我的奶牛
10.48M · 2026-03-26


from langchain_deepseek import ChatDeepSeek
from dotenv import load_dotenv
load_dotenv(override=True)
# 2 初始化模型参数
model = ChatDeepSeek(
model="deepseek-ch@t",
temperature=0.0, # 温度参数,用于控制模型的随机性,值越小则随机性越小
max_tokens=512, # 最大生成token数
timeout=30 # 超时时间,单位秒
)
# 3 定义问题
question = "你好,请你介绍一下你自己。"
# 4 调用模型
result = model.invoke(question)
print(result)
from langchain_community.ch@t_models.tongyi import ChatTongyi
model = ChatTongyi() # 默认qwen-turbo模型
question = "你好,请你介绍一下你自己。"
result = model.invoke(question)
print(result.content)
3.GLM
from langchain_openai import ChatOpenAI
from dotenv import load_dotenv
load_dotenv(override=True)
llm = ChatOpenAI(model = "glm-4.7")
question = "你好,请你介绍一下你自己。"
result = llm.invoke(question)
print(result)
# 1 导入 OllamaLLM
from langchain_ollama import OllamaLLM
# 2 初始化本地模型
llm = OllamaLLM(model="deepseek-r1:8b")
# 3 定义问题
question = "你好,请你介绍一下你自己。"
# 4 调用模型
result = llm.invoke(question)
# 5 打印结果
print(result)
# 连接本地vLLM服务
from langchain_openai import ChatOpenAI
# 连接到本地 vLLM 服务,配置长连接池,减少握手开销
model = ChatOpenAI(
model="qwen-32b-ch@t", # 指定使用的模型名称
base_url="http://localhost:8000/v1", # vLLM 的 OpenAI API 地址
api_key="EMPTY", # vLLM 不验证 key,可以随便写
max_retries=5, # 增加重试次数
timeout=120.0, # 超时时间设长
http_client={ # 自定义 HTTP 客户端
"limits": {
"max_connections": 100, # 最大连接数
"max_keepalive_connections": 20 # 最大保持活动连接数
}
}
)
from langchain.ch@t_models import init_ch@t_model
from dotenv import load_dotenv
load_dotenv(override=True)
model = init_ch@t_model(
"glm-4.7", # 指定聊天模型
model_provider="openai", # 指定模型提供商
)
result = model.invoke("你好,请你介绍一下你自己。")
print(result)
# 1. 定义带速率限制的load_ch@t_model函数
from langchain.ch@t_models import init_ch@t_model
from langchain_core.rate_limiters import InMemoryRateLimiter
# 2. 配置速率限制器
rate_limiter = InMemoryRateLimiter(
requests_per_second=5, # 每秒最多5个请求
check_every_n_seconds=1.0 # 每1秒检查一次是否超过速率限制
)
# 3. 对模型调用进行封装,后续直接调用传参数就行
def load_ch@t_model(
model: str,
provider: str,
temperature: float = 0.7,
max_tokens: int | None = None,
base_url: str | None = None,
):
return init_ch@t_model(
model=model, # 模型名称
model_provider=provider, # 模型供应商
temperature=temperature, # 温度参数,用于控制模型的随机性,值越小则随机性越小
max_tokens=max_tokens, # 最大生成token数
rate_limiter=rate_limiter # 自动限速
)
model = load_ch@t_model(
"glm-4.7",
provider="openai"
)
使用重试机制:通过 .with_retry() 方法为模型调用添加指数退避重试策略,在遇到临时性故障(如速率限制错误)时自动重试
指数退避的等待时间:
1s → 2s → 4s → 8s → 16s → …
每次失败都指数增加等待时间,避免快速重复打爆 API。
抖动 = 在等待时间上随机增加/减少一点随机数
防止集群中的多个客户端在相同时间重复同时回退,造成更大拥堵
失败的请求不会同时发起,极大降低 API 或本地模型的压力。
model = load_ch@t_model(
"glm-4.7",
provider="openai"
).with_retry(
stop_after_attempt=3, # 最多重试3次
wait_exponential_jitter=True # 指数退避 + 随机抖动
)
responses = model.batch([
"为什么鹦鹉有五颜六色的羽毛?",
"飞机是如何飞行的?",
"什么是量子计算?"
])
for response in responses:
print(response)
当然,我们也可以进行流式批处理,也就是每个每个任务完成后就立即获取结果(而不是等待全部完成),可以使用 batch_as_completed() 方法。
for response in model.batch_as_completed([
"请介绍下你自己。",
"请问什么是机器学习?",
"你知道机器学习和深度学习区别么?"
