
加菲猫欢乐跑
65.99M · 2026-03-26

大模型的浪潮如火如荼,但做为个人开发者和小企业的我们,不知道大家有没有面临这样的困境:有限的算力预算如同杯水车薪,是该训练一个参数更多的聪明模型,还是用更多数据喂养一个见多识广的模型,往往训练一个大体量的模型,需要耗费大量的资金和时间,而作为普通用户的我们,如果想训练一个自己的模型,在我们固定的计算预算下,我们应该训练一个多大的模型参数量?并用多少数据?如何高效地分配计算资源成为模型训练的核心问题!
扩展法则就是为了科学地回答这个问题而生的,也正是破解这一难题,为我们提供了精细化的指导思路,它们是基于大量实验得出的经验规律,用于预测模型性能损失如何随参数量N和数据量D的变化而变化,它告诉我们,盲目堆砌参数可能只是在制造昂贵的傻瓜,而恰当的数据配比能让小预算发挥大效能。理解扩展法则,意味着能用1%的资源达成80%的效果,让资源有限的团队也能在AI赛道上精准发力。这不仅是技术选择,更是生存智慧,在有限的算力资源中,找到属于我们个人或小团队的制胜策略。今天我们重点围绕两个关键的扩展法则:KM扩展法则和Chinchilla扩展法则深度解析基础释义、核心思想以及数学原理,总结两者的差异和对模型训练的重要意义。
在深入分析之前,我们必须明确扩展法则要解决的核心问题:
在计算预算 C 固定的前提下,如何分配模型参数量N和训练数据Token量D,才能使模型的最终性能损失L最优。
这里有几个关键概念:
FLOPs 是浮点运算次数,它就像是衡量计算机“做了多少脑力工作”的计数器,拆解开来理解:
所以,1个 FLOP 就代表计算机执行了一次浮点数的加法、减法、乘法或除法,FLOPs(末尾的s代表复数)就是指总的浮点运算次数。
想象我们要做一道数学题,要计算一个数学公式题:y = (3.2 × 1.5) + (2.1 ÷ 0.7) - 4.0,我们一步步算一下:
完成这道题,计算机总共需要执行4次浮点运算,所以它的计算量就是4FLOPs。
在训练和运行AI模型时,绝大部分工作都是大规模的矩阵和向量运算,而这些运算最终都可以分解成海量的加法和乘法。
一个具体的例子:计算一个神经元的输出
假设一个神经元有3个输入 [x1, x2, x3],对应的权重是 [w1, w2, w3],还有一个偏置项 b。
它的输出是:y = (x1*w1 + x2*w2 + x3*w3) + b
我们来数一下FLOPs:
总共:6 FLOPs。
由此可以看出,一个大语言模型有数千亿个参数(权重和偏置),每处理一个token都需要进行数百万甚至数十亿次这样的计算,这个总的FLOPs数量就会变得极其庞大。
FLOPs是衡量计算成本、算法效率和硬件性能的一个核心指标。
FLOPs就是完成一个计算任务,比如训练一个AI模型所需要完成的基础数学题的总数量,表示一个工作量单位,数量越大,意味着任务越复杂,需要的计算资源越多。它是我们理解和量化人工智能等领域巨大计算需求的基石。
计算预算通常以FLOPs衡量。对于自回归语言模型训练,一个广泛使用的近似是 C ≈ 6 * N * D,这个公式是理解模型训练成本的钥匙,它告诉我们,总计算量主要取决于模型有多大和学了多少数据。
为什么是 6 * N * D?
这是一个基于Transformer架构自回归语言模型训练的经验近似值。我们可以通过分析模型的前向传播和反向传播过程来理解它:
这是一个近似值,实际值可能因模型架构、序列长度、优化器类型等因素而在 ~2ND 到 ~10ND 之间变化,但 6ND 是一个被广泛接受和使用的可靠估算值,用于进行高阶的趋势分析和比较。
这个公式建立了一个预算约束,如果增大了模型规模N,但保持总预算C不变,那么必须相应地减少数据量D,反之亦然。这也是今天我们要谈论解决的核心问题:如何在固定的 C 下,最优地分配 N 和 D?
