread},
{"setCurrentThread", "(" THD ")V", (void *)&JVM_SetCurrentThread},
{"interrupt0", "()V", (void *)&JVM_Interrupt},
{"holdsLock", "(" OBJ ")Z", (void *)&JVM_HoldsLock},
{"getThreads", "()[" THD, (void *)&JVM_GetAllThreads},
{"dumpThreads", "([" THD ")[[" STE, (void *)&JVM_DumpThreads},
{"getStackTrace0", "()" OBJ, (void *)&JVM_GetStackTrace},
{"setNativeName", "(" STR ")V", (void *)&JVM_SetNativeThreadName},
{"scopedValueCache", "()[" OBJ, (void *)&JVM_ScopedValueCache},
{"setScopedValueCache", "([" OBJ ")V",(void *)&JVM_SetScopedValueCache},
{"getNextThreadIdOffset", "()J", (void *)&JVM_GetNextThreadIdOffset},
{"findScopedValueBindings", "()" OBJ, (void *)&JVM_FindScopedValueBindings},
{"ensureMaterializedForStackWalk",
"(" OBJ ")V", (void*)&JVM_EnsureMaterializedForStackWalk_func},
};
第二部分中我们能发现,创建线程的代码的过程中,JVM 请求创建线程会被这里转发给 OS
JNIEXPORT void JNICALL
Java_java_lang_Thread_registerNatives(JNIEnv *env, jclass cls)
{
(*env)->RegisterNatives(env, cls, methods, ARRAY_LENGTH(methods));
}
JNIEXPORT void JNICALL
Java_java_lang_Thread_clearInterruptEvent(JNIEnv *env, jclass cls)
{
#if defined(_WIN32)
// Need to reset the interrupt event used by Process.waitFor
ResetEvent((HANDLE) JVM_GetThreadInterruptEvent());
#endif
}
以下是更进一步的创建线程的代码
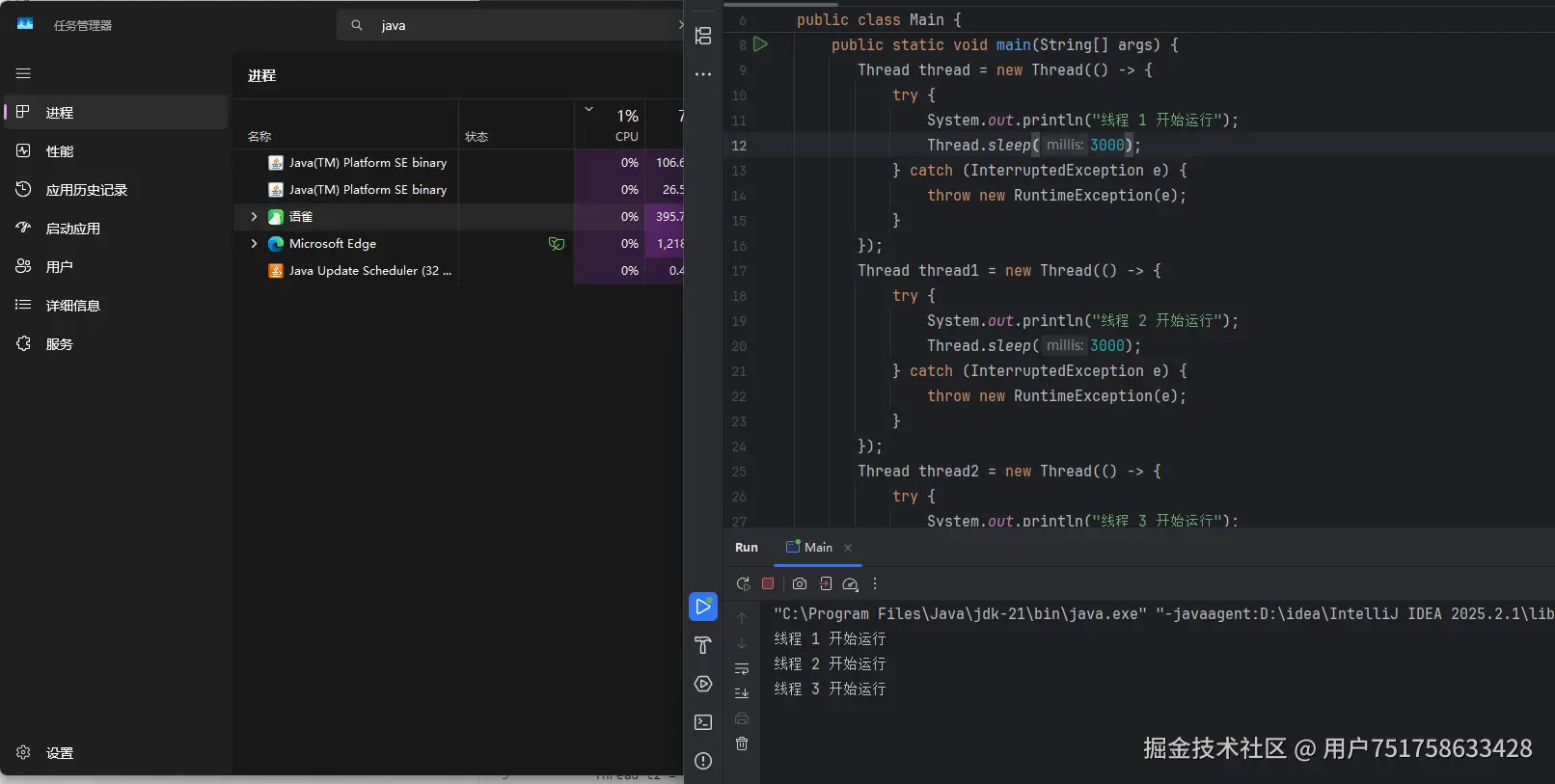
如下图,当程序运行时 OS 会为 Java 创建对应的线程,这个变化可以在控制台中观察到
从源码中设置线程对应的代码中我们能知道,在 Java 中会为新创建的线程设置类似于 OS 中那样的属性,例如 tid,这是每个 TCB 的身份证号。
但是 Java 中设置的 tid 不会被 OS 采纳。 操作系统(OS)完全不知道、也不关心 Java 层面的 tid 是多少。