]):
print(response)
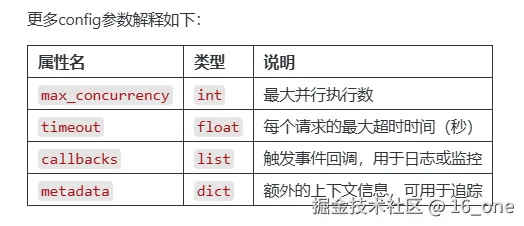
使用batch或 batch_as_completed()处理大量输入时,可以通过RunnableConfig字典中设置max_concurrency属性来控制最大并行调用数
#设置并发数为3
config = RunnableConfig(max_concurrency=3)
model.batch(
list_of_inputs,
config=config
)
for chunk in model.stream("用一段话描述大海."):
print(chunk.content, end="",flush=True)
每个 AIMessageChunk 都可以通过加法 + 操作符拼接。LangChain 内部为此设计了“消息块相加(chunk summation)”机制。
# 初始化变量,用于累积模型返回的完整内容
full = None # 初始值为空
# 使用流式方式调用模型,逐块接收返回内容
for chunk in model.stream("你好,好久不见"):
# 如果是第一块内容,则直接赋值;否则拼接到已有内容
full = chunk if full is None else full + chunk
# 打印当前累积的文本内容
print(full.text)
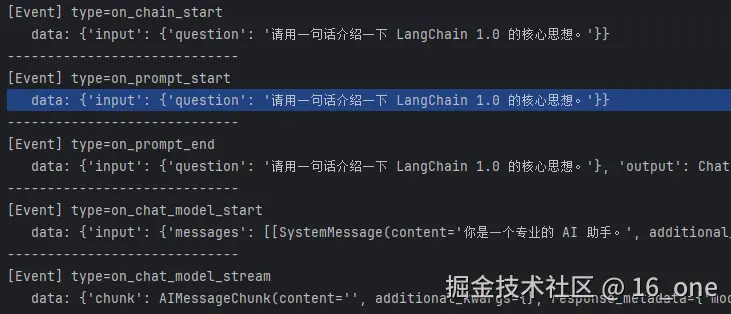
你能看到 完整语义生命周期事件,包括:
import asyncio
from collections.abc import Sequence
from langchain_core.prompts import ChatPromptTemplate
from langchain.ch@t_models import init_ch@t_model
from dotenv import load_dotenv
load_dotenv(override=True)
llm = init_ch@t_model(
"glm-4.5", # 指定DeepSeek的聊天模型
model_provider="openai", # 指定模型提供商为deepseek
)
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个专业的AI助手"),
("human", "{question}")
])
async def printMessage():
# 使用管道符将prompt 模板与llm 连接 构建可运行的链
chain = prompt | llm
# 使用astream_events()所有语义事件
events = chain.astream_events(
{
"question": "请用一句话介绍一下 LangChain 1.0 的核心思想。"
},
version="v1"
)
async for event in events:
print(f"""[Event] type={event["event"]}""")
# 展示关键字段
if "data" in event:
print(" data:", event["data"])
print("-----------------------------")
if __name__ == "__main__":
# 运行异步版本
async_responses = asyncio.run(printMessage())
from typing import List
from langchain_core.utils.pydantic import BaseModel, Field
from langchain_openai import ChatOpenAI
# 1. 定义期望的输出结构 (Pydantic 模型)
class Person(BaseModel):
"""Information about a person."""
name: str = Field(description="人的姓名")
age: int = Field(description="人的年龄")
high: int = Field(description="人的身高")
hobbies: List[str] = Field(description="人的爱好列表")
# 2. 初始化模型并绑定结构化输出格式
llm = ChatOpenAI(model="gpt-4o", temperature=0)
structured_llm = llm.with_structured_output(Person)
# 3. 调用模型并获取 Pydantic 对象,构造提示:要求提取约翰·多伊的姓名、年龄和兴趣爱好
prompt = "提取名为约翰·多伊的人的信息,提取不到的数据就为空值。他30岁,喜欢阅读、远足和弹吉他."
result = structured_llm.invoke(prompt)
# 4. 验证结果
print(f"Type of result: {type(result)}")
print(f"Result object: {result}")
# 5.判断result是否属于Person类
assert isinstance(result, Person)
include_raw=Truestructured_llm = llm.with_structured_output(Person, include_raw=True)
from pydantic import BaseModel
# 1. 定义年龄模型,限制范围 0-150
class AgeProfile(BaseModel):
name: str
age: int = Field(ge=0, le=150) # 年龄必须在0-150之间
from langchain_core.output_parsers import JsonOutputParser
import json
from pydantic import BaseModel, Field
# 1. 定义输出结构
class WeatherInfo(BaseModel):
"""天气信息"""
city: str = Field(description="城市名称")
temperature: int = Field(description="温度(摄氏度)")
condition: str = Field(description="天气状况")
# 2. 创建 JSON 输出解析器
json_parser = JsonOutputParser(pydantic_object=WeatherInfo)
# 3. 创建提示模板(关键:必须包含 "json" 这个词)
prompt = ChatPromptTemplate.from_template(
"""请根据以下信息提取天气数据,并以 JSON 格式返回。
信息:{weather_info}
请返回包含以下字段的 JSON:
- city: 城市名称
- temperature: 温度(摄氏度)
- condition: 天气状况
必须返回以下 JSON 格式(不要包含任何其他文本):
{{"city": "城市名称", "temperature": 温度数字, "condition": "天气状况"}}
例如:{{"city": "北京", "temperature": 25, "condition": "晴"}}
JSON 格式:
""")
# 4. 定义模型
model = load_ch@t_model(
model="gpt-4o-mini",
provider="openai",
)
# 5. 构建链
runnable = prompt | model | json_parser
# 6. 调用
result = runnable.invoke({"weather_info": "北京今天晴,温度25度"})
print(result)
print(result["city"])