L 是衡量模型好坏的指标,通常是模型在预留测试集上的交叉熵损失或困惑度,在语言建模中,它几乎总是通过交叉熵损失或其派生指标困惑度来定义,损失越低,模型能力越强。
**核心思想:**衡量模型预测的概率分布与真实的概率分布(一个one-hot向量,代表正确的下一个词)之间的距离。
计算公式(对于一个token):
**直观理解:**模型对正确下一个词赋予的预测概率 y_pred_correct_word 越高,损失 -log(y_prob) 就越低。
整个数据集的损失是所有这些单个token损失的平均值。
困惑度是交叉熵损失的指数形式,因为它更直观。
**计算公式:**Perplexity = exp(Cross-Entropy_Loss)
**直观理解:**困惑度可以理解为“模型在预测下一个词时的平均不确定性程度”或者“平均分支因子”。
**关系:**由于 Perplexity = exp(L),最小化交叉熵损失 L 就等价于最小化困惑度。在扩展法则的研究中,通常直接使用交叉熵损失 L 作为优化目标,因为它数学性质更好(是加法性的)。
交叉熵损失和困惑度的详细说明可参考《信息论完全指南:从基础概念到在大模型中的实际应用》
这是扩展法则的灵魂,揭示了性能提升的基本规律。
扩展法则发现,损失 L 与模型规模 N 和数据规模 D 遵循幂律关系:
L ∝ 1 / N^α
L ∝ 1 / D^β
这意味着,L 与 N^α 和 D^β 成反比。将其与不可约损失 E 结合,就得到了我们之前看到的完整公式:
L(N, D) = E + A/N^α + B/D^β
幂律中的指数 α 和 β(通常远小于1)是理解收益递减的关键。
让我们通过一个例子来理解:
示例发现:
对扩展法则的实际意义:
预算C、性能L和幂律这三个概念构成了一个完整的逻辑链:
核心思想: 在计算预算充足的情况下,模型参数量 N 是影响性能的最关键因素。为了达到最佳性能,应优先扩大模型规模,同时按比例适当增加数据量。
一个简单的比喻:
好比我们在组建一个研究团队来解决一个复杂问题。
KM法则将测试损失 L 建模为 N 和 D 的幂律函数:
L(N, D) = E + (A / N^α) + (B / D^β)
其中:
通过这个公式,如果我们知道了常数 E, A, B, α, β,我们就可以预测:一个拥有 N 参数、用 D 数据训练的模型,最终性能 L 大概会是多少,这为模型设计提供了很好的指导,由于 α 和 β 都很小,为了最小化损失,需要同时增大 N 和 D,但KM法则的实证结果表明,对 N 的投资回报率更高。
通过对上述公式的分析和实验验证,KM法则得出了几个改变AI研发方向的结论:
3.1 模型规模 N 的收益高于数据规模 D
3.2 性能平滑可预测
3.3 在计算最优边界上,模型应该“训练不足”
KM法则的核心公式:L(N, D) = E + A/N^α + B/D^β
其中:
L:模型损失(越低越好)
N:模型参数量
D:训练数据量(token数)
E, A, B, α, β:通过实验拟合的常数
import numpy as np import matplotlib.pyplot as plt from mpl_toolkits.mplot3d import Axes3D
plt.rcParams['font.sans-serif'] = ['SimHei'] plt.rcParams['axes.unicode_minus'] = False
def km_scaling_law_log(N, D, E=2.0, A=3.0, B=3.0, alpha=0.3, beta=0.3): """ 计算KM扩展法则预测的损失值 - 对数尺度版本 确保输出在合理范围内
参数:
N: 模型参数量 (单位: 十亿)
D: 训练数据量 (单位: 十亿token)
"""
# 使用对数尺度确保数值稳定
# 基础损失 + 模型项 + 数据项
L = E + (A / (np.log(N + 1) ** alpha)) + (B / (np.log(D + 1) ** beta))
return L
def safe_exp(x): """安全的指数函数,防止溢出""" return np.exp(np.clip(x, -700, 700))
print("=== 示例1: 单个模型性能预测 ===") N_example = 1.0 # 10亿参数 D_example = 5.0 # 50亿token
loss = km_scaling_law_log(N_example, D_example) print(f"模型规模: {N_example}B 参数") print(f"训练数据: {D_example}B token") print(f"KM法则预测损失: {loss:.4f}") print(f"对应的困惑度: {safe_exp(loss):.2f}n")
print("=== 示例2: 不同规模模型对比 ===") model_sizes = [0.1, 0.5, 1.0, 5.0, 10.0, 50.0, 100.0] # 从1亿到1000亿参数 fixed_data = 10.0 # 固定100亿token数据
print(f"固定训练数据: {fixed_data}B token") print("模型规模(B)t预测损失t困惑度") print("-" * 55)
for size in model_sizes: loss = km_scaling_law_log(size, fixed_data) perplexity = safe_exp(loss) print(f"{size:8.1f}t{loss:.4f}tt{perplexity:.2f}")