OS 有自己的分配机制。 OS 会按照内核的规则生成一个 Native Thread ID(比如 Linux 下的 LWP ID),这与 Java 的 tid 是两码事。
Java 设置 tid 是为了 JVM 内部的管理、跨平台抽象以及生命周期维护。
就像是在 JVM 中存在一张映射表,让 JVM 中的每一个线程都能对应 OS 中的每一个线程。
为什么 JVM 内部还要设置一个 TCB?
Java 层面的 TID (Thread.getId())
OS 层面的 TID (Native ID / LWP ID)
在现代的主流 JVM(如 HotSpot)中,采用的是 1:1 线程模型。
你可以通过命令验证这一点:
使用 jstack 查看线程堆栈,你会看到类似这样的信息:
code Text
"main" #1 prio=5 os_prio=0 tid=0x00007f... nid=0x1b03 runnable ...
这是关键所在,主要有以下几个原因:
A. 跨平台抽象 (Write Once, Run Anywhere)
Java 的核心承诺是跨平台。
如果 Java 直接暴露 OS 的 ID,那么 Java 代码在不同系统上运行时,ID 的类型和范围就会不一致,破坏了跨平台性。Java 定义自己的 long 类型 tid,保证了无论底层是 Linux、Windows 还是 macOS,开发者看到的都是一个标准的 Java ID。
B. 生命周期不一致 (Lifecycle Mismatch)
如果在 start() 之前没有 ID,那么在线程启动前的准备阶段(设置上下文、配置参数)就无法唯一标识这个线程对象。此外,当线程运行结束(Terminated),OS 线程会被回收,但 Java 的 Thread 对象可能还在堆内存中(只要有引用指向它),此时它仍然需要一个 ID 来保持身份。
C. 虚拟线程 (Virtual Threads / Project Loom)
这一点在 JDK 21+ 尤为重要。
Java 引入了 虚拟线程。虚拟线程是非常轻量级的,可能有成千上万个虚拟线程复用同一个 OS 线程(Platform Thread)。
D. 错误追踪与日志
JVM 的异常堆栈(Stack Trace)和日志需要清晰的标识。使用连续的、可读性强的 Java tid(从 1 开始递增)比使用 OS 随机分配的、大数字的 nid 对开发者更友好。
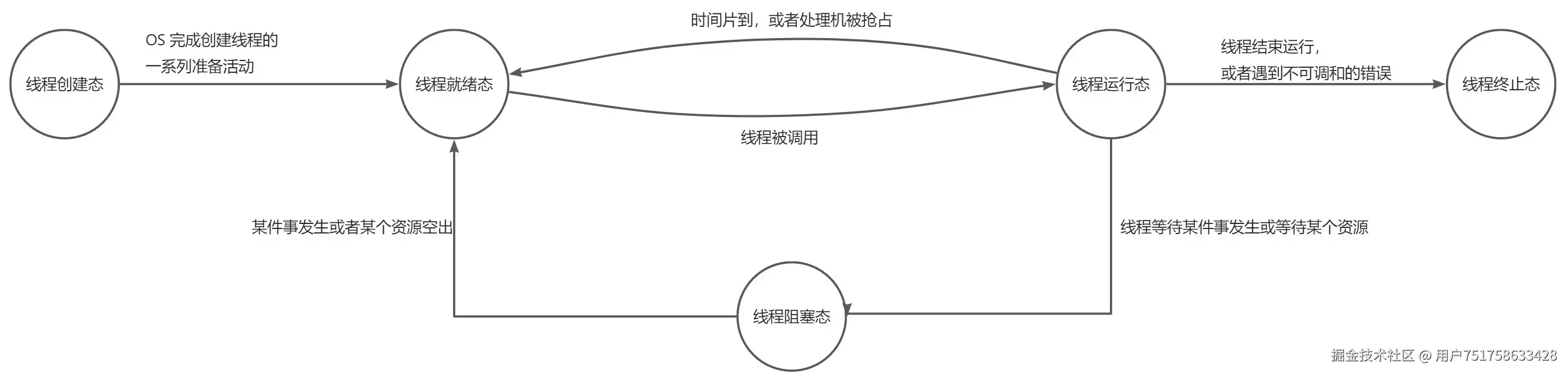
在操作系统中我们能知道,线程的生命周期:
用 Java 代码来对线程状态与转换进行实现
public class Main {
public static void main(String[] args) throws InterruptedException {
Thread t2 = new Thread(() -> {
try {
Thread.sleep(5000);
} catch (InterruptedException ignored) {
}
});
System.out.println("1. 刚 new 出来: " + t2.getState()); // NEW
t2.start();
System.out.println("2. start 之后: " + t2.getState()); // RUNNABLE
Thread.sleep(1000); // 主线程睡一下,让子线程有机会跑
System.out.println("3. 子线程 sleep 时: " + t2.getState()); // TIMED_WAITING
}
}
其中包含了三个最主要的状态,分别是 就绪/运行/阻塞,其中的方法 getState() 的作用就是获取当前线程的状态
在 Java 中存在着线程池,你可能会想“为什么要多此一举搞一个线程池出来?”这件事情就要说回OS 线程对应的规则了
OS 中,当线程处于运行态时会使用 CPU,线程产生的数据占用 CPU 中的缓存,但是由于并发的存在,CPU 会在规定时间里面换另一个线程执行,那么这一个执行到一半的线程产生的数据应该怎么办?
OS 说:你自己先带回去,等到下一次你要用 CPU 的时候再带过来,所以线程还会携带计算到中间的数值。
所谓的“数据带回去”,在计算机原理中就是保存上下文 (Context Save)。操作系统会把当前线程的程序计数器 (Program Counter) 和 寄存器 (Registers) 信息保存到内存里(TCB/PCB),等下次轮到它执行时再恢复。这个过程非常消耗 CPU 时间,这就是为什么线程切换慢的原因。
我们来做一个小实验,如果不使用线程池会产生什么结果
public class Main {
public static void main(String[] args) {
long start = System.currentTimeMillis();
for (int i = 0; i < 10000; i++) {
new Thread(() -> {
}).start();
}
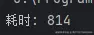
System.out.println("耗时: " + (System.currentTimeMillis() - start));
}
}
public class Main {
public static void main(String[] args) {
// 引入线程池
ExecutorService pool = Executors.newFixedThreadPool(10);
long start = System.currentTimeMillis();
for (int i = 0; i < 10000; i++) {
pool.execute(() -> {}); // 任务扔进队列,10个工人轮流干
}
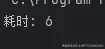
System.out.println("耗时: " + (System.currentTimeMillis() - start));
pool.shutdown();
}
}
我们能发现,如果不采取线程池,所需要消耗的时间成百倍上升,那为什么线程池能够节省 CPU 的性能呢?
答案是创建和复用的基本策略不同,
方法一 每一个线程都采取直接创建,而线程创建所消耗的性能十分庞大,需要先保存上下文 CPU 变态调用对应的创建语句,最后还需要切换回当前线程。
方法二 固定创建了 10 个线程,但是一直复用了10个线程,消耗自然而然就小了
除了 CPU 开销,内存开销也是大头。一个 Java 线程运行如果需要 1MB 的栈内存空间(Stack Size)。如果你同时运行 10000 个线程,理论上需要 10GB 内存!这不 OOM 谁 OOM?而线程池通过复用 10 个线程,只占用了 10MB 内存。