print("n=== 示例3: 不同数据量对比 ===") data_sizes = [1.0, 5.0, 10.0, 50.0, 100.0, 500.0, 1000.0] # 从10亿到1万亿token fixed_model = 1.0 # 固定10亿参数
print(f"固定模型规模: {fixed_model}B 参数") print("数据量(B)t预测损失t困惑度") print("-" * 55)
for data in data_sizes: loss = km_scaling_law_log(fixed_model, data) perplexity = safe_exp(loss) print(f"{data:8.1f}t{loss:.4f}tt{perplexity:.2f}")
print("n=== 示例4: 生成可视化图表 ===")
N_range = np.logspace(-1, 2, 50) # 从0.1B到100B参数 D_range = np.logspace(0, 3, 50) # 从1B到1000B token
N_grid, D_grid = np.meshgrid(N_range, D_range) L_grid = km_scaling_law_log(N_grid, D_grid)
fig = plt.figure(figsize=(16, 5))
ax1 = fig.add_subplot(131) fixed_D = 10.0 # 固定10B token
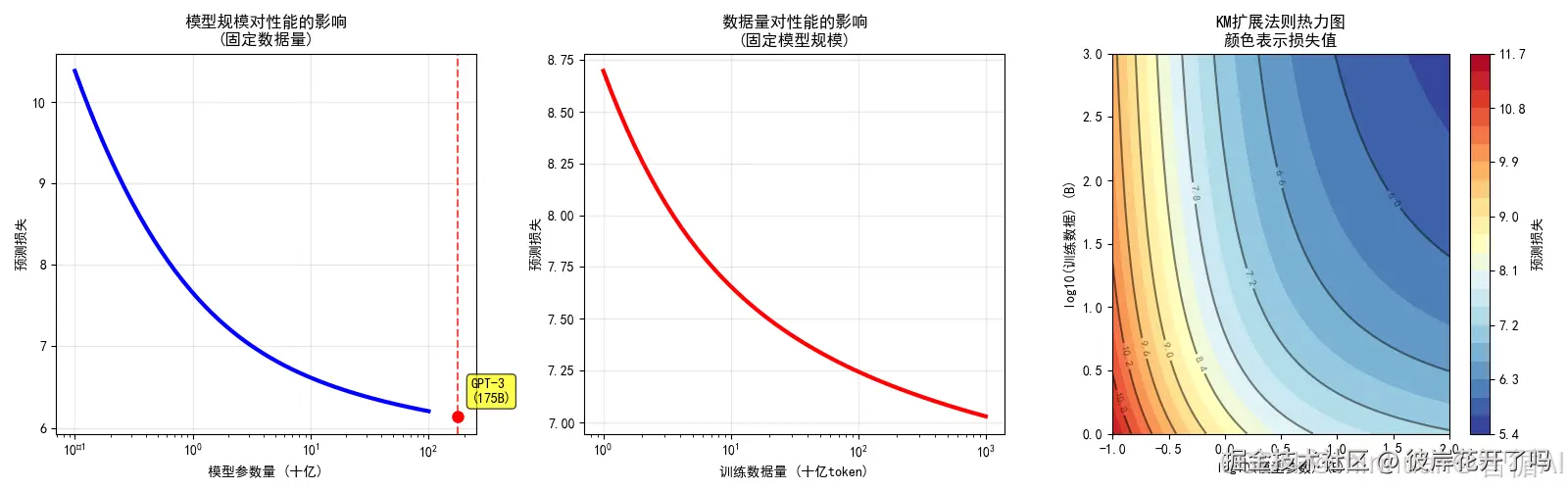
losses_N = [km_scaling_law_log(N, fixed_D) for N in N_range] ax1.semilogx(N_range, losses_N, 'b-', linewidth=3) ax1.set_xlabel('模型参数量 (十亿)') ax1.set_ylabel('预测损失') ax1.set_title('模型规模对性能的影响n(固定数据量)') ax1.grid(True, alpha=0.3)
gpt3_N = 175 gpt3_loss = km_scaling_law_log(gpt3_N, fixed_D) ax1.axvline(x=gpt3_N, color='red', linestyle='--', alpha=0.7) ax1.plot(gpt3_N, gpt3_loss, 'ro', markersize=8) ax1.annotate(f'GPT-3n({gpt3_N}B)', (gpt3_N, gpt3_loss), xytext=(10, 10), textcoords='offset points', bbox=dict(boxstyle="round,pad=0.3", fc="yellow", alpha=0.7))
ax2 = fig.add_subplot(132) fixed_N = 1.0 # 固定1B参数
losses_D = [km_scaling_law_log(fixed_N, D) for D in D_range] ax2.semilogx(D_range, losses_D, 'r-', linewidth=3) ax2.set_xlabel('训练数据量 (十亿token)') ax2.set_ylabel('预测损失') ax2.set_title('数据量对性能的影响n(固定模型规模)') ax2.grid(True, alpha=0.3)
ax3 = fig.add_subplot(133) contour = ax3.contourf(np.log10(N_grid), np.log10(D_grid), L_grid, levels=20, cmap='RdYlBu_r') ax3.set_xlabel('log10(模型参数) (B)') ax3.set_ylabel('log10(训练数据) (B)') ax3.set_title('KM扩展法则热力图n颜色表示损失值')
contour_lines = ax3.contour(np.log10(N_grid), np.log10(D_grid), L_grid, levels=10, colors='black', alpha=0.5) ax3.clabel(contour_lines, inline=True, fontsize=8)
plt.colorbar(contour, ax=ax3, label='预测损失')
plt.tight_layout() plt.show()
print("n=== 示例5: 实际模型性能预测 ===")
real_models = [ {"name": "GPT-3", "N": 175, "D": 300}, {"name": "LLaMA-2 7B", "N": 7, "D": 2000}, {"name": "LLaMA-2 70B", "N": 70, "D": 2000}, {"name": "PaLM", "N": 540, "D": 780}, {"name": "Chinchilla", "N": 70, "D": 1400}, ]
print("模型名称tt参数(B)t数据(B)t预测损失t困惑度") print("-" * 70)
for model in real_models: loss = km_scaling_law_log(model["N"], model["D"]) perplexity = safe_exp(loss) print(f"{model['name']:12}t{model['N']:4.0f}t{model['D']:4.0f}t{loss:.4f}tt{perplexity:.2f}")
print("n=== 示例6: 资源分配策略 ===")
def analyze_resource_allocation(total_compute): """分析不同资源分配策略""" print(f"n在总计算量 {total_compute:.1e} FLOPs 下的策略分析:") print("策略ttt模型规模(B)t数据量(B)t预测损失") print("-" * 65)
# 策略1: KM风格 (偏向大模型)
N_km = (total_compute / 6) ** 0.7 / 1e9
D_km = (total_compute / 6) ** 0.3 / 1e9
loss_km = km_scaling_law_log(N_km, D_km)
print(f"KM策略ttt{N_km:6.1f}tt{D_km:6.1f}tt{loss_km:.4f}")
# 策略2: Chinchilla风格 (平衡)
N_chi = (total_compute / 6) ** 0.5 / 1e9
D_chi = (total_compute / 6) ** 0.5 / 1e9
loss_chi = km_scaling_law_log(N_chi, D_chi)
print(f"Chinchilla策略tt{N_chi:6.1f}tt{D_chi:6.1f}tt{loss_chi:.4f}")
# 策略3: 偏向大数据
N_data = (total_compute / 6) ** 0.3 / 1e9
D_data = (total_compute / 6) ** 0.7 / 1e9
loss_data = km_scaling_law_log(N_data, D_data)
print(f"数据优先策略tt{N_data:6.1f}tt{D_data:6.1f}tt{loss_data:.4f}")
analyze_resource_allocation(1e22) # 分析1e22 FLOPs预算
代码详细解释
4.1 核心函数
def km_scaling_law_log(N, D, E=2.0, A=3.0, B=3.0, alpha=0.3, beta=0.3):
"""
计算KM扩展法则预测的损失值 - 对数尺度版本
确保输出在合理范围内
参数:
N: 模型参数量 (单位: 十亿)
D: 训练数据量 (单位: 十亿token)
"""
# 使用对数尺度确保数值稳定
# 基础损失 + 模型项 + 数据项
L = E + (A / (np.log(N + 1) ** alpha)) + (B / (np.log(D + 1) ** beta))
return L
4.2 单个预测示例
N_example = 1.0 # 10亿参数
D_example = 5.0 # 50亿token
loss = km_scaling_law_log(N_example, D_example)
这里我们预测一个10亿参数、用50亿token训练的模型的性能。
4.3 规模对比分析
model_sizes = [0.1, 0.5, 1.0, 5.0, 10.0, 50.0, 100.0] # 从1亿到1000亿参数
通过这个循环,我们可以看到模型规模从1亿参数增长到100亿参数时,性能如何变化。
4.4 输出结果
图例分析:
核心思想: 对于给定的计算预算 C,模型参数量 N 和数据Token量 D 应该成比例地增长。模型不是越大越好,而是需要与足够多的数据配对。许多现有的大模型是训练不足的,减小模型规模并大幅增加数据量,可以在相同计算成本下获得更优的性能。
这个思想可以分解为三个关键点:
1.1 挑战规模至上的观点
1.2 揭示训练不足问题
1.3 确立平衡分配原则
2.1 公式说明
与KM法则类似,Chinchilla将测试损失 L 建模为模型参数量 N 和训练数据量 D 的函数:
L(N, D) = E + A/(N^α) + B/(D^β)
其中:
关键的Chinchilla参数值:
DeepMind通过实验拟合出的参数约为:
2.2 与KM法则的数学对比
特性 KM 法则 Chinchilla 法则 含义与影响
**模型指数 α ** | ~0.076 | ~0.38 | Chinchilla的α大了约5倍! 这意味着增加模型规模带来的性能收益衰减得快得多。模型规模的增长不再那么“划算”。
数据指数 β | ~0.103 | ~0.38 | Chinchilla的β也大了约3.7倍! 这意味着增加数据量带来的性能收益同样衰减得很快,但其衰减速度现在与模型项持平。
指数关系 | α < β | α ≈ β | 这是最根本的差异。 KM认为模型收益衰减更慢,故应优先扩大模型。Chinchilla发现两者衰减速度相同,故应平衡分配资源。
2.3 直观理解指数差异:
α 和 β 决定了“收益递减”的速度。
2.4 了解 N_op 和 D_op
2.4.1 N_op 和 D_op 是什么
2.4.2 符号 ∝ 的含义
∝ 表示"正比于",所以:
2.4.3 直观理解:切蛋糕的比喻
想象我们有一块固定大小的蛋糕(计算预算 C),要分给两个人:
Chinchilla法则告诉我们:应该把蛋糕平均分给这两个人!
2.4.4 具体实例
场景1:小预算情况
假设计算预算 C = 1e21 FLOPs
场景2:预算增加100倍
现在预算增加到 C = 1e23 FLOPs(增加了100倍)
对比分析:
2.4 计算最优分配公式
基于上述性能预测公式,Chinchilla推导出了在固定计算预算 C(其中 C ≈ 6 N D)下,如何分配 N 和 D 才能使损失 L 最小化。
**核心发现:**最优配置是让模型容量项和数据容量项对损失的贡献大致相等。
其推导出的最优比例是:
N_op ∝ C^a
D_op ∝ C^b
其中 a = β/(α+β), b = α/(α+β)
代入Chinchilla的 α=β=0.38:
因此,最优策略为:
N_op ∝ C^0.5
D_op ∝ C^0.5
具体经验性结论:
对于一个计算预算 C,Chinchilla推荐:
注意:这里的常数20是考虑了模型前向和反向传播的FLOPs估算后的一个经验值,与 C ≈ 6ND 的本质思想一致。
Chinchilla法则的数学公式告诉我们:
在固定计算预算下,模型参数量(N)和训练数据量(D)应该平衡增长,而不是像KM法则那样偏向模型规模。
核心公式:L(N, D) = E + A/N^α + B/D^β
其中 α ≈ β ≈ 0.38,这与KM法则的 α=0.076, β=0.103 形成鲜明对比。
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
def chinchilla_scaling_law(N, D, E=1.69, A=406.4, B=410.7, alpha=0.38, beta=0.38):
"""
计算Chinchilla扩展法则预测的损失值
参数:
N: 模型参数量 (单位: 十亿)
D: 训练数据量 (单位: 十亿token)
E, A, B, alpha, beta: Chinchilla法则的经验参数
返回:
L: 预测的损失值
"""
# Chinchilla核心公式 - 注意指数alpha和beta都接近0.38
L = E + (A / (N ** alpha)) + (B / (D ** beta))
return L
def km_scaling_law(N, D, E=1.5, A=500, B=1000, alpha=0.076, beta=0.103):
"""
KM扩展法则用于对比
"""
L = E + (A / (N ** alpha)) + (B / (D ** beta))
return L
# 示例1: 单个模型预测对比
print("=== 示例1: Chinchilla vs KM 预测对比 ===")
N_example = 70 # 70亿参数
D_example = 1500 # 1.5万亿token
loss_chinchilla = chinchilla_scaling_law(N_example, D_example)
loss_km = km_scaling_law(N_example * 1000, D_example * 1000) # 转换为百万单位
print(f"模型规模: {N_example}B 参数")
print(f"训练数据: {D_example}B token")
print(f"Chinchilla预测损失: {loss_chinchilla:.4f}")
print(f"Chinchilla预测困惑度: {np.exp(loss_chinchilla):.2f}")
print(f"KM法则预测损失: {loss_km:.4f}")
print(f"KM法则预测困惑度: {np.exp(loss_km):.2f}n")
# 示例2: 计算最优配置对比
print("=== 示例2: 最优配置计算对比 ===")
def find_optimal_allocation(compute_budget, law_type='chinchilla'):
"""
根据不同的扩展法则找到最优配置
假设计算预算 C ≈ 6 * N * D
"""
if law_type == 'chinchilla':
# Chinchilla: 平衡分配
alpha, beta = 0.38, 0.38
N_optimal = (compute_budget / 6) ** 0.5 # N ∝ C^0.5
D_optimal = (compute_budget / 6) ** 0.5 # D ∝ C^0.5
else: # KM法则
alpha, beta = 0.076, 0.103
optimal_N_ratio = alpha / (alpha + beta)
optimal_D_ratio = beta / (alpha + beta)
N_optimal = (compute_budget / 6) ** optimal_N_ratio # N ∝ C^0.74
D_optimal = (compute_budget / 6) ** optimal_D_ratio # D ∝ C^0.26
return N_optimal, D_optimal
# 测试不同计算预算下的最优配置
budgets = [1e21, 5e21, 1e22, 5e22] # 不同的计算预算
print("计算预算(FLOPs)t法则类型tt最优参数(B)t最优数据(B)t参/数比例")
print("-" * 85)
for budget in budgets:
# Chinchilla最优配置
N_chi, D_chi = find_optimal_allocation(budget, 'chinchilla')
ratio_chi = N_chi / D_chi
# KM最优配置
N_km, D_km = find_optimal_allocation(budget, 'km')
ratio_km = N_km / D_km
print(f"{budget:.1e}tChinchillat{N_chi/1e9:8.1f}tt{D_chi/1e9:8.1f}tt{ratio_chi:.3f}")
print(f"{budget:.1e}tKM法则tt{N_km/1e9:8.1f}tt{D_km/1e9:8.1f}tt{ratio_km:.3f}")
print("-" * 85)
# 示例3: 训练不足分析
print("n=== 示例3: 训练不足分析 ===")
def analyze_under_training(model_size_B, compute_budget):
"""
分析在固定计算预算下,不同数据量对性能的影响
"""
print(f"n分析 {model_size_B}B 参数模型在 {compute_budget:.1e} FLOPs 预算下的表现:")
# Chinchilla推荐的数据量
N_chi_opt, D_chi_opt = find_optimal_allocation(compute_budget, 'chinchilla')
D_chi_for_model = compute_budget / (6 * model_size_B * 1e9)
# KM推荐的数据量
N_km_opt, D_km_opt = find_optimal_allocation(compute_budget, 'km')
D_km_for_model = compute_budget / (6 * model_size_B * 1e9)
# 计算不同数据量下的损失
data_ratios = [0.25, 0.5, 1.0, 2.0, 4.0] # 相对于Chinchilla推荐的数据量比例
print("数据比例t实际数据(B)tChinchilla损失tKM损失tt训练状态")
print("-" * 75)
for ratio in data_ratios:
actual_data = D_chi_for_model * ratio / 1e9 # 转换为十亿单位
loss_chi = chinchilla_scaling_law(model_size_B, actual_data)
loss_km = km_scaling_law(model_size_B * 1000, actual_data * 1000)
status = "严重训练不足" if ratio < 0.5 else "训练不足" if ratio < 1.0 else "接近最优" if ratio <= 2.0 else "数据充足"
print(f"{ratio:4.2f}tt{actual_data:8.1f}tt{loss_chi:.4f}tt{loss_km:.4f}tt{status}")
analyze_under_training(70, 1e22) # 分析70B模型
# 示例4: 可视化对比
print("n=== 示例4: 生成对比可视化图表 ===")
# 创建计算预算范围
compute_range = np.logspace(20, 24, 50) # 10^20 到 10^24 FLOPs
# 计算两种法则的最优配置
N_chi_optimal = []
D_chi_optimal = []
N_km_optimal = []
D_km_optimal = []
for C in compute_range:
N_chi, D_chi = find_optimal_allocation(C, 'chinchilla')
N_km, D_km = find_optimal_allocation(C, 'km')
N_chi_optimal.append(N_chi / 1e9) # 转换为十亿单位
D_chi_optimal.append(D_chi / 1e9)
N_km_optimal.append(N_km / 1e9)
D_km_optimal.append(D_km / 1e9)
# 创建可视化图表
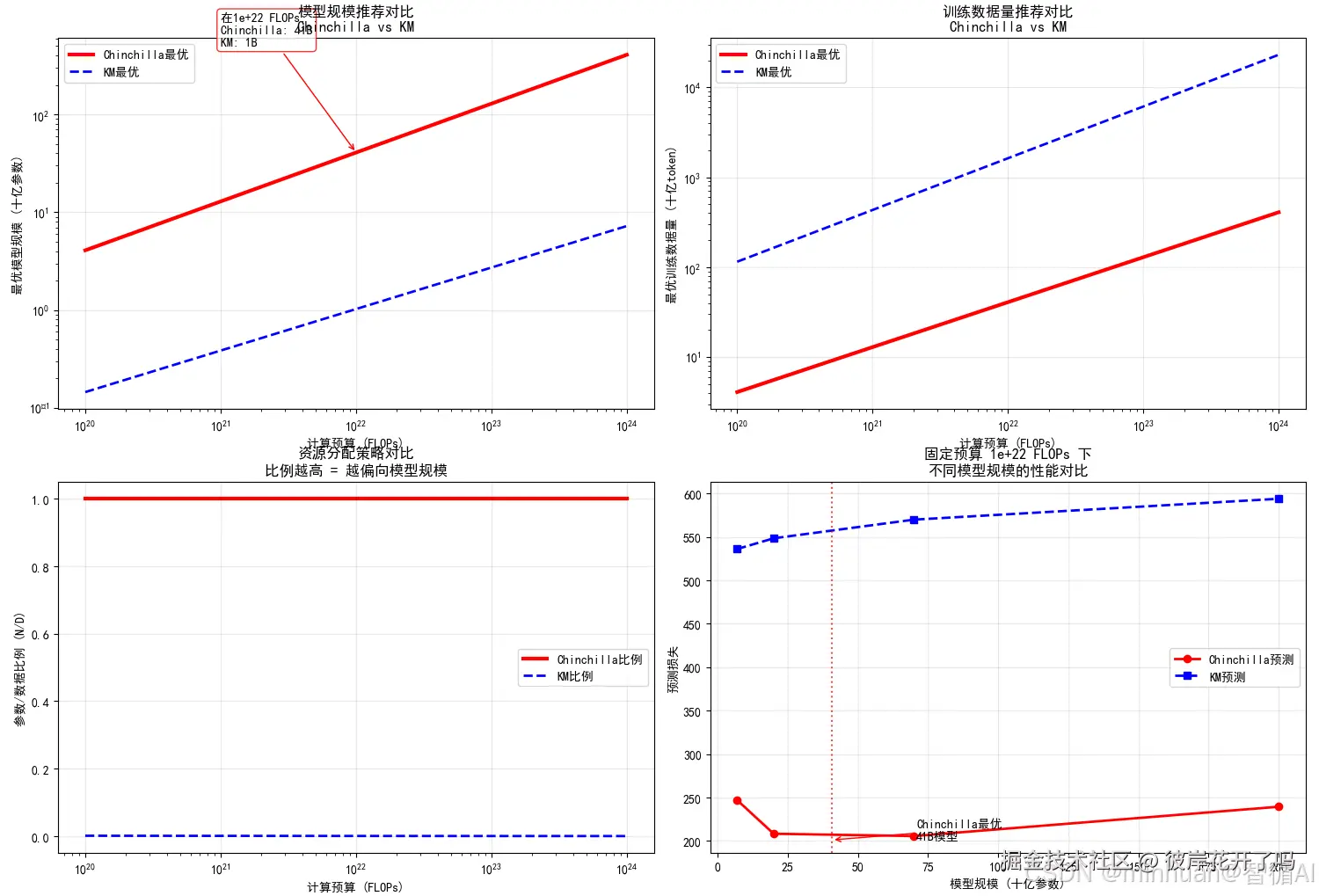
fig, ((ax1, ax2), (ax3, ax4)) = plt.subplots(2, 2, figsize=(15, 12))
# 子图1: 最优模型规模对比
ax1.loglog(compute_range, N_chi_optimal, 'r-', linewidth=3, label='Chinchilla最优')
ax1.loglog(compute_range, N_km_optimal, 'b--', linewidth=2, label='KM最优')
ax1.set_xlabel('计算预算 (FLOPs)')
ax1.set_ylabel('最优模型规模 (十亿参数)')
ax1.set_title('模型规模推荐对比nChinchilla vs KM')
ax1.legend()
ax1.grid(True, alpha=0.3)
# 标记具体预算点示例
sample_budget = 1e22
N_chi_sample = (sample_budget / 6) ** 0.5 / 1e9
N_km_sample = (sample_budget / 6) ** (0.076/(0.076+0.103)) / 1e9
ax1.annotate(f'在{sample_budget:.0e} FLOPs:nChinchilla: {N_chi_sample:.0f}BnKM: {N_km_sample:.0f}B',
xy=(sample_budget, N_chi_sample), xytext=(1e21, 500),
arrowprops=dict(arrowstyle='->', color='red'),
bbox=dict(boxstyle="round,pad=0.3", fc="white", ec="red", alpha=0.8))
# 子图2: 最优数据量对比
ax2.loglog(compute_range, D_chi_optimal, 'r-', linewidth=3, label='Chinchilla最优')
ax2.loglog(compute_range, D_km_optimal, 'b--', linewidth=2, label='KM最优')
ax2.set_xlabel('计算预算 (FLOPs)')
ax2.set_ylabel('最优训练数据量 (十亿token)')
ax2.set_title('训练数据量推荐对比nChinchilla vs KM')
ax2.legend()
ax2.grid(True, alpha=0.3)
# 子图3: 参数-数据比例对比
ratio_chi = np.array(N_chi_optimal) / np.array(D_chi_optimal)
ratio_km = np.array(N_km_optimal) / np.array(D_km_optimal)
ax3.semilogx(compute_range, ratio_chi, 'r-', linewidth=3, label='Chinchilla比例')
ax3.semilogx(compute_range, ratio_km, 'b--', linewidth=2, label='KM比例')
ax3.set_xlabel('计算预算 (FLOPs)')
ax3.set_ylabel('参数/数据比例 (N/D)')
ax3.set_title('资源分配策略对比n比例越高 = 越偏向模型规模')
ax3.legend()
ax3.grid(True, alpha=0.3)
# 子图4: 性能对比 - 固定计算预算下的损失
fixed_budget = 1e22
model_sizes = [7, 20, 70, 200] # 不同的模型规模 (十亿参数)
chinchilla_losses = []
km_losses = []
for size in model_sizes:
# 在固定预算下,计算对应的数据量
data_chi = fixed_budget / (6 * size * 1e9) / 1e9 # 十亿token单位
data_km = fixed_budget / (6 * size * 1e9) / 1e9 # 相同计算预算
loss_chi = chinchilla_scaling_law(size, data_chi)
loss_km = km_scaling_law(size * 1000, data_km * 1000)
chinchilla_losses.append(loss_chi)
km_losses.append(loss_km)
ax4.plot(model_sizes, chinchilla_losses, 'ro-', linewidth=2, label='Chinchilla预测')
ax4.plot(model_sizes, km_losses, 'bs--', linewidth=2, label='KM预测')
ax4.set_xlabel('模型规模 (十亿参数)')
ax4.set_ylabel('预测损失')
ax4.set_title(f'固定预算 {fixed_budget:.0e} FLOPs 下n不同模型规模的性能对比')
ax4.legend()
ax4.grid(True, alpha=0.3)
# 标记最优配置
optimal_size_chi = (fixed_budget / 6) ** 0.5 / 1e9
optimal_data_chi = (fixed_budget / 6) ** 0.5 / 1e9
optimal_loss_chi = chinchilla_scaling_law(optimal_size_chi, optimal_data_chi)
ax4.axvline(x=optimal_size_chi, color='red', linestyle=':', alpha=0.7)
ax4.annotate(f'Chinchilla最优n{optimal_size_chi:.0f}B模型',
xy=(optimal_size_chi, optimal_loss_chi),
xytext=(optimal_size_chi+30, optimal_loss_chi+0.1),
arrowprops=dict(arrowstyle='->', color='red'))
plt.tight_layout()
plt.show()
输出结果:
Chinchilla: 108, KM: 447,预测的损失值和现实偏差很大,对参数(A, B, E, α, β)需要重新校准。
Chinchilla法则(平衡策略):
KM法则(极端偏向策略):
import numpy as np
import matplotlib.pyplot as plt
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 1. 定义计算预算 C (以FLOPs为单位,使用对数等间距点)
# np.linspace(20, 24, 100) 生成一个从20到24的数组,包含100个等间距的点。
# 这个数组代表计算预算的对数值,范围从10^20到10^24 FLOPs,覆盖了从中等到大规模的训练预算。
log_C = np.linspace(20, 24, 100)
# 将对数坐标转换回线性坐标,得到具体的计算预算值C。
C = 10 ** log_C
# 2. 根据两种法则估算模型参数量 (N) 和训练数据量 (D)
# 注意:以下是非常简化的经验近似,用于演示两种法则在趋势上的根本差异。
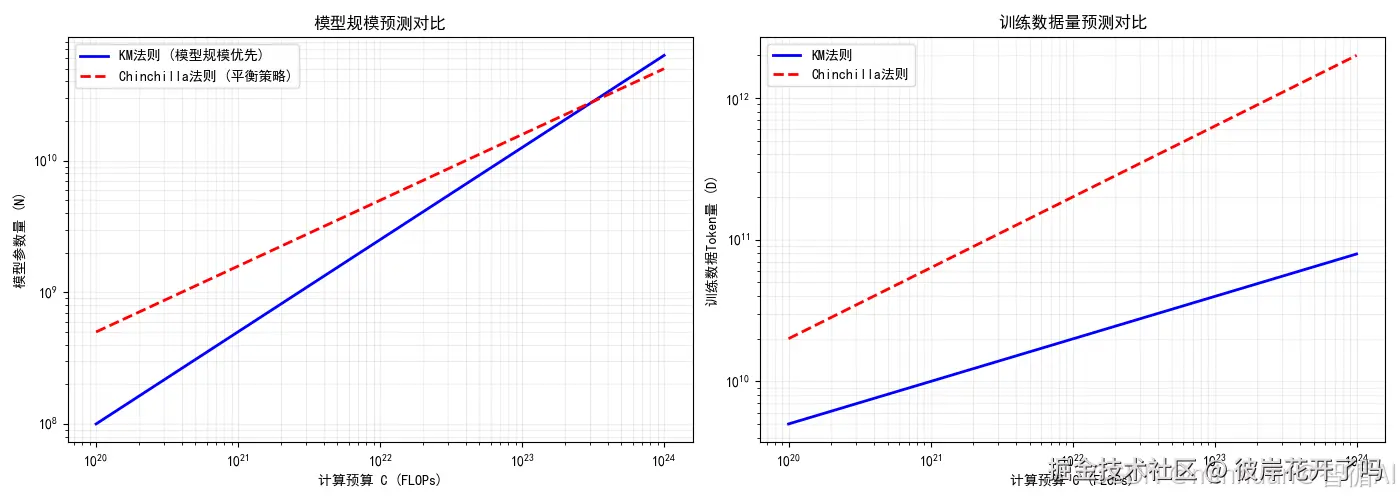
# KM扩展法则风格 (倾向于更大的模型规模):
# 假设模型参数量 N 与计算预算 C 的 0.7 次方成正比。
# 假设训练数据量 D 与计算预算 C 的 0.3 次方成正比。
# 这里的比例常数 (1e8, 5e9) 是为了让曲线在图表中处于一个合适的视觉位置而任意设定的。
N_km = 1e8 * (C / 1e20) ** 0.7 # 基础参数1亿,按比例缩放
D_km = 5e9 * (C / 1e20) ** 0.3 # 基础数据50亿Token,按比例缩放
# Chinchilla扩展法则风格 (模型与数据平衡增长):
# 假设模型参数量 N 和训练数据量 D 均与计算预算 C 的 0.5 次方成正比。
# 这体现了其核心思想:对于固定的计算预算,应在N和D之间进行平衡分配。
N_chi = 5e8 * (C / 1e20) ** 0.5 # 基础参数5亿,按比例缩放
D_chi = 2e10 * (C / 1e20) ** 0.5 # 基础数据200亿Token,按比例缩放
# 3. 创建图表进行可视化
# plt.subplots(1, 2) 创建一個包含1行2列子图的图形窗口。
# figsize=(14, 5) 设置整个图形窗口的尺寸为宽14英寸、高5英寸。
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(14, 5))
# 图表1:模型参数量 (N) 对比
# 在第一个子图(ax1)上,用蓝色实线绘制KM法则的N,用红色虚线绘制Chinchilla法则的N。
ax1.loglog(C, N_km, 'b-', linewidth=2, label='KM法则 (模型规模优先)')
ax1.loglog(C, N_chi, 'r--', linewidth=2, label='Chinchilla法则 (平衡策略)')
# 设置坐标轴标签、标题和图例。
ax1.set_xlabel('计算预算 C (FLOPs)')
ax1.set_ylabel('模型参数量 (N)')
ax1.set_title('模型规模预测对比')
ax1.legend() # 显示图例
ax1.grid(True, which="both", ls="-", alpha=0.2) # 添加网格线,便于读数
# 图表2:训练数据量 (D) 对比
# 在第二个子图(ax2)上,用同样的线型和颜色绘制两种法则的D。
ax2.loglog(C, D_km, 'b-', linewidth=2, label='KM法则')
ax2.loglog(C, D_chi, 'r--', linewidth=2, label='Chinchilla法则')
ax2.set_xlabel('计算预算 C (FLOPs)')
ax2.set_ylabel('训练数据Token量 (D)')
ax2.set_title('训练数据量预测对比')
ax2.legend()
ax2.grid(True, which="both", ls="-", alpha=0.2)
# 自动调整子图参数,使之填充整个图像区域,避免重叠。
plt.tight_layout()
# 显示图形
plt.show()
输出结果:
图例分析:
左图:模型规模预测对比
右图:训练数据量预测对比
图示结论:
大模型扩展法则揭示了计算预算的最优分配原理,KM法则主张“规模至上”,认为应优先扩大模型参数,数据适量即可。而Chinchilla法则通过实验证明,许多大模型实际处于训练不足状态,提出模型与数据应平衡增长的效率优先原则。
Chinchilla法则完成了关键范式转移,通过系统实验证明:平衡分配计算预算至模型参数量与训练数据量,才能在固定成本下实现性能最优。其核心在于将资源分配从KM的7:3倾斜调整为1:1平衡。这一转变具有深远影响:数据价值被重新评估,模型开发从盲目追求参数量转向寻求最优配比。实践中,Chinchilla法则催生了LLaMA等"小模型、大数据"的高效架构,显著降低了AI应用门槛。

